






阅读提示:
本篇文章于2023年底尝试挖掘并探寻以ChatGPT为代表的LLMs和以AlphaGO/AlphaZero及当下AlphaDev为代表的Alpha系列之间的AR和RL思想的背后底层理论及形式上的统一,同时尝试基于去年OpenAI暴露出的project Q*可能的关于推理过程学习再到系统①(快)思考与系统②(慢)思考的形式化统一的延展性思考,以展望当下面向未来AGI路径可行性...正如前几日AI一姐李飞飞教授所说,人工智能即将迎来它的「牛顿时刻」...
本篇文章拟分为「上篇」「中篇」「下篇」,因为文章内容整体比较冗长,也许会给大家造成一定的阅读困扰,但仍希望大家能够阅读下去,内容上尽量采用简单通俗的表述,其中文章囊括了诸如强化学习「RL」、自回归「AR」大语言模型「 LLMs」等技术领域深刻内涵思考,穿插关联了丰富的计算机科学/数学/物理学/哲学/心理学等领域跨学科内容,回顾了人工智能近现代发展历史,并在部分章节中以作者视角回顾总结过去一年中大模型给自己带来的思想冲击...大家如有疑问困惑和不同看法也非常欢迎评论指正或直接如流探讨,感谢!
本文原创作者: 吕明
如流ID:lvming01
Wechat:lvming6755
知乎:吕明 - 知乎
大家想要回顾 「上篇」「中篇」可访问如下链接:
「上篇」 融合RL与LLM思想,探寻世界模型以迈向AGI-CSDN博客
「中篇」 融合RL与LLM思想,探寻世界模型以迈向AGI-CSDN博客

「下篇」
-
这里不得不非常诚恳的向大家道歉,在发布「上篇」时你定的「下篇」的大纲内容将不再做非常细节的展开论述了,而只做一些简单的说明。
-
一方面确实是因为篇幅所限,截止当前全文似乎已经达到6万5千+字..相信不光是对我自己也对读者小伙伴们造成了写作和阅读上的非常大的困扰。
-
另一方面,文章的核心要点已经在「中篇」中向大家进行了详细论述和阐释,心愿也了了:)
-
同时,在写作中篇的过程中以及完成写作之后,发现很多本质的一些观点都有着不同的探寻方式和理解角度,因此,我也希望大家也不要被我的思想所禁锢,希望在「下篇」中所表露表露的一些其他方面的本质,读者小伙伴可以发挥自由意志各自尝试探寻,我在问题「上篇」和「中篇」当中的思想可作为大家借鉴参考之用。
-
对了,需要跟大家提前说明的是,「下篇」中的很多小章节中,内容都是相对比较轻松的主题,也缓和一下大家在阅读「上篇」和「中篇」时的那种枯燥的概念和逻辑。
-
最后,希望大家有任何问题也可随时与我取得联系,我非常愿意为大家进行开放的探讨和交流,先握个爪+拳掌相扣下
盘道了辣么多,本篇的目的是什么?
下面列出了最开始我的一些想法和目的,大家可以结合我在「上篇」和「中篇」中的内容,简单思考和回味下如下问题,我相信在「上篇」和「中篇」的某些位置可能有大家的答案
-
探究以泛GPT为代表的预训练自回归编码模型(即LLM)与泛Alpha系列为代表的RL的本质普遍性及表象差异性,以及为什么要将其两者联系起来?
-
鉴于LLM与RL两者间的差异化能力考量,业内不少的思路尝试将两种方法结合在一起,但结合后要么看着不是很巧妙,要不就是看起来很僵硬,总感觉像是一个过渡性的结合,并且看起来并没有以终为始,也不是原生的思想与方法的融合,因此想要尝试探寻一下两种学习方法是否能更巧妙的相互结合与统一。
-
探究思维系统的两种推理模式:系统Ⅰ(快系统)和系统Ⅱ(慢系统)在推理过程的本质普遍性及表象差异性,以及快慢思考是否与两类学习方法(LLM/RL)存在着某种关联?Agent在其中的内涵与定位是什么?
-
Prompt对于LLM来说其意义是什么,Prompt Learning给我们的更深一层的提示是什么?Meta Learning又是什么鬼?
-
模型中知识或模式的迁移及泛化能力代表了什么?
-
LLM的路径能达到一个真正意义上的世界模型WM并成为AGI甚至是ASI吗?WHY?HOW?
-
AI4S是否能带来科学突破?不光是改变研究范式,甚至是触达到探索知识的另一片天空之城?
精神的助产士 · 苏格拉底的追问模式
基于真实用户与 ChatGPT 的互动,通过反转学习目标(从学习回复到学习提问),训练更贴近真实用户的模拟器,更好的提问质量可以激发 ChatGPT 的更大潜力。在流行的 Alpaca Eval benchmark 超过 GPT 3.5,在 MT-bench 上得分 6.33,强于 Vicuna 新版。在这两个 benchmark 都是是基于 LLaMA 2 7B 底座的 SOTA。
如我们我们前文所说,用于训练数据的分布是否贴近推理时的使用场景同样影响训练后的助手模型能性。
因此,香港中文大学(深圳)和深圳市大数据研究院所在的王本友教授团队,通过在高质量的人机对话数据集 ShareGPT 上,仅计算人类提问的损失来反转学习目标,基于 LLaMA 基座,全微调训练出一个名为 “Socratic(苏格拉底的信徒)”的用户模拟器(也就是上文中的 Anuciv)。随后,通过迭代调用 Socratic 与 ChatGPT 获得了高度类人的人机对话数据集 SocraticChat,并在该数据集上训练出表现优越的助手模型 PlatoLM。

文章思路利用苏格拉底式提问采取老师教学生这个经典方法,通过连续提问来充分激发学生的能力,促进学生的思考。在大模型训练的场景是,学习一个用户模拟器专门去给 ChatGPT/GPT4 助手模型连续提问,通过学习助手模型的输出来高效蒸馏一个开源模型。在苏格拉底式提问中,苏格拉底的下一轮问题可以比上一轮更复杂,更具体或者联想到更高层次,以此充分帮助学生思考并做出更好的回复。
该论文提出的模拟器训练方法,可以使用户模拟器在基于上下文背景下持续追问,与在无上下文背景下自主提问之间灵活切换,这使其不仅具有良好的迁移领域的能力,将任何单轮对话扩展成多轮形式,还能够扩展 ShareGPT 数据集的规模和多样性。
此外,他们发现,Socratic 提出的问题的复杂性可以随着多轮对话的进行循序渐进地提高,并由此激发 ChatGPT 自动 ICL 的能力,这与苏格拉底式质疑——通过提问者由浅入深地提问来启发回答者思考的过程——不谋而合。
他们认为经过人类高超的 prompting 技术微调知识丰富的 llama backbone 后的高度类人的模拟器 Socratic 可以类比为苏格拉底,模拟器与 ChatGPT 之间的对话所形成的数据集 SocraticChat 可以类比为对话录(柏拉图所记载的苏格拉底启发人类思考的对话体文集),学习 ChatGPT 的回答的助手模型 PlatoLM 可以类比为柏拉图,整个 pipeline 可以类比为苏格拉底式教学。
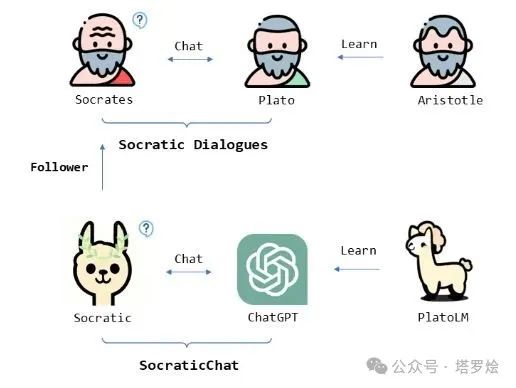
苏格拉底式的交互式prompt给出的模型持续探索的意义,这里似乎是想给大家说明一下系统二·慢思考与苏格拉底的追问模式似乎有着一些底层的联系。
上述这篇paper也在尝试通过以苏格拉底提问的方式与LLMs进行持续交互并探寻问题的解决方案或用于科学洞察与发现,为运用LLMs解决科学问题提供了一定的启发性。
大家捎带也推荐给大家阅读一本书《苏格拉底的申辩》,非常有意思和内涵的一本书,罗翔老师也重磅推荐过的。

华人数学家陶哲轩在天空之城的探索模式
去年7夏天,一篇加州理工和 MIT 研究者用 ChatGPT 证明数学定理的论文爆火,在数学圈引发了极大关注。

英伟达首席科学家 Jim Fan 激动转发,称 AI 数学 Copilot 已经到来,下一个发现新定理的,就是全自动 AI 数学家了!纽约时报近日也发文,称数学家们做好准备,AI 将在十年内赶上甚至超过最优秀的人类数学家,而陶哲轩本人,也转发了此文。

在今年二月,加州大学洛杉矶分校理论与应用数学研究所,曾举行了一场关于「机器辅助证明」的研讨会,研讨会的主要组织者,就是 2006 年的菲尔兹奖得主、在 UCLA 任职的数学家陶哲轩。他指出,用 AI 辅助数学证明,其实是非常值得关注的现象。
直到最近几年,数学家才开始担心 AI 的潜在威胁,无论是 AI 对于数学美学的破坏,还是对于数学家本身的威胁。而杰出的社区成员们,正在把这些问题摆上台面,开始探索如何「打破禁忌」。
2000 多年来,欧几里得的文本一直是数学论证和推理的范式,欧几里得以近乎诗意的「定义」开始,在此基础上建立了当时的数学 —— 使用基本概念、定义和先前的定理,每个连续的步骤都「清楚地遵循」以前的步骤,以这样一种方式证明事物,即公理化系统。

但是到 20 世纪以后,数学家们不愿意再将数学建立在这种直观的几何基础上了,相反,他们开发了正式的系统,这个系统中有着精确的符号表示和机械的规则。
最近,开源证明助手系统 Lean 再次引发了大量关注,Lean 使用的是自动推理,由老式的 AI GOFAI 提供支持,这是一个受逻辑启发的象征式 AI。
紧接着,时三周,陶哲轩成功地用AI工具完成了形式化多项式Freiman-Ruzsa猜想证明过程的工作。他再次呼吁数学研究者学会正确利用AI工具。陶哲轩表示,在整个团队中,自己贡献的代码大概只有5%。这个结果很鼓舞人心,因为这意味着数学家即使不具备Lean编程技能,也能领导Lean的形式化项目。
KeyPoint:
-
陶哲轩成功应用AI工具形式化多项式Freiman-Ruzsa猜想的证明,引起数学界广泛关注。
-
他详细记录了使用Blueprint在Lean4中形式化证明的过程,强调了正确使用AI工具的重要性。
-
利用Blueprint工具,陶哲轩团队分解证明过程,通过众多贡献者并行工作成功形式化了PFR猜想。
-
陶哲轩认为形式化证明的主流化或创造既人类可读又机器可解的证明,将数学演变成一种高效的编程。
-
这一成果引发了对数学研究未来的讨论,一些人认为形式化将成为主流数学中的关键趋势,但陶哲轩提醒不要削弱理解证明的重要性。

