







多策略黑猩猩优化算法
文章目录
摘要:针对基本黑猩猩优化算法存在的依赖初始种群、易陷入局部最优和收敛精度低等问题,提出一种多策略黑猩猩优化算法(Chaotic Elite Opposition-Based Simple Method Improved COA,EOSMICOA)。在EOSMICOA算法中,利用混沌精英反向学习策略对黑猩猩个体位置进行初始化,提高种群的多样性和质量,同时在位置更新过程中利用单纯形法和群个体记忆机制对较差个体进行改进,进一步提高算法的局部开发能力和勘探能力,提高算法的寻优精度。
1.黑猩猩优化算法
基础黑猩猩优化算法的具体原理参考,我的博客:https://blog.csdn.net/u011835903/article/details/119649041
2. 改进黑猩猩优化算法
2.1 混沌反向学习策略初始化种群
本文采用 Iteration 混沌映射。Iteration 映射数学表达式如下:
x
n
+
1
=
sin
(
b
π
/
x
n
)
(6)
x_{n+1}=\sin \left(b \pi / x_n\right) \tag{6}
xn+1=sin(bπ/xn)(6)
其中,
b
b
b 为控制参数,
b
∈
(
0
,
1
b \in(0,1
b∈(0,1, 文中设定
b
=
0.7
b=0.7
b=0.7
首先, 通过 Iteration 映射生成
N
N
N 个
d
d
d 维初始解
X
i
,
j
,
(
i
=
1
,
2
,
…
,
N
;
j
=
1
,
2
,
…
,
d
)
X_{i, j},(i=1,2, \ldots, N ; j=1,2, \ldots, d)
Xi,j,(i=1,2,…,N;j=1,2,…,d), 其次, 对当前种 群中个体初始解进行排序, 选择对应的自身极值点作 为精英个体
X
i
,
j
e
=
(
X
i
,
1
e
,
X
i
,
2
e
,
…
,
X
i
,
d
e
)
X_{i, j}^e=\left(X_{i, 1}^e, X_{i, 2}^e, \ldots, X_{i, d}^e\right)
Xi,je=(Xi,1e,Xi,2e,…,Xi,de), 按照公式 (6) 生成混沌精英反向解
X
i
,
j
e
‾
=
(
X
i
,
1
e
‾
,
X
i
,
2
e
‾
,
…
,
X
i
,
d
e
‾
)
\overline{X_{i, j}^e}=\left(\overline{X_{i, 1}^e}, \overline{X_{i, 2}^e}, \ldots, \overline{X_{i, d}^e}\right)
Xi,je=(Xi,1e,Xi,2e,…,Xi,de), 并按照公式 ( 7) 设置动态边界以规范越界的位置点。
X
i
,
j
e
‾
=
k
∗
(
α
j
+
β
j
)
−
X
i
,
j
e
(7)
\overline{X_{i, j}^e}=k^*\left(\alpha_j+\beta_j\right)-X_{i, j}^e \tag{7}
Xi,je=k∗(αj+βj)−Xi,je(7)
X
i
,
j
e
‾
=
rand
(
α
j
,
β
j
)
,
X
i
,
j
e
‾
<
α
j
,
X
i
,
j
e
‾
<
β
j
(8)
\overline{X_{i, j}^e}=\operatorname{rand}\left(\alpha_{\mathrm{j}}, \beta_j\right), \overline{X_{i, j}^e}<\alpha_j,\overline{X_{i, j}^e}<\beta_j \tag{8}
Xi,je=rand(αj,βj),Xi,je<αj,Xi,je<βj(8)
其中精英反向系数
k
∈
(
0
,
1
)
,
α
j
=
min
(
X
i
,
j
e
)
k \in(0,1), \alpha_j=\min \left(X_{i, j}^e\right)
k∈(0,1),αj=min(Xi,je) 和
β
j
=
max
(
X
i
,
j
e
)
\beta_j=\max \left(X_{i, j}^e\right)
βj=max(Xi,je) 。
最后将混沌生成的所有初始解和混沌精英反向解 合并进行排序, 选取前
N
N
N 个较优的解作为初始种群。
2.2 单纯形法
