









文章来源于微信公众号(茗创科技),欢迎有兴趣的朋友搜索关注
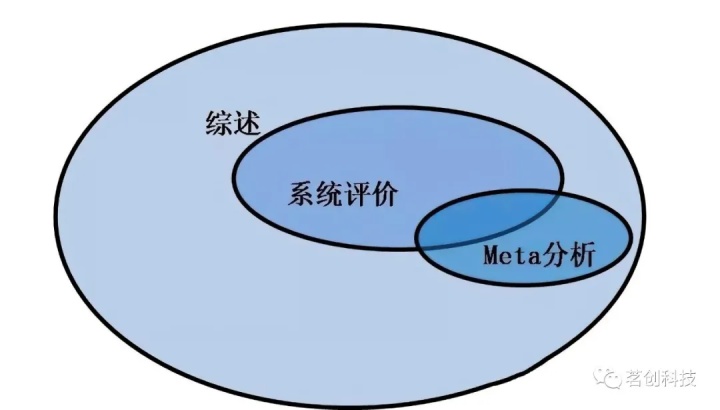
什么是元分析?
元分析 (Meta-Analysis) 统计方法是对众多现有实证文献的再次统计,通过对相关文献中的统计指标利用相应的统计公式,进行再一次的统计分析,从而可以根据获得的统计显著性等来分析两个变量间真实的相关关系。
元分析与传统综述的区别
元分析是用统计的概念与方法,去收集、整理与分析之前学者专家针对某个主题所做的众多实证研究,希望能够找出该问题或所关切的变量之间的明确关系模式,可弥补传统文献综述 Review Articles 的不足。

元分析过程
文献搜集:综合使用中、英文文献数据库对相关文献进行检索。中文文献数据库一般包括四个来源,即中国知网(CNKI) 、维普数据库、万方数据库、中国优秀硕博士学位论文数据库。英文文献主要使用Web of Science、Science Direct、SpringerLink、PubMed、PsycARTICLES、ElsevierSD、Wiley、Emerald、Psychology and Behavior Science Collection数据库、ProQuest博硕士论文全文数据库、SCI数据库、互联网google学术等进行检索。小伙伴们根据自己要研究的内容将相关中文、英文关键词在这些数据库进行全面检索。对于已经搜索到但没有研究内容的文献,则通过馆际互借的方式获得。
文献筛选:一般元分析会选取所要研究的相关内容的关键词从出现之初到目前的所有文献;或者近10-20年的文献。文献选取的标准大致分为:①文献涉及你所需要研究的内容,并且是实证研究、数据完整、样本大小明确、排除纯理论和文献综述类文章;②文献中报告的你感兴趣的研究内容来源于被试本人,即只包括同源数据,不包括异源数据;③一般所涉及的被试为正常群体(其他群体,如精神病人则具体看你所要研究的内容而定);④文献中指明测量工具且有据可查,数据重复发表的只取其一,使用非标准化方法和其他测量工具的文献被排除在外;⑤文献详细报告了 r 值或可以转化为 r 值的 F 值、t 值或 χ2值,排除运用结构方程模型、回归分析以及其它统计方法获得的数据。最终获得符合要求的文献。