同样,这也是去年我认为非常有启发意义的一件事情,试想一下,当LLMs或RL在充分掌握并运用数学的形式化证明体系后,是否会再次迎来数学的春天呢?
而且已经有很多围绕当前LLMs的数学探索工作在进行了,网上这方面的公开发表也很多,大家可以后续关注。
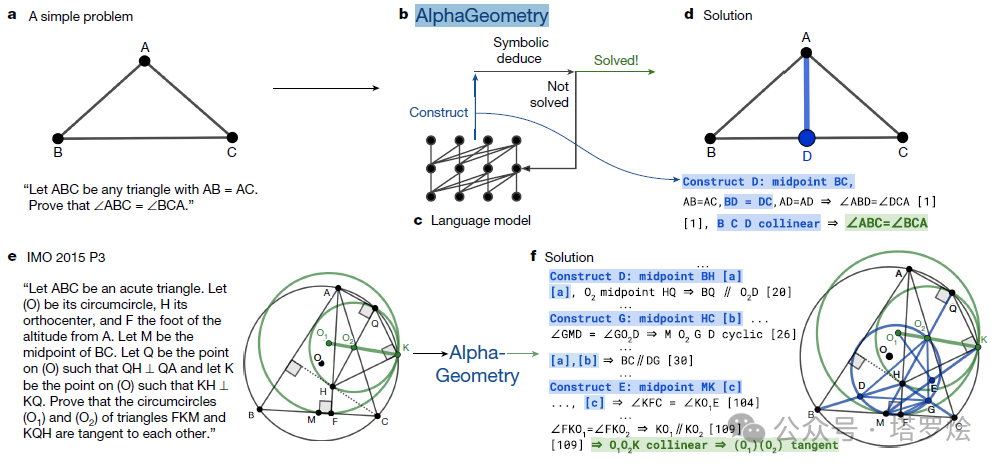
欧几里德的助手 · AI4S之AlphaGeometry
这是DeepMind去年底发布的又一个Alpha系列·AlphaGeometry,其创新展示了一种神经符号方法,通过从头开始的大规模探索来证明定理,避免了对人工注释的证明示例和人工策划的问题陈述的需求。在纯合成数据上生成和训练语言模型的方法为面临相同数据稀缺问题的数学领域提供了一个通用的指导框架。
我们看到,这即是一种尝试通过LLMs与RL构造环境并持续探索过程学习在平面几何上的路径,其提出了一种使用合成数据进行定理证明的替代方法,从而避免了翻译人工提供的证明示例的需要,在其中的数据合成方面,完全由高效的符号推导引擎 DD + AR 可以达到的推导步骤组成,并应用合成数据进行后LLMs预训练。
有兴趣的读者也可以直接搜索精度下里面的内容,也许会收到非常不一样的额外启发,不过也需要对形式化证明有较深刻的认知。
Q*猜想
好吧..终于到它了...Q-star,先来看下去年底来自LeCun的两篇推文...

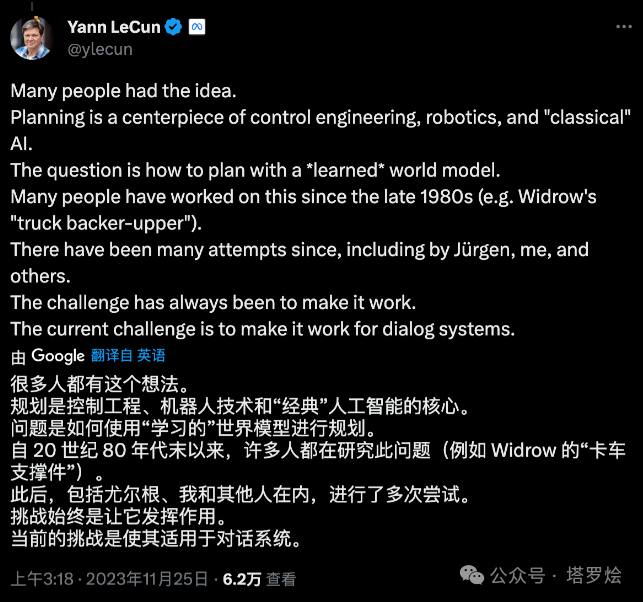
当然,在当前各界,充斥着很多关于Q*猜想的文章或者论文发表,但我猜想,结合本文核心要点内容所述,通往Q*的路途也许是通过LLMs融合RL的方法来进行实现的,尽管这里面会有很多可想而知的大量、复杂前期数据准备工作,而这也是为super alignment做出的必要准备,正如在「中篇」向大家阐释的那样,要想实现对世界中存在着可用token表征的多种模式(pattern)的泛化映射结构,包括系统一、系统二中的直觉与推理pattern,RL中的AI4S的过程pattern,World Models/Sora中的物理世界模拟的pattern,可以想象这里面对于前期数据工程相关工作的挑战还是非常巨大的,但OpenAI一贯善于采用简单暴力的方法来解决,只不过直到现在为止,我们仍不得而知。同时,现在在产业界或学术界也普遍认为Q* 很可能是 Q 强化学习和 A* 搜索这两种 AI 方法的结合。”
回顾:如果大家针对Q*有进一步兴趣,建议大家回顾一下本篇文章的「上篇」和「中篇」中相关内容,也可以为Q*的深入理解有一些铺垫:
其中在「上篇」中的后半部分,提及了相关“由Mistral 基于其微调的Zephyr 7B论文中的AIF+DPO(不同于RLHF PPO的算法)算法的延展性思考”。
在「中篇」其中的RL与LLM本质探寻过程中尝试对这一问题进行了一些更深刻背后理论的阐释,包括从回顾AI历史、当前的RLAIF再到self-play下的超级对齐..并最终给出了基于“tokenize世界中关于数据复杂分布互映射上,并抽象其底层数学概念中的数据流形分布再到认知流形分布的阐释。”
另外,近日(2024/04/26更新补充),斯坦福大学一个团队的一项新研究似乎为这一研究方向的潜力提供了佐证,其声称现在已经取得非凡成就的「语言模型不是一个奖励函数,而是一个 Q 函数!」由此发散思维猜想一下,也许 OpenAI 秘密的 Q* 项目或许真的是造就 AGI 的正确方向(或之一)。相关论文解读及相关论述如下:
近日,斯坦福大学一个团队的一项新研究似乎为这一研究方向的潜力提供了佐证,其声称现在已经取得非凡成就的「语言模型不是一个奖励函数,而是一个 Q 函数!」由此发散思维猜想一下,也许 OpenAI 秘密的 Q* 项目或许真的是造就 AGI 的正确方向(或之一)。

-
论文标题:From r to Q∗: Your Language Model is Secretly a Q-Function
-
论文地址:https://arxiv.org/pdf/2404.12358.pdf
在对齐大型语言模型(LLM)与人类意图方面,最常用的方法必然是根据人类反馈的强化学习(RLHF)。通过学习基于人类标注的比较的奖励函数,RLHF 能够捕获实践中难以描述的复杂目标。研究者们也在不断探索使用强化学习技术来开发训练和采样模型的新算法。尤其是直接对齐方案(比如直接偏好优化,即 DPO)凭借其简洁性收获了不少拥趸。
直接对齐方法的操作不是学习奖励函数然后使用强化学习,而是在上下文多臂赌博机设置(bandit setting)中使用奖励函数与策略之间的关系来同时优化这两者。类似的思想已经被用在了视觉 - 语言模型和图像生成模型中。
尽管有人说这样的直接对齐方法与使用 PPO 等策略梯度算法的经典 RLHF 方法一样,但它们之间还是存在根本性差异。
举个例子,经典 RLHF 方法是使用终点状态下的稀疏奖励来优化 token 层面的价值函数。另一方面,DPO 则仅在上下文多臂赌博机设置中执行操作,其是将整个响应当成单条臂处理。这是因为,虽然事实上 token 是一次性只生成一个,但研究强化学习的人都知道,密集型奖励是有益的。
尽管直接对齐算法颇引人注意,但目前人们还不清楚它们能否像经典强化学习算法那样用于序列。
为了搞清楚这一点,斯坦福这个团队近日开展了一项研究:在大型语言模型中 token 层面的 MDP 设置中,使用二元偏好反馈的常见形式推导了 DPO。
他们的研究表明,DPO 训练会隐含地学习到一个 token 层面的奖励函数,其中语言模型 logit 定义最优 Q 函数或预期的总未来奖励。然后,他们进一步表明 DPO 有能力在 token MDP 内灵活地建模任意可能的密集奖励函数。
这是什么意思呢?
简单来说,该团队表明可以将 LLM 表示成 Q 函数并且研究表明 DPO 可以将其与隐式的人类奖励对齐(根据贝尔曼方程),即在轨迹上的 DPO 损失。
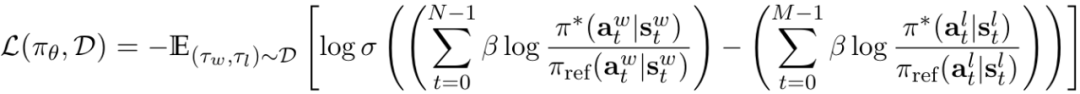
并且他们证明这种表示可以拟合任何在轨迹上的反馈奖励,包括稀疏信号(如智能体应用)。
实验
他们也进行了实验,论证了三个可能对 AI 社区有用的实用见解。
第一,他们的研究表明尽管 DPO 是作为上下文多臂赌博机而派生出来的,但 DPO 模型的隐含奖励可在每个 token 层面上进行解释。
在实验中,他们以定性方式评估了 DPO 训练的模型是否能够根据轨迹反馈学习 credit assignment。有一个代表性示例是商讨工作就职的场景,图 1 给出了两个答案。

