







具备自纠正和逐维学习能力的粒子群算法
文章目录
摘要:粒子群算法作为一种随机算法,其随机性对种群的进化速度和寻优精度提出了严峻的挑战.针对该问题,本文提出了一种具备自纠正和逐维学习能力的粒子群算法.首先提出了一种纠正策略来判断粒子进化趋势的正确性并作出必要干预,减少了随机性所带来的学习时间的浪费;其次,在使用逐维变异策略的基础上利用个体最优作为最优粒子的学习对象,加强个体最优与群体最优之间的联系,赋予粒子更多的有效信息来源;最后,结合两策略的特点,周期性地控制其触发时间,进而降低复杂度使得算法发挥更大的效能.
1.粒子群优化算法
基础粒子群算法的具体原理参考网络资料
2. 改进粒子群算法
2.1 纠正策略
传统 PSO 中粒子在进化过程中按照公式(1)和公式(2)进行速度和位移更新, 粒子在进化过程中受个体最优 (Pbest) 和群体最优 (Gbest) 的指导, 缺乏对粒子整个运动过程的关注, 特别是在寻优难度辆大的复杂多峰函数上, 使得粒子在进 化过程中产生很大的随机性, 这是导致粒子群算法收敛速度慢的重要原因之一.
V
i
′
+
1
=
w
⋅
V
i
′
+
c
1
⋅
r
1
⋅
(
Pbest
t
i
′
−
X
i
′
)
+
c
2
⋅
r
2
⋅
(
Gbest
i
′
−
X
i
′
)
(1)
V_{i}^{\prime+1}=w \cdot V_{i}^{\prime}+c_{1} \cdot r_{1} \cdot\left(\text { Pbest } t_{i}^{\prime}-X_{i}^{\prime}\right)+c_{2} \cdot r_{2} \cdot\left(\text { Gbest }_{i}^{\prime}-X_{i}^{\prime}\right)\tag{1}
Vi′+1=w⋅Vi′+c1⋅r1⋅( Pbest ti′−Xi′)+c2⋅r2⋅( Gbest i′−Xi′)(1)
X
i
t
+
1
=
X
i
t
+
V
i
t
(2)
X_{i}^{t+1}=X_{i}^{t}+V_{i}^{t}\tag{2}
Xit+1=Xit+Vit(2)
比如在种群进化过程中可能存在这种情况: 柆子初始运 动方向是向着最优解的方向前进的, 但由于寻优过程的复余 性, 接下来的某代上却朝看偏离最优解的方向移动, 此时若继 续按照公式 (1)、公式 (2) 更新逮度和位移, 受由上一代部分 粒子随机飞行而产生的错误信息指导, 必然浪费粒子学习时 间,导致收敛速度变㥅.
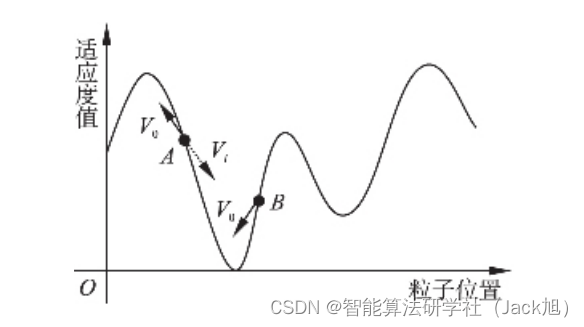
为了解决这个问题, 提出了一种纠正策咯, 即通过监督粒 子在整个进化过程中运动方向的变化情况, 对粒子下一代寻 优方向实施干预以避免其继续受到错误指导, 从而提高种群收敛速度. 图 1 给出了纠正策略的筒单示意图. 图中
A
\mathrm{A}
A 类粒 子表示受到了随机性和错误指导的影响的粒子, 其下一代更 新将偏离最优解的方向, 使用公式 (3) 更新速度, 将速度向量 方向取反, 使得下一代能够向看最优解的方向移动, 提高收敛速度, 位置更新使用公式 (2); 同时, 运动方向正确的
B
\mathrm{B}
B 类粒 子则将继续按照原有的方式进行更新.
V i t + 1 = − 1 ⋅ ( w ⋅ V i t + c 1 ⋅ r 1 ⋅ ( Pbest i t − X i t ) + c 2 ⋅ r 2 ⋅ ( Gbest i t − X i t ) ) (3) V_{i}^{t+1}=-1 \cdot\left(w \cdot V_{i}^{t}+c_{1} \cdot r_{1} \cdot\left(\text { Pbest }_{i}^{t}-X_{i}^{t}\right)+c_{2} \cdot r_{2} \cdot\left(\text { Gbest }_{i}^{t}-X_{i}^{t}\right)\right) \tag{3} Vit+1=−1⋅(w⋅Vit+c1⋅r1⋅( Pbest it−Xit)+c2⋅r2⋅( Gbest it−Xit))(3)
2.2 Pbest 指导 Gbest 的逐维学习策略
目前在大部分研究中, 对种群中最优粒子指导方面都采 用了选取所有维度整体更新再评价的策略, 但对于复杂的多 维函数的优化问题, 使用这种方法会由于维间的相互千扰导 致某些正确进化维度的信息被掩盖, 从而导致评价次数的浪 费, 降低算法的收玫速度和效率. 而逐维学习策略将最优解和 学习对象在维度上进行拆分, 独立的对每一维度上的信息进 行考察,能够有效避免维间千扰的问题.
