









这里写目录标题
Pytorch提供的十种权值初始化方法
- Xavier均匀分布;
- Xavier正态分布;
- Kaiming均匀分布;
- Kaiming正态分布;
- 均匀分布;
- 正态分布;
- 常数分布;
- 正交矩阵初始化;
- 单位矩阵初始化;
- 稀疏矩阵初始化;
为什么要进行权重初始化设计:从梯度消失与爆炸说起
参考x。可以得出结论: 要避免梯度消失或者梯度爆炸,就要严格控制网络输出层的输出值的范围,也就是每一层网络的输出值不能太大也不能太小。
那么,参数如果使用均匀分布进行初始化,网络每一层的输出结果如何呢,下面通过代码验证BP网络的输出,代码中使用输出Tensor的标准差来衡量数据的尺度范围:
import os
import torch
import random
import numpy as np
import torch.nn as nn
class MLP(nn.Module): # 建立全连接模型
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()): # 如果为nan,则停止
print("output is nan in {} layers".format(i))
break
return x
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data)
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
结果如下:
layer:0, std:15.959932327270508
layer:1, std:256.6237487792969
layer:2, std:4107.24560546875
layer:3, std:65576.8125
layer:4, std:1045011.875
layer:5, std:17110408.0
layer:6, std:275461408.0
layer:7, std:4402537984.0
layer:8, std:71323615232.0
layer:9, std:1148104736768.0
layer:10, std:17911758454784.0
layer:11, std:283574846619648.0
layer:12, std:4480599809064960.0
layer:13, std:7.196814275405414e+16
layer:14, std:1.1507761512626258e+18
layer:15, std:1.853110740188555e+19
layer:16, std:2.9677725826641455e+20
layer:17, std:4.780376223769898e+21
layer:18, std:7.613223480799065e+22
layer:19, std:1.2092652108825478e+24
layer:20, std:1.923257075956356e+25
layer:21, std:3.134467063655912e+26
layer:22, std:5.014437766285408e+27
layer:23, std:8.066615144249704e+28
layer:24, std:1.2392661553516338e+30
layer:25, std:1.9455688099759845e+31
layer:26, std:3.0238180658999113e+32
layer:27, std:4.950357571077011e+33
layer:28, std:8.150925520353362e+34
layer:29, std:1.322983152787379e+36
layer:30, std:2.0786820453988485e+37
layer:31, std:nan
output is nan in 31 layers
tensor([[ inf, -2.6817e+38, inf, ..., inf,
inf, inf],
[ -inf, -inf, 1.4387e+38, ..., -1.3409e+38,
-1.9659e+38, -inf],
[-1.5873e+37, inf, -inf, ..., inf,
-inf, 1.1484e+38],
...,
[ 2.7754e+38, -1.6783e+38, -1.5531e+38, ..., inf,
-9.9440e+37, -2.5132e+38],
[-7.7184e+37, -inf, inf, ..., -2.6505e+38,
inf, inf],
[ inf, inf, -inf, ..., -inf,
inf, 1.7432e+38]], grad_fn=<MmBackward>)
常用的几种权重初始化方法
不考虑激活函数
不加以证明,有如下结论:
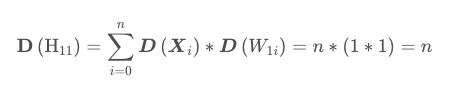
H11表示输出Tensor,X和W分别表示输入和权重。
- 第一个隐藏层的输出值的方差变为n,而输入数据的方差为1,经过一个网络层的前向传播,数据的方差就扩大了n倍,标准差扩大了根号n倍。同理,从第一个隐藏层到第二个隐藏层,标准差就变为n。不断往后传播,每经过一层,输出值的尺度范围都会不断扩大根号n倍,最终超出精度可以表示的范围,最终变为nan
- 标准差由三个因素决定,第一个是n,就是每一层的神经元个数,第二个是X的方差,也就是输入值的方差,第三个是W的方差,也就是网络层权值的方差。
- 方差一致性原则:一般第一层的输入数据进行归一化操作,X符合0均值,1方差,如果想让网络层的输出方差保持1,只能调整W的分布。且W满足下述条件时,符合方差一致性原则。
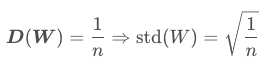
下面采用一个0均值,sqrt(1/n)分布的初始化W进行忘了的前向实验结果如下:
import os
import torch
import random
import numpy as np
import torch.nn as nn
from toolss.common_tools import set_seed
set_seed(1) # 设置随机种子
class MLP(nn.Module): # 建立全连接模型
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()): # 如果为nan,则停止
print("output is nan in {} layers".format(i))
break
return x
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num))