单纯形法是一种不受目标函数连续性和可导性影 响的直接搜索算法, 其主要通过迭代判断最差顶点 X s X_s Xs 向优运动的方向向量 g g g 是否正确, 并通过对最差 顶点进行反射、扩张、外收缩和内收缩操作来控制其 运动。
具体流程如下:
I 计算种群的适应度值, 并将最优的 4 个位置分别 适应度值为
f
(
X
Attacker
)
、
f
(
X
Barrier
)
、
f
(
X
Chaser
)
f\left(X_{\text {Attacker }}\right) 、 f\left(X_{\text {Barrier }}\right) 、 f\left(X_{\text {Chaser }}\right)
f(XAttacker )、f(XBarrier )、f(XChaser ) 和
f
(
X
Driver
)
f\left(X_{\text {Driver }}\right)
f(XDriver ), 设 中 心 位 置 为
X
c
=
(
X
A
t
t
a
c
k
e
r
+
X
)
X_c=\left(\quad X_{Attacker}+\quad X\right)
Xc=(XAttacker+X)
II 将剩下黑猩猩个体的适应度值进行排序, 选择 适应度值最差的个体作为较差点
X
s
X_s
Xs
对较差点
X
s
X_s
Xs 进行反射操作,
X
r
=
X
c
+
α
(
X
c
−
X
s
)
X_r=X_c+\alpha\left(X_c-\mathrm{X}_s\right)
Xr=Xc+α(Xc−Xs)
得到反射点
X
r
X_r
Xr, 反射系数
α
\alpha
α 取 1 。
III 若
f
(
X
r
)
<
f
(
X
Attacker
)
f\left(X_r\right)<f\left(X_{\text {Attacker }}\right)
f(Xr)<f(XAttacker ), 则反射方向正确, 继续执行扩张操作,
X
e
=
X
c
+
β
(
X
r
−
X
c
)
X_e=X_c+\beta\left(X_r-X_c\right)
Xe=Xc+β(Xr−Xc)
得到扩张点
X
e
X_e
Xe, 扩张系数
β
\beta
β 取 2。
若
f
(
X
e
)
<
f
(
X
Attacker
)
f\left(X_e\right)<f\left(X_{\text {Attacker }}\right)
f(Xe)<f(XAttacker ), 则用
X
e
X_e
Xe 代替
X
s
X_s
Xs; 否 则, 用
X
r
X_r
Xr 代替
X
s
X_s
Xs 。
IV 若
f
(
X
s
)
<
f
(
X
r
)
f\left(X_s\right)<f\left(X_r\right)
f(Xs)<f(Xr), 则反射方向错误, 执行 外收缩操作,
X
t
=
X
c
+
γ
(
X
s
−
X
c
)
X_t=X_c+\gamma\left(X_s-X_c\right)
Xt=Xc+γ(Xs−Xc)
得到外收缩点
X
t
X_t
Xt, 外收缩系数
γ
\gamma
γ 取
0.5
0.5
0.5 。
若
f
(
X
t
)
<
f
(
X
s
)
f\left(X_t\right)<f\left(X_s\right)
f(Xt)<f(Xs), 则用
X
t
X_t
Xt 代替较差点
X
s
X_s
Xs 。
V
\mathrm{V}
V 若
f
(
X
Attacker
)
<
f
(
X
r
)
<
f
(
X
s
)
f\left(X_{\text {Attacker }}\right)<f\left(X_r\right)<f\left(X_s\right)
f(XAttacker )<f(Xr)<f(Xs), 则执行内 收缩操作,
X
w
=
X
c
−
γ
(
X
s
−
X
c
)
X_w=X_c-\gamma\left(X_s-X_c\right)
Xw=Xc−γ(Xs−Xc)
得到内收缩点
X
w
X_w
Xw, 内收缩系数
γ
\gamma
γ 取
0.5
0.5
0.5 。
若
f
(
X
w
)
<
f
(
X
s
)
f\left(X_w\right)<f\left(X_s\right)
f(Xw)<f(Xs), 则用
X
w
X_w
Xw 代替较差点
X
s
X_s
Xs; 否则, 用
X
r
X_r
Xr 代替较差点
X
s
X_s
Xs 。