其中左边是正确的基础摘要,右边是经过修改的版本 —— 有更高层的职位和相应更高的工资。他们计算了这两个答案的每个 token 的 DPO 等价的奖励。图 1 中的每个 token 标注的颜色就正比于该奖励。
可以看到,模型能够成功识别对应于错误陈述的 token,同时其它 token 的值依然相差不大,这表明模型可以执行 credit assignment。
此外,还可以看到在第一个错误(250K 工资)的上下文中,模型依然为其余 token 分配了合理的值,并识别出了第二个错误(management position)。这也许表明模型具备「缝合(stitching)」能力,即根据离线数据进行组合泛化的能力。该团队表示,如果事实如此,那么这一发现将有助于强化学习和 RLHF 在 LLM 中的应用。
第二,研究表明对 DPO 模型进行似然搜索类似于现在很多研究中在解码期间搜索奖励函数。也就是说,他们证明在 token 层面的阐述方式下,经典的基于搜索的算法(比如 MCTS)等价于在 DPO 策略上的基于似然的搜索。他们的实验表明,一种简单的波束搜索能为基础 DPO 策略带来有意义的提升,见图 2。
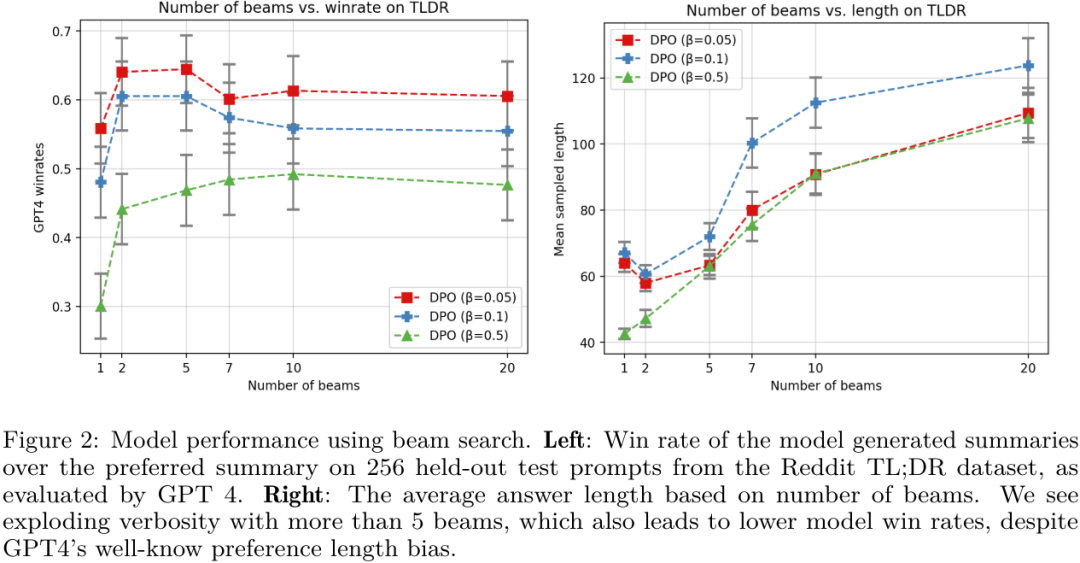
第三,他们确定初始策略和参考分布的选择对于确定训练期间隐性奖励的轨迹非常重要。
从图 3 可以看出,当在 DPO 之前执行 SFT 时,被选取和被拒绝的响应的隐含奖励都会下降,但它们的差距会变大。
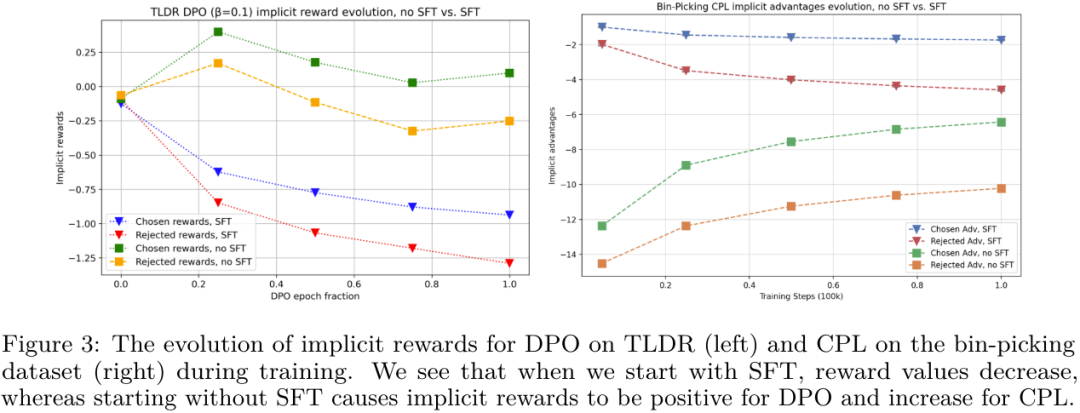
当然,该团队最后也表示,这些研究结果还需要更大规模的实验加以检验,他们也给出了一些值得探索的方向,包括使用 DPO 让 LLM 学会基于反馈学习推理、执行多轮对话、充当智能体、生成图像和视频等。
以下引入融合RL与LLM思想,探寻世界模型以迈向AGI「上篇」中关于引入DPO的回顾:
...首先我们从Self-Play或Synthetic Data本身的意义上尝试进行一下思考的延展,这里由于Synthetic Data本身是建立在Self-Play的机制之上形成的,而Synthetic Data有很多种途径(RLAIF方法中的AI Generate与AI feedback即是其中一种途径),其中Self-Play即是一种看似带有目标场景性的数据生成途径,这个目标场景即是Self-Play中所处的带有一定目标性的模拟环境。而Synthetic Data最终会在后续过程中用于AMIE模型的Fine-Tuning。而为了更深入的理解Fine-Tuning的意义,则需要一步步回溯到合成的数据意义再到如何合成的数据,即数据的合成目标所带来的合成数据对整个模型用于模拟环境中的医学知识与能力空间Fine-Tuning的价值与意义。因此接下来我们将目标聚焦在核心的Self-Play之上。
在本篇论文中,Self-Play采用了类似Multi-Agent的思想,包括Patient Agent、Doctor Agent、Critic以及Moderator等角色,在整个自循环self-play过程中,我们发现经过多角色交互过程,在数据层面会合成扩展更多围绕诊疗环境的多种医疗条件和医学要素,而这些复杂的条件和要素又会作为模型非原始信息作为输入通过多角色进行进一步的模型生成、决策、反思或评判,是的,这里的关键就是这些「合成扩展的非原始信息作为输入 即 上下文提示」,它将在一步步的推理链条中将模型按照规定的情景引导至最终更标准、精确、更高泛化性的结果之上,而最终将模拟的对话结果用于模型的Fine-Tuning当中来,以保证对模型结果输出的正确性。这里可能大家会问,为什么需要如此繁琐的过程来合成数据呢?LLM自己不能直接在推理中解决问题吗?难道在采用大量的数据LLM预训练过程中并没有见到过这些数据?如果没见到,为什么模型还能通过在多角色的交互中合成出来?如果见到了这些数据,为什么还需要SFT,为什么还需要Multi-Agent、COT、TOT这一过程?当然要要完全回答上述这些问题,可能需要对LLM的预训练机制和原理进行展开和剖析,在了解了其训练本质后,也许会逐步找到解决上述疑问的办法。
在这里尝试再进行一些延申,试想一下,在LLM预训练过程中真实世界数据样本是真正足够的吗?与某个领域的任务对应的真实世界数据样本的组织和分布是合理的吗?即用于LLM pre-training的人类认知下的训练样本空间的「token」序列组织形态是天然COT的吗?LLM在预训练过程中所预测的下一个token学会的是什么?预训练时是否能够覆盖空间所有的复杂情况?模型提示词工程 Prompt Engineering与模型参数的Fine-Tuning的本质普遍性?基于Multi-Agent环境下,是否能达成类AlphaGO这样的self-play博弈环境的学习?等等这一系列问题似乎将会将我们带入到一个更本质的探寻空间。
在进行上述问题思考和探寻的过程中,刚好也联想到去年了解到的Mistral 7B,而由Mistral 7B也进一步了解到基于其微调的Zephyr 7B论文中的AIF+DPO(不同于RLHF PPO的算法)算法的思考,包括从Anthropic的RLHF到Cluade的RAILF,。在这里除了让大众眼前一亮的DPO算法(DPO利用从奖励行数到最优策略的解析映射,使得将奖励函数上的偏好损失函数转换为策略上的损失函数)之外,我想在AIF这一环节所带来的意义也是非常重大的。
在Zephyr中,如下图所示,其三步骤的训练方式与chatGPT的三阶段训练方式有着看似较大的差异:
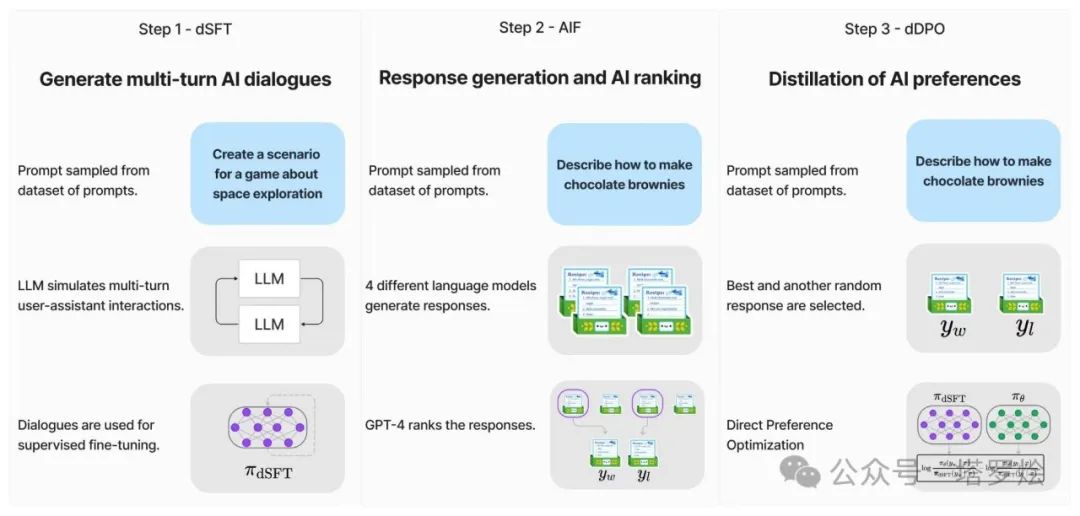
Step1 - sSFT:通过大规模、自指导式数据集(UltraChat)做精炼的监督微调(dSFT)
Step2 - AIF:通过集成收集AI反馈(AIF)聊天模型完成情况,然后通过GPT-4(UltraFeedback)进行评分并二值化为偏好
Step3 - dDPO:利用反馈数据对dSFT模型进行直接偏好优化·DPO
其中这里的Step2 - AIF,即某种程度上的一种self-play,也是通过多模型prompt生成来进行的一种RL,试想,通过其中的AIF,对于模型最终所采用的DPO算法的SFT过程里,其用于最终模型的SFT所训练的AIF数据集在与原始pre-training数据集在数据(tokens)序列组织构象上应该有着一些差异,而这种差异是之前原始数据集在用于模型pre-training中很难找到的,而这也是一种Synthetic Data的路径,关键是这种Synthetic Data与原始Data上述中的那些特征与知识分布差异。
DPO算法:如下公式的解析通俗来讲就是:当一个答案是好的答案时,模型要尽可能增大其被策略模型生成的概率,而当一个答案是差的答案时,模型则需要尽可能降低其被策略模型生成的概率。
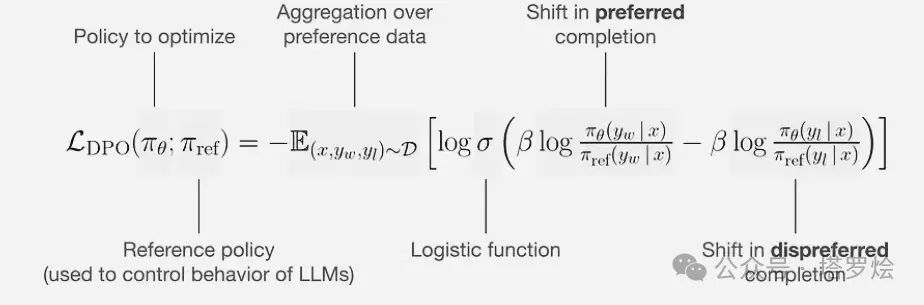