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:0.9974957704544067
layer:1, std:1.0024365186691284
layer:2, std:1.002745509147644
layer:3, std:1.0006227493286133
layer:4, std:0.9966009855270386
layer:5, std:1.019859790802002
layer:6, std:1.026173710823059
layer:7, std:1.0250457525253296
layer:8, std:1.0378952026367188
layer:9, std:1.0441951751708984
layer:10, std:1.0181655883789062
layer:11, std:1.0074602365493774
layer:12, std:0.9948930144309998
layer:13, std:0.9987586140632629
layer:14, std:0.9981392025947571
layer:15, std:1.0045733451843262
layer:16, std:1.0055204629898071
layer:17, std:1.0122840404510498
layer:18, std:1.0076017379760742
layer:19, std:1.000280737876892
layer:20, std:0.9943006038665771
layer:21, std:1.012800931930542
layer:22, std:1.012657642364502
layer:23, std:1.018149971961975
layer:24, std:0.9776086211204529
layer:25, std:0.9592394828796387
layer:26, std:0.9317858815193176
layer:27, std:0.9534041881561279
layer:28, std:0.9811319708824158
layer:29, std:0.9953019022941589
layer:30, std:0.9773916006088257
layer:31, std:0.9655940532684326
layer:32, std:0.9270440936088562
layer:33, std:0.9329946637153625
layer:34, std:0.9311841726303101
layer:35, std:0.9354336261749268
layer:36, std:0.9492132067680359
layer:37, std:0.9679954648017883
layer:38, std:0.9849981665611267
layer:39, std:0.9982335567474365
layer:40, std:0.9616852402687073
layer:41, std:0.9439758658409119
layer:42, std:0.9631161093711853
layer:43, std:0.958673894405365
layer:44, std:0.9675614237785339
layer:45, std:0.9837557077407837
layer:46, std:0.9867278337478638
layer:47, std:0.9920817017555237
layer:48, std:0.9650403261184692
layer:49, std:0.9991624355316162
layer:50, std:0.9946174025535583
layer:51, std:0.9662044048309326
layer:52, std:0.9827387928962708
layer:53, std:0.9887880086898804
layer:54, std:0.9932605624198914
layer:55, std:1.0237400531768799
layer:56, std:0.9702046513557434
layer:57, std:1.0045380592346191
layer:58, std:0.9943899512290955
layer:59, std:0.9900636076927185
layer:60, std:0.99446702003479
layer:61, std:0.9768352508544922
layer:62, std:0.9797843098640442
layer:63, std:0.9951220750808716
layer:64, std:0.9980446696281433
layer:65, std:1.0086933374404907
layer:66, std:1.0276142358779907
layer:67, std:1.0429234504699707
layer:68, std:1.0197855234146118
layer:69, std:1.0319130420684814
layer:70, std:1.0540012121200562
layer:71, std:1.026781439781189
layer:72, std:1.0331352949142456
layer:73, std:1.0666675567626953
layer:74, std:1.0413838624954224
layer:75, std:1.0733673572540283
layer:76, std:1.0404183864593506
layer:77, std:1.0344083309173584
layer:78, std:1.0022705793380737
layer:79, std:0.99835205078125
layer:80, std:0.9732587337493896
layer:81, std:0.9777462482452393
layer:82, std:0.9753198623657227
layer:83, std:0.9938382506370544
layer:84, std:0.9472599029541016
layer:85, std:0.9511011242866516
layer:86, std:0.9737769961357117
layer:87, std:1.005651831626892
layer:88, std:1.0043526887893677
layer:89, std:0.9889539480209351