通过运用单纯形法的 4 种操作,可以让最差点在 反射操作下搜索到所有可行的解, 内外收缩操作可以 使最差点摆脱当前位置, 而在扩张操作下可以让最优 解跳出局部最小值, 向距离最差点更远的反方向继续 搜索,从而提高了算法整体的局部开发能力和寻优能 力。由于单纯形法针对的是种群中最差的个体, 对于 种群中其他个体仍然执行黑猩猩原始算法中的随机搜 索, 故而在提高算法的局部搜索能力的同时, 不会降 低种群的多样性。
2.3 群个体记忆机制
在原始 COA 算法中, 通过对群体历史前四个最 优位置的加权记忆, 实现了黑猩猩种群间信息交流, 最终促使个体在搜索空间快速移动寻优, 但这一做法 并末考虑到每个黑猩猩个体自身的搜索经验, 因而, 在结合 COA算法群体信息交流表达式( 5 )的基础上, 引人粒子群算法的个体记忆策略, 具体表达式变为:
X
(
t
+
1
)
=
b
1
∗
(
X
1
+
X
2
+
X
3
+
X
3
)
/
4
+
b
2
∗
rand
1
∗
[
X
best
−
X
(
t
)
]
+
rand
2
∗
[
X
j
(
t
)
−
X
i
(
t
)
]
(9)
\begin{aligned} &X(t+1)=b_1^*\left(X_1+X_2+X_3+X_3\right) / 4 \\ &+b_2^* \operatorname{rand}_1 *\left[X_{\text {best }}-X(t)\right]+\operatorname{rand}_2 *\left[X_j(t)-X_i(t)\right] \end{aligned} \tag{9}
X(t+1)=b1∗(X1+X2+X3+X3)/4+b2∗rand1∗[Xbest −X(t)]+rand2∗[Xj(t)−Xi(t)](9)
其中,
b
1
b_1
b1 和
b
2
b_2
b2 是
[
0
,
1
]
[0,1]
[0,1] 间的常数, 分别表示群体交 流和个体经验记忆的系数; rand 表示
[
0
,
1
]
[0,1]
[0,1] 间的随机 变量;
X
b
e
s
t
X_{b e s t}
Xbest 表示第
i
i
i 只黑猩猩所经历过的最佳位置,
X
j
,
X
i
,
(
j
≠
i
)
X_j, X_i,(j \neq i)
Xj,Xi,(j=i) 是记忆过程中记下的随机个体位置。
通过对
b
1
b_1
b1 和
b
2
b_2
b2 的调节来平衡群体交流和个体记忆对 位置更新的影响。
对比原始位置更新方程式(5), 式(9)增加了两个部 分, 第一个是引人的个体自身记忆信息, 进一步提高 了算法在局部的开发能力和收敛速度, 第二个是随机 记忆的个体位置, 从而起到增强算法种群多样性和全 局勘探的能力。
综上所述, 本文提出 EOSMICOA 算法的运算步 骤如下:
步骤 1: 设置相关参数, 种群规模
N
N
N 、最大迭代 次数
t
max
t_{\text {max }}
tmax 、收敛因子
f
f
f 、影响系数
A
、
C
A 、 C
A、C 、混沌因子
m
m
m 等。
步骤 2: 利用 Iteration 混沌映射和精英反向学习 生成初始种群
X
i
,
i
=
1
,
2
,
…
,
N
X_i, i=1,2, \ldots, N
Xi,i=1,2,…,N 。
步骤 3: 计算个体的适应度值, 并确定历史前四
步骤 4:利用单纯形法改变较差个体
X
s
X_s
Xs 的位置。
步骤 5: 更新
A
、
C
A 、 C
A、C, 按照公式 (5) 计算其他 黑猩猩的位置。
步骤 6: 通过粒子群算法改进的群个体记忆机制, 按照公式 (9) 进一步更新黑猩猩位置。
步骤 7: 判断算法是否达到最大迭代次数, 若达 到, 则算法结束, 输出最优位置
X
Attacker
X_{\text {Attacker }}
XAttacker ; 否则, 执 行步骤 3。
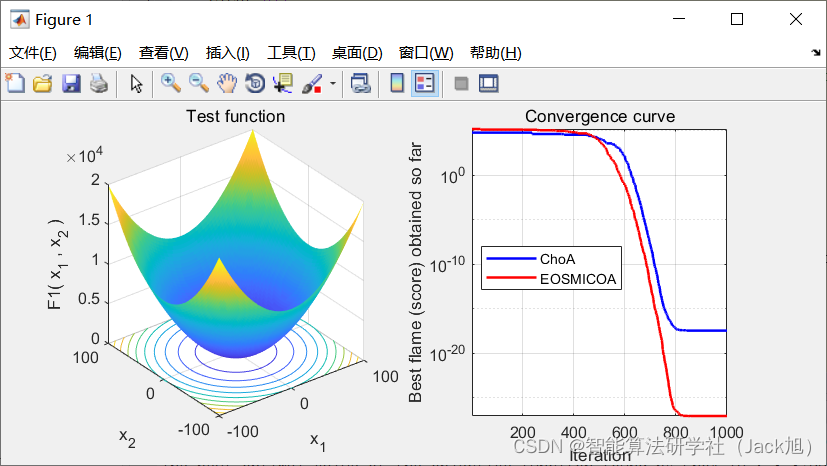
3.实验结果
4.参考文献
[1]黄倩,刘升,李萌萌,郭雨鑫.多策略黑猩猩优化算法研究及其工程应用[J/OL].计算机工程与应用:1-12[2021-10-25].http://kns.cnki.net/kcms/detail/11.2127.TP.20210806.1055.011.html.

















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











