







方阵
1.正交矩阵
2.非奇异矩阵 A为满秩 (所有的列都是线性无关的) det(A) 0
3.奇异矩阵 A不是满秩
对称矩阵 (方阵)
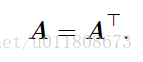
可对角化矩阵
满秩矩阵,即非奇异矩阵

特征分解
非奇异矩阵才满足特征分解的条件
矩阵的迹
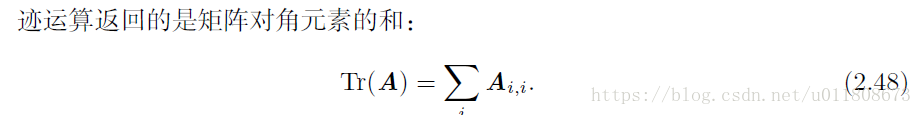

特征分解

最终结论:
如果A 为对称矩阵,则 得到的 V 为正交矩阵,否者不是,因为 AT*A 是对称矩阵,所以SVD分解(奇异值分解)得到的奇异值向量组成的矩阵为正交向量。
设A为n阶对称阵,则必有正交阵P,使得
P-1AP= PTAP = Λ
Λ是以A的n个特征值为对角元的对角阵(只有对角有值,其余为0 例如 diag(lambda))。
该变换称为“合同变换”,A和Λ互为合同矩阵。
伪逆

