









《Real-time Facial Animation on Mobile Devices》
作者:Yanlin Weng, Chen Cao, Qiming Hou, Kun Zhou
来源:浙大
时间:2014
文章目录
0 Abstract
本文提出了一种高性能的,可实时运行在移动设备上的面部动画系统(facial animation system)。新颖的回归算法可直接从2D的视频图像中回归出人脸运动参数(facial motion parameters)
相较文献【1】(也是本团队论文)采用的人脸形状回归算法(facial shape regression algorithm)(分2步:首先回归出3D关键点,然后计算头部姿态和表情系数)相比,本文直接回归出头部姿态(head poses)和表情系数(expression coefficients),大大减少了回归目标的系数维度,显著提高了跟踪过程性能,同时保持了跟踪精度
收集不同光照下的训练数据,并训练处出特定用户的回归器(user-specific regressor),使得设备可以有效地适应频繁多变的光照环境
1 Introduction
面捕技术常常基于特殊设备,如人脸标记点,结构光,相机阵列等,显然这种法式在使用有些束缚;随着移动设备的普及,基于单摄像头的人脸动画系统将在视频聊天,社交网络,网络游戏等诸多应用中发挥重要作用
根据怎样从视频中提取人脸特征,跟踪算法分为2类主流:优化类和回归类(optimization based and regression-based)
基于优化的方法总能得到特征和图像表现之间的拟合能量相匹配误差,如文献【9,10】的AAM(Active Appearance Model)方法;回归算法如文献【13】直接回归关键点,不用形状模型,通过最小化训练集的对其误差
这些方法都尝试找到一个通用的方法来跟踪面部特征,但是它们都没有产生令人满意的结果,特别是在面对非正面和夸张表情时
文献【2】提出了基于Kinect,利用深度和颜色信息的实时人脸动画系统,但它适用于室内环境且依赖深度摄像头
文献【1】,见上,提出的3D形状回归,可以适应于刚性变换( rigid transformation)和非刚性blendshape系数(non-rigid blendshape coefficients),可以映射向任何数字化头像(digital avatar)
2 Facial Motion Regression
本文人脸运作参数回归算法是在文献【1】的3D人脸形状回归算法基础上的延展;文献【1】中回归目标是3D人脸形状,本文是人脸运动参数(描述刚性和非刚性人脸运动)
2.1. Training Data Preparation
1)Image capturing and labelling
首先:采集60张预定义的用户人脸姿态和表情
然后:75个特征点,可以用文献【13】中的模型自动标记+手动修正,如下图

2)User-specific blendshape generation
利用这些带标签的数据和FaceWarehouse数据集,可以提取User-specific blendshape(B)和相机内参intrinsic matrix (Q),通过最小化能量函数:

参数Q,Wid,Wexp,Mi为未知参数,求解方法见文献【1】,相机内参Q
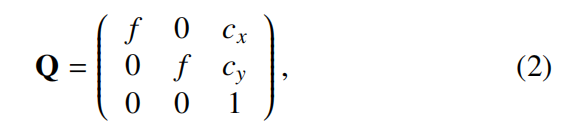
expression blendshapes{Bi}
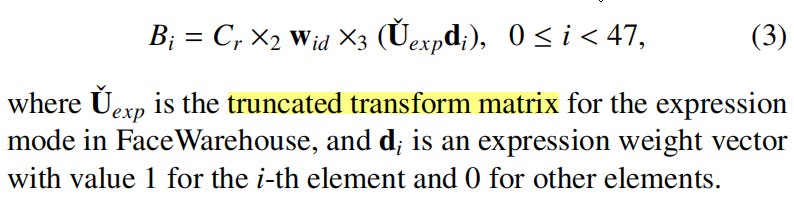
3)Motion parameter recovery
基于blendshape和相机内参,可以恢复3D人脸mesh,然后针对每张图,最小化3D特征定点的投影误差,求解出人脸运动参数
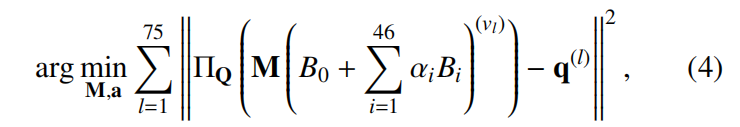
其中,
α
\alpha
α为46维的表情系数,这里要求生成的blendshape系数与预先定义的表情系数一致,所有增加正则化项
∣
∣
α
−
α
∗
∣
∣
2
||\alpha - \alpha^* ||^2
∣∣α−α∗∣∣2
刚性变换矩阵M包括一个4D旋转4元素向量R和3D变换向量,共计46+4+3=53D向量
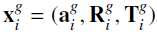
2.2. Training Set Construction
对每张训练图像 I i I_i Ii来说,都有与之相匹配的运动参数向量 X i g X_i^g Xig(motion parameter vector),而这里的参数向量由上述的3部分组成,训练中并对样本进行数据增强