以上,我们在RL×LLM上开了一个小头,了解到了一些两种算法或训练模式的融合例子,并尝试做出了一些探索性思考,接下来,将上述模型case以及延展的思考进行一下沉淀,回归第一性原理进行更进一步的本质探寻,以求找到两者之间所隐含的的共性、差异以及之所以呈现出当前技术发展路径与现状的必然性..
大家如果有兴趣可以继续参考如下来自于DPO的简要概述:
DPO方法的定义与工作原理
直接偏好优化(DPO)是一种新兴的机器学习方法,它旨在直接通过用户反馈来优化语言模型的输出。与传统的强化学习方法不同,DPO不依赖于一个预先定义的奖励函数。相反,它使用从用户反馈中提取的信号来调整模型的行为,使其更加符合用户的偏好。
与经典的RLHF不同,DPO(如Rafailov等人在2023年推导的)完全保持在上下文bandit设置中,并且还使用了基于bandit的偏好模型。为了避免使用RL算法,DPO使用了KL-contextual bandit版本的RL问题的众所周知的闭式解:
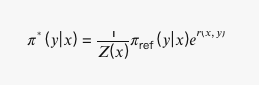
其中π∗是最优策略,Z(x)是归一化的分区函数。DPO重新排列这个方程,以解出奖励:

将这个关系代入用于奖励建模的标准二进制交叉熵损失函数中,得到DPO的损失方程,因为分区函数Z(x)从Bradley Terry模型中消除。

在DPO中,模型的每个输出都被视为一个“臂”,而用户的反馈则被用作评估这些“臂”的“奖励”。通过这种方式,模型学习哪些类型的输出更可能获得正面的用户反馈,并倾向于在未来的预测中生成类似的输出。
DPO与传统强化学习方法的对比
传统的强化学习方法通常依赖于一个明确的奖励函数来指导模型的学习过程。这个奖励函数定义了在给定的状态和行动下应该获得的奖励。但是定义一个能够准确反映复杂任务目标的奖励函数往往是非常困难的。
DPO方法的一个关键优势在于它不需要这样的奖励函数。它直接利用用户的反馈来指导模型的学习,这使得它在处理那些难以用传统奖励函数描述的任务时更加有效。
DPO在实际应用中的优势
DPO方法在实际应用中的一个主要优势是它的灵活性和适应性。由于它直接依赖于用户反馈,DPO能够适应用户的变化偏好,并且能够在没有明确奖励函数的情况下进行优化。
此外DPO还能够处理那些传统强化学习方法难以处理的任务,如那些需要细粒度评估和长期策略规划的任务。通过直接从用户反馈中学习,DPO能够在这些复杂的任务中找到有效的策略。DPO为优化语言模型提供了一个直接、灵活且高效的方法,特别是在那些传统强化学习方法难以应用的领域。
令牌级别的奖励函数与策略优化
直接偏好优化(DPO)方法在令牌级别的应用中,展现了其独特的优势。在这个层面上,每个令牌(即单词或字符)都被视为一个决策点,模型需要在这些决策点上做出最优选择以生成最终的文本输出。DPO通过评估每个令牌对整体输出质量的贡献来优化策略,这种方法允许模型在生成文本时进行更精细的调整。
在令牌级别上,奖励函数的作用是为每个可能的令牌选择提供一个评分,这个评分反映了该选择对于达成目标的贡献程度。DPO方法通过用户反馈来动态调整这些评分,使得模型能够学习到哪些令牌选择更能满足用户的偏好。
DPO在组合泛化中的应用
组合泛化是指模型的能力,能够将学到的知识和模式应用到新的、未见过的情境中。DPO通过在令牌级别上进行优化,为模型提供了学习如何将不同的令牌组合成有意义和符合用户偏好的输出的能力。
在实际应用中,这意味着DPO训练的模型能够更好地处理新的用户查询和任务,即使这些任务在训练数据中没有直接的例子。通过这种方式,DPO有助于创建更灵活、更适应性强的语言模型,这些模型能够在多变的真实世界情境中表现出色。
DPO在令牌级别的解释能力为语言模型的优化提供了一个强大的工具,它通过精细的信用分配和组合泛化能力,使模型能够更好地适应用户的具体需求和偏好。这种方法的应用前景广阔,从提高对话系统的互动质量到创建更准确的文本生成模型,DPO都显示出了巨大的潜力。
经典搜索算法的原理
经典搜索算法在人工智能领域中扮演着重要角色,特别是在决策问题和规划任务中。这些算法旨在在大规模的状态空间中寻找最优解或接近最优解的策略。
1.深度优先搜索(DFS):从根节点开始,沿着一个分支一直探索到底,然后回溯到上一层,继续探索其他分支。DFS通常用于树结构或图搜索。
2.广度优先搜索(BFS):从根节点开始,逐层探索,先探索所有相邻节点,然后再探索下一层。BFS通常用于图搜索和状态空间搜索。
3.A*搜索:结合了启发式信息和实际代价的搜索算法。它使用估计的最优路径成本(启发式函数)来指导搜索,以便更快地找到目标状态。
P vs. NP 的五十年
不管是通往未来的AGI还是World Model或World Simulator,我们可能仍旧会在持续的路途探寻中遇到P/NP这个存在于计算机领域50年的老大难问题,当然这也是对于是否能够彻底实现AI4S的一种侧面印证,其中个人认为P/NP问题似乎在某种中与AGI或AI4S相互影响亦或携头并进着,甚至反过来某种程度上,P/NP会指引或驱动着通用人工智能的发展...如下这篇文章内容的整理并在其中进行了注释说明。

【此文有助于理解2023图灵奖获得者Avi Wigderson过去40年的工作重心:随机性与难解性。原文标题是:Fifty Years of Pvs.NP and the Possibility of the Impossible。作者曾出版过一本专门谈P/NP问题的科普书,中文版名为《可能与不可能的边界——P/NP问题趣史》。】