文献检索和筛选流程图
文献编码:根据所要探讨的问题和感兴趣的研究内容对文献数据进行编码:①文献信息,如作者名和发表年限;②总样本量、被试年龄和性别(如男为1,女为2);③研究使用的工具类型;④被试的发展阶段(学前期、儿童中期、青春期、成年期);⑤被试特征;⑥文化背景;⑦相关系数等。文献编码的有效性通过采用一名编码者进行两次编码的编码者一致性系数,或者两位编码者的一致性来进行评估。
数据分析与处理:一般是以相关系数 r 作为元分析的计算值,前期可以使用 Excel 与 SPSS 进行文献的整理与编码过程,元分析过程通常采用CMA 2.0软件或者 R 语言进行元分析的统计计算,最后使用 SPSS,Mplus 等对效果量进行调节效应检验。(常用的元分析软件推荐:CMA、Meta Win、EasyEA、RevMan、Meta-Disc、EpiMeta、R、Stata、SAS、NCSS、WinBUGS)
元分析方法
异质性检验:元分析有两种效应模型可以选择,随机效应模型 (Random Effect Model) 和固定效应模型 (Fixed Effect Model),当效应值显著时应采用随机效应模型,反之则选用固定效应模型。所以为了进一步从实证角度检验每一个研究结果是否可以代表总体效应量的样本估计,需要进行异质性检验。如果各个研究之间不同质,则选择随机效应模型进行元分析会更加合适。
发表偏差检验:发表偏差是指在收集文献的过程中,研究者可能只收集了已经出版的文献,而遗漏了未出版的文献,这样会导致元分析的效应值高于真实值。因此,发表偏差检验主要是用于探测研究者所选取的文献是否具有全面性和代表性,纳入文献 10 篇以上就需要做发表偏差检验。可以采用漏斗图 (Funnel Plot)、失安全系数 (fail-safe N)、剪贴法 (Trim and Fill) 来评估出版偏差。由于漏斗图可能具有主观评判性或者有个别研究偏离漏斗图的置信区间,因此可以用 Begg’s 检验和 Egger’s 检验等进一步检验漏斗图的对称性。以漏斗图为例,如果元分析所选取的文献大都集中在漏斗图上方,处于下方的文献很少,并且文献均匀的分布在两侧,基本呈对称趋势,这表明元分析存在出版偏差的可能性较小。
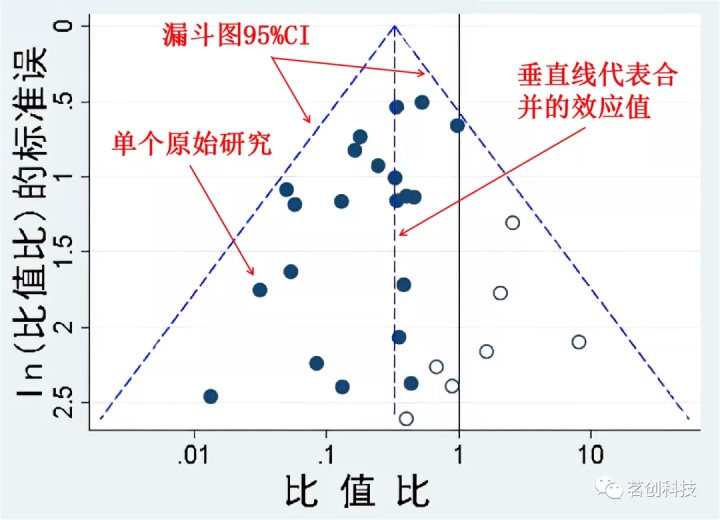
漏斗图
主效应检验:采用随机效应模型或固定效应模型考察研究变量间的整体性关联程度后,得出相关系数,效应量及其置信区间。主效应检验其实是在有一个或几个因子(自变量)的多水平的实验中,描述一个因子在各水平上对因变量影响大小的度量。对有 S个水平的单因子 A 的试验,若随机变量 yij 是在第j次试验中于第 i 个水平上的观测值,则模型为:

调节效应检验:调节效应和中介效应都是在寻找三个以上变量之间的作用机制。中介效应探讨的是自变量通过中介变量对因变量的作用。而调节效应关注的是调节变量与自变量的交互作用对于因变量的作用,可以理解为调节自变量与因变量关系的方向和大小。如果因变量 Y 和自变量 X 的关系(回归斜率的大小和方向)随第三个变量 Z 的变化而变化,则称 Z 在 X 和 Y 之间起调节作用,此时称 Z 为调节变量(见下图 a)。当 X 和 Z 都可以作为定距变量时,调节效应可以通过下面回归方程进行分析(见下图 b 是相应的路径图)。

