









目录
1.模型思想
2.Transformer模型架构
3.Attention机制
4.位置编码
5.代码实现与解析
6.资料
一. 模型思想
Transformer是续MLP RNN CNN后又一个影响深远的模型, 之前CNN RNN基本上都在各自的领域发光发热, 但是Transformer 在很多领域都有着很广泛的应用. eg: chatgpt llama等语言大模型, sd文生图模型, 以及多模态 llava等. 我们最近探索的视频&图像画质评测以及画质增强很多算法也都是基于Transformer. 所以加强对Transformer学习理解和应用迫在眉睫.
Transformer抛弃了传统的RNN和CNN,完全由Attention机制组成。
相比传统RNN、CNN,Transformer有以下优势:
-
使用Attention机制,解决了长距离依赖的问题
-
实现并行化,显著提高训练效率
-
更高的灵活性和通用性,支持处理各种类型的序列数据:文本、图像、音频、视频等
Attention机制很关键,本文会重点阐述
二. 模型架构
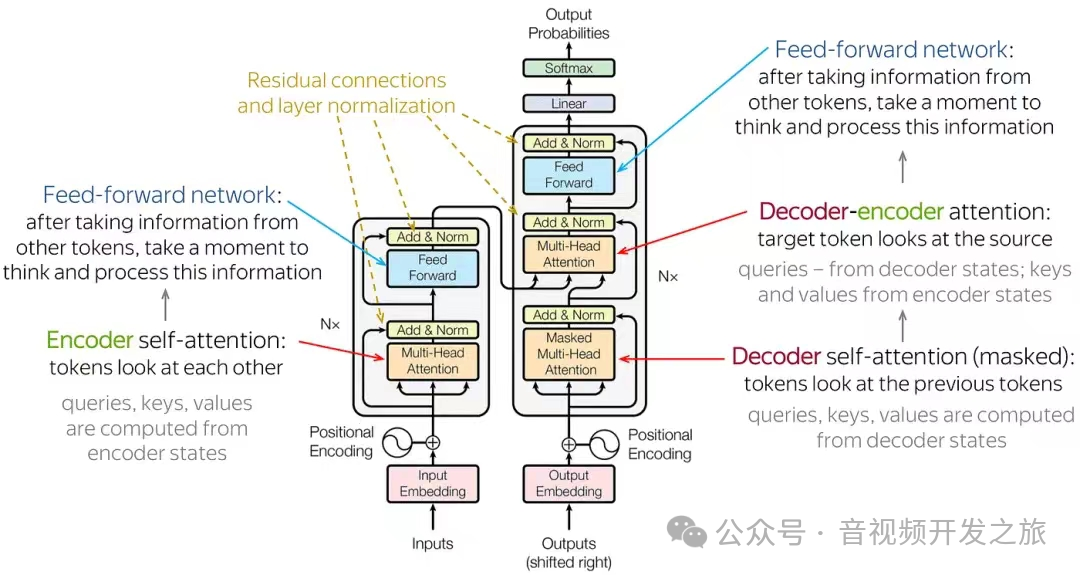
Transformer由一个编码器(Encoder)和一个解码器(Decoder)组成.通过自注意力机制(self-attention),模型能够捕捉长距离的依赖关系,该设计支持并行计算,大大提高了处理速度.
