







年轻人嘛,总是有一点功利心理,发一篇博客,不管内容质量怎么样,总是想得到更多的浏览量,就像渴求朋友圈的赞一样。但是频繁的上自己的博客只是为了看一眼浏览数或者有无评论,感觉听麻烦,所以就写了个爬虫抓一下数据。
说明:
- CSDN某用户的文章列表是这种网址http://blog.csdn.net/u011130578/article/list/,但是写博客多的用户,会有很多叶列表,这该怎么爬呢?这里有个投机取巧的办法是,在list后面输入一个足够大的数(比如某用户写了100篇博客,每页罗列20篇博文,那么一共就有5页网页来展示你的博文,只要这个数字大于5就ok),比如http://blog.csdn.net/u011130578/article/list/200,那么这个网址就会把该用户所有的文章全部列出来,然后直接截取数据就ok
- 正则表达式部分有瑕疵。应该有一个表达式把三项数据全都截取出来的办法,但是太弱了不会写,还得学。:)
-
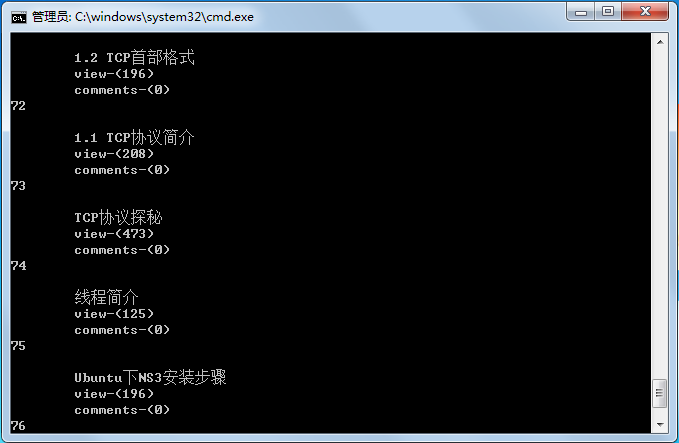
#引入库文件 import re import urllib import urllib.request #标题标号 cnt = 1 #爬虫开始的网址 url = 'http://blog.csdn.net/u011130578/article/list/200' #截取文章题目的正则 rule_title = r'<span class="link_title"><a.*?>((?:.|[\r\n])*?)</a></span>' #截取文章点击数的正则 rule_click = r'<span class="link_view".*?><a.*?>.*?</a>((?:.|[\r\n])*?)</span>' #截取文章评论数的正则 rule_comment = r'<span class="link_comments".*?><a.*?>.*?</a>((?:.|[\r\n])*?)</span>' #模拟浏览器,加入User-Agent request = urllib.request.Request(url, headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1) \ AppleWebKit/537.36 (KHTML, like Gecko)\ Chrome/50.0.2657.3 Safari/537.36' }) try: html = urllib.request.urlopen(request) data = html.read() titles = re.compile(rule_title) title = titles.findall(data.decode('UTF-8')) clicks = re.compile(rule_click) click = clicks.findall(data.decode('UTF-8')) comments = re.compile(rule_comment) comment = comments.findall(data.decode('UTF-8')) for n in range(len(title)): print(str(cnt)+"\n"+title[n]+"view-"+click[n]+"\n\tcomments-"+comment[n]) cnt += 1 except: print('error')运行截图就是这样:
如果每次在DOS框敲执行命令也觉得费劲的话,可以对代码做一个死循环处理,来定时查看某项数据(在linux下可以使用crontab来定时自动化执行)。
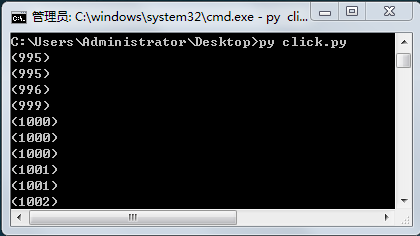
import time ... ... while 1: try: html = urllib.request.urlopen(request) data = html.read() titles = re.compile(rule_title) title = titles.findall(data.decode('UTF-8')) clicks = re.compile(rule_click) click = clicks.findall(data.decode('UTF-8')) comments = re.compile(rule_comment) comment = comments.findall(data.decode('UTF-8')) print(click[0]) #for n in range(len(title)): # print(str(cnt)+"\n"+title[n]+"view-"+click[n]+"\n\tcomments-"+comment[n]) # cnt += 1 except: print('error') #180s = 3mins time.sleep(180)运行截图;















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









