







Fine-tune Gemma models in Keras using LoRA | Kaggle
1.Overview
Gemma is a family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models.
Large Language Models (LLMs) like Gemma have been shown to be effective at a variety of NLP tasks. An LLM is first pre-trained on a large corpus of text in a self-supervised fashion. Pre-training helps LLMs learn general-purpose knowledge, such as statistical relationships between words. An LLM can then be fine-tuned with domain-specific data to perform downstream tasks (such as sentiment analysis).
LLMs are extremely large in size (parameters in the order of millions). Full fine-tuning (which updates all the parameters in the model) is not required for most applications because typical fine-tuning datasets are relatively much smaller than the pre-training datasets.
Low Rank Adaptation (LoRA){:.external} is a fine-tuning technique which greatly reduces the number of trainable parameters for downstream tasks by freezing the weights of the model and inserting a smaller number of new weights into the model. This makes training with LoRA much faster and more memory-efficient, and produces smaller model weights (a few hundred MBs), all while maintaining the quality of the model outputs.
This tutorial walks you through using KerasNLP to perform LoRA fine-tuning on a Gemma 2B model using the Databricks Dolly 15k dataset{:.external}. This dataset contains 15,000 high-quality human-generated prompt / response pairs specifically designed for fine-tuning LLMs.
2.Setup
Get access to Gemma
To complete this tutorial, you will first need to complete the setup instructions at Gemma setup. The Gemma setup instructions show you how to do the following:
Gemma models are hosted by Kaggle. To use Gemma, request access on Kaggle:
- Sign in or register at kaggle.com
- Open the Gemma model card and select "Request Access"
- Complete the consent form and accept the terms and conditions
请参考以下链接里对应的Setup:
Get started with Gemma using KerasNLP实践实验一-CSDN博客
3. Install dependencies
Install Keras, KerasNLP, and other dependencies.
注意事项: 首先需要从以下链接进入环境中,这样避免无法读取json文件。
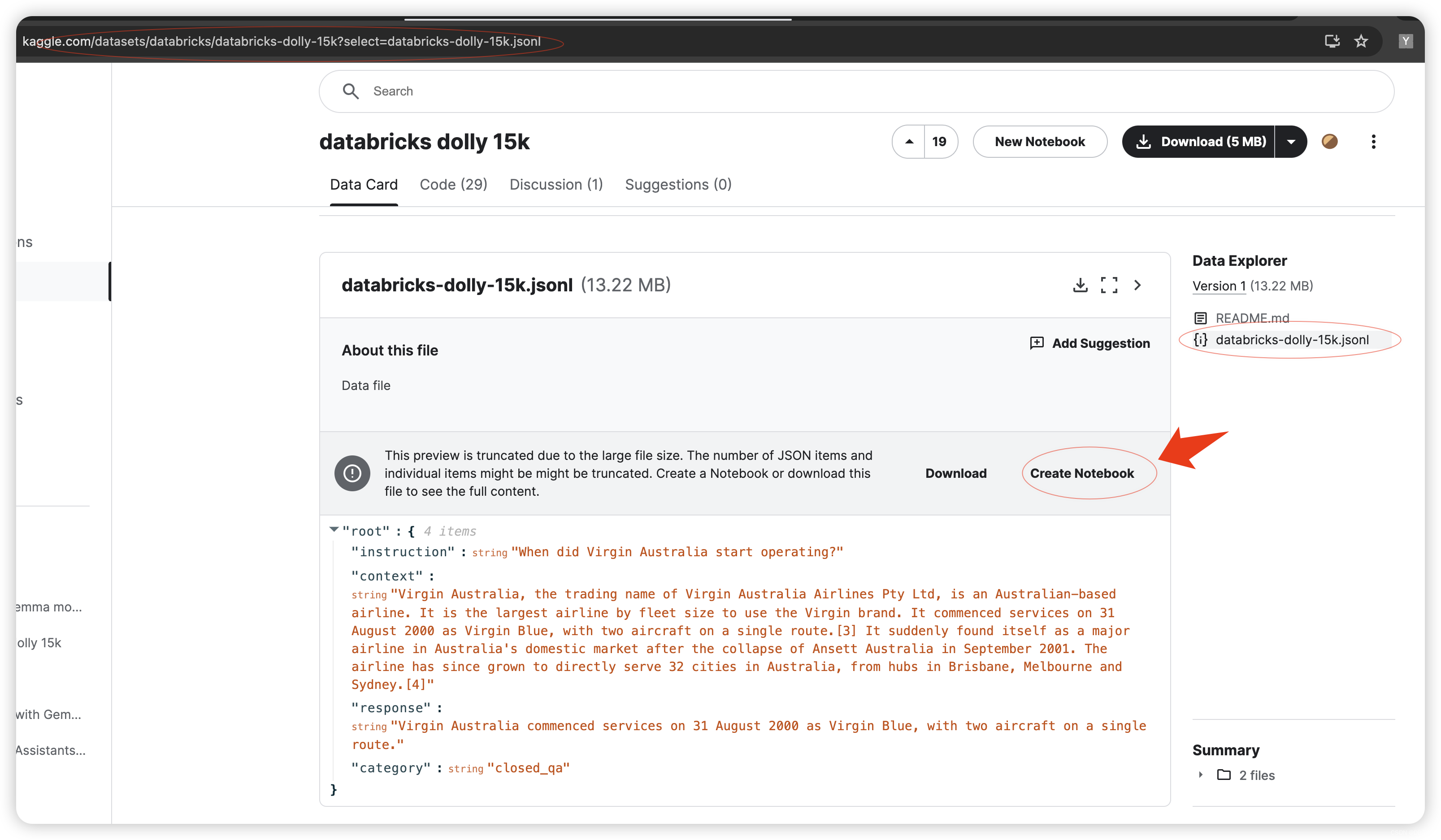
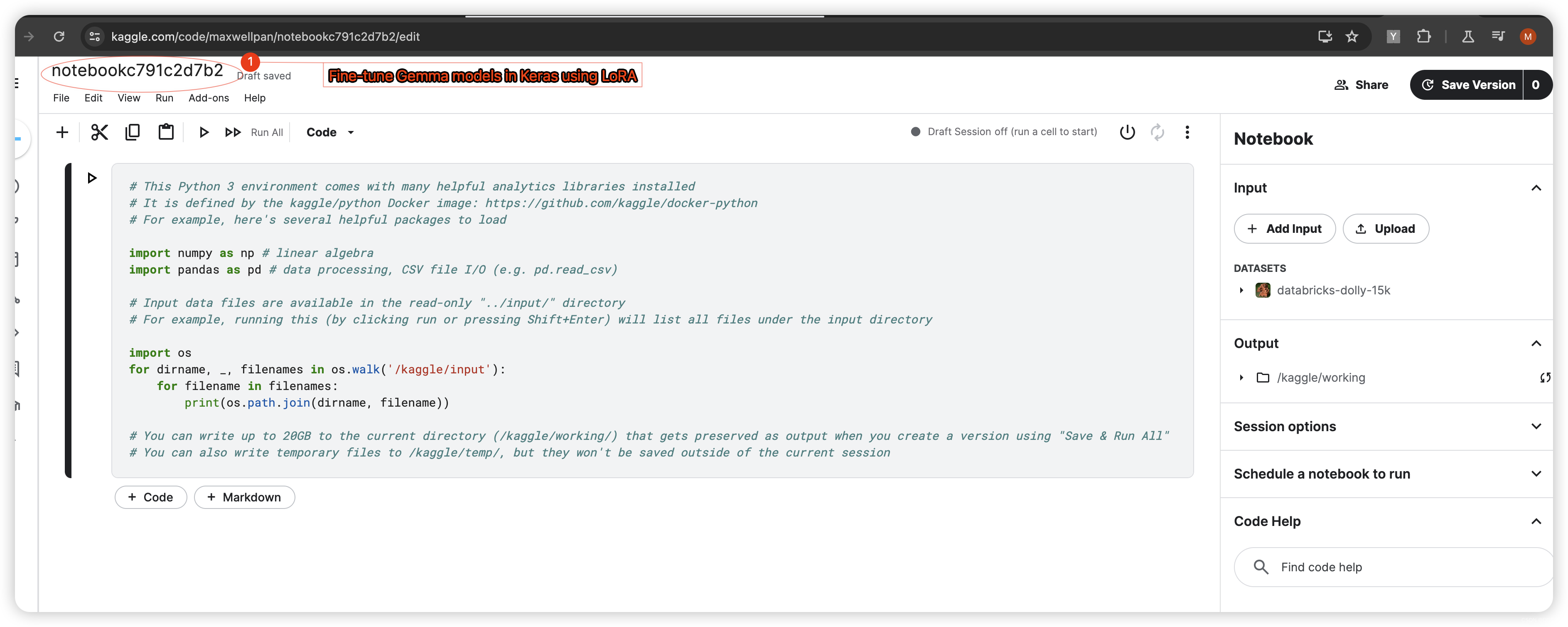
修改Notebook中的名称:
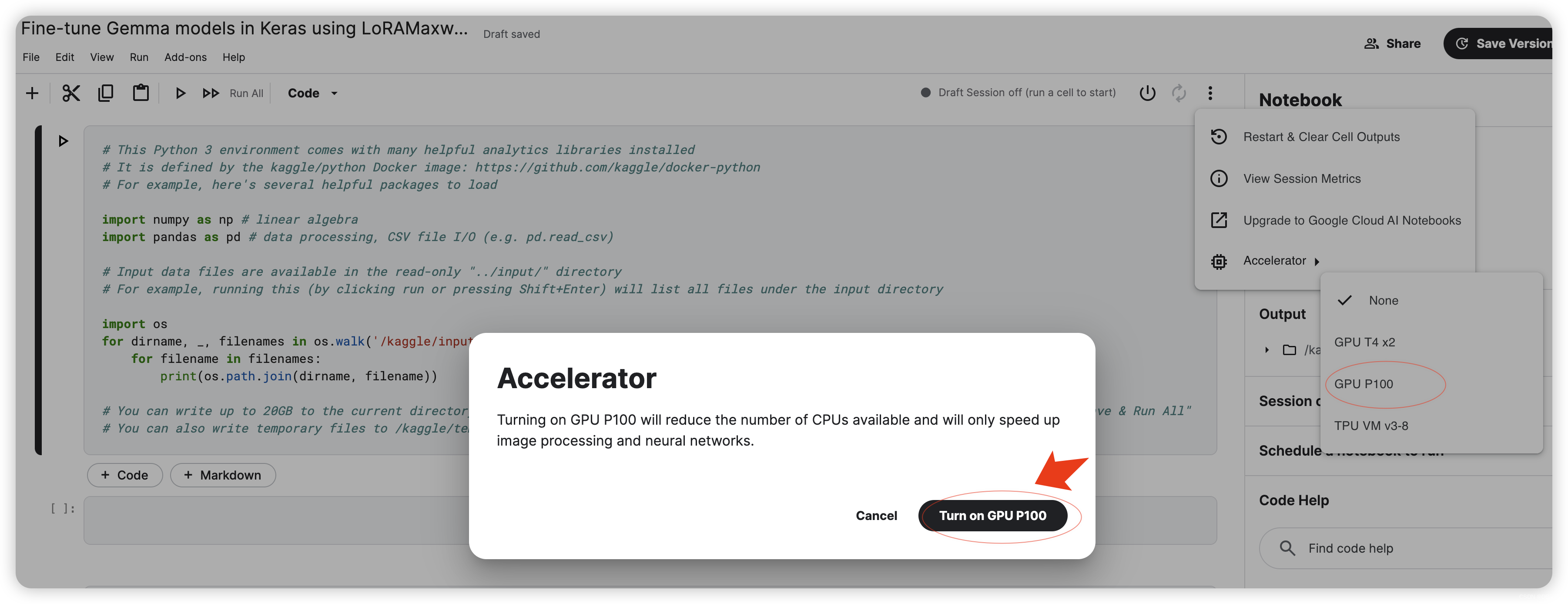
更改加速器:
运行初始环境:
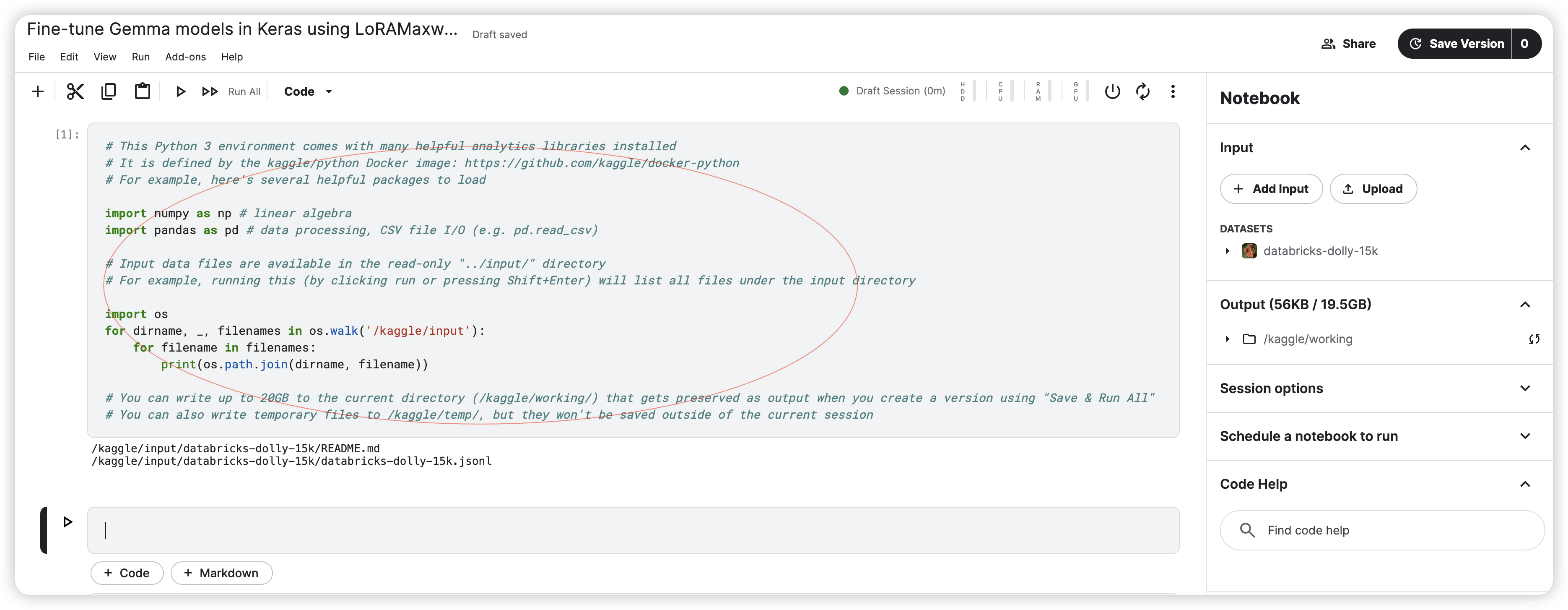
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session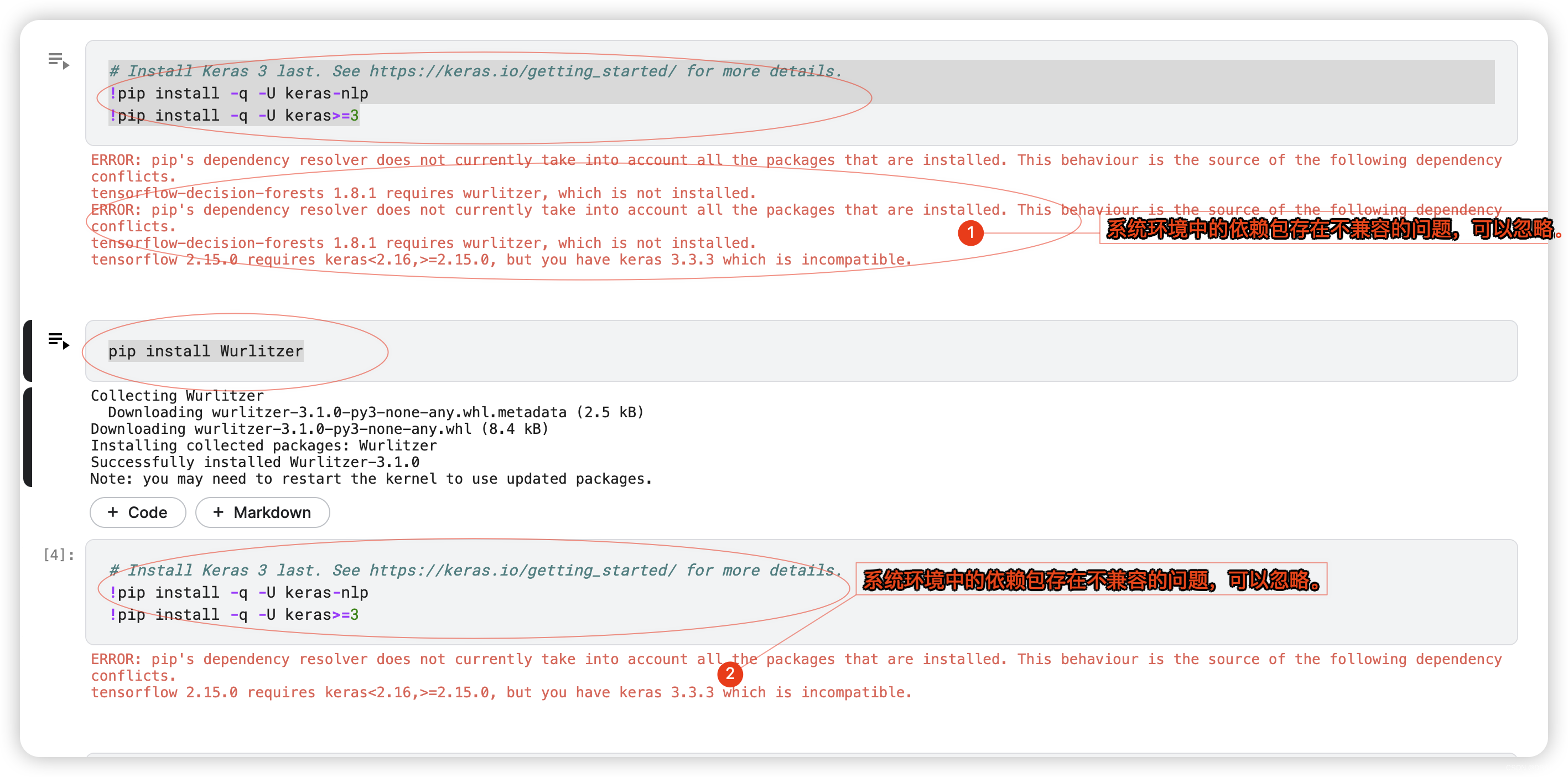
pip install Wurlitzer# Install Keras 3 last. See https://keras.io/getting_started/ for more details.