Transformer的输入序列可以是文本也可以是图像分割的patch,这些数据经过WordEmbedding或者PathEmbedding等转为向量, 然后和位置编码(Position Encoding)相加作为编码器和解码器的输入.
编码器模块 有N层TransfomerEconderLayer组成, 每层由多头注意力机制(Multi-Head Attention)以及前馈神经网络(Feed Forward)组成. 每个模块的输出通过残差结构以及LayerNalization避免深层网络梯度消失的问题
解码器模块 和编码器模块类似,有N层TransfomerDecoderLayer组成, 解码模块输入的是上一层TransfomerDecoderLayer的输出;每层相比EncoderLayer多了一个带掩码的多头注意力机制(Masked Multi-Head Attention),确保解码器只能看到之前位置的数据;第2个Multi-Head Attention的 Q来自解码器中第1个Self-attention的输出, K,V则来自Encoder的输出。
Encoder和Decoder模块可以组合使用,也可以单独使用。比如,翻译任务使用了Encoder-Decoder,Bert、VIT等使用了Only-Encoder,ChatGpt生LLM使用了Only-Decoder。
三. Attention机制
3.1 Attention
Attention机制的核心思想:模型处理信息时聚焦于输入数据中最重要的部分,具体步骤:
1. 将输入转换为查询(Query) 键(Key) 值(Value)
2. 计算查询(Q)和键(K)之间的相似度得分
3. 对得分进行归一化(通常使用Softmax函数)
4. 用归一化后的得分对值(V)进行加权求和
3.2 self-Attention(Scaled dot-product attention)
self-Attention自注意力是一种特殊类型的注意力机制,其中Q、K、V都是源自同一个输入。
用X矩阵表示输入,使用线性变换矩阵WQ、WK、WV计算得到Q、K、V
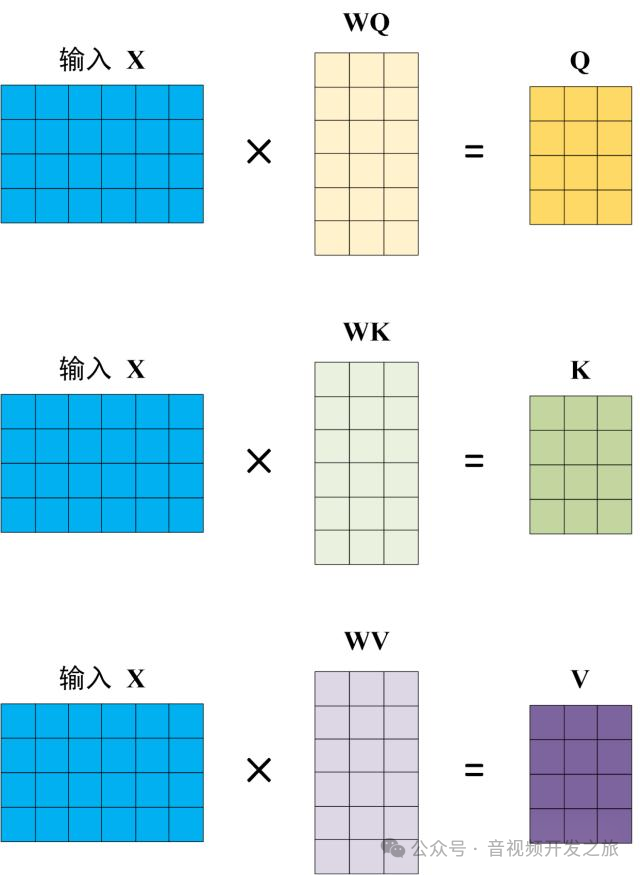
图片来自:Transformer模型详解(图解最完整版)
计算公式如下:
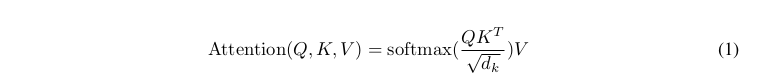
Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度(相似度)。
因为q和k的点积的数值会随着dimension的增大而增大,所以除以dimension的平方根,相当于归一化的效果。
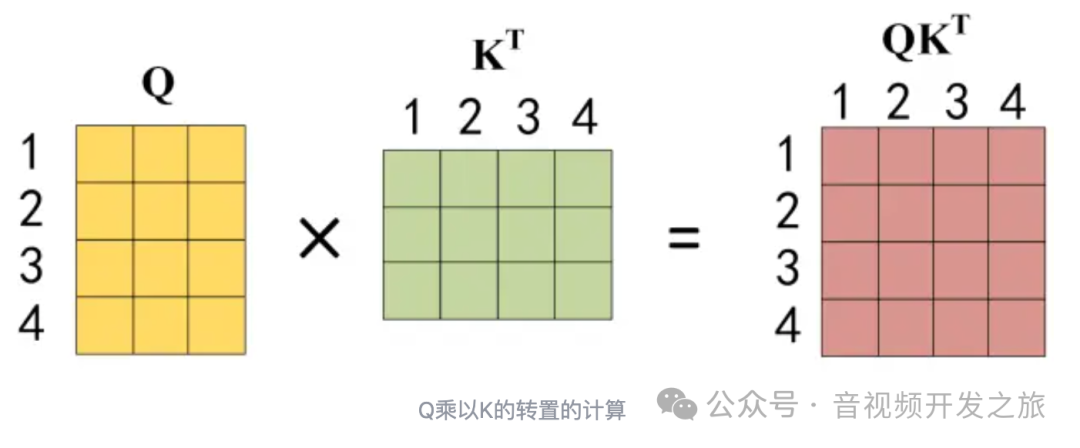
图片来自:Transformer模型详解(图解最完整版)
