







 本教程展示了如何使用TensorFlow2训练一个序列到序列模型进行英语到西班牙语的翻译。模型基于注意力机制,包括编码器和解码器。数据集经过预处理,模型训练后可以输出翻译结果并可视化注意力图。
本教程展示了如何使用TensorFlow2训练一个序列到序列模型进行英语到西班牙语的翻译。模型基于注意力机制,包括编码器和解码器。数据集经过预处理,模型训练后可以输出翻译结果并可视化注意力图。
Copyright 2019 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
基于注意力的神经机器翻译
| |
|
 在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
|
Note: 我们的 TensorFlow 社区翻译了这些文档。因为社区翻译是尽力而为, 所以无法保证它们是最准确的,并且反映了最新的
官方英文文档。如果您有改进此翻译的建议, 请提交 pull request 到
tensorflow/docs GitHub 仓库。要志愿地撰写或者审核译文,请加入
docs-zh-cn@tensorflow.org Google Group。
此笔记本训练一个将西班牙语翻译为英语的序列到序列(sequence to sequence,简写为 seq2seq)模型。此例子难度较高,需要对序列到序列模型的知识有一定了解。
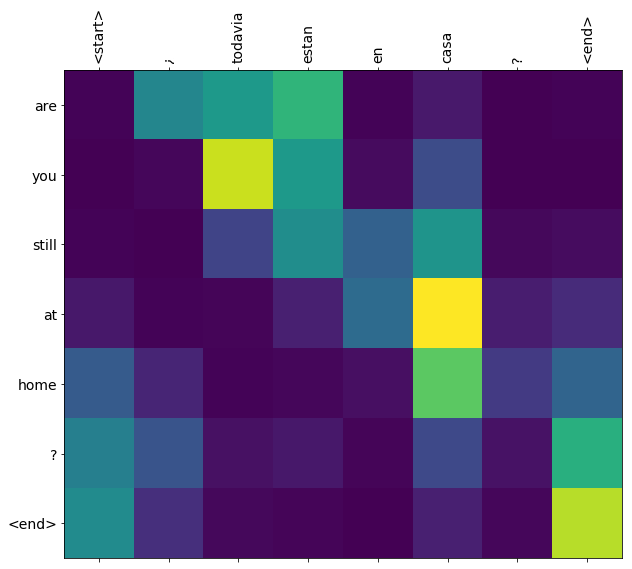
训练完此笔记本中的模型后,你将能够输入一个西班牙语句子,例如 “¿todavia estan en casa?”,并返回其英语翻译 “are you still at home?”
对于一个简单的例子来说,翻译质量令人满意。但是更有趣的可能是生成的注意力图:它显示在翻译过程中,输入句子的哪些部分受到了模型的注意。
请注意:运行这个例子用一个 P100 GPU 需要花大约 10 分钟。
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.model_selection import train_test_split
import unicodedata
import re
import numpy as np
import os
import io
import time
下载和准备数据集
我们将使用 http://www.manythings.org/anki/ 提供的一个语言数据集。这个数据集包含如下格式的语言翻译对:
May I borrow this book? ¿Puedo tomar prestado este libro?
这个数据集中有很多种语言可供选择。我们将使用英语 - 西班牙语数据集。为方便使用,我们在谷歌云上提供了此数据集的一份副本。但是你也可以自己下载副本。下载完数据集后,我们将采取下列步骤准备数据:
- 给每个句子添加一个 开始 和一个 结束 标记(token)。
- 删除特殊字符以清理句子。
- 创建一个单词索引和一个反向单词索引(即一个从单词映射至 id 的词典和一个从 id 映射至单词的词典)。
- 将每个句子填充(pad)到最大长度。
# 下载文件
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = os.path.dirname(path_to_zip)+"/spa-eng/spa.txt"
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip
2646016/2638744 [==============================] - 0s 0us/step
# 将 unicode 文件转换为 ascii
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
# 在单词与跟在其后的标点符号之间插入一个空格
# 例如: "he is a boy." => "he is a boy ."
# 参考:https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# 除了 (a-z, A-Z, ".", "?", "!", ","),将所有字符替换为空格
w = re.sub(r"[^a-zA-Z?.!,¿]+", " ", w)
w = w.rstrip().strip()
# 给句子加上开始和结束标记
# 以便模型知道何时开始和结束预测
w = '<start> ' + w + ' <end>'
return w
en_sentence = u"May I borrow this book?"
sp_sentence = u"¿Puedo tomar prestado este libro?"
print(preprocess_sentence(en_sentence))
print(preprocess_sentence(sp_sentence).encode('utf-8'))
<start> may i borrow this book ? <end>
b'<start> \xc2\xbf puedo tomar prestado este libro ? <end>'
# 1. 去除重音符号
# 2. 清理句子
# 3. 返回这样格式的单词对:[ENGLISH, SPANISH]
def create_dataset(path, num_examples):
lines = io.open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')] for l in lines[:num_examples]]
return zip(*word_pairs)
en, sp = create_dataset(path_to_file, None)
print(en[-1])
print(sp[-1])
<start> if you want to sound like a native speaker , you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo . <end>
<start> si quieres sonar como un hablante nativo , debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un musico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado . <end>
def max_length(tensor):
return max(len(t) for t in tensor)
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(
filters='')
lang_tokenizer 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









