










简介: 近邻法(
近邻法(
 ,
, )是一种基本分类与回归方法,它的原理是,对给定的训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的个实例,依据“少数服从多数”的原则,根据这个实例中占多数的类,就把该实例分为这个类。从上面简介可以看出,算法实际上是利用训练数据集对特征空间进行划分。在分类方法中,值的选择、实例之间距离的度量及分类决策规则是近邻法的三个基本要素 。
)是一种基本分类与回归方法,它的原理是,对给定的训练数据集,对新的输入实例,在训练数据集中找到与该实例最近邻的个实例,依据“少数服从多数”的原则,根据这个实例中占多数的类,就把该实例分为这个类。从上面简介可以看出,算法实际上是利用训练数据集对特征空间进行划分。在分类方法中,值的选择、实例之间距离的度量及分类决策规则是近邻法的三个基本要素 。
近邻算法计算过程:
设有训练数据集:

其中, 为实例的特征向量,
为实例的特征向量, 为实例的类别,输入新的实例
为实例的类别,输入新的实例 ,根据给定的距离度量,在训练集
,根据给定的距离度量,在训练集 中找出与最近邻的个点,涵盖这个点的的邻域记作
中找出与最近邻的个点,涵盖这个点的的邻域记作 ,在
,在 中根据分类决策规则(如多数服从少数)决定的类别
中根据分类决策规则(如多数服从少数)决定的类别 。
。
从上面的计算过程,可以发现近邻法的三个基本要素:值的选择、实例之间距离的度量及分类决策规则。
- 值的选择:首先,值的选择会对结果产生重要影响,这时毋庸置疑同时又显而易见的。如果选择较小的值,就相当于用较小的邻域中的实例进行预测,学习的近似误差会减小,只有与输入实例较近的训练实例才会对结果起作用,但缺点是学习的估计误差会增大,预测结果会对临近的实例点非常敏感。如果临近的实例点恰好是噪声,预测就会出错。也即,值的减小就意味着整体模型变得复杂,容易产生过拟合。
- 距离度量:特征空间中两个实例点的距离是两个实例点相似程度的反映。距离的表示常见的有欧氏距离和
 距离等。两个实例点之间的距离定义为:
距离等。两个实例点之间的距离定义为: - 分类决策规则:近邻法中de分类决策规则往往是多数表决,即由输入实例的个临近训练实例的多数决定输入实例的类别。这个临近实例的权值可以相同,也可以根据一定的规则产生不同的权值,如离输入实例越近,权值相应也越大。

以上介绍了近邻法的计算过程以及其三要素,下面介绍sklearn中的近邻分类器模型。
sklearn中近邻分类器定义为:
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, **kwargs)
#n_neighbors: 即k值
#weight:临近实例的权重,可以取三个值,‘uniform’为权重相同的情况,‘distance’表示权重与距离成反比,也可以自己定义函数来对权值进行设定
#algorithm:可以取四个值:{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},‘ball_tree‘、’kd_tree’表示使用‘ball_tree'和'kd_tree'进行计算,’brute‘表示使用brute-force搜索,’auto‘表示计算时尝试选择最合适的算法进行计算
#leaf_size: 选择’ball_tree'和‘kd_tree'时树的叶子数量
#p:即上面提到的距离度量的p值
#metric:距离度量方法的选择
下面使用sklearn 中的近邻分类器对数据进行分类。
首先,制造一些用于分类的数据:
# coding:utf-8
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
#1000个样本,分为三类
x,y = make_classification(n_samples=1000,n_features=2,n_informative=2,n_redundant=0,n_clusters_per_class=1,n_classes=3)
#将样本分为训练数据和测试数据
x_train = x[:800]
y_train = y[:800]
x_test = x[800:]
y_test = y[800:]
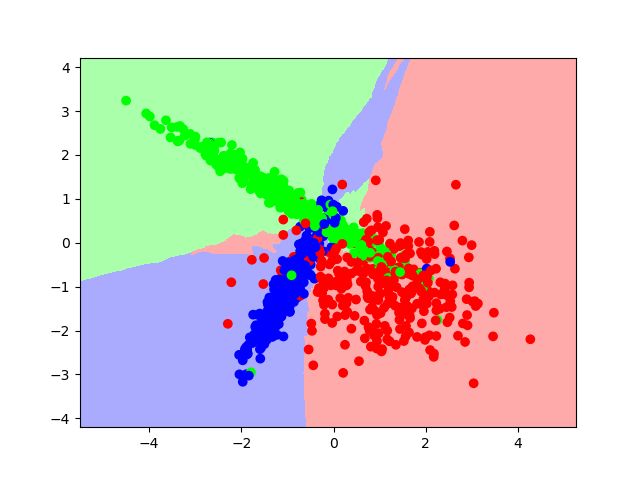
clf=KNeighborsClassifier(n_neighbors=4)
clf.fit(x_train,y_train)
#进行训练
clf.fit(x_train,y_train)
#测试训练成绩
print(clf.score(x_test,y_test))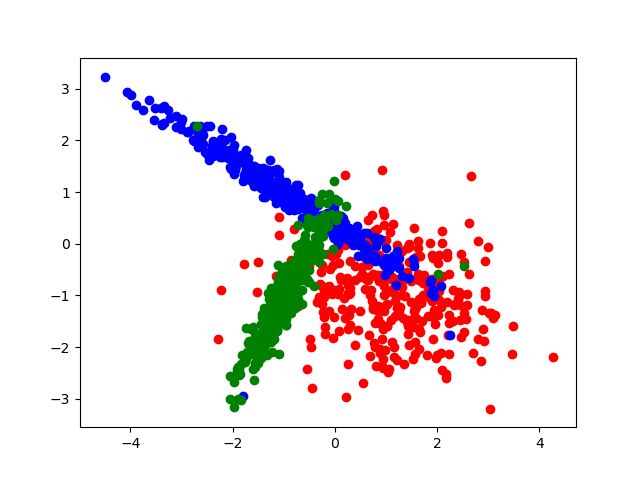















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