对于矩阵A 的 特征值lamdb求和 = tr(A), 特征值 lamdb 乘积 = det(A)
从线性空间的角度看,在一个定义了内积的线性空间里,对一个N阶对称方阵进行特征分解,就是产生了该空间的N个标准正交基,然后把矩阵投影到这N个基上。N个特征向量就是N个标准正交基,而特征值的模则代表矩阵在每个基上的投影长度。
特征值越大,说明矩阵在对应的特征向量上的方差越大,功率越大,信息量越多。
应用到最优化中,意思就是对于R的二次型,自变量在这个方向上变化的时候,对函数值的影响最大,也就是该方向上的方向导数最大。
应用到数据挖掘中,意思就是最大特征值对应的特征向量方向上包含最多的信息量,如果某几个特征值很小,说明这几个方向信息量很小,可以用来降维,也就是删除小特征值对应方向的数据,只保留大特征值方向对应的数据,这样做以后数据量减小,但有用信息量变化不大。
——————————————————举两个栗子——————————————————
应用1 二次型最优化问题
二次型,其中R是已知的二阶矩阵(二阶求导矩阵,Hessian Matrix),R=[1,0.5;0.5,1],x是二维列向量,x=[x1;x2],求y的最小值。
求解很简单,讲一下这个问题与特征值的关系。
对R特征分解,特征向量是[-0.7071;0.7071]和[0.7071;0.7071],对应的特征值分别是0.5和1.5。
然后把y的等高线图画一下
从图中看,函数值变化最快的方向,也就是曲面最陡峭的方向,归一化以后是[0.7071;0.7071],嗯哼,这恰好是矩阵R的一个特征值,而且它对应的特征向量是最大的。因为这个问题是二阶的,只有两个特征向量,所以另一个特征向量方向就是曲面最平滑的方向。这一点在分析最优化算法收敛性能的时候需要用到。
二阶问题比较直观,当R阶数升高时,也是一样的道理。
应用2 数据降维
兴趣不大的可以跳过问题,直接看后面降维方法。
机器学习中的分类问题,给出178个葡萄酒样本,每个样本含有13个参数,比如酒精度、酸度、镁含量等,这些样本属于3个不同种类的葡萄酒。任务是提取3种葡萄酒的特征,以便下一次给出一个新的葡萄酒样本的时候,能根据已有数据判断出新样本是哪一种葡萄酒。
问题详细描述:UCI Machine Learning Repository: Wine Data Set
训练样本数据:http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
原数据有13维,但这之中含有冗余,减少数据量最直接的方法就是降维。
做法:把数据集赋给一个178行13列的矩阵R,它的协方差矩阵,C是13行13列的矩阵,对C进行特征分解,对角化,其中U是特征向量组成的矩阵,D是特征之组成的对角矩阵,并按由大到小排列。然后,另,就实现了数据集在特征向量这组正交基上的投影。嗯,重点来了,R’中的数据列是按照对应特征值的大小排列的,后面的列对应小特征值,去掉以后对整个数据集的影响比较小。比如,现在我们直接去掉后面的7列,只保留前6列,就完成了降维。这个降维方法叫PCA(Principal Component Analysis)。
下面看结果:
这是不降维时候的分类错误率。
这是降维以后的分类错误率。
结论:降维以后分类错误率与不降维的方法相差无几,但需要处理的数据量减小了一半(不降维需要处理13维,降维后只需要处理6维)。N个标准正交基,然后把矩阵投影到这N个基上。N个特征向量就是N个标准正交基,而特征值的模则代表矩阵在每个基上的投影长度。
特征值越大,说明矩阵在对应的特征向量上的方差越大,功率越大,信息量越多。
应用到最优化中,意思就是对于R的二次型,自变量在这个方向上变化的时候,对函数值的影响最大,也就是该方向上的方向导数最大。
应用到数据挖掘中,意思就是最大特征值对应的特征向量方向上包含最多的信息量,如果某几个特征值很小,说明这几个方向信息量很小,可以用来降维,也就是删除小特征值对应方向的数据,只保留大特征值方向对应的数据,这样做以后数据量减小,但有用信息量变化不大。
——————————————————举两个栗子——————————————————
应用1 二次型最优化问题
二次型,其中R是已知的二阶矩阵(二阶求导矩阵,Hessian Matrix),R=[1,0.5;0.5,1],x是二维列向量,x=[x1;x2],求y的最小值。
求解很简单,讲一下这个问题与特征值的关系。
对R特征分解,特征向量是[-0.7071;0.7071]和[0.7071;0.7071],对应的特征值分别是0.5和1.5。
然后把y的等高线图画一下
从图中看,函数值变化最快的方向,也就是曲面最陡峭的方向,归一化以后是[0.7071;0.7071],嗯哼,这恰好是矩阵R的一个特征值,而且它对应的特征向量是最大的。因为这个问题是二阶的,只有两个特征向量,所以另一个特征向量方向就是曲面最平滑的方向。这一点在分析最优化算法收敛性能的时候需要用到。
二阶问题比较直观,当R阶数升高时,也是一样的道理。
应用2 数据降维
兴趣不大的可以跳过问题,直接看后面降维方法。
机器学习中的分类问题,给出178个葡萄酒样本,每个样本含有13个参数,比如酒精度、酸度、镁含量等,这些样本属于3个不同种类的葡萄酒。任务是提取3种葡萄酒的特征,以便下一次给出一个新的葡萄酒样本的时候,能根据已有数据判断出新样本是哪一种葡萄酒。
问题详细描述:UCI Machine Learning Repository: Wine Data Set
训练样本数据:http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
原数据有13维,但这之中含有冗余,减少数据量最直接的方法就是降维。
做法:把数据集赋给一个178行13列的矩阵R,它的协方差矩阵,C是13行13列的矩阵,对C进行特征分解,对角化,其中U是特征向量组成的矩阵,D是特征之组成的对角矩阵,并按由大到小排列。然后,另,就实现了数据集在特征向量这组正交基上的投影。嗯,重点来了,R’中的数据列是按照对应特征值的大小排列的,后面的列对应小特征值,去掉以后对整个数据集的影响比较小。比如,现在我们直接去掉后面的7列,只保留前6列,就完成了降维。这个降维方法叫PCA(Principal Component Analysis)。
下面看结果:
这是不降维时候的分类错误率。
这是降维以后的分类错误率。
结论:降维以后分类错误率与不降维的方法相差无几,但需要处理的数据量减小了一半(不降维需要处理13维,降维后只需要处理6维)。
无穷范数 ,也是 最大范数
F范数,矩阵的各元素平方和。



















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