dk是K矩阵的维度,为了防止Q和K点积过大,除以该缩放因子,然后对矩阵中每一行进行Softmax,使每一行的和为1
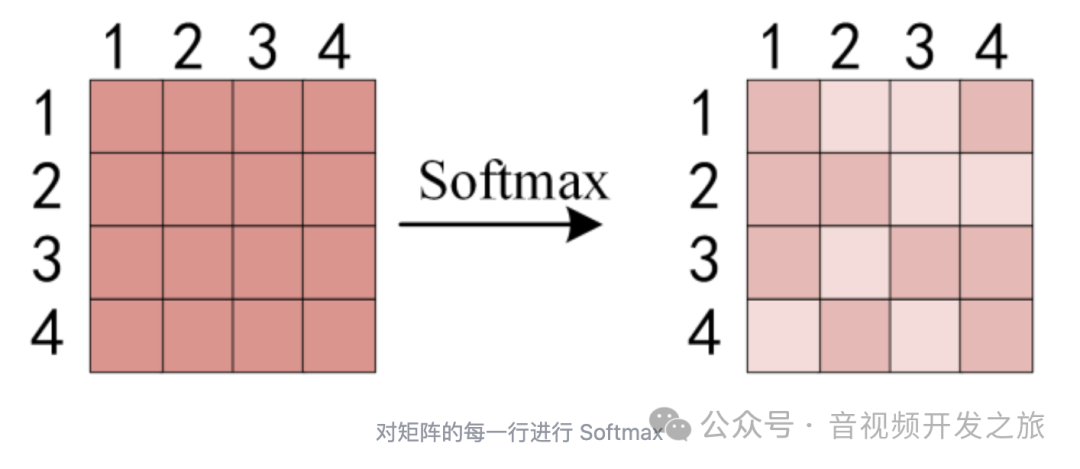
图片来自:Transformer模型详解(图解最完整版)
最终单词1的输出Z1等于所有单词i的值V乘以attenion系数之和
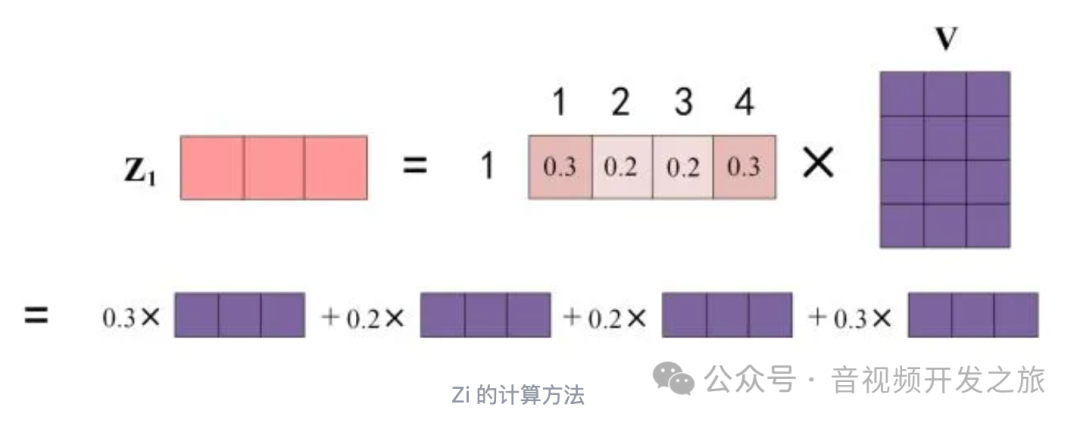
图片来自:Transformer模型详解(图解最完整版)
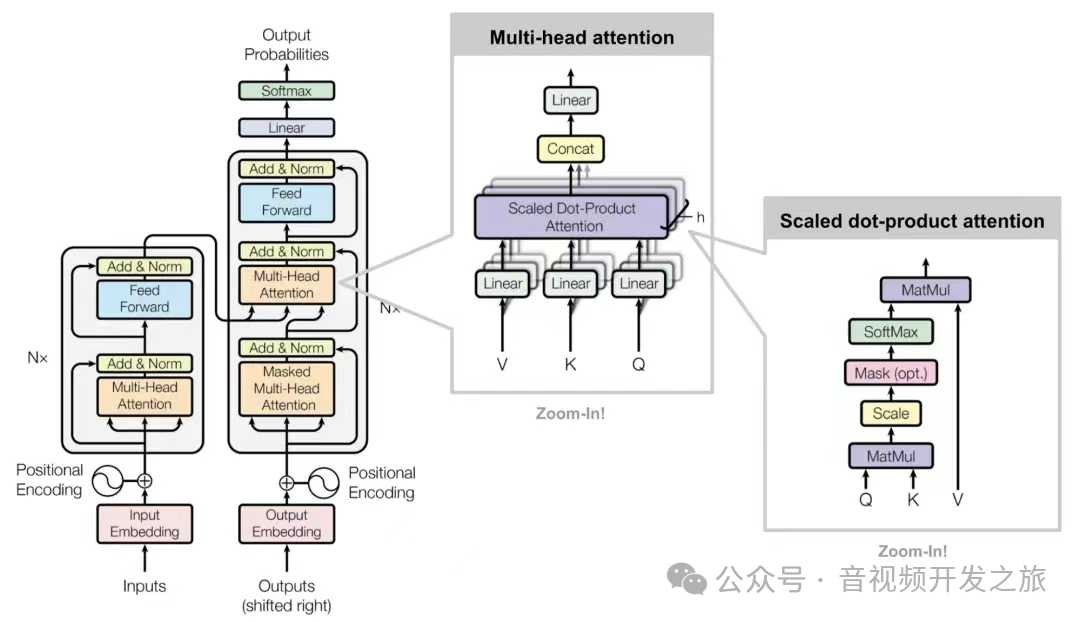
3.3 Multi-Head Attention
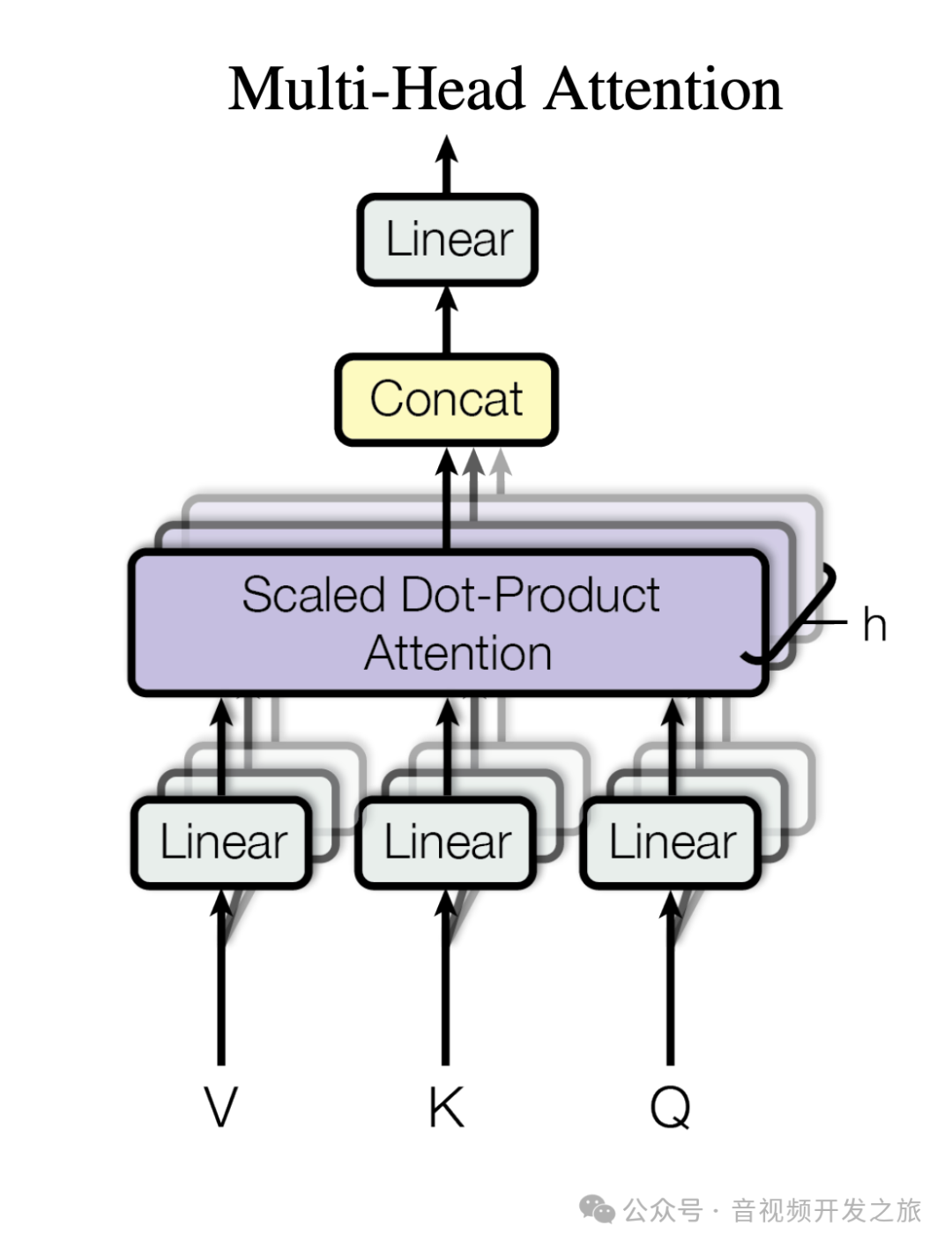
多头注意力(Multi-Head Attention)包含多个self-attention,使模型可以在不同的子空间捕获特征信息,增加模型的学习能力. 将输入X分别传递多个不同的self-attention,计算出每个输出矩阵,然后将他们concat在一起,再经过Linear层得到最终的输出。
输出矩阵Z和输入矩阵X的维度是一样的。
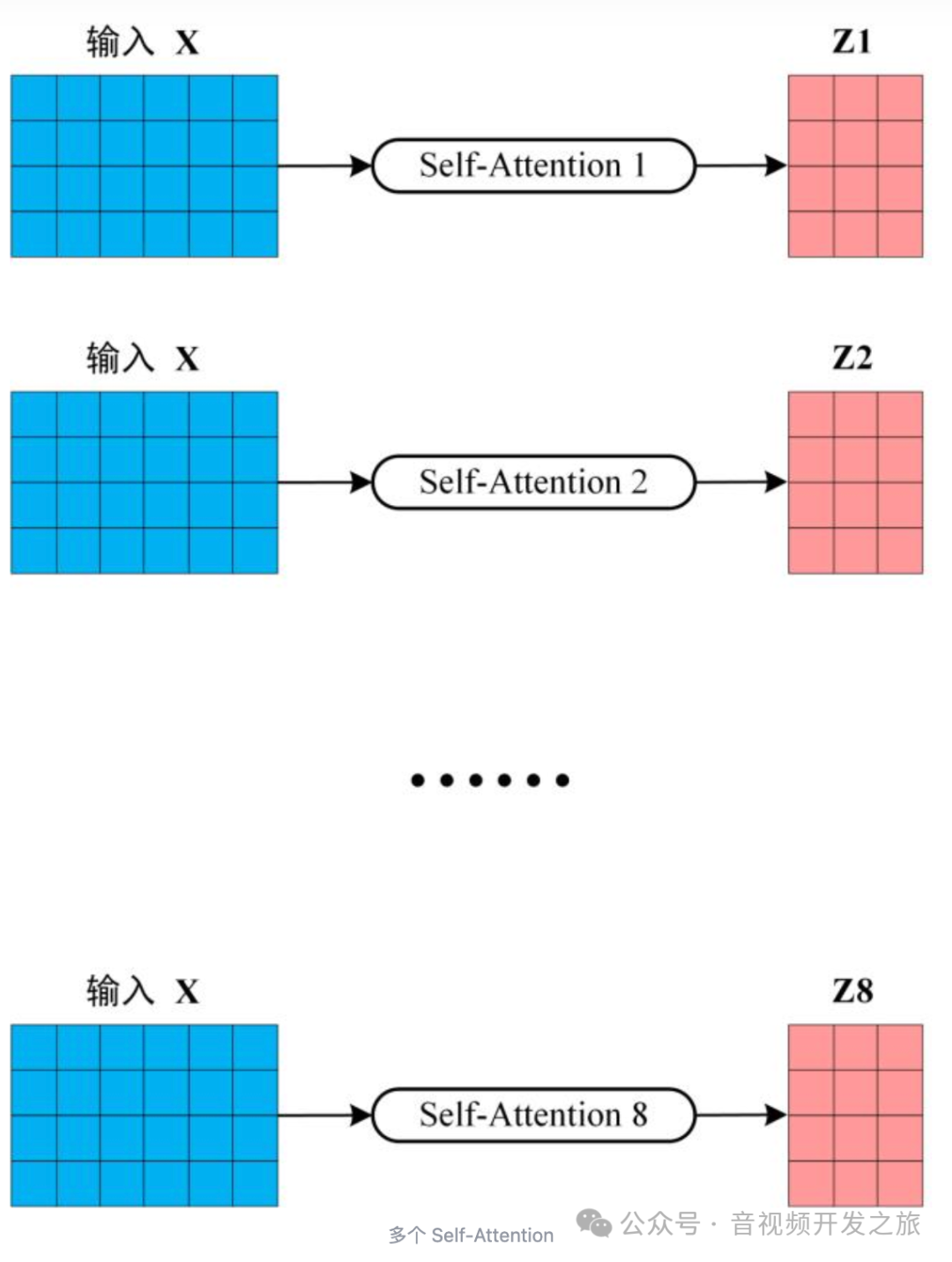
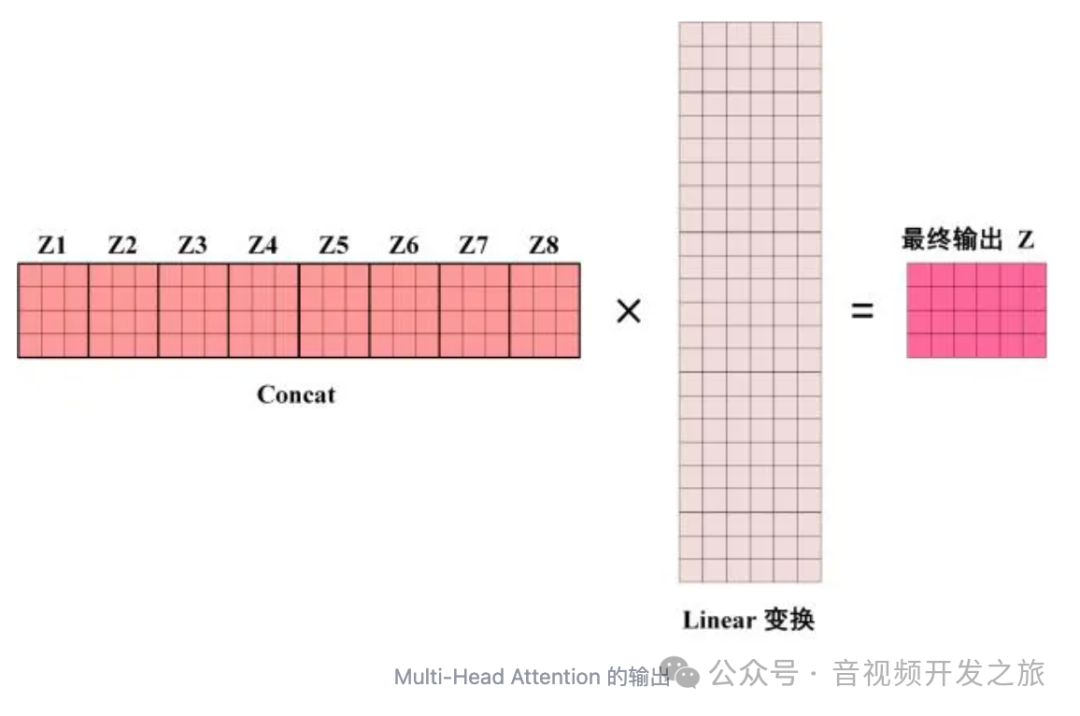
图片来自:Transformer模型详解(图解最完整版)
论文中也做了不同header的对attention的影响.
