









YOLO
Rgb大神关于物体检测的新作YOLO,论文You Only Look Once: Unified, Real-Time Object Detection。
Introduction
对比人类的视觉系统,现存的物体检测模型:
- 要不就是准确度不咋的(DPM速度还行,准确率很差,实用不现实)
- 要不就是速度跟不上(Faster R-CNN 准确度还可以,3FPS的速度不能实时监测啊~)

这一堆物体检测模型,无论在学术界还是工程界,都不算令人满意。为此需要注入新的血液(重新挖坑),那么从哪里开始扎针呢?
作者在论文内主要对比R-CNN系列,指出了R-CNN系列速度慢的原因是: 模型把物体检测任务分为了多个阶段,而这几个阶段需要分开训练,难以优化(虽然Faster R-CNN是一个整体的网络,但是训练的时候还是需要交替训练)。
为什么非要分为多个阶段?
这是因为基于RPN(region proposal networks)在设计时已经把object detection问题分为多个pipeline,如果要改,就要把RPN方案砍掉。
YOLO在此基础上重建了整个模型框架,将原先的Region Proposal一套方案抛弃掉,将object detection作为回归问题来处理,模型能够接收原始像素直接输出object的bbox和类别categories,也就是end-to-end模型.
Detection System
YOLO工作的流程图如下:
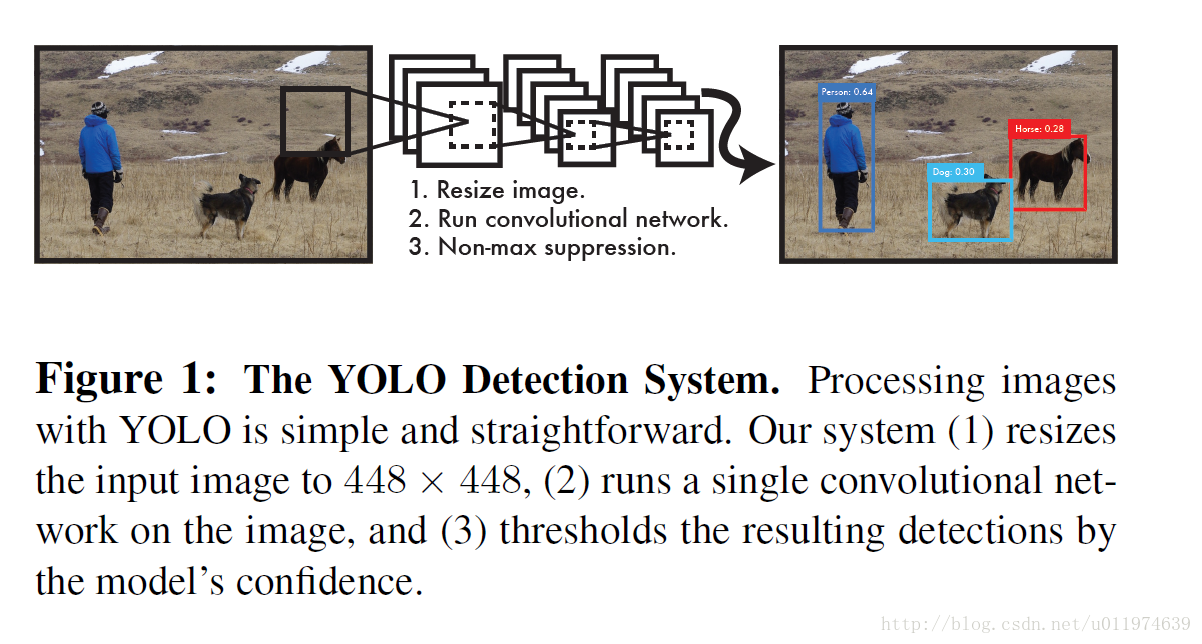
大致步骤为:
- 整个图片resize到指定大小,得到图片 Inputrs
- 将 Inputrs 塞给CNN
- 使用NMS(非极大值抑制)去除多余框,得到最后预测结果
总的步骤很简单,下面具体看看图片塞给CNN时是怎么整的。
分成单元格
首先会把原始图片resize到 448×448 ,放缩到这个尺寸是为了后面整除来的方便。再把整个图片分成 S×S(例:7×7) 个单元格,此后以每个单元格为单位进行预测分析。

每个单元格需要做三件事:
如果一个object的中心落在某个单元格上,那么这个单元格负责预测这个物体(论文的思想是让每个单元格单独干活)。
每个单元格需要预测 B 个bbox值(bbox值包括坐标和宽高),同时为每个bbox值预测一个
置信度(confidence scores)。也就是每个单元格需要预测B×(4+1) 个值。每个单元格需要预测 C (物体种类个数)个条件概率值.
注意到:每个单元格只能预测一种物体,并且直接预测物体的概率值。但是每个单元格可以预测多个bbox值(包括置信度)。
单元格数据
我们细致的分析一下每个单元格预测的
- (x,y) 是bbox的中心相对于单元格的offset
- (w,h) 是bbox相对于整个图片的比例
- confidence 下面有详解

