










《Facial Landmark Detection by Deep Multi-task Learning》发表于ECCV-2014,作者来自香港中文大学汤晓鸥团队的Zhanpeng Zhang等人。
创新点:
1.将MTL(多任务学习)结合CNN应用到人脸关键点检测
2.为解决各任务有着不同收敛速度而导致的优化难问题,提出针对多任务学习的early stopping。
Zhang等人将MTL(Multi-Task Learning)应用到人脸关键点检测中,提出TCDCN(Tasks-Constrained Deep Convolutional Network)。作者认为,在进行人脸特征点检测任务时,结合一些辅助信息可以帮助更好的定位特征点,这些信息如,性别,是否带眼镜,是否微笑和脸部的姿势等等。看看作者给的对比图,感受一下~~:

———————————————分割线—————————————————–
作者将人脸关键点检测(5个关键点)与性别,是否带眼镜,是否微笑和脸部的姿势这四个子任务结合起来构成一个多任务学习模型,模型框架如图所示。
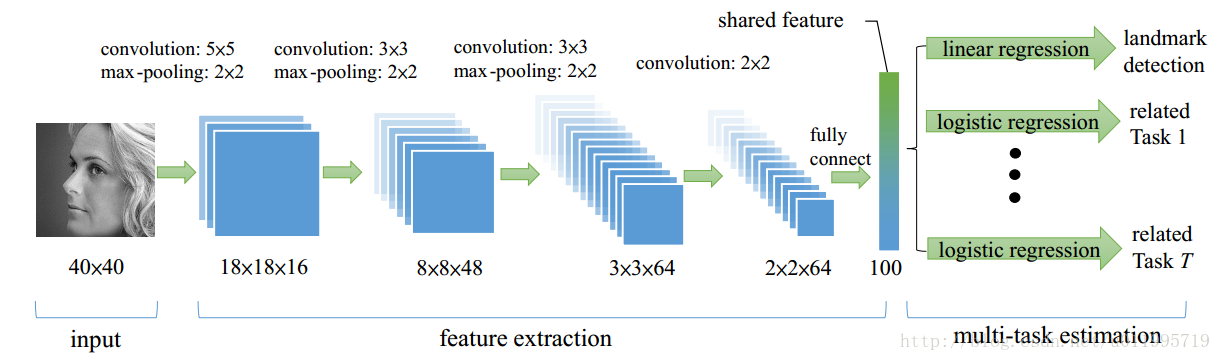
网络输出为40*40的灰度图,经过CNN最终得到2*2*64的特征图,再通过一层含100个神经元的全连接层输出最终提取得到的共享特征。该特征为所有任务共同享用,对于关键点检测问题,就采用线性回归模型;对于分类问题,就采用逻辑回归。
在传统MLT中,各任务重要程度是一致的,其目标方程如下:
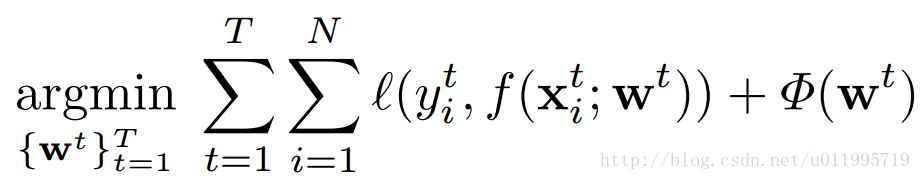
其中,
f(xt;wt)
表示
xt
与权值矩阵
wt
相乘之后经过函数
f(∗)
,
l(∗)
表示损失函数,
Φ(⋅)
是正则项。可以看到对于各任务t而言,其重要性是相同的,但是在多任务学习中,往往不同任务的学习难易程度不同,若采用相同的损失权重,会导致学习任务难以收敛。文章针对多任务学习中,不同学习难度问题进行了优化,提出带权值的目标函数:
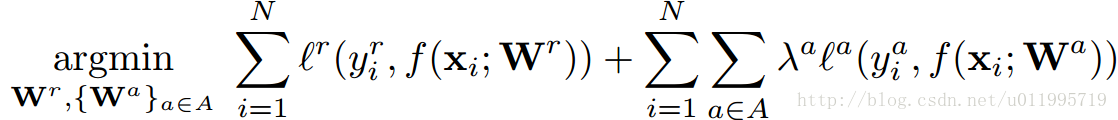
其中,第一项表示主任务的损失函数,即人脸关键点检测的损失函数,第二项表示其余各子任务的损失函数,其中
λa
表示任务a的重要性因子。针对人脸关键点检测任务,本文结合了四个子任务,分别是:性别、是否带眼镜、是否微笑和脸部的姿势,最终目标函数为:
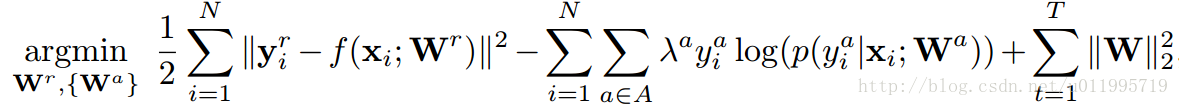
其中,第一项是平方和误差,表示人脸关键点损失函数,第二项是分类任务,采用的是交叉熵误差,第三项即正则项。
针对多任务学习的另外一个问题——各任务收敛速度不同,本文提出一种新的提前停止(Early Stopping)方法。当某个子任务达到最好表现以后,这个子任务就对主任务已经没有帮助,就可以停止这个任务。文章给出自动停止子任务的计算公式,如下:
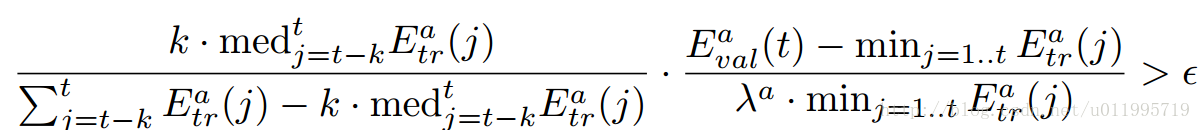
其中, Eatr 表示训练得误差, Eaval 表示验证的误差, ε 为阈值,第一项表示训练误差的趋势,第二项表示泛化误差与训练误差之比,当两项之积大于阈值 ,则该任务停止。
TCDCN采用多任务学习方法对人脸关键点进行检测,针对多任务学习在人脸关键点检测任务中的两个主要问题——不同任务学习难易程度不同以及不同任务收敛速度不同,分别提出了新目标函数和提前停止策略加以改进,最终在AFLW和AFW数据集上获得领先的结果。同时对比于级联CNN方法,在Intel Core i5 cpu上,级联CNN需要0.12s,而TCDCN仅需要17ms,速度提升七倍有余。
随笔:
TCDCN是借助了MTL(多任务学习)机制,有效将面部属性(如:性别,是否戴眼镜,微笑与否,面部姿势)结合到人脸关键点检测任务上。
理论支撑:在进行人脸特征点检测任务时,结合一些辅助信息可以帮助更好的定位特征点。
TCDCN与TCNN是否有相似之处? 都是在面部属性上做文章,TCNN是将fc层的特征进行聚类(感觉是个绕了弯的trick,肯定是能把不同属性的sample聚到一簇里的啦,何必从fc层的特征去做?),然后依据不同面部属性分别的训练一个输出层;而TCDCN则是只训练一个输出层,只不过在训练时,有了四个子任务loss的辅助,给主任务做一定的“指导”。
参考博客推荐:
http://blog.csdn.net/tinyzhao/article/details/52730553(TCDCN)
http://blog.csdn.net/qq_28618765/article/details/78128619(TCDCN)















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









