







距离《DeepSeek实战指南:AI股票分析软件》系列文章的上次更新已过去两个月。在此期间,我利用工作之余完成了基础框架的搭建。五一假期后,本系列将恢复定期更新节奏,所有技术实现细节将继续以完全免费的形式公开分享。上一篇地址:DeepSeek实战指南:AI股票分析软件(二)—— 股票数据API功能对比与选型策略_tushare收费标准-CSDN博客
一、 业务需求分析

当前技术路线聚焦于自主数据采集+AI分析的组合方案。通过对比其他AI股票分析(如扣子空间等),发现现有方案普遍存在两个问题:
-
过度依赖预置AI接口,数据控制力不足
-
动态页面处理能力有限,扩展性较差
1.1 借助DeepSeek需求分析
把上面的图片上传DeepSeek,基于DeepSeek的辅助分析,明确以下实现路径:
输入模块
公司名称/网站:支持手动输入或链接导入。
要求描述:通过NLP解析用户需求(如行业关键词、财务指标、风险偏好等)。
关联分析:自动提取关键词(如“光伏”“新能源”),关联产业链及对应股票(如通威股份)。
数据处理与抓取
多源数据整合:
企业数据:社保人数、中标项目(对接政府招标平台、天眼查/企查查API)。
司法数据:裁判文书网、企业信用公示系统。
舆情信息:新闻(新浪财经、雪球)、社交媒体(微博、Twitter)、论坛(股吧、Reddit)。
实时更新:通过爬虫和API实现动态数据监控(如每日舆情热度)。
分析引擎
产业链图谱:构建行业知识图谱,分析上下游关联企业。
热度指数模型:基于舆情数据(情感分析+传播量)生成概念热度排名。
风险评估:结合司法数据、财务指标(如负债率)提示潜在风险。
输出模块
推荐列表:
热点概念:当前市场热点(如“AI芯片”“碳中和”)。
关联股票:产业链相关标的及关联度评分。
热度指数:实时舆情热度(0-100分)。
可视化报告:图表展示企业社保趋势、中标项目分布、司法风险雷达图。
然后我们继续让DeepSeek深入分析:
1. 数据获取:多渠道整合公开信息
企业基础数据(社保人数、司法记录、中标项目):
工具:天眼查/企查查API(付费接口直接获取结构化数据)、政府公开招标平台爬虫(如使用