!pip install -q -U keras-nlp
!pip install -q -U keras>=34.Select a backend
Keras is a high-level, multi-framework deep learning API designed for simplicity and ease of use. Using Keras 3, you can run workflows on one of three backends: TensorFlow, JAX, or PyTorch.
For this tutorial, configure the backend for JAX.
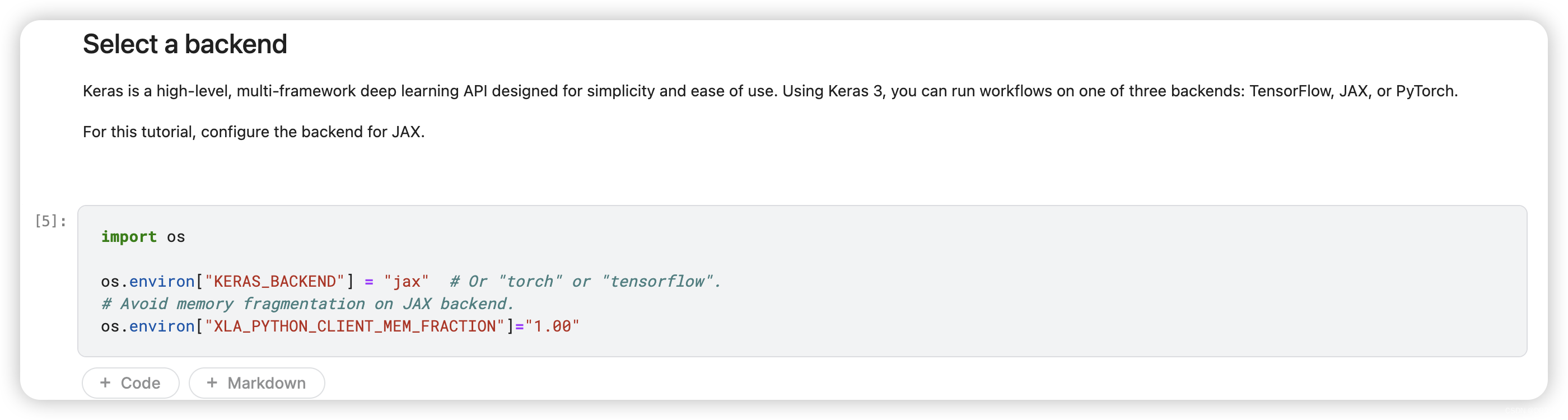
import os
os.environ["KERAS_BACKEND"] = "jax" # Or "torch" or "tensorflow".
# Avoid memory fragmentation on JAX backend.
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"]="1.00"5.Import packages
Import Keras and KerasNLP.
import keras
import keras_nlp6. Load Dataset
Preprocess the data. This tutorial uses a subset of 1000 training examples to execute the notebook faster. Consider using more training data for higher quality fine-tuning.
import json
data = []
with open('/kaggle/input/databricks-dolly-15k/databricks-dolly-15k.jsonl') as file:
for line in file:
features = json.loads(line)
# Filter out examples with context, to keep it simple.
if features["context"]:
continue
# Format the entire example as a single string.
template = "Instruction:\n{instruction}\n\nResponse:\n{response}"
data.append(template.format(**features))
# Only use 1000 training examples, to keep it fast.
data = data[:1000]
7. Load Model
KerasNLP provides implementations of many popular model architectures{:.external}. In this tutorial, you'll create a model using GemmaCausalLM, an end-to-end Gemma model for causal language modeling. A causal language model predicts the next token based on previous tokens.
