






import torch
import torch.nn as nn
import torch.nn.functional as F
nn中定义的是类,functional里面定义的是函数操作。
输出shape的计算公式:
out_shape
=
round_mode
(
in_shape + 2 * padding - kernel_size
stride
+
1
)
\text{out\_shape} = \text{round\_mode} (\frac{\text{in\_shape + 2 * padding - kernel\_size}}{\text{stride}} + 1)
out_shape=round_mode(stridein_shape + 2 * padding - kernel_size+1)
默认的round_mode为floor,即向下取整。可以通过ceil_mode开关,指定为向上取整。
Normalization
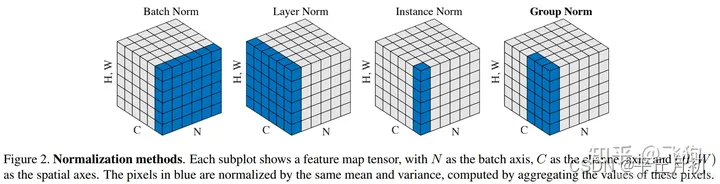
这张图描述的很清晰。
BatchNorm
\text{BatchNorm}
BatchNorm: 逐通道计算batch内所有样本的mean和std,然后逐通道归一化。维度可以理解为[1, C, 1, 1]。对
batchsize
\text{batchsize}
batchsize大小敏感,小
batchsize
\text{batchsize}
batchsize效果容易不好,主要是
batchsize
\text{batchsize}
batchsize太小,计算出来的mean和std不足以代表整个数据集的数据分布。
LayerNorm
\text{LayerNorm}
LayerNorm:这种归一化方式的接口比较特别,接口的地方再详细解释。上图仅对4D的[N, C, H, W]解释有效,逐样本计算batch内每个样本自身的mean和std,然后逐样本归一化。维度可以理解为[N, 1, 1, 1]。主要对
RNN
\text{RNN}
RNN作用明显。
InstanceNorm
\text{InstanceNorm}
InstanceNorm:逐样本逐通道计算batch内每个样本每个通道的mean和std,然后逐样本逐通道归一化。维度可以理解为[N, C, 1, 1]。用于风格化迁移,因为在图像风格化中,生成结果主要依赖某个图像实例,所以对整个batch做归一化不适合图像风格化任务,因而对HW维度做归一化,可以加速模型收敛,并保持每个图像实例之间的独立。
GroupNorm
\text{GroupNorm}
GroupNorm:逐样本计算batch内每个样本N个通道的mean和std,然后逐样本逐N个通道做归一化。维度可以理解为[N, G, 1, 1]。实际上GN就是LN和IN的中间态。作者认为G=32比较好。
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
BatchNorm
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift <https://arxiv.org/abs/1502.03167>
y = x − E [ x ] V a r [ x ] + ϵ ∗ γ + β y = \frac{x - \mathrm{E}[x]}{\sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta y=Var[x]+ϵx−E[x]∗γ+β
BatchNorm1d
class nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, tracking_running_stats=True, device=None, dtype=None)
对2D或者3D输入在C这个维度上做BN。2D输入时,维度为[N, C], 3D输入时,维度为[N, C, L], C表示通道数, L表示序列长度。
BatchNorm2d
class nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, tracking_running_stats=True, device=None, dtype=None)
对4D输入在C这个维度上做BN,维度为[N, C, H, W]。
BatchNorm3d
class nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, tracking_running_stats=True, device=None, dtype=None)
对5D输入在C这个维度上做BN,维度为[N, C, D, H, W]。不常用,后面实际用到再讨论。
上述三个类是这样的继承关系:BatchNormNd <- _BatchNorm <- _NormBase <- nn.Module,实际forward计算时,用了_BatchNorm中的F.batch_norm接口,进而调用了torch.batch_norm接口,其最终的底层实现是用C++写的,代码在aten/src/ATen/native/Normalization.cpp。具体的cpu实现方式参见aten/src/ATen/native/cpu/batch_norm_kernel.cpp。
using accscalar_t = at::acc_type<scalar_t, false>;
int64_t n_batch = input.size(0);
int64_t n_channel = input.size(1);
int64_t image_size = input.numel() / n_batch / n_channel;
int64_t N = input.numel() / n_channel;
// parallel dim reduce on 'channel'
at::parallel_for(0, n_channel, 1, [&](int64_t begin, int64_t end) {
for (const auto c : c10::irange(begin, end)) {
// compute mean per input
accscalar_t sum = 0;
for (const auto n: c10::irange(n_batch) {
for (const auto i: c10::irange(image_size) {
auto offset = n * n_channel * image_size + c * image_size + i;
sum += input_data[offset];
}
}
scalar_t mean = sum / N;
mean_data[c] = mean;
// compute variance per input
accscalar_t _var_sum = 0;
for (const auto n: c10::irange(n_batch)) {
for (const auto i: c10::irange(image_size) {
auto offset = n * n_channel * image_size + c * image_size + i;
auto x = input_data[offset];
_var_sum += (x - mean) * (x - mean);
}
}
var_sum_data[c] = _var_sum;
}
}
/// Collect the linear and constant terms regarding the input.