将增强的数据标记为: X i j c X_{ij}^c Xijc,则训练数据可表示为: ( I i , x i , x i c ) {(I_i,x_i,x_i^c)} (Ii,xi,xic)
2.3. Regressor training
对于N个训练样本,基于图像 I i I_i Ii像素训练 x i x_i xi从 x i c x_i^c xic到的运动参数回归函数;采用的是2级boost回归算法(two-level boosted regression algorithm),如

第1级,从当前运动参数
x
i
c
x_i^c
xic中重建3D关键点,并采用像素构建外观向量(appearance vector)
第2级,基于外观向量,更新当前运动参数
x
i
c
x_i^c
xic,以最小化
x
i
x_i
xi与
x
i
c
x_i^c
xic的误差
1)Appearance vector generation
第1级中,我们需要在人脸mesh网格中随机生成p点,并用它们采样图像;每个点表示为:索引-偏移对(
k
p
,
d
p
k_p,d_p
kp,dp),在这里,kp表示关键点索引,dp表示偏移量;根据经验,我们随机选择kp,具体见文献【1】
对每个训练样本,首先对静止姿态(rest pose),即没有旋转和变换,重建3D关键点:
S
i
c
=
{
s
i
k
c
}
S_i^c = \left \{s_{ik}^c\right\}
Sic={sikc},通过
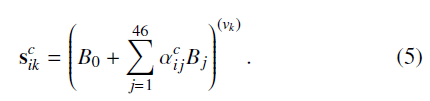
再通过变换3D点,并通过映射函数变换点到图像空间:
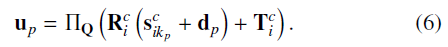
然后根据Up值,构建外观向量:
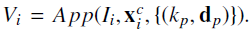
对单个Vi,生成 p 2 p^2 p2个索引对特征
第2级中,根据Vi,同累加法构建一组弱回归器,使得 x i x_i xi与 x i c x_i^c xic的误差最小化;为了训练这些弱回归器,需要有效选择特征,从 p 2 p^2 p2个索引对特征中。
2)Feature selection
特征选择与回归目标高度相关,首先随机生成53D向量Y,然后对个样本,计算误差向量
δ
x
i
=
x
i
−
x
i
c
\delta x_i = x_i - x_i^c
δxi=xi−xic,再将误差向量投影到Y得到一个标量,最后选择与该标量高度相关的索引对
在这里由于,53D向量中三者,处于不同量级,所以不能同等对待,根据经验,本文为其设置不同权重:

3)Fern construction
重复F次选择F个索引对特征,对每个特征,在外观向量区间值中,设置随机阈值;特征和阈值被用来构建原始回归起,称为:fern
对每个fern,计算F个索引对特征和阈值,并鉴定它们属于特征空间的那个bin;对每个bin,对属于该bin的训练数据表示为
Ω
b
\Omega_b
Ωb,然后尝试寻找偏移量使得
x
i
x_i
xi与
x
i
c
x_i^c
xic的误差最小化,表示为:
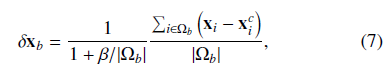
并用这个偏移量跟新 x i c x_i^c xic
2.4. Runtime Regression
利用最后一节训练的人脸运动回归器,可以实时计算视频帧
I
I
I的人脸运动参数,从前一帧的回归结果
x
′
x'
x′开始,从训练集中找到与
x
′
x'
x′相似的运作参数作为回归的初始参数
1)Initial parameters
与训练相似,首先重建3D关键点向量
S
′
=
{
s
k
′
}
S' = \left\{s_k'\right\}
S′={sk′},它基于前一帧参数向量
v
′
v'
v′:
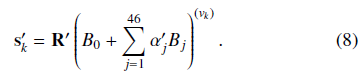
2)Appearance vector
与训练相似
3)Fern passing
与训练相似,详见算法流程:

3 Handling Lighting Changes

4 Experimental Results















 2189
2189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