绿色部分(head更多)关注global的信息,而红色部分(header较少)关注local的信息。
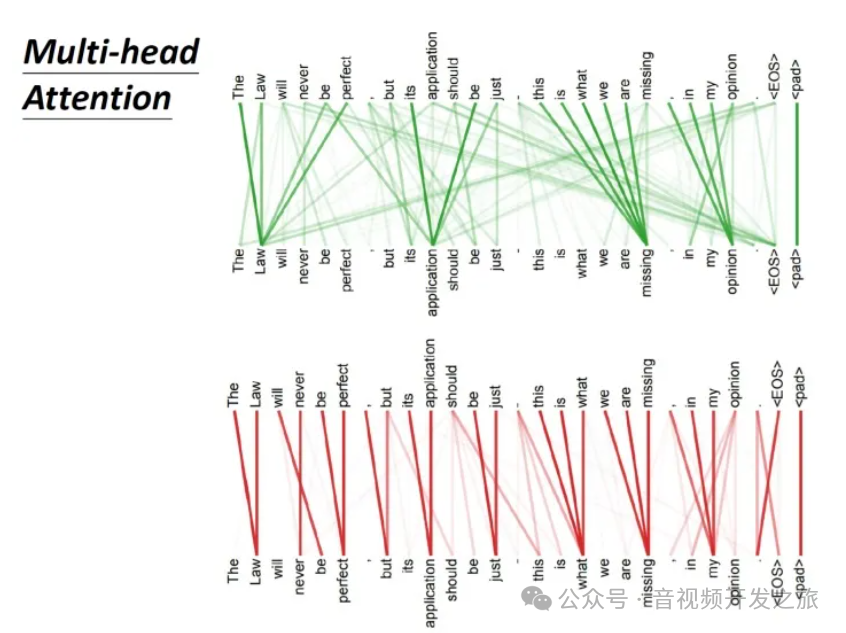
3.4 Masked Multi-Head Attention
Masked Multi-Head Attention是多头注意力的特殊形式,用在序列生成任务中,防止模型在生成当前元素时“看到”未来的元素。
四、位置编码
Transformer 没有使用具有序列特征的 RNN 的结构,而是使用全局信息,因此我们要向输入嵌入中注入位置信息,且位置编码要与输入嵌入具有相同的维度 dmodel ,使两者可以相加。
论文中的PE计算公式如下:
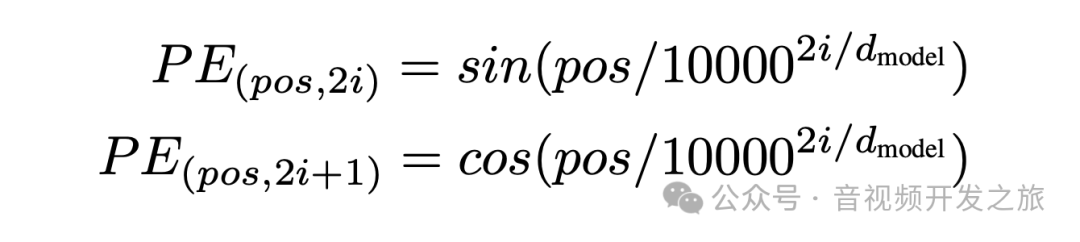
其中:“pos”指的是“单词”在序列中的位置,
eg:P0指的是第一个词的位置embedding;“d-model”表示词向量的维度,“i” 是指维度的index。下面我们以d-model为5为例说明
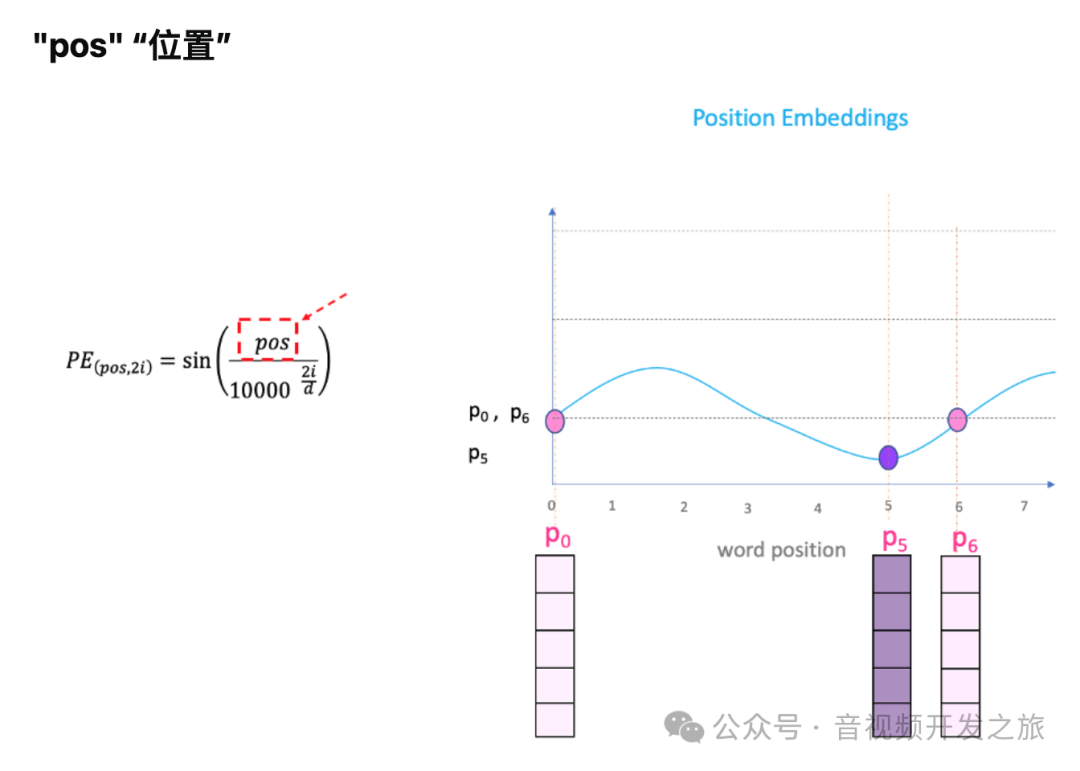
图片来自:What is the positional encoding in the transformer model?