requests抓取网页表格)。股票数据(股价、财务指标):
工具:免费金融API(如Tushare、AKShare),直接调用接口获取实时或历史数据。
舆情信息(新闻、社交媒体、论坛讨论):
工具:爬虫(如
BeautifulSoup抓取新闻标题) + 公开API(如新浪财经RSS、Twitter开发者接口)。2. 数据处理与分析:简单AI模型驱动
数据清洗:
去重(如删除重复新闻)、格式标准化(如统一日期格式)、异常值处理(如剔除极端股价波动)。
关键分析模块:
情感分析:用预训练模型(如Hugging Face的
transformers库)判断舆情正负面。热度计算:统计关键词(如“光伏”“AI芯片”)在新闻/社交媒体的出现频率,生成热度指数。
风险识别:基于司法数据(如裁判文书数量)和财务指标(如资产负债率)标注风险等级。
推荐逻辑:
简单规则:结合“舆情正面 + 近期股价上涨 + 低风险”筛选股票。
进阶方案:用机器学习(如
scikit-learn的随机森林)预测短期涨跌趋势。3. 用户交互:轻量级界面设计
输入功能:
文本框:用户输入公司名称或行业关键词(如“新能源”)。
下拉菜单:选择分析维度(如“风险偏好”“短期/长期投资”)。
输出展示:
推荐列表:表格形式展示股票名称、关联行业、热度指数、风险提示。
可视化图表:用Python库(如
matplotlib或Plotly)生成趋势图(如舆情热度变化、股价走势)。工具选择:
本地应用:用
Streamlit(Python库)快速搭建交互网页,无需前端知识。部署方式:本地运行或简单服务器托管(如PythonAnywhere)。
4. 实现流程总结
数据抓取 → 2. 清洗存储 → 3. 分析建模 → 4. 生成推荐 → 5. 界面展示
5. 注意事项
合规性:仅使用公开数据,避免隐私问题;添加免责声明(如“不构成投资建议”)。
轻量化:优先调用现成API和预训练模型,避免从零开发复杂算法。
迭代优化:先从简单规则(如“热度+风险”)开始,后续逐步加入机器学习模型。
二、 数据采集模块
万丈高楼平地起,接下来主要实现数据采集这一步。
2.1 开源爬虫管理平台对比