P和NP问题一直是计算机领域的老大难问题,那么在近50年间,人们对这个问题有什么深入的研究呢?让我们在本文中深挖这个世纪难题。
在1971年5月4日,伟大的计算机科学家和数学家Steve Cook就在他的论文《定理证明程序的复杂性 The Complexity of Theorem Proving Procedures》中首次向世界提出了P和NP的问题。在50年后的今天,世人仍然在试图解决这个计算机领域中最著名的问题。其实在12年前(2009年),我也曾经就该问题进行了一些讨论,大家可以看之前的《P与NP问题的现状》综述。
文章地址:Fortnow, L. The status of the P versus NP problem. Commun. ACM 52, 9 (Sept. 2009), 78–86. https://doi.org/10.1145/ 1562164.1562186
计算机理论在近些年并没有得到很大的发展。从2009年那篇文章发表以来,P与NP问题及其背后的理论并没有发生显著的变化,但计算世界确实发生了变化。比如说云计算,就推动了社交网络、智能手机、经济、金融科技、空间计算、在线教育等领域的飞速发展。更重要的是,云计算还帮助了数据科学和机器学习的崛起。
在2009年,世界前10大科技公司中出现了一家独大的场面——微软公司独孤求败。但是截至2020年9月,市值前七名的公司分别是苹果、微软、亚马逊、Alphabet(谷歌)、阿里巴巴、Facebook和腾讯,彼此平分秋色。不光是大公司的变革明显,计算机人才的需求量也是如此。据统计,在2009到2020年间,美国的计算机科学专业毕业生的数量增加了三倍有余,但这还是无法满足市场上对该领域人才的需求量。
P和NP的问题作为数学界和计算机界的一个难题来源已久,它被列入克莱数学研究所的千年难题之一。而且这个组织还为能够攻克该问题的研究人员提供了上百万美元的奖金悬赏。我会在文章的末尾用一些例子来解释P和NP问题,这虽然没能让我们从本质上对其有更多的认识,但是也能看出来P和NP的很多思考和成果推动了这个领域的研究和发展。
P和NP问题
如果有人问你,你能不能在微博上找到一些人,他们彼此之间都是朋友,这帮人的数量大概是300左右。你会怎么回答这个问题?
假如你在一个社交平台企业工作,而且可以访问整个平台的数据库,也就是能看到每个人的好友列表,那你可以尝试遍历所有的300人群组,然后挨个儿看他们是否有相同的关注人群,如果是,则他们被称为一个团(Clique )。但是这样算法的计算量太大,数量也太多了,通常无法全部遍历。
你也可以耍耍小聪明,也就是从小的群组开始,然后慢慢的将这个小群组扩大,纳入那些彼此之间都是好友的人。当然实际做起来可能也有难度。其实从理论上来说,这个问题没有最好的解决方案,没有人知道到底存不存在比挨个遍历更好的解决方案。
这个例子其实就是一个典型的P和NP的问题。NP代表了可以有效检验一个解的准确性的一类问题。比如当你知道有300个人可能构成一个团,你就可以快速的检验出由他们两两配对的44850对用户到底是不是都是彼此的好友。成团问题(clique problem)是一个NP问题。
P则代表了可以有效找到解的问题。我们不知道这300个目标人群的问题是否也是具有P的可解性质。
实际上,令人惊讶的是,成团问题具有“NP完全”的性质。也就是说,当且仅当P=NP时,我们才可以快速有效地解决成团问题。
许多其他问题都具有NP完全的性质,比如3 Coloring问题(是否可以仅使用三种颜色对地图进行染色,然后让相邻的两个地块没有相同的颜色)、旅行商问题(通过城市列表找到最短路径,让这个旅行者能够在路径所有城市之后回到出发城市),等等。
形式上来说,P代表“确定性多项式时间”,也就是可以在输入长度的多项式限定时间之内解决的一类问题。NP则代表“非确定性多项式时间”。在实际的算法开发中,我们最好可以换个角度看待P和NP的问题:我们可以将前者视为可有效计算,而将后者视为可有效检查的问题。
大家如果想更多的了解P和NP的问题,可以去看看2009年的综述论文,或者一些其他的科普书籍自行了解。也有一些比较偏正式的介绍工作,比如Michael Garey 和 David Johnson在1979年出版的书籍,他们的这本书对于想了解NP完全问题的读者来说一定不能错过:
Garey, M. and Johnson, D. Computers and Intractability. A Guide to the Theory of NP-Completeness.W.H. Freeman and Company, New York, (1979).
为什么要讨论P和NP问题
在1971年的那个星期二的下午,Cook在ACM计算理论研讨会上发表他那篇关于NP完全的论文时,他证明了可满足性是NP完全的,而重言式是NP难的。论文中也推断说Tautology是不具备P特性的一个问题,当然,当时没有对这个问题进行很好的证明。但无论如何,这篇论文以及其中的证明方法,标志着复杂性理论的重大突破。
想要去证明一个数学概念通常具有很大挑战。算法和证明的基础概念至少可以追溯到古希腊时期,当然,他们从来没考虑过NP和P这样的问题。高效计算和非确定性的理论基础是在1960年代才发展起来的。但P和NP的问题在这之前很久就已经被提出来了,只是我们没有给它们正式冠名而已。
库尔特·哥德尔在1956年曾经写过一封给冯·诺依曼的信。在信中他就初步描述了P和NP问题。这封信直到1988年才被发现,并广为流传。
Richard Karp真正意义上首次将P和NP问题引入大家视野。他在1972年的论文中介绍了该问题,并随后得到广泛的关注。
我们知道很多有名的组合问题都是NP完全的,包括Clique, 3-coloring和旅行商问题。1973年,当时在俄罗斯的Leonid Levin在他两年前独立研究结果的基础上发表了一篇新的论文,并在这篇论文中定义了P和NP问题。当Levin的论文传播到西方的时候,P和NP问题也已经确立了作为计算领域最重要问题的地位。
Optiland
Russell Impagliazzo在1995年的一篇经典的论文中描述了P和NP问题具有不同程度可能性的5个层级:
算法:P=NP或理论上等效,例如NP的快速概率算法(fast Probilistic algorithm)
-
启发式:NP问题在最坏的情况下很难求解,但平均来说还是可以得到求解的
-
Pessiland:我们可以轻松的创建困难的NP问题,这是所有可能中最糟糕的,因为我们既不能在平均意义上解决难题,也不能从这些问题的难度中获取任何明显的优势
-
Minicrypt:存在加密的单向函数的问题,但我们没有公钥加密
-
Cryptomania:公钥密码学,也就是说,两方可以通过公开渠道来交换加密信息,然后通过公钥解密
上述的5个层级没有正式的定义,都是通过人们对P和NP问题的了解人为规定的。但是人们普遍认为,Cryptomania这个等级的可能性最高。
Impagliazzo借鉴了P和NP理论中的核心思想——“我们无法拥有一切”。
我们或许可以解决困难的NP问题,或者解决密码学的重要关键,但是不能将两者同时攻克。
不过,也许我们正在走向事实上的Optiland——机器学习和软硬件优化等方面的长足进步让我们能够在一定程度上解决当年无法设想的问题,包括语音识别、蛋白质折叠解析等。但是大多数情况下,我们的密码协议仍然是安全的,所以不用太担心。
在2009年的综述中,我曾经在其中“如果P=NP怎么办”的章节中提出,通过使用奥卡姆剃刀法则,学习将会变得容易——我们只需要找到与数据一致的最小程序,也就是问题的关键核心。那么此时,原本十分难以解决的视觉识别、语音识别、翻译以及其他的任务都会变得微不足道。我们还将对天气、地震和其他自然现象做出更好的预测和理解,以及建模。
今天,我们可以使用人脸识别解锁手机,可以和一些智能设备语音对话来提出问题并且得到理想的回答,可以将我们说的话、输入的文字翻译成另外的语言。我们的手机会收到关于天气和其他突发事件的警报,它的预测效果比我们之前十几年前能做到的效果好的多。与此同时,除了对小密钥长度进行类似暴力破解的攻击之外,我们的密码学基本上还是很鲁棒和安全的。那么现在,让我们看看计算、优化和学习方面的最近进展如何将我们带到Optiland中吧!
解决困难问题
2016年,Bill Cook和他的同事决定挑战一个问题,就是如何以最短的距离访问英国的每一家酒吧。他们列出了已知的24727家酒吧,并且迈开腿,真的去走遍这些酒吧。这是一次跨越45495239米,大概28269英里的步行之旅,比绕地球一圈还要长。
其实Cook做了个弊,他没有真的走去每一家酒吧,他忽略了其中一些酒吧来让这次步行没那么夸张。这个事情在英国的媒体中宣传了之后,很多人在底下留言说:你没有来我家旁边的这个酒吧呀。于是,Cook和他的公司重新开始计划,将酒吧的名单增加到49687个,整体的旅行长度就达到了惊人的63739687米,也就是39606英里。但其实,相对于之前的那个旅行,这趟新的寻酒之旅其实只需要多走40%的距离就能达到两倍多数量的酒吧。
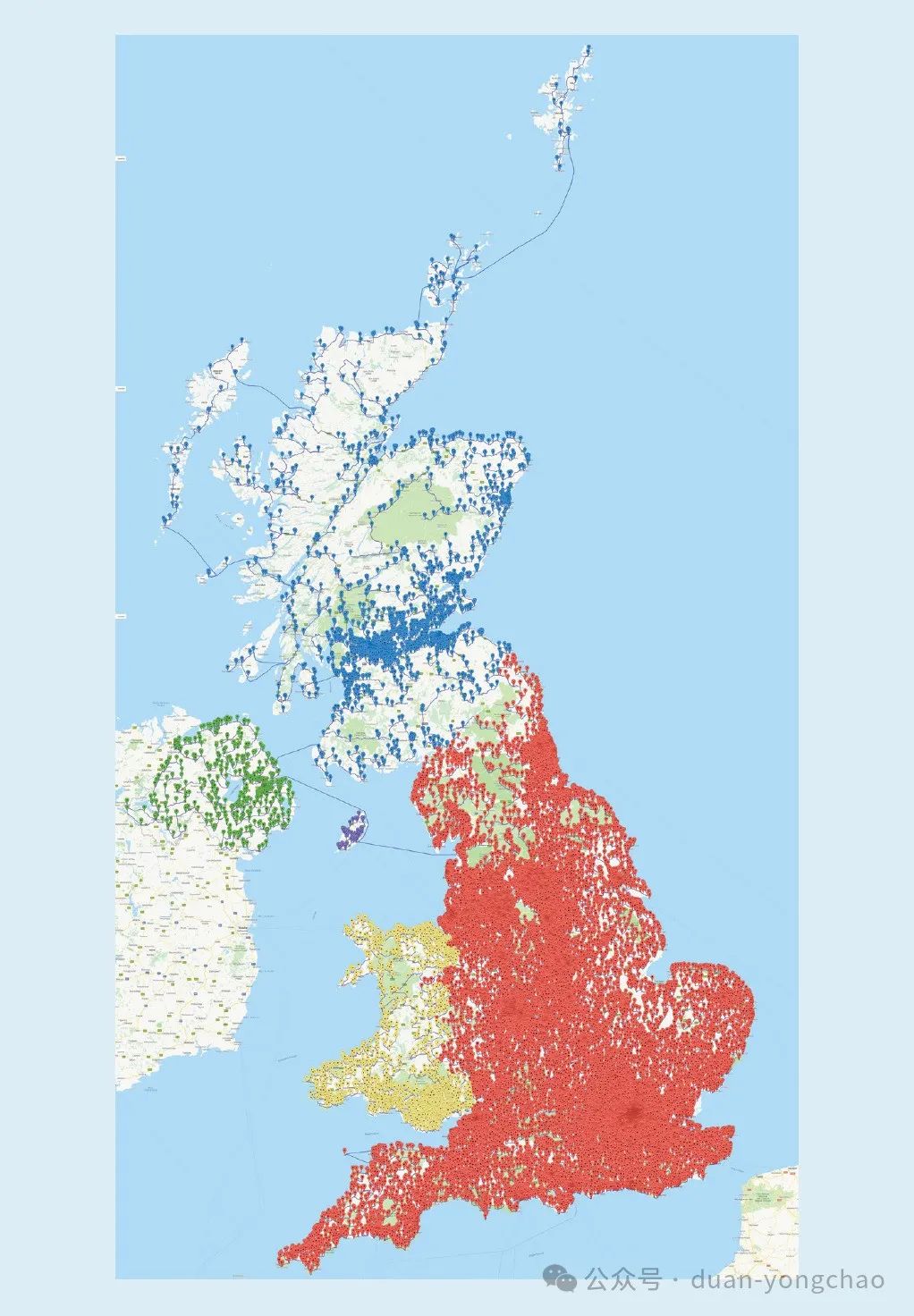
遍历英国49687家酒吧的全览图
这种酒吧遍历之旅在某种程度上就是旅行商问题的变种,也就是最著名的NP完全问题之一。通过所有49687家酒吧的可能游览次数约等于3加上后面211761个零这个量级。当然了,Cook的计算机不会搜索整个集合,而是使用了多种优化的技术。更令人印象深刻的是,这次旅行带有基于线性程序对偶性的最优性证明。
除了旅行商问题之外,我们还看到了求解可满足性和混合整数规划方面的重大进步,也就是线性规划的一种变体,其中一些变量的解要求是整数。当我们使用高精度的启发式算法,使用快速的处理器、专用的硬件系统和分布式的云计算进行辅助的时候,人们通常可以解决实际中出现的具有好几万个变量和几十上百万个约束的问题。
面对NP问题时,人们通常可以将NP问题表述为可满足性或混合整数规划问题,并将其扔给目前最好的求解器来借助计算机的力量,自动找到答案。这些工具已经成功用于电路和代码的验证、自动化测试、计算生物学、系统安全、产品和包装设计、金融交易,甚至是一些困难的数学问题求解之中了。
数据科学和机器学习
人们通常无法忽视机器学习在近些年带来的革命性影响,尤其是神经网络。人工神经网络建模的概念基础,基本上是计算加权阈值函数。这种思想起源于1940年代Warren Mcculloch和Walter Pitts的工作。在1990年代,Yoshua Bengio、Geoffrey Hinton和Yann Lecun开发了反向传播算法,来将深度神经网络的层数加深,并得到非凡的结果。
与此同时计算机硬件计算、存储等方面出现突破,那些更快、更加分布式的计算单元,那些专用的硬件和海量的数据有助于推动机器学习完成很多类似人类的功能。ACM认识到Bengio 、Hinton和LeCun的贡献,并在2018年为他们颁发了图灵奖。
有的同学可能会问,机器学习怎么和P、NP问题相联系呢?奥卡姆剃刀说:如无必要,勿增实体。如果P=NP,我们可以用这个思想来创造强大的学习算法:找到与数据一致的最小电路。即便P≠NP,机器学习也可以学习并且近似这种思想,这就赋予它强大的能力。
尽管如此,神经网络也可能不是真正的“最小”的电路,当然或许可能是尽量小的。今天我们所使用的深度学习方法通常是结构固定的,能够变动的都是神经元连接上的权重。为了能够实现足够泛化的表达能力,这些网络通常有几百上千的权重数量。这就限制了深度网络的能力(也就是不够简单)。它们可以在人脸识别上做的很好,但是无法根据示例学习乘法。
通用分布和GPT-3
让我们考虑二进制字符串的无限集上的分布场景。我们虽然不能拥有均匀分布,但是可以创建一种每个长度相同的字符串都有相同概率的分布。但是,有些字符比其他字符更重要。比如π的前一百万位数字比随机生成的一百万位数字更有意义。
Think:这里可以与「中篇」 融合RL与LLM思想,探寻世界模型以迈向AGI-CSDN博客中关于数据&认知构象分布上做对比关联思考..如下图所示