我们绘制一条正弦曲线并改变“pos”(在 x 轴上),将在 y 轴上得到不同的位置值,不同位置的单词将具有不同的位置嵌入值。
但有一个问题。由于“sin”曲线间隔重复,可以在上图中看到 P0 和 P6 位于不同的位置,但是却具有相同的位置嵌入值。而方程中“i”就可以解决这个题。
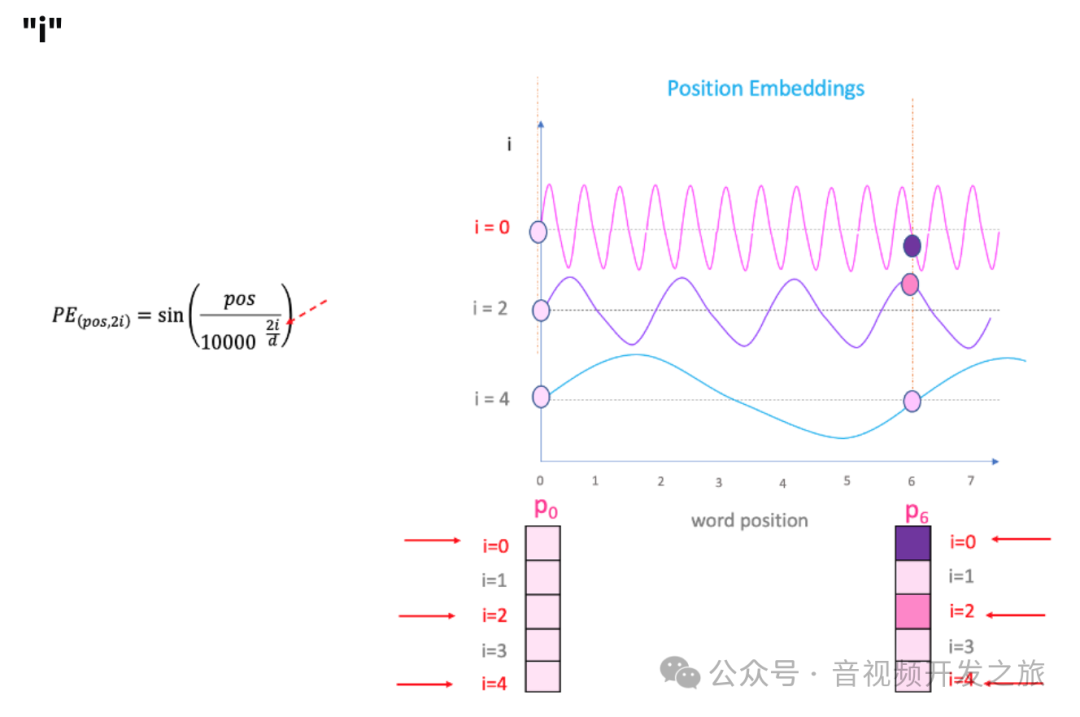
图片来自:What is the positional encoding in the transformer model?
改变上面等式中的“i”,将得到一堆频率不同的曲线。P0 和 P6在不同频率下的位置嵌入具有不同的值。
下面两张截图同另外一个维度解释了为什么PositionEmbedding和inputEmbedding可以相加.

搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了
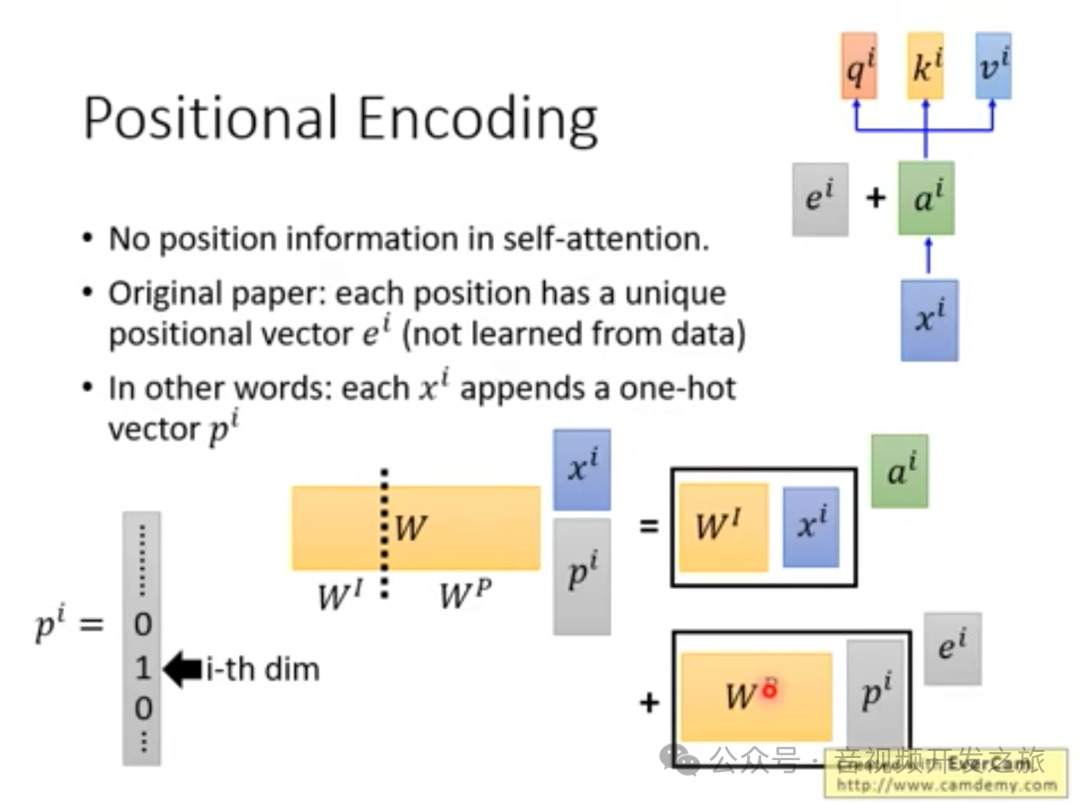
图片来自李宏毅-transformer:https://www.bilibili.com/video/av56239558
五、代码实现与解析
代码来自:https://github.com/jadore801120/attention-is-all-you-need-pytorch
5.1 self-attention
"""缩放点积注意力机制,实现自注意力机制 self-attention"""class ScaledDotProductAttention(nn.Module):''' Scaled Dot-Product Attention '''def __init__(self, temperature, attn_dropout=0.1):super().__init__()self.temperature = temperatureself.dropout = nn.Dropout(attn_dropout)def forward(self, q, k, v, mask=None):#计算q和v的相似系数(或称为注意力度) q和k点积相乘,除以temperature缩放系数,值为d_k ** 0.5,即建维度的平方根,防止维度过大时点积的数值过大attn = torch.matmul(q / self.temperature, k.transpose(2, 3))#如果有mask,把把mask区域填充为一个非常小的值(-1e9),这样在应用softmax时,这些位置的权重会接近0if mask is not None:attn = attn.masked_fill(mask == 0, -1e9)#对注意力度进行softmax归一化,应用dropout减少过拟合attn = self.dropout(F.softmax(attn, dim=-1))#最后 计算V的加权值 得到最终的输出output = torch.matmul(attn, v)return output, attnMultiHeadAttentionclass MultiHeadAttention(nn.Module):''' Multi-Head Attention module '''def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):super().__init__()#定义多头注意力机制 默认8个头,每个头的k和v的维度为64 (共8*64=512维),即 n_head=8, d_k=64, d_v=64self.n_head = n_head#d_k:每个头的K和Q的维度self.d_k = d_k#d_v 每个头的V的维度self.d_v = d_v#定义wq wk wv,用于对输入x进行线性变换投影 生成q k v矩阵self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)self.fc = nn.Linear(n_head * d_v, d_model, bias=False)#实例化 self-attention,其中缩放系数为dk的平方根self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)self.dropout = nn.Dropout(dropout)#实例化 LayerNormal归一化处理, eps: 一个很小的常数,用于数值稳定性,防止除零错误self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)def forward(self, q, k, v, mask=None):d_k, d_v, n_head = self.d_k, self.d_v, self.n_head#q k v 都是四维张量,(批次大小 batch_size,序列长度sequence_length,q/k/v的数量(即多少个单词) number of k/q/v, q/k/v的维度 dimension of k/q/v)sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)#保存输入 q 作为残差,在注意力机制后会加上这个残差residual = q# Pass through the pre-attention projection: b x lq x (n*dv)# Separate different heads: b x lq x n x dv#通过线性变换生成Q K V矩阵, 调整结构为 批次大小batchsize, 序列长度sequence_len,头的个数,维度的树量q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)# 矩阵维度转换为(batchsize,头的数量headnum,序列长度,维度) Transpose for attention dot product: b x n x lq x dv# 转换的目的为了self-attention中对最后两维进行矩运算q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)#如果mask遮罩不为空,新增一维if mask is not None:mask = mask.unsqueeze(1) # For head axis broadcasting.#调用self-attention进行前向传播q, attn = self.attention(q, k, v, mask=mask)# Transpose to move the head dimension back: b x lq x n x dv# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)#再把矩阵转为(batchsize,序列长度,头的数量headnum,维度)#合并最后两个维度,并将所有头拼接在一起q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)#进行全链接以及dropoutq = self.dropout(self.fc(q))#做残差连接处理q += residual#进行layernorm归一化q = self.layer_norm(q)return q, attnPositionwiseFeedForwardclass PositionwiseFeedForward(nn.Module):''' FeedForward Network (FFN)前馈神经网络. 数据从输入层单向流向输出层 没有循环或者反向连接包含两个前馈层的模块 A two-feed-forward-layer module'''def __init__(self, d_in, d_hid, dropout=0.1):super().__init__()#输入特征维度d_in=512, 隐藏层特征维度d_hid=2048self.w_1 = nn.Linear(d_in, d_hid) # position-wiseself.w_2 = nn.Linear(d_hid, d_in) # position-wiseself.layer_norm = nn.LayerNorm(d_in, eps=1e-6)self.dropout = nn.Dropout(dropout)def forward(self, x):#保存输入x作为残差,在两层线性变换后会加上这个残差residual = x#将输入x从d_in(512)升维到d_hid(2048),然后再从d_hid降维到d_in的作用:#增加模型容量(引入一个更大的隐藏层,模型获得更多的参数和容量来学习输入数据的复杂映射)#非线性变换,在两个线性层之间使用非线性激活函数(relu),允许模型学习非线性关系,有助于捕获数据中复杂的特性#特征转换和信息整合:在这个过程中重新表征和组合特征,更好的适应下游任务x = self.w_2(F.relu(self.w_1(x)))x = self.dropout(x)x += residualx = self.layer_norm(x)return x
5.2 位置编码 PositionalEncoding 固定位置编码