layer:90, std:1.0130352973937988
layer:91, std:1.0030947923660278
layer:92, std:0.9993206262588501
layer:93, std:1.0342745780944824
layer:94, std:1.031973123550415
layer:95, std:1.0413124561309814
layer:96, std:1.0817031860351562
layer:97, std:1.128799557685852
layer:98, std:1.1617802381515503
layer:99, std:1.2215303182601929
tensor([[-1.0696, -1.1373, 0.5047, ..., -0.4766, 1.5904, -0.1076],
[ 0.4572, 1.6211, 1.9659, ..., -0.3558, -1.1235, 0.0979],
[ 0.3908, -0.9998, -0.8680, ..., -2.4161, 0.5035, 0.2814],
...,
[ 0.1876, 0.7971, -0.5918, ..., 0.5395, -0.8932, 0.1211],
[-0.0102, -1.5027, -2.6860, ..., 0.6954, -0.1858, -0.8027],
[-0.5871, -1.3739, -2.9027, ..., 1.6734, 0.5094, -0.9986]],
grad_fn=<MmBackward>)
饱和型激活函数
饱和型激活函数是指sigmoid、tanh等输入极大或者极小时,导数接近0的激活函数。
在forward()函数中加一个tanh激活函数,观察网络的输出结果:
import os
import torch
import random
import numpy as np
import torch.nn as nn
from toolss.common_tools import set_seed
set_seed(1) # 设置随机种子
class MLP(nn.Module): # 建立全连接模型
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.tanh(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()): # 如果为nan,则停止
print("output is nan in {} layers".format(i))
break
return x
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num))
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
layer:0, std:0.6273701786994934
layer:1, std:0.48910173773765564
layer:2, std:0.4099564850330353
layer:3, std:0.35637012124061584
layer:4, std:0.32117360830307007
layer:5, std:0.2981105148792267
layer:6, std:0.27730831503868103
layer:7, std:0.2589356303215027
layer:8, std:0.2468511462211609
layer:9, std:0.23721906542778015
layer:10, std:0.22171513736248016
layer:11, std:0.21079954504966736
layer:12, std:0.19820132851600647
layer:13, std:0.19069305062294006
layer:14, std:0.18555502593517303
layer:15, std:0.17953835427761078
layer:16, std:0.17485804855823517
layer:17, std:0.1702701896429062
layer:18, std:0.16508983075618744
layer:19, std:0.1591130942106247
layer:20, std:0.15480302274227142
layer:21, std:0.15263864398002625
layer:22, std:0.148549422621727
layer:23, std:0.14617665112018585
layer:24, std:0.13876433670520782
layer:25, std:0.13316625356674194
layer:26, std:0.12660598754882812
layer:27, std:0.12537944316864014
layer:28, std:0.12535445392131805
layer:29, std:0.1258980631828308
layer:30, std:0.11994212120771408
layer:31, std:0.11700888723134995
layer:32, std:0.11137298494577408
layer:33, std:0.11154613643884659
layer:34, std:0.10991233587265015
layer:35, std:0.10996390879154205
layer:36, std:0.10969001054763794
layer:37, std:0.10975217074155807
layer:38, std:0.11063199490308762
layer:39, std:0.11021336913108826
layer:40, std:0.10465587675571442
layer:41, std:0.10141163319349289
layer:42, std:0.1026025339961052
layer:43, std:0.10079070925712585
layer:44, std:0.10096712410449982
layer:45, std:0.10117629915475845
layer:46, std:0.10145658254623413
layer:47, std:0.09987485408782959
layer:48, std:0.09677786380052567
layer:49, std:0.099615179002285
