







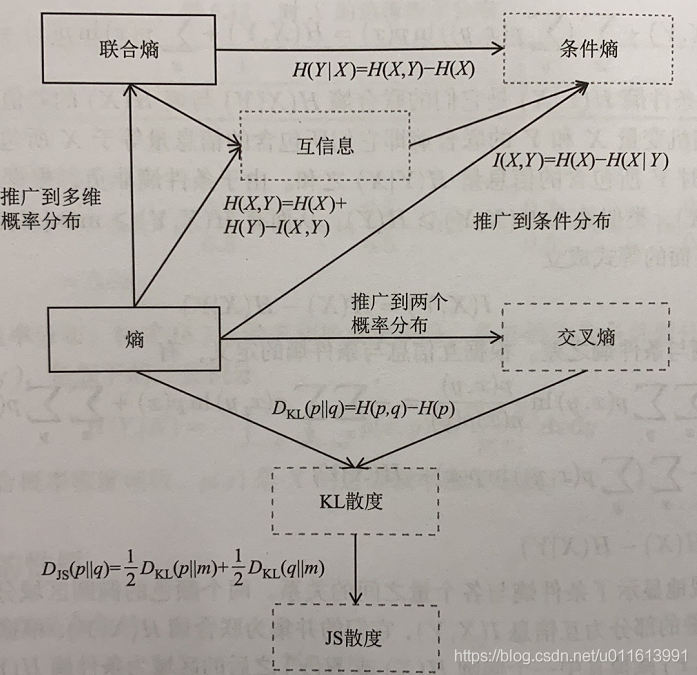
- 熵
熵是信息论中的一个基本概念,也称香农熵或信息熵,它衡量了一个概率分布的随机性程度,或者说它包含的信息量的大小。
考虑随机变量取某一特定值所包含的信息量大小,假设随机变量X取值x的概率为p(x), 取这个值的概率很小而它又发生了,则包含的信息量大。 考虑下面两个随机事件。
(1)明天要下雨
(2)奥巴马登上火星了
显然后者所包含的信息量要大于前者,因为后者的概率要远小于前者但却发生了。
如果定义一个函数h(x)来描述随机变量取值为x时的信息量大小,则h(x) 应为p(x)的单调减函数。但单调减函数有很多,如何确认呢?
假设有两个相互独立的随机变量X和Y,他们取值为x和y的概率分别为p(x)何p(y)。因为相互独立,因此他们的联合概率为:
p(x,y) = p(x)p(y)
它们取值为(x,y)的信息量应该是X取值为x且Y取值为y的信息量之和,即h(x,y) = h(x) +h(y)。
因此要求h(x)能把p(x)的乘法转换为加法运算,可满足的基本函数为对数函数,可以把信息量定义为:
h(x) = -lnp(x)
取负数是因为要满足h(x)为p(x)的单调减函数。而且由于 ,lnp(x)值为负的,加上负号后也保证了信息量h(x)
0
上面只考虑了随机变量取某一个值时包含的信息量,随机变量可以取多个值,因此需要计算它取所有各种值时所包含的信息量。随机变量取每一个值有一个概率,因此可以计算它取各个值时信息量的数学期望,这个均值就是熵。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