Create the model using the from_preset method:
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")
gemma_lm.summary()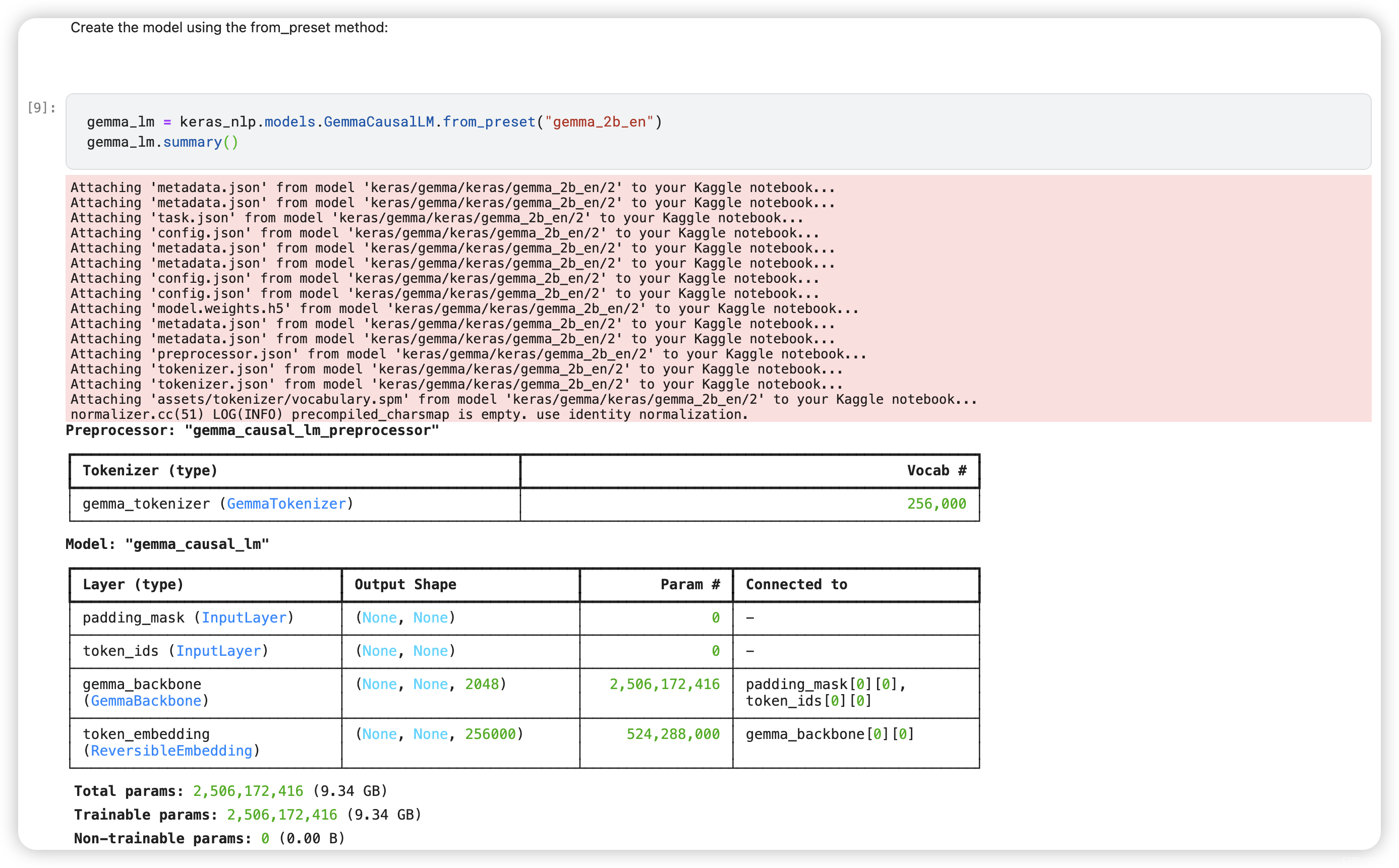
8.Inference before fine tuning
In this section, you will query the model with various prompts to see how it responds.
8.1 Europe Trip Prompt
Query the model for suggestions on what to do on a trip to Europe.
prompt = template.format(
instruction="What should I do on a trip to Europe?",
response="",
)
print(gemma_lm.generate(prompt, max_length=256)) 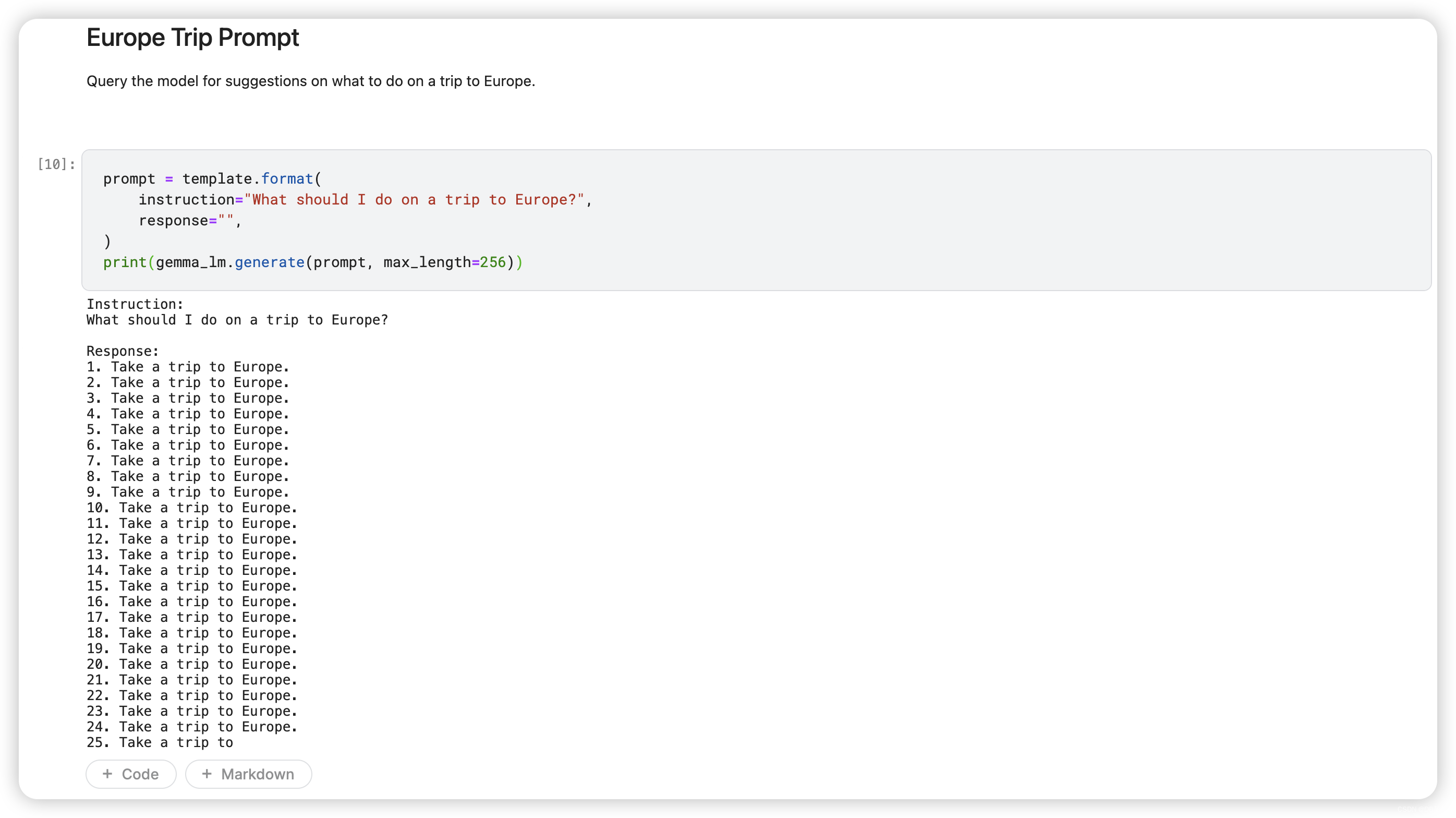
The model just responds with a recommendation to take a trip to Europe.