通过DeepSeek推荐+实际验证,形成开源项目对比表:
| 框架 | 核心优势 | 适用场景 | 环境管理方案 |
|---|---|---|---|
| Crawlab | 分布式任务调度 | 企业级复杂项目 | Docker容器化 |
| Gerapy | Scrapy深度集成 | Python爬虫项目 | 虚拟环境隔离 |
| TaskPyro | 轻量级任务编排 | 中小型项目 | Conda环境切换 |
| Crawlee | 浏览器自动化支持 | 动态页面采集 | Playwright集成 |
2.2 开发进度
基础框架的话我找了一个开源的项目基于fastapi的ruoyi项目,爬虫使用crawl4ai,先看一下爬虫的主要架构以及项目、爬虫、任务、调度器、节点的关系。
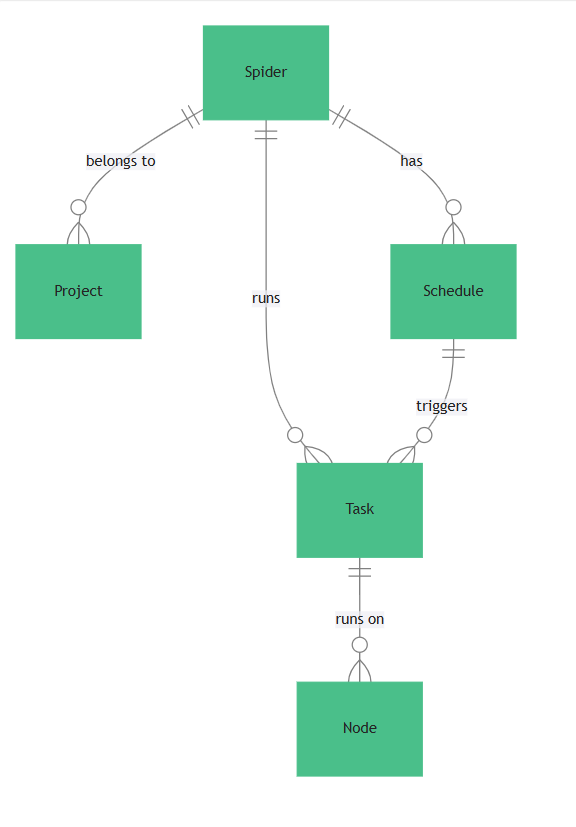
整个平台的实现流程如下:
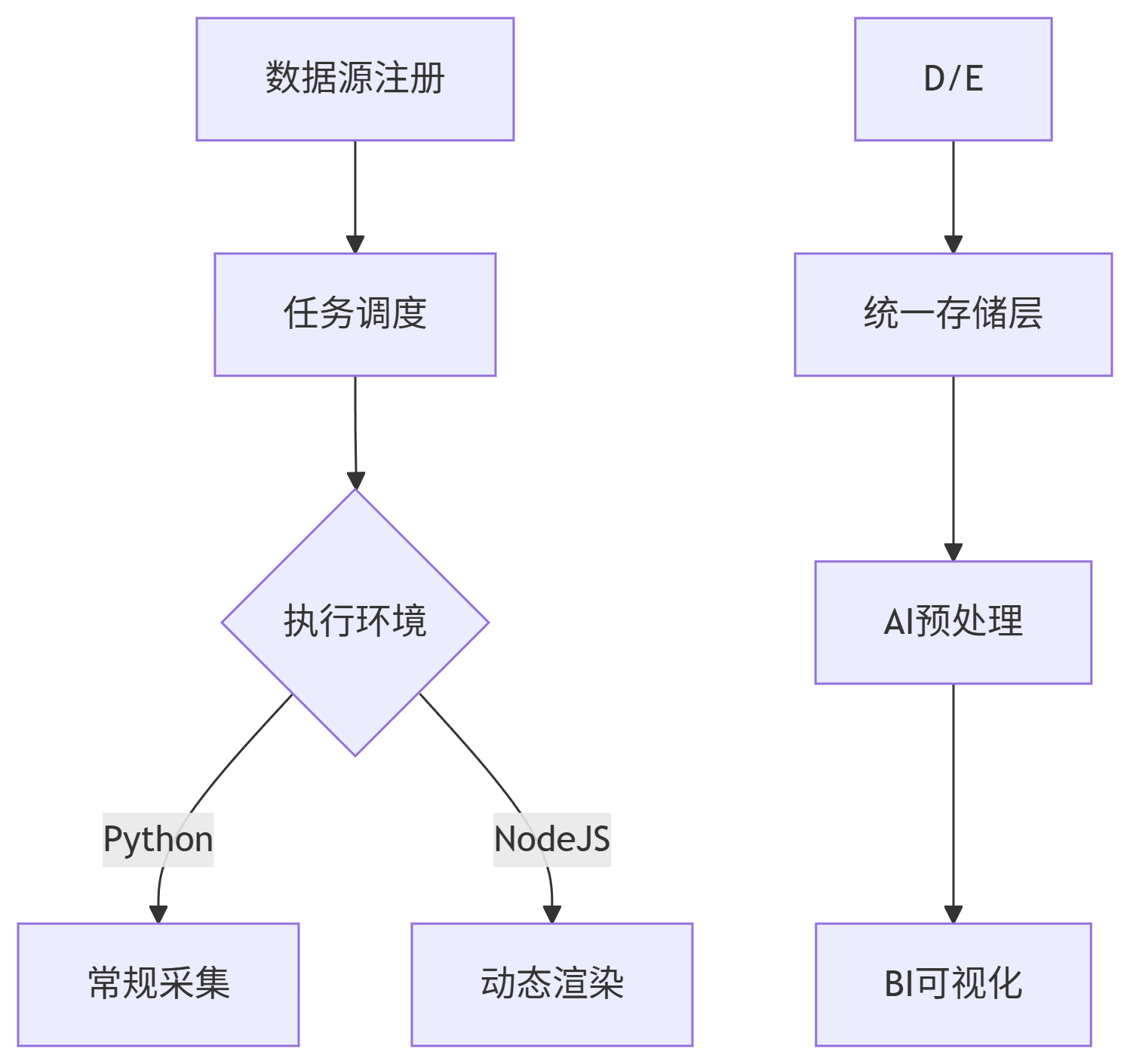
爬虫管理系统采用的技术栈:
-
后端框架:基于RuoYi改造的FastAPI服务
-
核心组件:Crawl4ai网页解析器 + Celery任务队列
-
数据存储:MongoDB文档数据库(分集合存储原始数据)
-
文件存储:MinIO对象存储(PDF/图片等二进制文件)
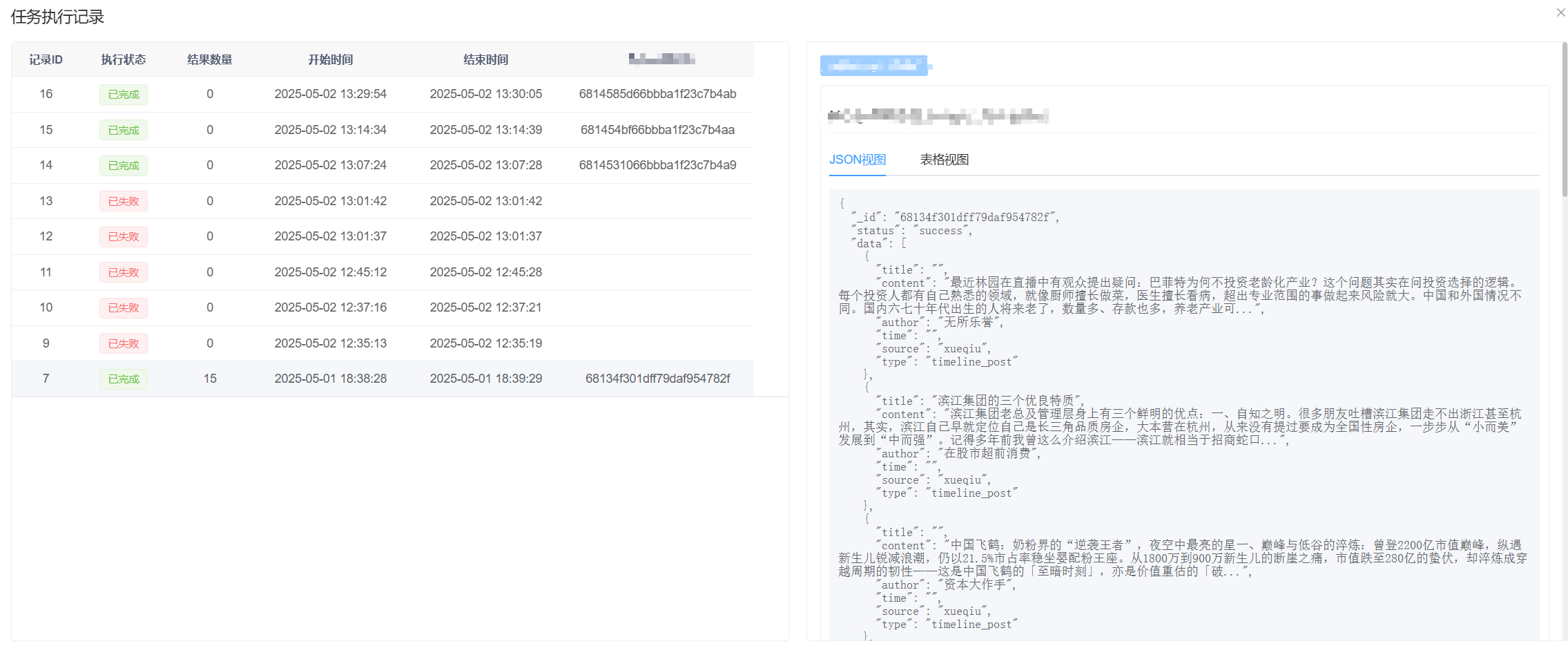
下面展示一下完成的功能和页面,主要涉及:
- 爬虫管理,如爬虫上传、在线编辑、在线调试
- 爬虫任务管理,手动执行、停止、数据查看、日志查看


三、接下来计划
-
支持API调用与爬虫任务混合调度
-
增加任务异步调度
-
数据分析验证:数据采集->财务指标提取 -> 行业对比分析 -> 可视化报告生成
三、致谢
本项目基于以下开源技术构建:
-
RuoYi-Vue3-FastAPI - 中台管理框架
-
Crawlab - 分布式爬虫管理
-
crawl4ai - 智能解析组件
-
TaskPyro - 环境隔离方案


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