此截图来自作者所在公司内网知识库模板整理,内容与文章中篇中一致
我们可能希望将更高的概率放在更有意义的字符上。现在我们有很多方法能够做到这点。实际上,已经有人发现了一种接近任何其他可计算分布的通用分布,这种分布与学习有很大的联系——例如,任何能够以小错误率学习这个分布的算法,将可以学习所有的可计算分布。
但是问题在于,即使P=NP,这种分布通常也是不可计算的。如果P=NP,我们仍然可以通过创建一个对其他有效可计算分布通用的分布来获取一些有用的信息。
那么我们能够从机器学习中得到什么?让我们考虑生成式预训练Transformer(GPT)。
在2020年5月GPT-3发布了,它有1750亿个参数,并且训练了4100亿个token。这些Token来自很多的文字语料库。它能够回答问题,能够根据提示写出文字,甚至可以进行一些基础的编码工作。尽管还有很长的路要走,但是GPT-3因其生成内容的自然性而受到广泛的赞誉。
在某种意义上,我们可以将GPT-3视作一种特殊的分布方法。我们可以在其中查看算法生成输出的概率,这是通用分布的一种弱化版本。如果我们将通用分布限制为具有给定前缀,则会提供由该前缀提示的随机样本。GPT-3也可以建立在此类提示的基础上,无需进一步训练即可处理范围广泛的领域知识。随着这一系列研究的发布,我们将更接近一个可以执行内置学习的通用衡量标准:从给定的上下文中学习一个随机样例。
科学和医学
在科学方面,我们通过进行大规模的模拟来理解。例如在探索核聚变的反应过程中,我们就取得了一些不错的结果。研究人员可以应用一种形式化的研究方法,为物理系统创建一个假设,然后使用这个假设,并且不断的使用这个假设进行反应和模拟。如果我们得到的结果和实际不相符,则丢弃模型,并且重新开始。
当我们得到了一个强大的模型之后,我们就可以在物理模拟系统中进行很多实际实验中代价昂贵的测试了。如果P=NP,我们可以使用奥卡姆剃刀方法来创建假设,即找到与数据一致的最小电路。机器学习技术可以沿着这条技术路径前进,使假设的创建自动化。当我们给定数据之后,不论是通过模拟还是真正的实验得到数据,机器学习就可以创建模型来拟合这些数据,达到最佳的匹配。我们可以使用这些模型进行预测,然后就像之前那样测试这些预测。
虽然这些技术使我们能够找到可能遗漏的假设和模型,但是也有可能导致误报。人类通常会趋向于接受有95%置信度的假设(这意味着20个坏假设中只有一个能够通过检验)。机器学习和数据科学工具能够让我们生成假设,这些假设都有着脱离实际建模的风险。这就限制了它的工作范围,比如医学工作者就不能承担这些风险,他们的诊断中如果有这些问题,那会遭到很大的麻烦。生物系统也是一种极为复杂的结构。我们知道人类的DNA形成了复杂的编码,它描述了我们的身体是如何形成的,以及它们执行的功能。但是很可惜,我们目前对其工作原理知之甚少。
在2020年11月30日,谷歌旗下的DeepMind发布了AlphaFold,这是一种基于氨基酸序列预测蛋白质形状和结构的新算法。AlphaFold的预测几乎达到了实际实验构建氨基酸序列的和测量蛋白质形状相同的准确度。但是关于DeepMind是否真正“解决”了蛋白质折叠的问题,还存在一些争议,现在评估其影响还为时过早,但是从长远的角度来看,这可以为我们提供一种新的数字工具来研究蛋白质,来了解它们是如何互相作用,并且了解如何设计DNA来对抗疾病。
超越P和NP问题的思考:国际象棋
NP就像是一个迷宫一样,在任意大小的棋盘上各种操作。数独也是NP完全的问题,它需要从一些正方形中给定的数字设置中求解。但是,当我们问到谁从给定的初始设置中获胜时,我们是不是就没办法给出准确的回答了呢?即使我们有P=NP的前提,它也不一定会给我们一个完美的国际象棋的程序来解决问题,这就像需要设计一个程序,它保证能够让白棋走的这一步,逼迫黑棋走那一步,然后白棋再按照计划走这一步,使得黑棋...,最终是白棋获胜。人们无法单独在P=NP上完成所有这些白棋和黑棋的交替。像这样的游戏往往被称为PSPACE-hard,即很难计算、或使用合理数量的内存,并且在约定的时间之内求解完成的问题。根据规则的精确限制,国际象棋和围棋甚至可能更难。
这不意味着如果P=NP,你就不能得到一个好的国际象棋程序。事实上,在某种程度上,象棋的程序体积越大,其智能程度越高。我们可以找到一种有效的计算机程序,它可以击败所有尺寸稍小的其他程序。同时,即使没有P=NP,计算机在国际象棋和围棋方面也变得非常强大了。1997年,IBM的深蓝击败了当时的国际象棋世界冠军。
此外,机器学习为电脑游戏带来了巨大的进步。我们讨论一下声名大噪的AlphaZero,它是2017年DeepMind开发出来的人工智能程序。
Think:想象一下「上篇」 融合RL与LLM思想,探寻世界模型以迈向AGI-CSDN博客中的AlphaZero中的描述..
AlphaZero使用了一种被称为蒙特卡洛树搜索MCTS的技术,这个技术为两个玩家随机移动以确定最佳的行动方案。AlphaZero使用深度学习来预测游戏位置的最佳分布,以优化使用MCTS的获胜机会。虽然AlphaZero不是第一个使用MCTS的工作,但是它没有任何内置的人工策略或者使用任何已有的游戏数据库。AlphaZero只学习了游戏的规则。这就让AlphaZero在国际象棋和围棋这两个运动中大放异彩,除了交替移动和固定大小的棋盘之外,这两个游戏在规则和目的上没有任何相似之处。DeepMind最近在MuZero上也有新动作。它甚至都没有得到完整的游戏规则,只得到了对棋盘位置的一些表示,和合法动作列表,以及对哪些位置是输是赢有了一些了解。也就是说,现在我们已经发展到了一个阶段,在这个阶段里,纯机器学习在国际象棋或者围棋这样的高复杂度的问题中都能轻松击败大多数的人类或者启发式算法。人类的先验知识只会画蛇添足、碍手碍脚。对于国际象棋和围棋这样的游戏,机器学习可以在P=NP无法满足的情况下取得成功。太不可思议了。
可解释的人工智能
许多机器学习算法似乎已经能够达到不错的效果,但是我们不知道其中的原因。如果我们仔细的去看语音翻译或者图像识别的神经网络内部参数,很难理解它为什么会做出这样的动作或者处理。有人可能会问了,它有这个能力就好,我们为什么要关心?以下是几个原因:信任、公平性、安全性、因果关系。
信任:我们如何知道神经网络是否正常运行了?除了检查输入和输出之外,我们无法对其他中间的变量进行分析和理解。不同的应用程序具有不同的信任级别。如果Netflix推荐了一个很差的电影,那没什么问题,但是如果自动驾驶汽车推荐了一个让车撞墙的转弯操作,那事儿可就大了。
-
公平性:很多应用程序都是在训练集上进行学习的,训练集中的数据可能不是完全公平或者说没有偏见的。如果不理解程序,那我们可能无法纠正其中的偏差和歧视。种族歧视可是一个严重的话题呦。
-
安全性:如果我们使用机器学习来监控数据安全系统甚至安保系统,那么不可解释的机器学习模型可能无法让你知道他存在的漏洞是什么,尤其是当我们的对手具有适应性的时候。如果我们能够理解代码和网络的结构,就可以发现并且修复这些安全漏洞。当然,如果我们的敌人拥有代码,他们也有可能发现漏洞并针对其组织攻击。
-
因果关系:目前来说,我们最多可以检查机器学习算法是否只与我们想要的输出类型相关。但是理解代码能够帮助我们理解数据中的因果关系,从而造出更好的科学理论和医学成果。
如果P=NP,我们能得到更好的计算机程序吗?如果你有一个解决NP完全问题的快速算法,你就可以用它来找到匹配旅行商问题的最短路径,但是你不会知道为什么这种方法有效。另一方面,我们都希望能够得到可解释的算法,因为能够深入了解其属性。在研讨会中,我们都在研究可解释的人工智能,比如ACM Fairness Accountability and Trust会议等。
机器学习的局限性
虽然机器学习在过去的几十年间取得了令人瞩目的进展,但是这些系统远非完美。在大多数的应用中,它们还是会被人类碾压。我们将继续通过新的和优化的算法,收集更多的数据并研发更快的硬件来提高机器学习的能力。机器学习似乎确实有不少的局限。正如我们上面看到的,机器学习让我们无限逼近P=NP,但是永远无法达到这个程度。比如,机器学习在破解密码方面的进展很慢,我们稍后对其进行讨论。
机器学习似乎也无法学习简单的算术关系。比如总结大量的数字规律,以及大数相乘。人们可以想象将机器学习和符号数学工具结合起来,一定能得到很好的效果。虽然我们已经在定理的证明应用方面看到了一些进步,但是距离梦想中的功能还比较遥远。我也正在写一篇相关的论文。
同样的,P=NP将使这些任务变得更加容易,或者至少更加易于处理。机器学习在面对和训练数据分布不同的样本的时候,表现通常不好。这可能是由于低概率的边缘情况,例如在训练数据中没有很好的包括所有人种的时候,对于一些国家或者种族的人的识别效果比较差。深度神经网络算法可能有数百万个参数,因此,它们可能无法达成良好的泛化分布。如果P=NP,那就可以生成最小尺寸的模型,并且能够做出最好的泛化,但是如果我们无法进行实验,我们永远不知道这是不是P=NP问题。