/// output(n, c, h, w)
/// = (input(n, c, h, w) - mean(c)) / sqrt(var(c) + eps) * weight(c) + bias(c)
/// = input(n, c, h, w) * inv_var(c) * weight(c)
/// - mean(c) * inv_var(c) * weight(c) + bias(c),
/// where inv_var(c) = 1 / sqrt(var(c) + eps).
/// So the linear term, alpha(c) = inv_var(c) * weight(c),
/// the constant term beta(c) = bias(c) - mean(c) * inv_var(c) * weight(c)
// output(n, c, h, w) = input(n, c, h, w) * alpha(c) + beta(c)
at::parallel_for(0, n_batch * n_channel, 1, [&](int64_t begin, int64_t end) {
//......
}
InstanceNorm
Instance Normalization: The Missing Ingredient for Fast Stylization
简单来说就是,区别于
BatchNorm2d
\text{BatchNorm2d}
BatchNorm2d对batch内每个通道的所有样本计算mean和std,得到mean[c], std[c]。
InstanceNorm2d
\text{InstanceNorm2d}
InstanceNorm2d对batch内的每个样本的每个通道都会算一个mean和std,得到mean[b][c], std[b][c],然后逐样本逐通道做归一化。
InstanceNorm2d
class nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, tracking_running_stats=True, device=None, dtype=None)
LayerNorm
class nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, bias=True, device=None, dtype=None)
在最后的D维上计算mean和std,D是接口中的 normalized_shape \text{normalized\_shape} normalized_shape的维度。比如,如果 normalized_shape \text{normalized\_shape} normalized_shape为[3, 5],其维度为2, 那就在输入的最后两维上计算mean和std。如果 normalized_shape \text{normalized\_shape} normalized_shape只是一个数字,会认为是一个singleton list,在最后一维做归一化。
NLP任务范例:
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
layer_norm(embedding)
计算出来的mean和std的尺寸为[batch, sentence_length],在最后一维度上归一化。
Image任务范例:
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
也就是最上面放的那张图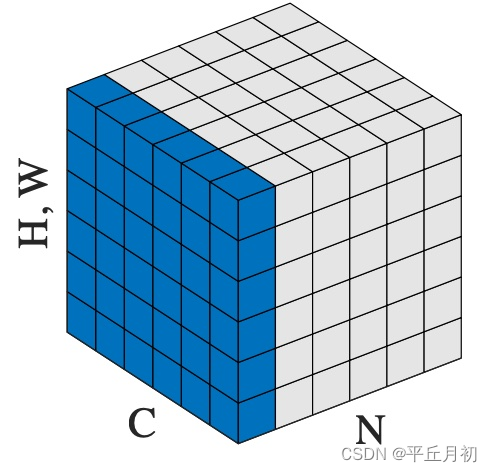
GroupNorm
class nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True, device=None, dtype=None)
输入通道分成num_groups组,每组包含num_channels / num_groups个通道,num_channels必须能被num_groups整除。每组独立计算mean和std,并做归一化。
pool
平均池化
avg_pool2d
F.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)->Tensor
input: [B, C, iH, iW]
kernel_size: 池化区域尺寸。单独的数或者[kH, kW]元组。
stride: 池化操作步长。单独的数或者[sH, sW]元组,默认值是kernel_size。
padding:输入两边padding数目。单独的数或者[padH, padW]元组。默认值是0。
ceil_mode: 如果为True,计算输出shape时使用ceil模式,否则为floor模式。默认是False。
在一个 k H × k W kH \times kW kH×kW的区域内做步长为 s H × s W sH \times sW sH×sW的 2 D 2D 2D平均池化操作。这里的 i H iH iH, k H kH kH, s H sH sH命名有点迷惑性,初看以为是相乘,其实每个就是一个独立名称,分别代表了 i n p u t _ h e i g h t input\_height input_height, k e r n e l _ h e i g h t kernel\_height kernel_height, s t r i d e _ h e i g h t stride\_height stride_height。
实际的底层pool计算逻辑:
o
u
t
(
N
i
,
C
j
,
h
,
w
)
=
1
k
H
×
k
W
∑
m
=
0
k
H
−
1
∑
n
=
0
k
W
−
1
i
n
p
u
t
(
N
i
,
C
j
,
s
t
r
i
d
e
[
0
]
×
h
+
m
,
s
t
r
i
d
e
[
1
]
×
w
+
n
)
out(N_i, C_j, h, w) = \frac{1}{kH\times kW}\sum_{m=0}^{kH-1}\sum_{n=0}^{kW-1}input(N_i, C_j, stride[0] \times h + m, stride[1] \times w + n)