class PositionalEncoding(nn.Module):#d_hid 保持和word_embedding一样的维度数512def __init__(self, d_hid, n_position=200):super(PositionalEncoding, self).__init__()# Not a parameterself.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))def _get_sinusoid_encoding_table(self, n_position, d_hid):''' Sinusoid position encoding table '''# TODO: make it with torch instead of numpydef get_position_angle_vec(position):return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2isinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1return torch.FloatTensor(sinusoid_table).unsqueeze(0)def forward(self, x):return x + self.pos_table[:, :x.size(1)].clone().detach()
5.3 编码器 EncoderLayer
class EncoderLayer(nn.Module):''' Compose with two layers '''def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):super(EncoderLayer, self).__init__()#d_model=512, d_inner=2048,n_head=8, d_k=64, d_v=64, dropout=0.1#编码层,包含一个多头注意力机制和一个前馈神经网络self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)def forward(self, enc_input, slf_attn_mask=None):#自注意力机制的Q K V 都是enc_input,mask为Noneenc_output, enc_slf_attn = self.slf_attn(enc_input, enc_input, enc_input, mask=slf_attn_mask)enc_output = self.pos_ffn(enc_output)return enc_output, enc_slf_attnclass Encoder(nn.Module):''' A encoder model with self attention mechanism. '''#d_word_vec=512, d_model=512, d_inner=2048,n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200def __init__(self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):super().__init__()#wordembeddingself.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)#position embeddingself.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)self.dropout = nn.Dropout(p=dropout)#6个编码层self.layer_stack = nn.ModuleList([EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)for _ in range(n_layers)])self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)self.scale_emb = scale_embself.d_model = d_modeldef forward(self, src_seq, src_mask, return_attns=False):enc_slf_attn_list = []# -- Forwardenc_output = self.src_word_emb(src_seq)if self.scale_emb:enc_output *= self.d_model ** 0.5# wordembedding 加上positionembdding,进行dropout,在进行layer_norm作为 encoder层的输入enc_output = self.dropout(self.position_enc(enc_output))enc_output = self.layer_norm(enc_output)#逐层进行encoderfor enc_layer in self.layer_stack:enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)enc_slf_attn_list += [enc_slf_attn] if return_attns else []if return_attns:return enc_output, enc_slf_attn_listreturn enc_output,
5.4 解码层 DecoderLayer
class DecoderLayer(nn.Module):''' Compose with three layers '''def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):super(DecoderLayer, self).__init__()#d_model=512, d_inner=2048,n_head=8, d_k=64, d_v=64, dropout=0.1#解码层,包含一个MaskMultiHeadAttention ,一个MultiHeadAttention和一个FFNself.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)def forward(self, dec_input, enc_output,slf_attn_mask=None, dec_enc_attn_mask=None):#第一层为maskMultiHeadAttention,输入的QKV都是dec_inputdec_output, dec_slf_attn = self.slf_attn(dec_input, dec_input, dec_input, mask=slf_attn_mask)#第二层为MultiHeadAttention,Q为dec_ountput,KV为enc_output,mask为Nonedec_output, dec_enc_attn = self.enc_attn(dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)dec_output = self.pos_ffn(dec_output)return dec_output, dec_slf_attn, dec_enc_attnclass Decoder(nn.Module):''' A decoder model with self attention mechanism. '''#d_word_vec=512, d_model=512, d_inner=2048,n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200def __init__(self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):super().__init__()self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)self.dropout = nn.Dropout(p=dropout)self.layer_stack = nn.ModuleList([DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)for _ in range(n_layers)])self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)self.scale_emb = scale_embself.d_model = d_modeldef forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):dec_slf_attn_list, dec_enc_attn_list = [], []# -- Forwarddec_output = self.trg_word_emb(trg_seq)if self.scale_emb:dec_output *= self.d_model ** 0.5dec_output = self.dropout(self.position_enc(dec_output))dec_output = self.layer_norm(dec_output)for dec_layer in self.layer_stack:dec_output, dec_slf_attn, dec_enc_attn = dec_layer(dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)dec_slf_attn_list += [dec_slf_attn] if return_attns else []dec_enc_attn_list += [dec_enc_attn] if return_attns else []if return_attns:return dec_output, dec_slf_attn_list, dec_enc_attn_listreturn dec_output,