在 PSO 中, 随着种群的进化, 每个粒子的 Pbest 都在不断 更新, 它记录并更新着在飞行过程中的历史最佳表现, 利用价 值高. 因此为了保证逐维策略中学习对象的多样性和有效性, 本文结合 Pbest 的特点和逐维策略的优势提出了一种 Pbest 指导 Gbest 的逐维学习策略.
图 2 给出了本策略的模型示意图. 图中引入了数据结构 中的压栈与出栈操作模拟种群中所有 Pbest 逐个的对最优粒子进行指导的动作.
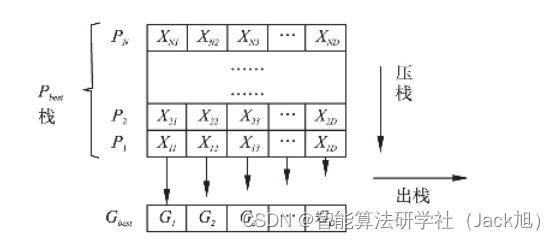
该策略的思想是:按维度分解 Gbest 和 Pbest 位置向量,将 Pbest 上某一维的值和 Gbest 上其他维的值组成新的Gbest;计算适应度值评价新解;若当前新解质量更优则保留Pbest该维度信息对解的更新结果;否则放弃当前维度值,保留原 Gbest 维度信息不变. 采用这样的贪心评价方式,直到各维度更新完毕. 当一个 Pbest 的所有维上的信息都对 Gbest 的相应维指导结束后,执行出栈操作离开 Pbest 栈容器,并对Pbest 栈容器进行压缩,开始其他 Pbest 对 Gbest 的指导.
通过在逐维学习策略中引入贪心评价策略,彻底消除了某些维上出现退化的情况,避免了进化维度信息被掩盖的的问题,从而获得更高质量的解,显著提高收敛精度. 同时,与大多数逐维学习策略中所采用的向某个单一对象学习的方式不同,该策略中 Gbest 受种群个体 Pbest 的指导影响,加强了个体最优粒子与群体最优粒子之间的联系,提高了最优粒子学习对象的多样性.
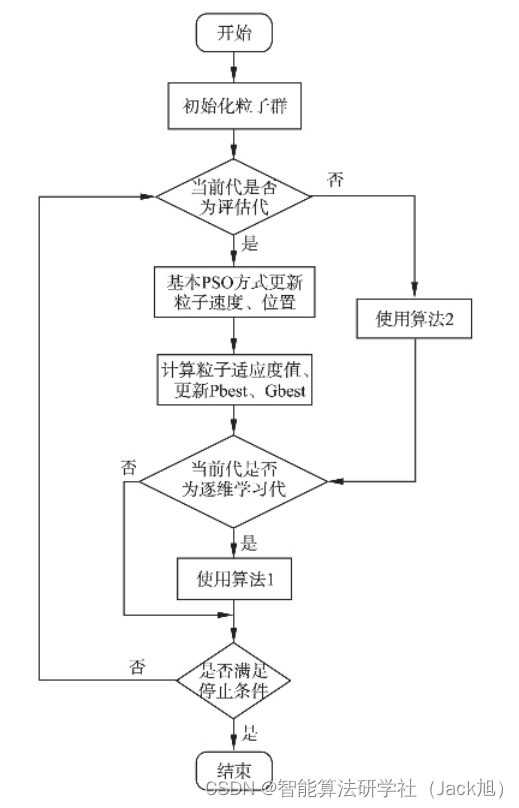
具备自纠正和逐维学习能力的 PSO(SCDLPSO)的算法流程如下:
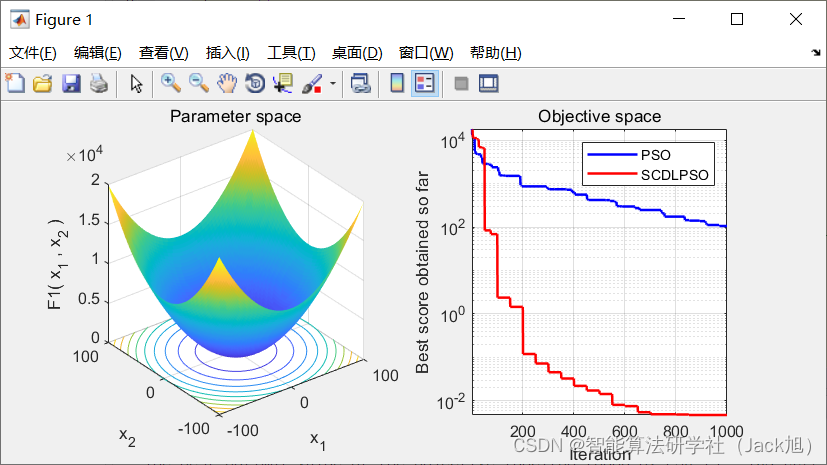
3.实验结果
4.参考文献
[1]张津源,张军,季伟东,孙小晴,张珑.具备自纠正和逐维学习能力的粒子群算法[J].小型微型计算机系统,2021,42(05):919-926.



















 2495
2495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