out(Ni,Cj,h,w)=kH×kW1m=0∑kH−1n=0∑kW−1input(Ni,Cj,stride[0]×h+m,stride[1]×w+n)
input = torch.rand(1, 3, 64, 64)
output = F.avg_pool2d(input, kernel_size=4, stride=2, padding=1) # [1, 3, 32, 32]
AvgPool2d
nn.AvgPool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)
作用和F.avg_pool2d()是一样的,只是一个是函数,一个是类。
自适应平均池化
adaptive_avg_pool2d
F.adaptive_avg_pool2d(input, output_size)
具体参见下面的AdaptiveAvgPool2d。
AdaptiveAvgPool2d
nn.AdaptiveAvgPool2d(output_size)
不同于上面的AvgPool2d指定了滤波器的各种参数,得到输出特征。这里是指定输出特征的尺寸,算法自行计算出合适的滤波器参数,输出特征可以满足指定的尺寸要求。
Embedding
nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, _freeze=False, device=None, dtype=None)
参数:
num_embeddings: 查询表中embeddings的条目数。
embedding_dim: 每个embedding向量的维度。
padding_idx: 如果指定,padding_idx这个位置的条目不会贡献梯度,训练时也不会更新。
max_norm: 如果给定,每个embedding向量,如果范数超过max_norm, 会重新归一化为范数为max_norm。
norm_type: 计算max_norm时的范数度,默认是2.0.
变量:
weight(Tensor): 模块中可学习的权重,维度为[num_embeddings, embedding_dim],标准高斯分布初始化参数。
存储固定长度字典的查询表。
embedding = nn.Embedding(10, 3)
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
output = embedding(input) # [2, 4, 3]
参数初始化
fan计算
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.dim()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out
以[16, 8, 3, 3]的卷积核为例
num_input_fmaps = 8
num_output_fmaps = 16
receptive_field_size = 9
fan_in = 8 * 9 = 72
fan_out = 16 * 9 = 144
def _calculate_correct_fan(tensor, mode):
mode = mode.lower()
valid_modes = ['fan_in', 'fan_out']
if mode not in valid_modes:
raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes))
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
return fan_in if mode == 'fan_in' else fan_out
gain计算
给定非线性函数,返回推荐的增益值。
| nonlinearity | gain |
|---|---|
| Linear / Identity | 1 |
| Conv{1,2,3}D | 1 |
| Sigmoid | 1 |
| Tanh | 5 3 \frac{5}{3} 35 |
| ReLU | 2 \sqrt{2} 2 |
| Leaky ReLU | 2 1 + negative_slope 2 \sqrt{\frac{2}{1 + \text{negative\_slope}^2}} 1+negative_slope22 |
def calculate_gain(nonlinearity, param=None):
linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d']
if nonlinearity in linear_fns or nonlinearity == 'sigmoid':
return 1
elif nonlinearity == 'tanh':
return 5.0 / 3
elif nonlinearity == 'relu':
return math.sqrt(2.0)
elif nonlinearity == 'leaky_relu':
if param is None:
negative_slope = 0.01
elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float):
# True/False are instances of int, hence check above
negative_slope = param
else:
raise ValueError("negative_slope {} not a valid number".format(param))
return math.sqrt(2.0 / (1 + negative_slope ** 2))
else:
raise ValueError("Unsupported nonlinearity {}".format(nonlinearity))
uniform初始化
def uniform_(tensor, a=0, b=1.)
