






结构体是一种复合数据类型,通常编译器会自动的进行其成员变量的对齐,已提高数据存取的效率。在默认情况下,编译器为结构体的成员按照自然对齐(natural alignment)条方式分配存储空间,各个成员按照其声明顺序在存储器中顺序存储。自然对齐是指按照结构体中成员size最大的对齐,在cl编译器下可以使用
#pragma pack(n)来指定结构体的对齐方式。
默认对齐方式
在默认对齐方式下,结构体成员的内存分配满足下面三个条件
- 结构体第一个成员的地址和结构体的首地址相同
- 结构体每个成员地址相对于结构体首地址的偏移量(offset)是该成员大小的整数倍,如果不是则编译器会在成员之间添加填充字节(internal adding)。
- 结构体总的大小要是其成员中最大size的整数倍,如果不是编译器会在其末尾添加填充字节(trailing padding)。
下面是一个示例:
struct s1{
char ch;
int a;
double b;
char c1;
};
struct s2{
char ch;
int a;
double b;
};
int main()
{
cout << "s1的大小: " << sizeof(struct s1) << endl;
cout << "ch的地址偏移是 " << offsetof(s1, ch) << endl;
cout << "a 的地址偏移是 " << offsetof(s1, a) << endl;
cout << "b 的地址偏移是 " << offsetof(s1, b) << endl;
cout << "c1的地址偏移是 " << offsetof(s1, c1) << endl;
cout << "=====================================" << endl;
cout << "s2的大小: " << sizeof(struct s2) << endl;
cout << "ch的地址偏移是 " << offsetof(s2, ch) << endl;
cout << "a 的地址偏移是 " << offsetof(s2, a) << endl;
cout << "b 的地址偏移是 " << offsetof(s2, b) << endl;
getchar();
return 0;
} 代码中 offsetof函数可以得到结构体成员相对于该结构体首地址的偏移量。
其运行结果如下图
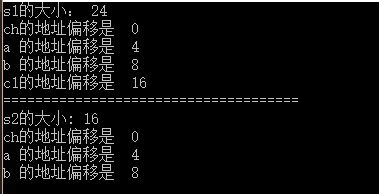
对于结构体s1来说,
- ch是其第一个成员故其地址和结构体的地址是相同的也就是说偏移量为0;
- a是int型其大小为4个字节,按照条件(2) 结构体每个成员地址相对于结构首地址的偏移量(offset)是该成员大小的整数倍,如果不是则编译器会在成员之间添加填充字节,所以其地址偏移应该是4,也就说编译器在第一个成员ch后面填充了3个字节。
- b是double型占8个字节,其地址偏移应该是8的整数倍,由于a的地址偏移是4其大小为4个字节,正好b的偏移地址是8,不需要填充字节。
- c1是char型占1个字节,偏移地址是16(b的偏移地址是8大小也是8,中间也没有填充字节)。
- 这时成员ch占1个字节后面有3个字节的填充,a占4个字节后面无填充,b占8个字节后面无填充,c1占1个字节,s1总的大小是
1+3+4+8+1=17
1+3+4+8+1=17。按照条件(3)结构体总的大小需是其最大成员所占空间的整数倍,其最大的成员b占有8字节,17显然是不符合条件的,所以需要在结构体的末尾填充7个字节,最后结构体总的大小是24字节。
结构体s2和s1的成员是非常相似的,唯一的区别是其末尾没有最后7个字节的填充,所以其大小是16个字节,这里用于和s1做对比说明s1末尾的填充字节。
指定对齐方式
可以使用#pragma pack(N)来指定结构体成员的对齐方式
对于指定的对齐方式,其成员的地址偏移以及结构的总的大小也有下面三个约束条件
- 结构体第一个成员的地址和结构体的首地址相同
- 结构体每个成员的地址偏移需要满足:N大于等于该成员的大小,那么该成员的地址偏移需满足默认对齐方式(地址偏移是其成员大小的整数倍);N小于该成员的大小,那么该成员的地址偏移是N的整数倍。
- 结构体总的大小需要时N的整数倍,如果不是需要在结构体的末尾进行填充。
- 如果N大于结构体成员中最大成员的大小,则N不起作用,仍然按照默认方式对齐。
示例仍然是上面的s1和s2,不过使用
#pragma pack(4) 设定按照4字节对齐
运行结果
结果分析
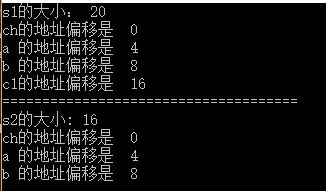
- ch是其第一个成员故其地址和结构体的地址是相同的也就是说偏移量为0;
- a占4个字节,和设定的对齐方式相等,所以其地址偏移是其大小的整数倍为4。
- b占8个字节,大于设定的对齐方式4,所以其地址偏移是N的整数倍为8。
- c1占1个字节,小于设定的对齐方式,所以其地址偏移是其大小的整数倍为16。
- 总的大小17个字节,不是N(4)的整数倍,所以在结构体的末尾填充3个字节,总的大小为20个字节。
说明:
- 在使用#pragma pack设定对齐方式一定要是2的整数幂,也就是(1,2,4,8,16,...),不然不起作用的,仍然按照默认方式对齐。
- 当结构体中有其他的结构体作为成员时,计算最大成员是不能把结构体成员作为一个整体来计算,要看其每个成员的大小。















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