如上图,图片分成 S×S(7×7) 个单元格。整张图片的长宽为 hi,wi 。
(x,y) 到底代表啥意思?
对于蓝色框的那个单元格(坐标为
(xcol=1,yrow=4)
),假设它预测的是红色框的bbox(即object是愚蠢的阿拉斯加),我们设bbox的中心坐标为
(xc,yc)
,那么最终预测出来的
(x,y)
是经过归一化处理的,表示的时中心相对于单元格的offset,计算公式如下:
(w,h) 又是啥意思?
预测的bbox的宽高为
wb,hb
,
(w,b)
表示的是bbox的是相对于整张图片的占比,计算公式如下:
Confidence
这个置信度有两个含义:一是格子内是否有目标,二是bbox的准确度。
我们定义置信度为 Pr(Object)∗IOUtruthpred .
- 如果格子内有物体,则 Pr(Object)=1 ,此时置信度等于IoU
- 如果格子内没有物体,则 Pr(Object)=0 ,此时置信度为0
C 个种类的概率值
每个网格在输出bbox值的同时要给出给个网格存在object的类型。记为:
需要注意的是:输出的种类概率值是针对网格的,不是针对bbox的。所以一个网格只会输出 C 个种类信息。(这样就是默认为一个格子内只能预测一种类别的object了,简化了计算,但对于检测小object很不利)。
在检测目标时,我们把
这就是每个单元格的class-specific confidence scores,这即包含了预测的类别信息,也包含了对bbox值的准确度。 我们可以设置一个阈值,把低分的class-specific confidence scores滤掉,剩下的塞给非极大值抑制,得到最终的标定框。
对于这部分可以看deepsystem.ai的PPT,讲的很详细,需要翻墙。
单元格输出
每个网络一共会输出:
B×(4+1)+C
个预测值.
故所有的单元格输出为:
S×S×(B×5+C)
个预测值.
论文中每个单元格的输出如下图:

所有单元格输出为 7×7×(2×5+20) ,即最终的输出为 7×7×30 的张量。
YOLO检测物体的流程

- 分割成单元格
- 预测bbox与类别信息,得到最终的 specificconfidence
- 设置阈值,滤掉低分的bbox
- 非极大值抑制得到最终的bbox
YOLO的架构
上面说了YOLO的检测过程,那么中间关键的预测bbox和 confidence 该怎么实现?
当然是用CNN来整,整个网络框架如下:

网络架构受GoogleNet启发,共24个卷积层,后面接了2个FC层。
预训练
使用上图的前20个卷积层+平均池化+FC层在ImageNet上跑了一圈。(在ImageNet上跑是用的 224×224 输入)。
预训练完事后,也就是get到了想要的前20个卷积层权重,在此基础上添加4个卷积层和2个FC层,得到最终模型(也就是上图)。同时将网络的输入尺寸从 224×224 改成了 448×448 。

YOLO的训练
整个YOLO在训练时,有很多处理的细节,我们主要讲一下网络损失函数的定义。
损失函数
这里我们把损失函数分为3个部分,每个部分都使用均方误差(为什么用均方,论文给出的原因是这样做简单啊):
先看一下整个损失函数:

每个图片的每个单元格不一定都包含object,如果没有object,那么 confidence 就会变成0,这样在优化模型的时候可能会让梯度跨越太大,模型不稳定跑飞了。为了平衡这一点,在损失函数中,设置两个参数 λcorrd 和 λnoobj ,其中 λcorrd 控制bbox预测位置的损失, λnoobj 控制单个格内没有目标的损失。
对三个损失函数有细节上的调整:
bbox
对于预测的bbox框,大的bbox预测有点偏差可以接受,而小的bbox预测有点偏差就比较受影响了,如下图:
对于这种情况,使用先平方根再求均方误差,尽可能的缩小小偏差下的影响。
bbox的损失记为:
中心点损失:λcorrd∑i=0S2∑j=0BIobjij[(xi−xi^)2+(yi−yi^)2]
宽高损失:+λcorrd∑i=0S2∑j=0BIobjij[(wi−−√−wi^−−√)2+(hi−−√−hi^−−√)2]
Iobjij 表示第i个单元格内预测的第j个bbox是否负责这个object:在计算损失过程中,bbox与ground truth的IoU值最大的负责object。confidence
对于置信度的损失,是按照是否含有object情况下分成两部分,对于不包含object的单元格,我们使用 λnoobj 调整比例,防止这部分overpowering。
∑i=0S2∑j=0BIobjij(Ci−Ci^)2+λnoobj∑i=0S2∑j=0BIobjij(Ci−Ci^)2categories
对于种类预测,前面说了,这里设定每个单元格只负责一个object的预测,所以我们不用考虑多个bbox了。故损失函数为:
∑i=0S2Iobji(pi(c)−pi^(c))2

训练细节
在激活函数上:
最后一层使用的是标准的线性激活函数,其他的层都使用leaky rectified linear activation:
ϕ(x)={ x, if x>00.1x , otherelse在学习率上:
- 前75个epoch设置为 10−2
- 再30个epoch设置为 10−3
- 最后30个epoch设置为 10−4
其他的训练细节:
- batch=64
- 动量0.9,衰减为0.0005
- 使用dropout,设置为0.5,接在第一个FC层后
- 对样本做了数据增强
总结
优点
YOLO有如下特点:
- 速度快。YOLO将物体检测作为回归问题进行求解,使用单个网络完成整个检测过程。
- 召回率低,表现为背景误检率低。YOLO可以get到图像的整体信息,相比于region proposal等方法,有着更广阔的“视野”。
- 泛化能力强,对其他类的东西,训练后效果也是挺好的。
缺点
论文给出了YOLO与Fast RCNN的对比图,YOLO的定位准确率相对于fast rcnn比较差。但是YOLO对背景的误判率比Fast RCNN的误判率低很多。这说明了YOLO中把物体检测的思路转成回归问题的思路有较好的准确率,但是bounding box的定位不是很好。
















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