Args:
a: the lower bound of the uniform distribution
b: the upper bound of the uniform distribution
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.uniform_(w)
normal初始化
用正态分布初始化tensor数值。
def normal_(tensor, mean=0, std=1.)
Args:
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.normal_(w)
trunc_normal初始化
用正态分布+数值截断,初始化tensor数值。
def trunc_normal_(tensor, mean=0, std=1., a=-2., b=2.)
Args:
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
constant初始化
用常量初始化tensor数值。
def constant_(tensor, val)
Args:
tensor: an n-dimensional `torch.Tensor`
val: the value to fill the tensor with
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.constant_(w, 0.3)
xavier uniform初始化
出自Understanding the difficulty of training deep feedforward neural networks (2010),使用均匀分布初始化tensor数值。
a
=
gain
×
6
fan_in
+
fan_out
a = \text{gain} \times \sqrt{\frac{6}{\text{fan\_in} + \text{fan\_out}}}
a=gain×fan_in+fan_out6
def xavier_uniform_(tensor, gain=1.):
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / float(fan_in + fan_out))
a = math.sqrt(3.0) * std
return _no_grad_uniform_(tensor, -a, a)
这里的 a \text{a} a就是 uniform \text{uniform} uniform分布的上下界。直觉上这种初始化方式要比直接的 U ( 0 , 1 ) \mathcal{U}(0, 1) U(0,1)初始化好,数值更小,且均匀分布在0两侧。以一个[16, 8, 3, 3]的卷积核为例
fan_in = 8 * 3 * 3 = 72
fan_out = 16 * 3 * 3 = 144
a = 0.1667
卷积核的数值会从分布 U ( − 0.1667 , 0.1667 ) \mathcal{U}(-0.1667, 0.1667) U(−0.1667,0.1667)中均匀采样,做初始化。
xavier normal初始化
def xavier_normal_(tensor, gain=1.):
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / float(fan_in + fan_out))
return _no_grad_normal_(tensor, 0., std)
雷同
xavier uniform
\text{xavier uniform}
xavier uniform,区别是计算中间数值时6变为2, 然后计算的数值是正态分布的标准差。
这里提个问题:卷积核权重初始化时,
xavier uniform
\text{xavier uniform}
xavier uniform和
xavier normal
\text{xavier normal}
xavier normal这两种初始化方式,哪种更好?还是几无差异?
kaiming uniform初始化
出自Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification (2015),使用
kaiming
\text{kaiming}
kaiming均匀分布初始化tensor数值。
bound
=
gain
×
3
fan_mode
\text{bound} = \text{gain} \times \sqrt{\frac{3}{\text{fan\_mode}}}
bound=gain×fan_mode3
def kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
bound = math.sqrt(3.0) * std
return _no_grad_uniform_(tensor, -bound, bound)
这里有几个讨论点:
- 这里的 nonlinearity \text{nonlinearity} nonlinearity默认是 leaky_relu \text{leaky\_relu} leaky_relu,那默认情况下,不管待初始化权重的类型是什么,都会以 leaky_relu \text{leaky\_relu} leaky_relu的增益1.414来计算bound。虽然不同类型操作的非线性gain差别不大。
- mode选择 fan_in \text{fan\_in} fan_in还是 fan_out \text{fan\_out} fan_out来初始化权重,有什么标准么?