调节效应的效果量用△R2=R12 - R02 表示,其中R12表示回归方程的测定系数,R02表示去掉乘积项 XZ 后的回归方程的测定系数。
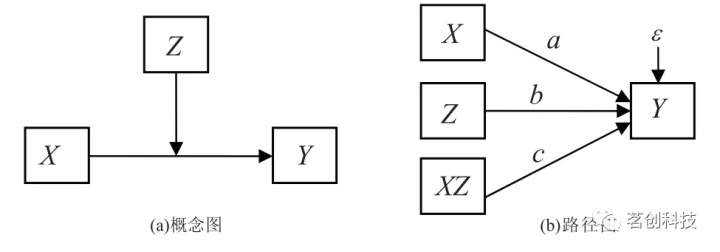
调节效应模型图
元回归分析(MRA)方法:元回归分析需要选择一个代表统计量,并将其转化为统一的可比较的尺度。应在考虑“代表统计量的分布类型是否具有潜在的异方差与文献的自由度间的关系”等基础上,决定好入选的各文献拟采用什么代表统计量,如回归系数、弹性系数、t 值、χ2值、F 值以及其他的一些统计值等。在转化为一个统一的可比较的尺度的方法上,元回归分析一般不使用元分析中普遍采用的“效应值”,而使用其他的统计值,如Lipak(1958) 提出的标准正态分布、Maddala(1977) 提出的t统计值等。可以构建元回归分析的基本模型:bj = β+ ∑Kk = 1αk Zjk + ej ( j = 1,2,⋯L)。其中,因变量 bj 为“统一尺度值”,是第j篇文献中的所关心的变量的系数估计值(即一般回归模型中的 β值);自变量(也称为“调节变量”) Zjk 代表原始实证文献中所涉及到的一些重要特征,如各研究所使用的不同数据集、不同模型的哑变量/虚拟变量等,但由于不同的研究往往采用了不同的数据集、自变量和时间段,因而在有限的研究文献数量的样本空间里,不可能包括所有的这些特征,需要有重点的选择。其系数 αk 可用来解释特定文献中某一特征与其他文献的偏离效应,ej 是元回归分析的随机扰动项。模型中的 β 则是我们所关注的真正的参数估计值。
结构方程模型:结构方程模型,又称为潜变量模型或协方差结构模型。它是一种先根据理论文献或经验法则构建具有因果关系的假设模型图,然后从一种假设的理论架构出发,通过采集变量数据,来验证这种设定的结构关系或模型假设的合理性和正确性,也就是检验样本实际协方差和理论协方差之间的差距,并试图缩到最小的过程。它建立在传统分析方法的基础上,是对验证性因素分析、路径分析和因子分析等统计分析方法进行的综合运用和整合改进,研究观测变量与潜变量,及潜变量与潜变量之间的关系,从微观个体出发探索事物间的宏观因果规律,并将这种关系用路径分析图反映出来的一种模型。路径图反映各变量之间存在的关系,对于路径图中的任意两个变量 x 和 y,存在四种可能的关系:①若 x 影响 y,y 不影响 x,那么它们之间是一条由 x 指向 y 的单箭头线;②若 x 影响 x,x 不影响 y,那么它们之间是一条由 y 指向 x 的单箭头线;③若 x 影响 y,同时y也影响x,那么 x 和 y 之间是一条双箭头线;④若 x 和 y 之间没有确定的因果关系,而有相关关系,那么 x 和 y 之间由一个带箭头的弧线相连。
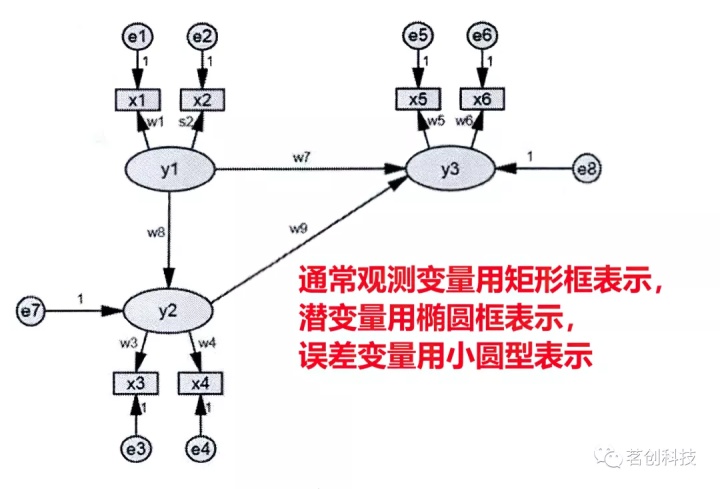
简单路径图示例
注:虽然 Meta 分析作为一种结合独立研究的统计学方法,具有传统综述不可比拟的优越性。但是再好的 Meta 分析也不能代替独立研究,独立的研究是 Meta 分析的基础。而且 Meta 分析只是一种统计工具,不可能将那些本身有问题的研究结果合成一个好的结果。所以在解释 Meta 分析的结果上也应尽可能做到正确、客观、真实。
更多资讯看下图

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









