










对于上次说的LSA模型,它能解决多个单词一个意义,但是不能解决多个意义一个单词,就是多义词的问题,而PLSA模型能较好的解决这个问题,首先说下,这个模型的假设:
1 假设生成一个单词的过程是这样的:首先选择一篇文章di,然后再次基础上选择一个潜变量zk(可以理解为主题),最后在此基础上再在生成一个单词。如果p(di,wj)表示第i个文本中有第j个单词的概率,根据假设有:
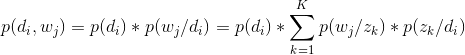
2 另外一个非常重要的假设是,单词wj和文本di是基于潜变量条件独立的,即:
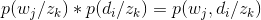
与LSA模型相似,我们首先得到了一个加权词频矩阵(如TF/IDF),接下来可以写出似然函数如下:

其中n(di,wj)表示这个词频矩阵(i,j)的元素值,且对于p(di)这一部分,求和后为常数,可以将其省去(省去后我还是写成L),不影响求最大值。
继续推导:
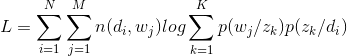
接下来开始EM推导!
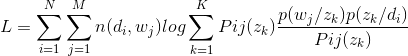
这里Pij(zk)表示第j个单词是由第i篇文档通过zk这个潜在变量生成的概率,根据上一篇文章所说的性质,有:
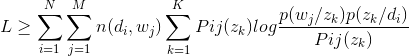
然后根据等号取到的条件,有:
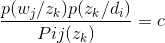
我觉得有必要说明的一点是,对于任意的i,j,k这个式子的结果都是一个常数c,但是并不是说对于任意i,j,k,这个c是相同的,所以这里不能提取出常数c,但是无论c是多少,下面的步骤都是可以的。
并且分子分母都按照sigma zk求和,有:
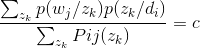
和之前一样有分子等于1,那么分母等于c,将分母代回上面那个式子,得到:
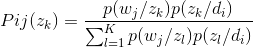
这里说下我遇到的一个困惑,我当初看的那篇论文中,并没有按照EM推导的步骤,而是不知道通过什么途径(我没看懂)得到了Pij(zk)=P(zk/wi,dj),然后利用贝叶斯公式和条件独立的假设,得到:
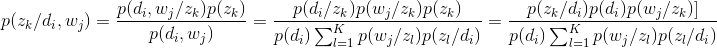
分子分母约掉p(di)就得到了和Pij(zk)相同的结果,这里略为困惑,不过好在结果是一样的。
最终的结果为:
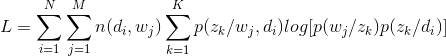
接下来就是开始EM算法的迭代了:
E步:随机选取(初始情况下)或者由上一步M得到参数p(zk/di)(总共K*N个),p(wj/zk)(总共K*M个),计算出p(zk/wi,dj)。
M步: p(zk/wi,dj)由p(zk/di)和p(wj/zk)替代后,求L的最大值,它是以p(zk/di),p(wj/zk)为参数的,且p(zk/di),p(wj/zk)符合这一定的限制条件,有:
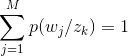

这个问题可以用拉格朗日乘子法求解,求解过程非常复杂,结果如下:
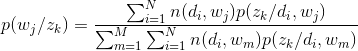
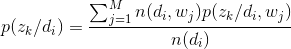
E步和M步交替执行,直到收敛。
收敛后我们可以用得到的两个概率矩阵进行一些比如文本聚类,单词聚类等处理。















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