- 从 xavier \text{xavier} xavier和 kaiming \text{kaiming} kaiming的计算公式看,感觉两者很相似,效果上不会有明显区别。但 kaiming \text{kaiming} kaiming是基于 xavier \text{xavier} xavier的进一步延伸,观点是 xavier \text{xavier} xavier的推导基于激活函数是线性的,但这对 ReLU \text{ReLU} ReLU和 PReLU \text{PReLU} PReLU不成立。 kaiming \text{kaiming} kaiming将这两个非线性激活函数也考虑了进来,且 kaiming \text{kaiming} kaiming认为自己的初始化方法对于极深模型(30个conv/fc layers)也能收敛,但 xavier \text{xavier} xavier初始化不行。那问题又来了, BN \text{BN} BN的想法是2015.02.11发表的, kaiming \text{kaiming} kaiming初始化是2015.02.06发表的,这个时候还没用上 BN \text{BN} BN,在当下看来,网络设计时都会加上 BN \text{BN} BN,那么 xavier \text{xavier} xavier初始化方法也能保证极深网络的收敛。但日常实际使用时,还是会优先使用理论高度更新的方法。
kaiming
\text{kaiming}
kaiming这篇文章的详细解读:
核心思想是研究每层响应的方差。对于一个卷积层,其响应为:
y
l
=
W
l
x
l
+
b
l
y_l = W_lx_l + b_l
yl=Wlxl+bl
V
a
r
[
y
l
]
=
n
l
V
a
r
[
w
l
x
l
]
Var[y_l] = n_lVar[w_lx_l]
Var[yl]=nlVar[wlxl]
V
a
r
[
y
l
]
=
n
l
V
a
r
[
w
l
]
E
[
x
l
2
]
Var[y_l] = n_lVar[w_l]E[x_l^2]
Var[yl]=nlVar[wl]E[xl2]
V
a
r
[
y
L
]
=
1
2
n
l
V
a
r
[
w
l
]
V
a
r
[
y
l
−
1
]
Var[y_L] = \frac{1}{2}n_lVar[w_l]Var[y_{l-1}]
Var[yL]=21nlVar[wl]Var[yl−1]
V
a
r
[
Y
L
]
=
V
a
r
[
y
1
]
(
∏
l
=
2
L
1
2
n
l
V
a
r
[
w
l
]
)
Var[Y_L] = Var[y_1](\prod_{l=2}^{L}\frac{1}{2}n_lVar[w_l])
Var[YL]=Var[y1](l=2∏L21nlVar[wl])
合理的初始化方法需要避免指数级放大或者缩小输入信号的幅度。因此我们希望上述乘法的系数是一个合理的标量,比如1,因此:
1
2
n
l
V
a
r
[
w
l
]
=
1
,
∀
l
\frac{1}{2}n_lVar[w_l]=1, \forall l
21nlVar[wl]=1,∀l
kaiming normal初始化
def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
return _no_grad_normal_(tensor, 0., std)
雷同 kaiming uniform \text{kaiming uniform} kaiming uniform,区别是计算中间数值时3变为1, 然后计算的数值是正态分布的标准差。
register
register_parameter(name, param)
Adds a parameter to the module.
register_buffer(name, tensor, persistent=True)
Adds a buffer to the module. 如果persistent=False,不会放进模型的 state_dict \text{state\_dict} state_dict里面。
这两者的异同:这两个接口都是 nn.Module \text{nn.Module} nn.Module类提供的方法,通过这两个接口注册的变量,可以出现在模型的 state_dict \text{state\_dict} state_dict中。但通过 register_parameter \text{register\_parameter} register_parameter接口注册,可以将 name \text{name} name变量放进模型的 parameter \text{parameter} parameter中,并在训练过程中,接受梯度更新参数。通过 register_buffer \text{register\_buffer} register_buffer接口注册的变量,则不会根据梯度更新参数,最常见的就是 BatchNorm \text{BatchNorm} BatchNorm中的 running_mean \text{running\_mean} running_mean。这里有个注意点,有人会觉得, self.name = tensor \text{self.name = tensor} self.name = tensor和 register_xxx(name, tensor) \text{register\_xxx(name, tensor)} register_xxx(name, tensor)是不是等价的,注意,通过 self.name = tensor \text{self.name = tensor} self.name = tensor声明的变量 self.name \text{self.name} self.name是不会出现在模型的 state_dict \text{state\_dict} state_dict中的,除非写成 self.name = nn.Parameter() \text{self.name = nn.Parameter()} self.name = nn.Parameter()的形式。
常规使用方法:
class Model(nn.Module):
def __init__(self):
super().__init__()
self.id = torch.rand(1, 80)
self.register_buffer('texture', torch.rand(1, 27))
self.register_parameters('exp', nn.Parameter(torch.rand(1, 80)))
self.id等价register_buffer(‘id’, torch.rand(1, 80), persistent=False)只做为模型训练过程中的临时变量,不参与梯度计算,也不会保存到state_dict中。self.texture不参与梯度计算,但会保存在state_dict中。self.exp既参与梯度计算,也会保存在state_dict中。















 5835
5835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