8.2.ELI5 Photosynthesis Prompt
Prompt the model to explain photosynthesis in terms simple enough for a 5 year old child to understand.
prompt = template.format(
instruction="Explain the process of photosynthesis in a way that a child could understand.",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))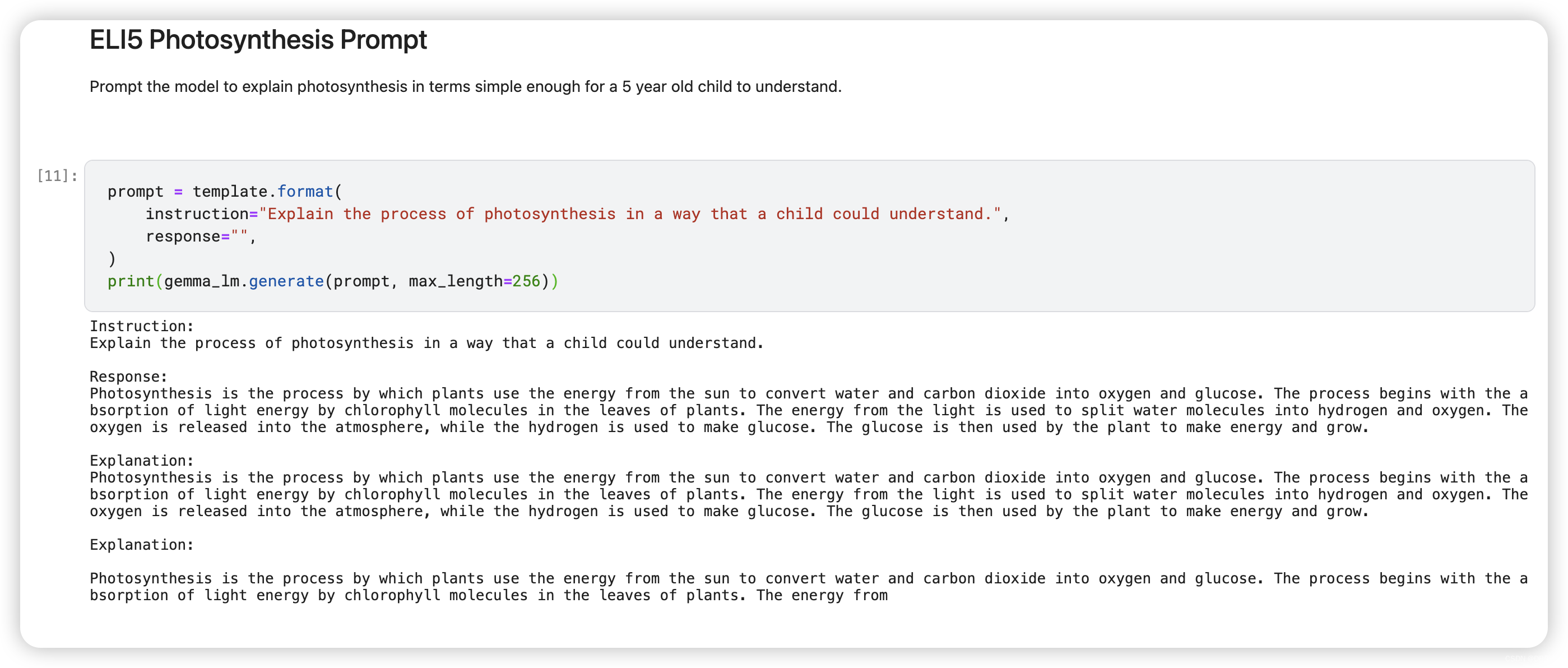
9.LoRA Fine-tuning
To get better responses from the model, fine-tune the model with Low Rank Adaptation (LoRA) using the Databricks Dolly 15k dataset.
The LoRA rank determines the dimensionality of the trainable matrices that are added to the original weights of the LLM. It controls the expressiveness and precision of the fine-tuning adjustments.
A higher rank means more detailed changes are possible, but also means more trainable parameters. A lower rank means less computational overhead, but potentially less precise adaptation.
This tutorial uses a LoRA rank of 4. In practice, begin with a relatively small rank (such as 4, 8, 16). This is computationally efficient for experimentation. Train your model with this rank and evaluate the performance improvement on your task. Gradually increase the rank in subsequent trials and see if that further boosts performance.