layer:50, std:0.09867013245820999
layer:51, std:0.09398546814918518
layer:52, std:0.09388342499732971
layer:53, std:0.09352942556142807
layer:54, std:0.09336657077074051
layer:55, std:0.094817616045475
layer:56, std:0.08856320381164551
layer:57, std:0.09024856984615326
layer:58, std:0.0886448472738266
layer:59, std:0.08766943961381912
layer:60, std:0.08726290613412857
layer:61, std:0.08623497188091278
layer:62, std:0.08549781143665314
layer:63, std:0.08555219322443008
layer:64, std:0.08536665141582489
layer:65, std:0.08462796360254288
layer:66, std:0.08521939814090729
layer:67, std:0.08562128990888596
layer:68, std:0.08368432521820068
layer:69, std:0.08476376533508301
layer:70, std:0.08536301553249359
layer:71, std:0.08237562328577042
layer:72, std:0.08133520931005478
layer:73, std:0.08416961133480072
layer:74, std:0.08226993680000305
layer:75, std:0.08379077166318893
layer:76, std:0.08003699779510498
layer:77, std:0.07888863980770111
layer:78, std:0.07618381083011627
layer:79, std:0.07458438724279404
layer:80, std:0.07207277417182922
layer:81, std:0.07079191505908966
layer:82, std:0.0712786540389061
layer:83, std:0.07165778428316116
layer:84, std:0.06893911212682724
layer:85, std:0.06902473419904709
layer:86, std:0.07030880451202393
layer:87, std:0.07283663004636765
layer:88, std:0.07280216366052628
layer:89, std:0.07130247354507446
layer:90, std:0.07225216180086136
layer:91, std:0.0712454691529274
layer:92, std:0.07088855654001236
layer:93, std:0.0730612725019455
layer:94, std:0.07276969403028488
layer:95, std:0.07259569317102432
layer:96, std:0.0758652538061142
layer:97, std:0.07769152522087097
layer:98, std:0.07842093706130981
layer:99, std:0.08206242322921753
tensor([[-0.1103, -0.0739, 0.1278, ..., -0.0508, 0.1544, -0.0107],
[ 0.0807, 0.1208, 0.0030, ..., -0.0385, -0.1887, -0.0294],
[ 0.0321, -0.0833, -0.1482, ..., -0.1133, 0.0206, 0.0155],
...,
[ 0.0108, 0.0560, -0.1099, ..., 0.0459, -0.0961, -0.0124],
[ 0.0398, -0.0874, -0.2312, ..., 0.0294, -0.0562, -0.0556],
[-0.0234, -0.0297, -0.1155, ..., 0.1143, 0.0083, -0.0675]],
grad_fn=<TanhBackward>)
网络层的标准差随着前向传播变得越来越小,从而本层的梯度越来越小。
针对存在激活函数的权值初始化问题,分别提出了Xavier方法和Kaiming方法
xavier_uniform方法
参考论文 Understanding the difficulty of training deep feedforward neural networks,结合方差一致性原则,也就是让每一层的输出值的方差尽量为1,同时这种方法是针对饱和激活函数如Sigmoid,Tanh方法进行分析的。
结论为:
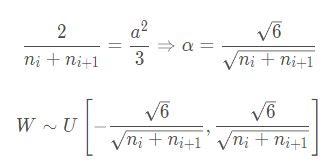
自定义实现
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
a = np.sqrt(6 / (self.neural_num + self.neural_num)) # Xavier初始化方法
tanh_gain = nn.init.calculate_gain('tanh')
a *= tanh_gain
nn.init.uniform_(m.weight.data, -a, a)
非饱和型激活函数
Kaiming
针对Xavier方法不能有效解决Relu非饱和激活函数的问题,2015年提出了Kaiming初始化方法。基于方差一致性原则,Kaiming初始化方法保持数据尺度维持在恰当范围,通常方差为1,这种方法针对的激活函数为ReLU及其变种。
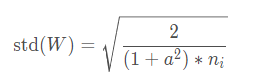
公式中a是负半轴的斜率。在ReLU中,其负半轴的斜率为0,即a=0,ni是输入神经元个数
自定义实现:
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
PyTorch中的实现:
nn.init.kaiming_normal_(m.weight.data)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









