







1.CPU如何读取内存
CPU在处理内存的过程中,是把内存当做一块一块来处理的,每一块可以是2,4,8或16bytes。假设CPU读取块的大小是4bytes
其中一块内存分布如图:
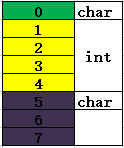
假设我们读取第一个char类型,那么CPU会读取0-3地址的4bytes的内存,存入寄存器,然后踢出1-3部分的内存,最后得到char类型的变量值。然后读取int类型,此时CPU是不能直接读取1-4地址空间的,只能读取0-3地址内存,通过移位提出0位置地址,并空出一个byte的空间,然后读取4-7地址的内存,通过移位,踢出5-7地址的内存,只剩4位置的内存值,然后剩余的1-3地址和4地址进行组合,构成此时的int值。这样的操作效率很低。当然,如果硬件系统并不支持这种“合并”的操作,那么读取内存操作就会崩溃。
试想,假如我们就把char存在0-3地址空间空间,int存储在4-7地址空间那么CPU就可以直接读取两个变量的值,虽然耗费了空间,但是CPU读取内存的效率确实大大增加了。事实上,操作系统在分配内存的时候就是按照这种方式进行的,也就是内存对齐。
2.内存对齐原则
规则:
- 类内数据成员先自身对齐(地址值%自身所占空间长度 == 0)
- 类整体在进行对齐(内存尾地址值%min(#pragma pack, 类中数据成员最长长度) == 0)
下图是一张内存中的部分地址图:
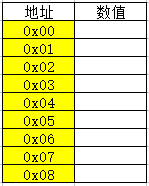
我们定义类
struct A{
char a;
int b;
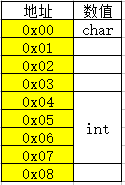
}- 首先存储char类型变量,那么数据成员自身对齐就是:
偏移地址%自身所占内存长度 == 0
所以a存在0x00位置。 - 存储int类型,按照由低到高的顺序访问地址,发现第一个满足对齐的地址是0x04,那么b变量就从这个位置开始存储。
- 存储完成后,整体在对齐。此时的内存空间是这样的:
sizeof(A);//8
在次定义结构体
struct B{
int a;
char b;
short c;
}分配规则相同,那么此时的内存分布图:
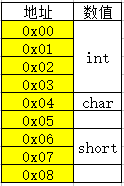
sizeof(B);//8
那么同理,sizeof(C);//12
struct C {
char a;
int b;
short c;
}3.预处理器语法
前文中提到#pragma pack()这是预处理器自定义的对齐参数,默认是8。
- #pragma pack(show)可以查看默认对齐参数,在编译器中以warning形式给出
- 通过以下代码可以自定义内存对齐的数值
#pragma pack(push)
#pragma pack(n)
...//这里是n对齐
#pragma pack(pop)
...//这里是默认对齐n的取值可以是1,2,4,8,16。
4.32位和64位编译器各类型所占空间
注意int和long类型。
32位编译器:
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器:
char :1个字节
char*(即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节














 2656
2656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