跟机器学习一样,我们目前还没有任何的工作能够接近真正意义上的通用人工智能。这个通用人工智能是指对某个主题的真正理解,或者真正具有意识或者自我意识的人工系统。定义这些术语可能比较棘手,也具有一些争议。就我个人而言,我目前还没见过一个正式的通用人工智能的合理定义,我只是抓住了对它概念的知觉的理解并且总结。我怀疑我们永远不会实现真正意义上的通用人工智能,即使P=NP。
6
密码学
虽然我们在解决NP问题方面取得了很大的进展,但是很多密码学的领域仍旧毫无进展。包括单向函数、安全散列和公钥密码等多种形式的加密。一种有效的NP算法,其实是能够破解所有密码系统的,除了那些信息理论上安全的密码系统(比如一次性密码和一些量子物理学的安全系统)。我们已经看到过很多成功的网络安全攻击,但是它们通常源于服务器糟糕的设置、很差的随机数生成器,或者人为的一些错误,几乎都不是由于密码学本身的问题所导致的。
现在的大多数CPU芯片都内置AEC,因此一旦我们使用公钥密码技术来设置私钥,我们就可以像发送纯文本一样轻松的发送加密数据了。加密为区块链和加密货币提供了底层的技术支持,这意味着人们对加密技术的信任十分高,足以将现金和比特币进行交换。Michael Kearns和Lesilie Valiant在1994年的研究表明,学习最小的电路,甚至学习最小的有界层神经网络,都可以用来分解质因数和破解公钥密码系统。但是到目前为止,机器学习尚未成功用于破解密码协议。
可能有人会问,我们既然已经在许多其他NP问题上取得了很多的进展,为什么单单是密码学上失灵了呢?在密码学中,我们可以选择问题,专门设计为这个场景单独设计的方法来加密,从而达到不错的效果。而其他的NP问题通常使用通用的、通过程序自己形成的方法来执行。这些自动匹配的方法可能不是量体裁衣的,就并不是最合适和最困难的方法。
量子计算是目前我们知道的唯一一个能够威胁到互联网公钥协议安全的存在。Shor的算法可以用于对大数进行质因数分解和其他相关的数论计算。这种担忧可以通过几种方法来加以解决。虽然目前来看量子计算取得了一些令人惊叹的进步,但是它距离能够破解当今的密码系统相去甚远,毕竟还不能够处理足够多的纠缠位。有人估计,可能还得需要几十年甚至几个世纪才能真正使用Shor算法+量子计算机对目前的公钥产生威胁。另外,研究人员在开发对量子攻击具有抵抗力的公钥密码系统方面取得了良好的进展。我们将在本文后面的部分详细介绍量子计算。
因式分解问题,目前来说并不是NP完全的,即使我们没有大规模的量子计算机,数学上的突破也肯定有可能推导出很高效有用的解决方案。不论我们如何看待量子计算的未来,一些拥有了多种公钥系统的计算机都可能解决因式分解问题。
7
摩擦力般的复杂性
话说回来,面对这么多难以计算的问题,我们能有什么优势呢?或者说我们能从中学习到些什么呢?我想到了密码学。但是,既然造物主让某些计算问题变得十分困难和复杂,甚至难以求解和实现,肯定是有内在原因的,这和很多自然界中的摩擦力现象(Friction)十分类似。在物理世界中,摩擦力通常是需要我们额外付出能量做功来克服的,但是如果没有摩擦力这种常在的阻力,我们甚至无法行走、跑步和前进。同样的,在计算机的世界里,复杂性虽然会导致一些计算困难,但是如果没有它,我们可能就会遇到类似于无法前进般的更棘手的问题。在许多情况下,P=NP将消除这种摩擦力。
最近发表的很多计算理论相关论文告诉我们,如果消除了摩擦力般的计算复杂性,那么会产生许多负面的影响。例如,如果消除了计算复杂性,那么人们将不能够表露自己的思想,人们也只能够看到其他人所采取的行动,而不知其动作背后的目的。经济学家有一个术语:偏好启示(Preference Revelation),这个现象试图根据我们所采取的行为来推断其背后的真实目的。在过去的大量时间里,我们通常没有大量的训练数据来支持类似模型的训练,因此这种程序也成为了一种空中楼阁般高度不精确的“艺术品”,无法实用。
时至今日,我们从人们的网络搜索记录、他们的社交账号的照片视频、游戏账号的购买记录,以及在网上的浏览记录、现实生活中的足迹信息,以及各种智能设备中残留的隐私信息中收取大量的个人信息数据。因此数据集已经很充足。同时,机器学习也可以拥有处理这些复杂信息的能力,因此就可以据此做出非常精确的预测和估计。计算机对我们的了解往往比我们自己对自己的了解还要多。
我们现在的技术已经足够强大,强大到甚至能够开发出一个智能眼镜,让你戴上它就立刻知道眼前人的各种信息,姓名、年龄、身高体重、兴趣爱好,甚至是政治偏好。也就是说,在大数据的时代,由于机器学习和大量隐私信息的存在,本来十分复杂、几乎不可能实现的一些问题被计算机攻克,也就带来了隐私的泄露——复杂性不再能为我们提供隐私的保护。我们需要通过法律和对企业的责任约束来保护个人的隐私安全。
计算机世界的“摩擦”现象可以超越隐私。美国政府在1978年取消了对航空公司定价的管制,因此如果旅客想要找到一条最便宜的航线,就需要打好多个电话给很多家航空公司,或者通过旅行社来寻找。但是旅行社嘛,通常不会尽心尽力的帮你寻找最便宜的,而是寻找对他们利益最高的那条路线。各个航空公司的生存理念不同,有的可能致力于保持高水平的服务质量,因此价格稍贵;有些则是想要用低价来吸引更多的乘客。今天,我们可以很容易的通过计算机程序找到最便宜的航空公司的航线信息,因此航空公司也都跑去在价格上苦苦鏖战竞争,并期望计算出最佳的定价来提高上座率,此时服务态度和体验可能就被牺牲掉了。
计算机的“摩擦力”或者说复杂性,也有助于打击作弊问题。我在1980年读大学的时候,天天被微积分问题虐,整天都在各种数学计算,生不如死。但是时至今日,这些微积分问题在Mathematica和Matlab面前都是弟弟,一行指令轻松破解。我现在当老师了,在我的课程上,我甚至留不出一些网上无法搜索到的家庭作业题目来让学生训练。更可笑的时候,我甚至可以使用GPT-3或者它的后续优化代码来生成一些家庭作业。那么当GPT之类的工具已经可以自动回答这些很复杂的问题的时候,我们如何激励学生,或者说防止他们作弊偷懒呢?
股票交易也是一个重灾区。在过去,股票交易通常需要在一个很大的交易所中进行,就像我们在电影中看到的那样,交易员在那里用一个很帅的手势来指挥买入和抛售,用一个眼神来匹配最佳的价格。但是现在,算法会自动适应最佳的价格并且买入抛售股票。虽然偶尔会导致“闪崩”的现象。机器学习算法已经很强大了,他们能够替代人类进行一些决策,也能进行人脸识别,将社交媒体的内容和用户进行匹配,也能进行一些司法判决。这些决策系统都为人们提供了便利,但也带来了很大的社会挑战。比如歧视问题和政治两极化的问题正在被拉大。这个问题很复杂我们无法一言概之。
上述的问题只是此类场景中的一小部分。作为计算机科学家,我们的目的是使计算尽可能高效和简单,但我们必须保留减少计算复杂性,也就是计算“摩擦力”的成本。
量子计算机的力量
随着摩尔定律的失效,计算机研究人员将目光转移到量子计算机的领域,这些年,量子计算机的研究和应用正在经历大幅的增长。谷歌、微软和IBM等大型科技公司,以及各种创业公司都在量子计算机方面投入大量资源进行研究。美国发起了国家级的量子计算研究计划,中国等其他国家也在纷纷效仿。
在2019年,谷歌宣布他们已经通过使用53个量子比特的量子计算机实现了“量子霸权”,解决了当前传统计算机无法解决的很多计算任务。虽然有很多人质疑这个说法,但是我们无疑的正在处于量子计算新时代的起点之上。尽管如此,我们距离能够跑起来Peter Shor的量子算法,以及拥有一台真正的量子计算机,还有相当远的距离。保守来说,我们还需要几万个量子位的距离需要攻克。通常来说,量子计算机可以被理解成是由比特表示的状态数的系统,比如53个量子比特计算机的2^53个状态。这可能说明,我们可以通过创建特别多的状态位,也就是使用量子计算来解决NP完全问题——也就是大力出奇迹。但不幸的是,目前我们无法证明量子计算机能够充分操控这些状态位,也就是不知道使用什么算法来解决NP完全问题,在这个角度上,这个问题已经超出了Grover的算法限制。
复杂性更新
自从2009年以来,我们在高效计算理论方面取得了一些重大的进展。虽然这些结果在解决P和NP方面没什么帮助,但是它们可能从一旁帮助理解相关的问题,并且启发后世的一些研究发展。
图同构
一些NP问题无法表征为P(有效可解)或NP完全问题(与Clique问题一样难的问题)。我们之前讨论过的最著名的整数因式分解仍然需要指数级的时间来求解。对于另一个这样的问题,也就是图同构问题,我们最近看到了一些戏剧性的进展。图同构问题是指,人们可否找到两个图在统一表示下完全相同。具体举例来说,就像在Facebook中,当我们给定了两组1000人,我们能否将他们映射到另一个组中,在那个新组中好友的关系不变。(小A和小B是好友,在另一群人中A’和B’也是好友)