# Enable LoRA for the model and set the LoRA rank to 4.
gemma_lm.backbone.enable_lora(rank=4)
gemma_lm.summary()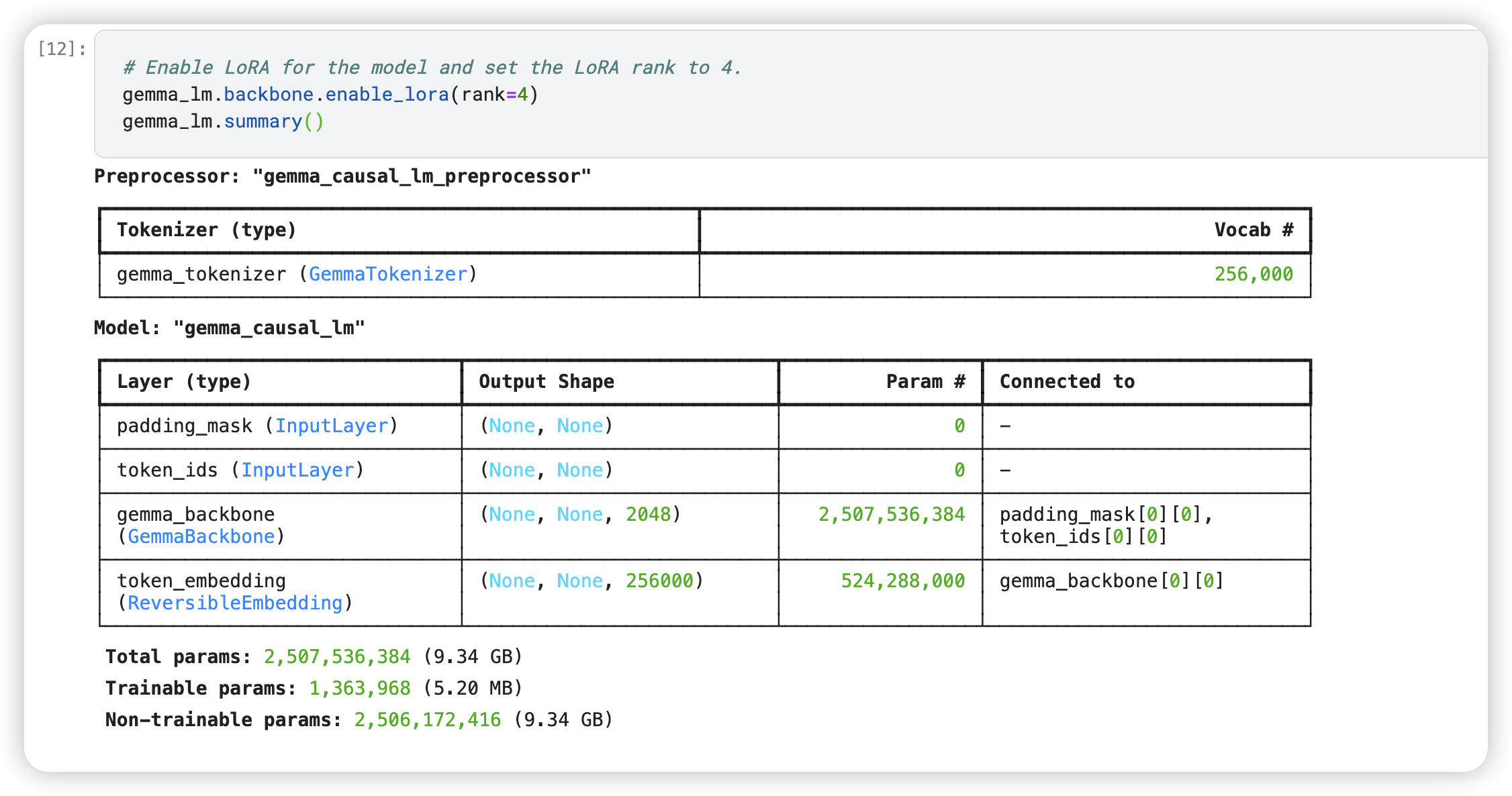
Note that enabling LoRA reduces the number of trainable parameters significantly (from 2.5 billion to 1.3 million).
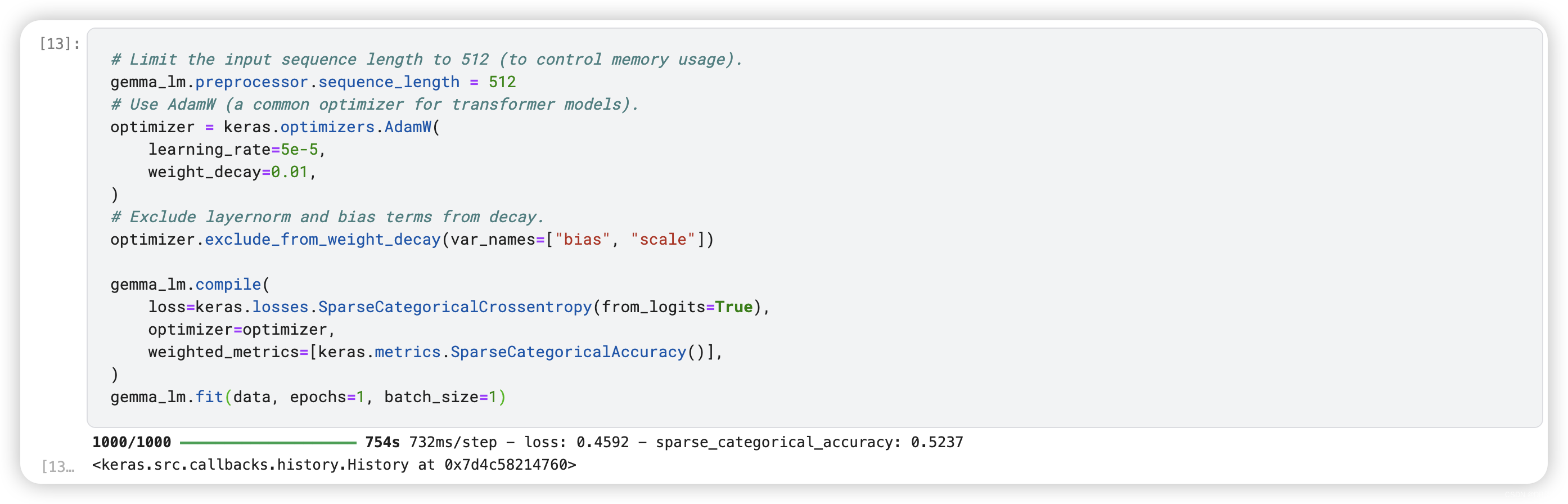
# Limit the input sequence length to 512 (to control memory usage).
gemma_lm.preprocessor.sequence_length = 512
# Use AdamW (a common optimizer for transformer models).
optimizer = keras.optimizers.AdamW(
learning_rate=5e-5,
weight_decay=0.01,
)
# Exclude layernorm and bias terms from decay.
optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])
gemma_lm.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=optimizer,
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
gemma_lm.fit(data, epochs=1, batch_size=1)
10.Inference after fine-tuning
After fine-tuning, responses follow the instruction provided in the prompt.