5.5 Transformer
class Transformer(nn.Module):''' A sequence to sequence model with attention mechanism. '''def __init__(self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,d_word_vec=512, d_model=512, d_inner=2048,n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,scale_emb_or_prj='prj'):super().__init__()self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idxassert scale_emb_or_prj in ['emb', 'prj', 'none']scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else Falseself.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else Falseself.d_model = d_modelself.encoder = Encoder(n_src_vocab=n_src_vocab, n_position=n_position,d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb)self.decoder = Decoder(n_trg_vocab=n_trg_vocab, n_position=n_position,d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb)self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)for p in self.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)assert d_model == d_word_vec, \'To facilitate the residual connections, \the dimensions of all module outputs shall be the same.'if trg_emb_prj_weight_sharing:# Share the weight between target word embedding & last dense layerself.trg_word_prj.weight = self.decoder.trg_word_emb.weightif emb_src_trg_weight_sharing:self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weightdef forward(self, src_seq, trg_seq):src_mask = get_pad_mask(src_seq, self.src_pad_idx)trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)enc_output, *_ = self.encoder(src_seq, src_mask)dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)seq_logit = self.trg_word_prj(dec_output)if self.scale_prj:seq_logit *= self.d_model ** -0.5return seq_logit.view(-1, seq_logit.size(2))
六、资料
1.论文:Attention Is All You Need:https://arxiv.org/pdf/1706.03762
2.代码:https://github.com/huggingface/transformers
transformers_training: https://huggingface.co/docs/transformers/training
3.《Attention is all you need》通俗解读,彻底理解版:注意力机制的运算 https://blog.csdn.net/dongtuoc/article/details/140198622
4.一文读懂「Attention is All You Need」| 附代码实现 https://www.jiqizhixin.com/articles/2018-01-10-20
5.论文翻译:Attention Is All You Need https://blog.csdn.net/nocml/article/details/103082600
6.论文理解:transformer 结构详解 https://blog.csdn.net/nocml/article/details/110920221
7.论文实现:transformer pytorch 代码实现 https://blog.csdn.net/nocml/article/details/124489562
8.Pytorch代码讲解:https://zhuanlan.zhihu.com/p/403433120
9.李沐-Transformer论文逐段精读【论文精读】:https://www.bilibili.com/video/BV1pu411o7BE
10.李宏毅-Transformer:https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=61
11.Transformer中的position encoding https://zhuanlan.zhihu.com/p/166244505
12.attention-is-all-you-need-pytorch:https://github.com/jadore801120/attention-is-all-you-need-pytorch
13.The Annotated Transformer https://nlp.seas.harvard.edu/2018/04/03/attention.html
14.Transformer模型详解(图解最完整版)https://zhuanlan.zhihu.com/p/338817680
15.Transformer 中的 Positional Encoding https://wmathor.com/index.php/archives/1453/
16.Transformer Architecture: The Positional Encoding https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
17.Visual Guide to Transformer Neural Networks - (Episode 1) Position Embeddings https://www.youtube.com/watch?v=dichIcUZfOw
What is the positional encoding in the transformer model? https://datascience.stackexchange.com/questions/51065/what-is-the-positional-encoding-in-the-transformer-model?newreg=8c38c485c8e8422f8ed92f54f89a711a
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









