







作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[人工智能-深度学习-54]:什么是非监督式学习以及常见的非监督式学习的模式_文火冰糖(王文兵)的博客-CSDN博客
目录
第3章 非监督学习(Unsupervised learning)
第4章 半监督学习(Semi-supervised learning)
第1章 机器学习的种类
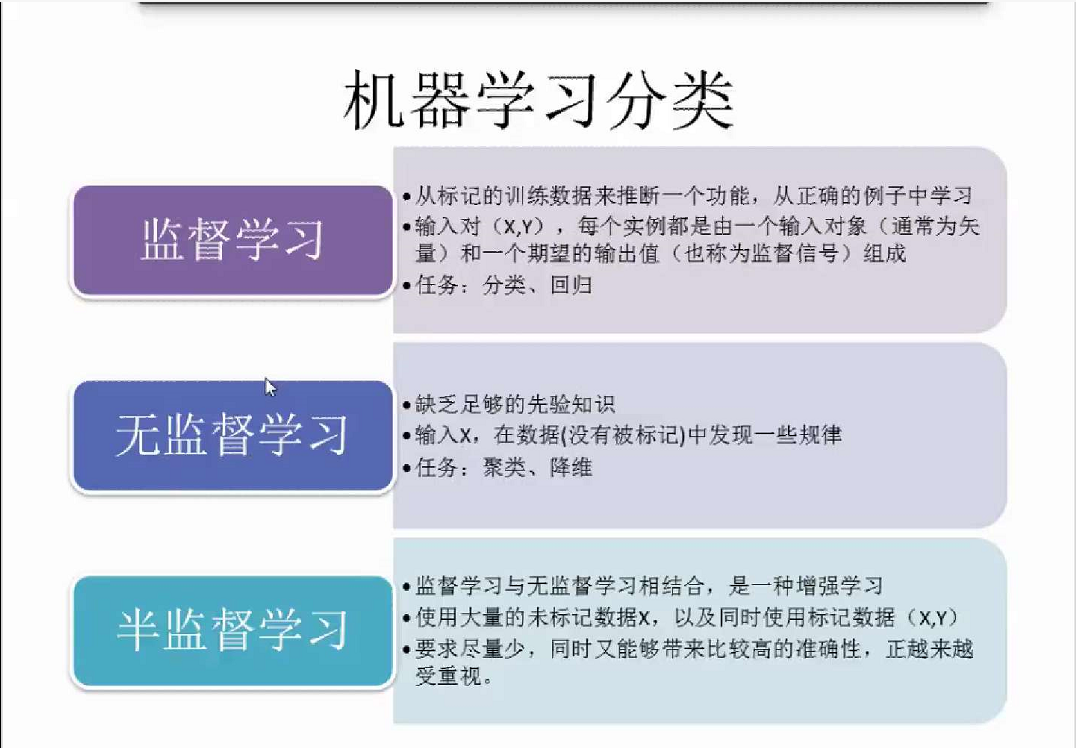
在机器学习(Machine learning)领域,主要有三类不同的学习方法:
(1)监督学习(Supervised learning)
(2)非监督学习(Unsupervised learning)
(3)半监督学习(Semi-supervised learning)
第2章 监督学习(Supervised learning)
通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
监督式学习,需要人工对数据集进行标注,识别出数据对应的“标准”答案,这个标准答案就是“label"标签。
理解1:监督式学习是拥有一组已知的输入变量(自变量)和一组已知的输出变量(因变量),使用某种算法去学习从输入到输出之间的映射函数。目标是得到足够好的近似映射函数。
当输入新的变量的数值时,可以以此预测输出变量的值。
算法从数据集学习的过程可被看作一名教师在监督学习,所以称:监督式学习。
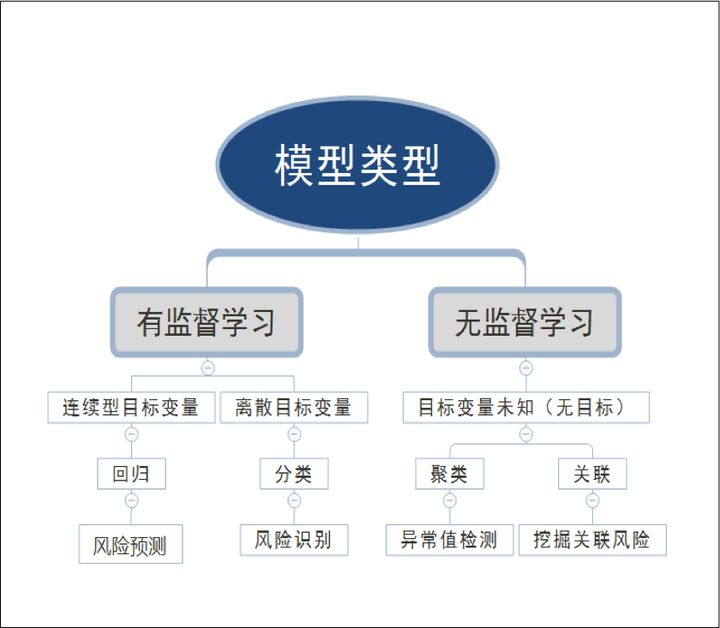
监督式学习 分为:
(1)分类(输出类别标签)问题

