







 本文是吴恩达斯坦福大学机器学习课程第8周笔记,重点讲解无监督学习中的聚类算法K-means及其优化方法,包括K-means的目标函数、初始化策略和选择类别数的策略。同时介绍了主成分分析PCA,阐述PCA的作用、计算过程和应用场景,以及如何选择PCA的维度k。内容涵盖K-means的实践应用和PCA在数据压缩、可视化中的价值。
本文是吴恩达斯坦福大学机器学习课程第8周笔记,重点讲解无监督学习中的聚类算法K-means及其优化方法,包括K-means的目标函数、初始化策略和选择类别数的策略。同时介绍了主成分分析PCA,阐述PCA的作用、计算过程和应用场景,以及如何选择PCA的维度k。内容涵盖K-means的实践应用和PCA在数据压缩、可视化中的价值。

coursera-斯坦福-机器学习-吴恩达-第8周笔记-无监督学习
对于无监督学习我们主要学习两种算法:聚类(K-means)和维度约简(PCA法)。
1聚类算法clutering
1.1聚类算法简介
无监督学习:我们面对的是一组无标记的训练数据, 数据之间, 不具任何相关联的标记。如图:
[外链图片转存失败(img-VKkgpvIU-1566960756437)(http://oqy7bjehk.bkt.clouddn.com/17-12-16/62891890.jpg)]
我们得到的数据 看起来像这样:一个数据集, 一堆数据点,但没有任何标记以供参考。所以从训练数据中, 我们只能看到 x 1、 x 2… 等等… 到 x(m) 没有任何标记 y 供参考。
就此数据而言, 其中一种可能的结构 是 所有的数据 可以大致地划分成 两个类或组。 因此,像我介绍的 这种划分组的算法, 称为
聚类算法。 这是我们第一种 无监督学习算法。
记住,聚类算法clutering只是无监督学习的一种,不是所有的无监督学习都是聚类算法
1.2K-means
K-means也是聚类算法中最简单的一种。但是里面包含的思想却是不一般。
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
-
随机选取k个聚类质心点(cluster centroids)为
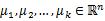 。
。 -
重复下面过程直到收敛 {
- 对于每一个样例i,计算其应该属于的类
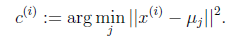
- 对于每一个类j,重新计算该类的质心
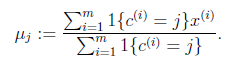
}
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

一个练习题:
[外链图片转存失败(img-F2eVM398-1566960756443)(http://oqy7bjehk.bkt.clouddn.com/17-12-16/7484812.jpg)]
1.2.1kmeans的目标函数
在大多数我们已经学到的 监督学习算法中。 算法都有一个优化目标函数 或者某个代价函数(又叫:畸变函数)需要通过算法进行最小化 。
事实上 K均值也有 一个优化目标函数或者 需要最小化的代价函数。
注意,这个值只会随着迭代下降,不会上升。
1.2.2随机初始化
这一节我们讨论: 如何避开局部最优来构建K均值聚类方法 。
有几种不同的方法 可以用来随机 初始化聚类中心 ,但是 事实证明, 有一种方法比其他 大多数方法 更加被推荐。
[外链图片转存失败(img-vBXgequh-1566960756446)(http://oqy7bjehk.bkt.clouddn.com/17-12-18/20474706.jpg)]
可以避免 可能局部,获得全局最优的结果 。
1.2.3选择类别数
讨论一下 K-均值聚类的最后一个细节 :我想选择聚类数目的更好方法。 或者说是如何去选择 参数大写K的值 。
说实话 这个问题上没有一个 非常标准的解答 、或者能自动解决它的方法。
目前用来决定聚类数目的 最常用的方法 ,仍然是通过看可视化的图, 或者看聚类算法的输出结果 ,或者其他一些东西来手动地决定聚类的数目。
两种常见方法:
- 肘部法则
例如下面的例子,分别考虑3和5,画出loss图像。
[外链图片转存失败(img-FTukxHBG-1566960756447)(http://oqy7bjehk.bkt.clouddn.com/17-12-18/26571725.jpg)]
- 从后续需求(生意)角度考虑
[外链图片转存失败(img-zzShPOzB-1566960756449)(http://oqy7bjehk.bkt.clouddn.com/17-12-18/6770429.jpg)]
下面有个练习题:
[外链图片转存失败(img-l4rl1wkt-1566960756450)(http://oqy7bjehk.bkt.clouddn.com/17-12-18/21753139.jpg)]
1.3考试quiz
- For which of the following tasks might K-means clustering be a suitable algorithm? Select all that apply.答案ad
- From the user usage patterns on a website, figure out what different groups of users exist.
- Given historical weather records, predict if tomorrow’s weather will be sunny or rainy.
- Given many emails, you want to determine if they are Spam or Non-Spam emails.
- Given a set of news articles from many different news websites, find out what are the main topics covered.
-
第二题:
[外链图片转存失败(img-JQP9TP0N-1566960756451)(http://oqy7bjehk.bkt.clouddn.com/17-12-18/43376572.jpg)] -
K-means is an iterative algorithm, and two of the following steps are repeatedly carried out in its inner-loop. Which two?
K-means是一种迭代算法,以下两个步骤在其内部循环中重复执行。哪两个?
- The cluster assignment step, where the parameters c(i) are updated.
- Move the cluster centroids, where the centroids μk are updated.
- Suppose you have an unlabeled dataset {x(1),…,x(m)}. You run K-means with 50 different random initializations, and obtain 50 different clusterings of the data. What is the recommended way for choosing which one of these 50 clusterings to use?答案C
- Plot the data and the cluster centroids, and pick the clustering that gives the most “coherent” cluster centroids.
- Manually examine the clusterings, and pick the best one.
- Compute the distortion function J(c(1),…,c(m),μ1,…,μk), and pick the one that minimizes this.
- Use the elbow method.
- 第 5 个问题 Which of the following statements are true? Select all that apply.答案BC
- Since K-Means is an unsupervised learning algorithm, it cannot overfit the data, and thus it is always better to have as large a number of clusters as is computationally feasible.
- If we are worried about K-means getting stuck in bad local optima, one way to ameliorate (reduce) this problem is if we try using multiple random initializations.-
- For some datasets, the “right” or “correct” value of K (the number of clusters) can be ambiguous, and hard even for a human expert looking carefully at the data to decide.
- The standard way of initializing K-means is setting μ1=⋯=μk to be equal to a vector of zeros.
2 维数约减 (dimensionality reduction)
这节开始介绍 第二种无监督学习问题 它叫维数约减 (dimensionality reduction) 。
我们希望使用维数约简 的原因有以下几个 :
- 一个原因是数据压缩。
数据压缩不仅通过 压缩数据使得数据 占用更少的计算机 内存和硬盘空间, 它还能给算法提速 它还能给算法提速 。 - 另一个原因就是可视化。通过降维进行可视化,进而更好地
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