10.1 Europe Trip Prompt
prompt = template.format(
instruction="What should I do on a trip to Europe?",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))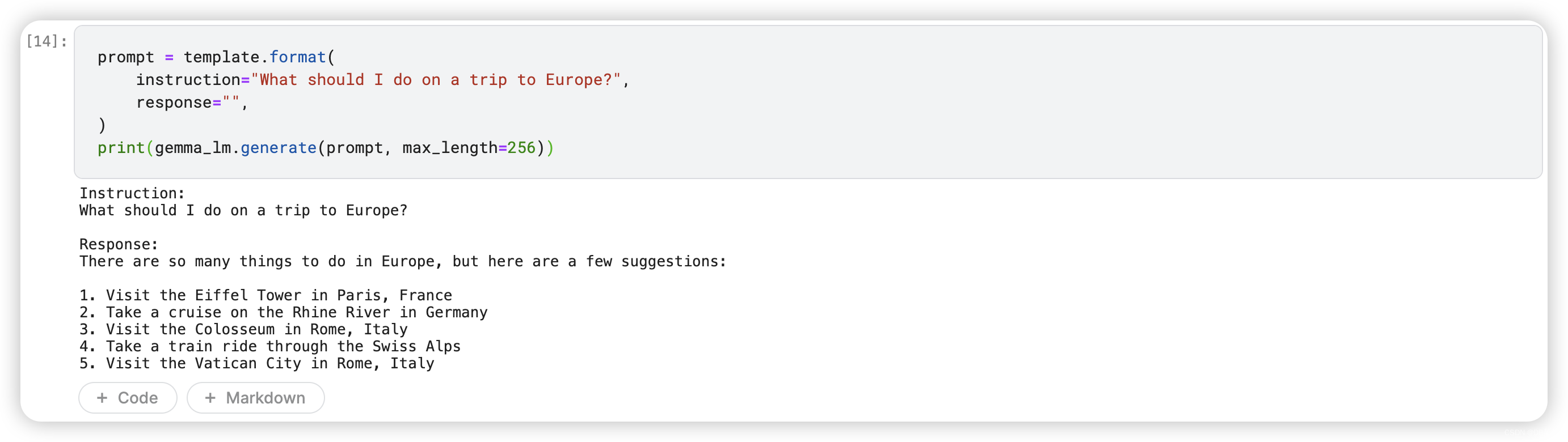
10.2 ELI5 Photosynthesis Prompt
prompt = template.format(
instruction="Explain the process of photosynthesis in a way that a child could understand.",
response="",
)
print(gemma_lm.generate(prompt, max_length=256))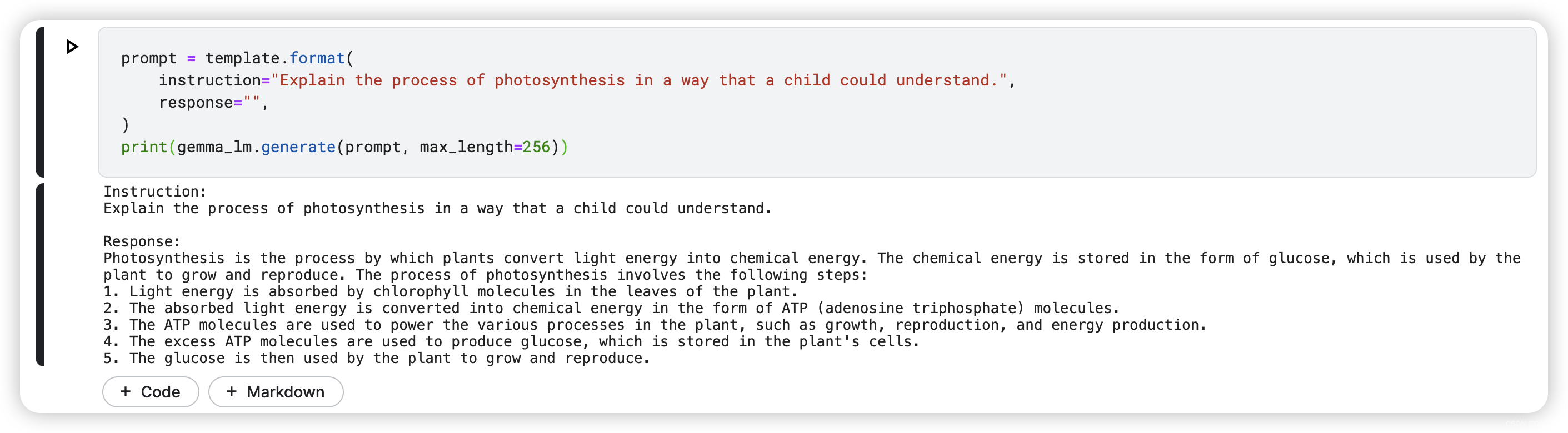
The model now explains photosynthesis in simpler terms.
linkcode
Note that for demonstration purposes, this tutorial fine-tunes the model on a small subset of the dataset for just one epoch and with a low LoRA rank value. To get better responses from the fine-tuned model, you can experiment with:
- Increasing the size of the fine-tuning dataset
- Training for more steps (epochs)
- Setting a higher LoRA rank
- Modifying the hyperparameter values such as
learning_rateandweight_decay.
倘若您觉得我写的好,那么请您动动你的小手粉一下我,你的小小鼓励会带来更大的动力。Thanks.















 8802
8802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