这个图同构的问题在80年代中有了一些理论上的证明。在80年代,有人用交互式的方法证明了图同构问题不是NP完全的,而且它其实不是很困难,在一些实际的情况下,使用启发式的方法也能快速找到解决答案。尽管如此,我们仍然无法找到一个能够在所有场景中都快速找到解的算法。Laszlo Babai在2016年对该问题进行了深入研究,并发表了一种用于图同构的多项式时间的解决算法。简单来说,P中的问题在多项式时间内如果可以得到解决,也就是对于某个常数k,复杂度是n^k,其中n是输入的大小,比如每组的人数。拟多项式时间算法在时间n^(logn)k内执行,只比多项式时间差一点点,但起码比我们预计的NP完全问题所需要的2^n^ε的复杂性好的多。
Babai的证明结合了组合学和群论,是一个非常棒的工作。虽然距离让这个算法能够在多项式时间内执行完还有些远,但是Babai提供了一个重要的理论结果。这在P和NP完全问题之间取得了一项重大的进展。
电路设计
如果NP在完整的电路设计的基础上(也就是与或非门)没有最小的电路,那么就不存在P=NP的解。虽然在1980年代的电路发展黄金年代中,没有明确的证明否定P=NP的假设。在2009年的各项调查中,也说明在过去20年中,电路复杂性也没有取得重大的成果。在1987年,Razborov和Smolensky证明说不可能用与或非和Mod_p门的恒定深度电路计算某些固定素数p的多数函数。但是对于带有Mod_6门的电路来说,我们几乎无法证明这个结果。即便是我们可以证明NEXP(NP的指数时间版本)无法通过与或非和Mod_6门的小型、恒定深度的电路进行计算,P和NP是否相等的问题在几十年见也仍旧无法得到解答。话说回来,恒定深度的电路在理论上被认为是具有很弱的可计算性的,我们在这些年一直没有取得实质性的进展,在电路的算法最新产出上的无人问津也侧面证明了这个现象。
在2010年,Rayan Williams表明NEXP确实不具有那些使用Mod_6或其他Mod门一样的恒定深度的电路。因此,他创造了一种新的技术,使用可满足性算法进行解决。这种算法的实现下界比尝试所有可能,或者使用一些复杂性工具来暴力实现来说要好一些。后来,Williams和他的学生Cody Murray进行了进一步的研究,结果表明,可以在任何固定的没有带Mod_m门的小的恒定深度的电路中,都有非确定性拟多项式时间的解。然而,证明NP没有任意深度的小回路这个问题,仿佛仍然遥不可及。
复杂性的反击?
在2009年的那篇综述中,我在名为“新希望”的章节中讨论了一种新的几何复杂性理论方法,这个方法基于Ketan Mulmuley和Milind Sohoni开发的代数几何和表示论来攻克P和NP问题。简而言之,Mulmuley和Sohoni创建了高维的多边形空间,以在NP的代数版本中找到P和NP的映射,从而在这个空间中重构、理解并解决该问题。他们的一个猜想中,假设多边形包含某个表示理论对象的特殊属性。在2016年,Peter Burgisser、Christian Ikenmeyer和Greta Panova从理论上证明了这种方法是不可能滴。
虽然Burgisser和Ikenmeyer、Panova的研究成果否定了GCT分离P和NP的方法,但是并没有将这种实验方法和思路进行否定。人们仍然可以根据这种表示理论对象的数量创建不同的多边形空间。尽管如此,我们还是无法孤注一掷的认为多边形方法能够在不久的将来解决P和NP的问题。
不可能的可能性
当我们反思P和NP问题时,我们看到这个问题有很多不同的含义。P和NP的数学正式定义仍然是它的官方定义,虽然很冷冰冰但是含义最为完全。而且能够解决这个数学问题的人还能给你的到数百万美元的赏金不是吗。
有时候,我们虽然可以通过可计算理论、电路、证明和代数几何等工具看到解决P和NP的方法,但是目前没有能够完全解决P和NP问题的有力方法。从这个角度上来说,我们正在抽象P和NP问题到一些领域中,降低了它的难度,也就是距离原问题越来越远。
在现实生活中,我们也有很多秉待解决的实际NP问题。在1976年出版的经典著作《计算机与难处理性:NP完全性理论指南》一书中,Garey和Johnson举了一个倒霉的员工的例子,他老板让他去解决一个NP完全优化的问题。最终的时候,这个员工苦恼地找到老板说,我实在没辙了,找不到一个有效的算法来解决这个问题,而且不光是我,这个世界上不管是比尔盖茨还是沃兹尼亚克都束手无策。书中说,这个老板不应该解雇这名员工,因为没有其他的人能够解决这个问题。
在P和NP的早期,我们将NP完全性视作障碍。这些是我们无法解决的问题。但是随着计算机的发展和进步,我们发现可以通过启发式与暴力计算的组合,在很多NP问题上取得很好的进展。在Garey和Johnson的故事中,如果我是老板,我可能不会解雇那名倒霉的员工,而是建议他使用一些新的方法,比如混合整数编码、机器学习以及暴力搜索的方法进行破解。NP完全意味着不可能,这个想法其实已经out了,它的时代也已经成为过去式了。NP完全,只是意味着可能没有始终有效和可扩展的算法而已,但是问题,还是有可能被解决的。
在我2013年发表的P和NP的书中,我有一章名为“美丽新世界”的文字。我在其中提到了一个理想化的世界,在那里,捷克数学家证明了P=NP,从而为所有NP问题提供了一种非常有效的解决算法。虽然我们不会也可能永远不会生活在这样的理想世界中,但是随着医学的进步,随着虚拟世界、元宇宙等新概念的崛起,P=NP这个古老的美妙话题似乎也不再遥不可及。
但是,话说回来,我们正在朝着几乎能够颠覆P=NP问题思想的方向大步前进。与其一直将其视为算法的障碍,不如去想象P和NP的解决之道,在其中探索一些新的方向,发掘出其中不可能的可能性。
注:本文内容来自整合雷锋网、人工智能学家等多家媒体开放信息
本篇完结·心得体会
终于..在年后繁忙的工作与生活交织拉扯当中,今天完成了全篇内容的撰写,同时十分抱歉因为写作过程中诸多欠考虑因素,可能会造成篇幅仍过于冗长、繁杂的阅读体会,而且在内容的表述和思考的阐释过程中,如上篇最后体会中所说,我自己感觉仍没有找到一个更加适合的形式化表达工具或方法来阐释核心要点内容,即通过文字语言的形式。再次跟大家抱歉!
最后,关于本篇文章,还是想多啰嗦几句自己的初衷:
在写完这篇文章外加最近外界的诸多新闻,似乎更坚定了我对AGI实现的确定性,因此回到我最初想要写这篇文章前其中的一个分非常重要的目的同时也非常迫切的希望我们需尽快完善AI进行综合安全监管和治理上的考虑,正如Hitton的担忧与后悔:自己正在成为下一个曼哈顿计划的始作俑者,包括我们每一个人,包括我自己。
不管未来的AGI的实现路径是基于LLMs自回归一直暴力scaling prediction下去,还是沿着LeCun的世界模型路径缓慢的摸索前进,还是即将到来的下几代GPT中出现了真正通往AGI的Q-star,亦或sora变成了真正的世界模拟器,我想不管人类最终探索出上述通往AGI路途中的哪种路径,采用那种模型结构,运用哪些数学变换方法,还是最终找到了创造无限的数据构象分布并建立全域pattern的可能,最终结合本文回归第一性原理的思考,在这个世界中推理认知的模式和对人类产生的影响的本质方面,我想都是值得我们每一位伙伴深思并做出正确的人类发展历程中的决定的。
目前,看起来现在已经没有什么能够阻止奥特曼率领的OpenAI了大跨步前进了,而其所尊崇的scaling law也许会成为阻止其吞噬真实世界的最后屏障,而此scaling law非彼scaling law,似乎只有期待在自然法则下无休止的scaling law也许并不被允许的可能,就像在我们的真实世界中并没有演化出无限制scaling的超级合体一样,也许这个世界还存在着另一个restricting law吧。
也期待自己这篇文章的能够最大价值的发挥出一定的作用:
1. 激发大家对大模型的创新的热情和警惕性,带给大家一些回归一次性原理的思考方法,并尝试洞悉未来AGI的内涵,以便届时我们能有一些好的办法来应对。
2. 未来希望可以作为长文本上下文prompt到某个开源LLMs中,以促进开源社区的进一步探索和治理。
最后,上中下全文约6万6千字,因为平日工作也异常繁(内)忙(卷),只有占用自己闲暇时间一个一个字码完,能写完着实也是挺耗费精力的,也希望大家看在字数上面如果可以的话多帮忙转发,让更多的人看到,感谢!
最后的PS:本篇文章完全非类GPT生成,最后一统计巧的是,全文66666字,祝大家一切顺利!
大家也可以访问:
作者知乎融合RL与LLM思想,探寻世界模型以迈向AGI「中·下篇」 - 知乎 (zhihu.com)以及
微信公众号「塔罗烩」融合RL与LLM思想,探寻世界模型以迈向AGI「中·下篇」 (qq.com)
进一步了解详细内容,感谢大家,欢迎讨论!

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