(2)回归(输出连续值)问题。

理解2:根据输入-输出样本对L={(x1,y1),···,(xl,yl)}学习输入到输出的映射f:X->Y,来预测测试样例的输出值。SL包括分类(Classification)和回归(Regression)两类任务,分类中的样例xi∈Rm(输入空间),类标签yi∈{c1,c2,···,cc},cj∈N;回归中的输入xi∈Rm,输出yi∈R(输出空间)。
理解3: 监督学习针对的是带标签的训练集,根据标签的离散/连续,监督学习又分为分类/回归。我们定义样本集合为X,与X中样本一一对应的标签组成的集合记为Y,令image.png表示样本和标签服从的联合分布(未知),监督学习的任务就是训练一个方程image.png,使得f(x)可以预测出x的真实标签。
第3章 非监督学习(Unsupervised learning)
3.1 什么是非监督式学习
直接对输入数据集进行建模,训练数据集本身并不提供人为的“标签”,例如聚类。
模型需要根据数据集自身,来发现或学习到数据集内部隐藏的规律。
理解1:无监督式学习指的是指,在学习时,只有输入变量,没有相关的输出变量的人为标准。
目标是对数据中潜在的结构和分布建模,以便对数据做进一步的学习。
相比于监督式学习,无监督式没有确切的答案和学习过程也没有监督,算法独自运行发现和表达数据中的结构。
无监督式学习 分为:
(1)聚类问题(在数据中发现内在的分组) VS “分类”
(2)关联问题(数据的各部分之间的关联和规则) VS "回归“
例如,找到同时购买x和y商品的顾客 =》 商品x和商品y之间的关系。
如:我爱北京天安门 =》 单词与单词之间的关系,词向量。
理解2: 利用无类标签的样例U={x1,···,xn}所包含的信息,学习其对应的类标签Yu=[y1···yn]T。
由学习到的类标签信息把样例划分到不同的簇(Clustering)或找到高维输入数据的低维结构。
UL包括:
- 聚类(Clistering)
- 降维(Dimensionality Reduction)
3.2 非监督学习的基本思路
在非监督学习中,数据并不会被人为地特别标识,学习模型是能够推断出数据的一些内在结构。
非监督学习一般有两种思路:
(1)第一种思路是在指导Agent时不为其指定明确的分类,而是在成功时采用某种形式的激励制度。需要注意的是,这类训练通常会被置于决策问题的框架里,因为它的目标不是产生一个分类系统,而是做出最大回报的决定,这类学习往往被称为强化学习。
(2)第二种思路称为聚合(Clustering),这类学习类型的目标不是让效用函数最大化,而是找到训练数据中的近似点,本节将重点介绍此类非监督学习思路。
聚类的目的在于把相似的东西聚在一起,并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
第二种思路的非监督学习常见的应用场景包括关联规则的学习及聚类等。常见算法包括Apriori、K-Means、EM等。
聚类分析是无监督学习的主要方法,它能从大量的数据集中找出有规律性的结果。为了适应各种实际问题的数据结构的特点,还发展了以上述方法为基础的各种其他算法。
3.3 非监督式学习的应用
词向量、聚类都是一种非监督式学习的应用。
第4章 半监督学习(Semi-supervised learning)
半监督学习:综合利用有标签的数据和没有类标的数据,来生成合适的模型函数。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121687892



















 5183
5183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











