










训练流程:
- 设置各种超参数
- 定义数据加载模块 dataloader
- 定义网络 model
- 定义损失函数 loss
- 定义优化器 optimizer
- 遍历训练数据,预测-计算loss-反向传播
- 对模型预测进行后处理
测试流程:
- 读取一张图片
- 预处理
- 模型预测
- 对模型预测进行后处理
后处理:
- 目标框信息解码
- NMS非极大值抑制
######
#此代码只包含单个图像后处理,批处理参考原文
######
# Decode object coordinates from the form we regressed predicted boxes to
decoded_locs = cxcy_to_xy(
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy)) # (441, 4), these are fractional pt. coordinates
# Lists to store boxes and scores for this image
image_boxes = list()
image_labels = list()
image_scores = list()
max_scores, best_label = predicted_scores[i].max(dim=1) # (441)
# Check for each class
for c in range(1, self.n_classes):
# Keep only predicted boxes and scores where scores for this class are above the minimum score
class_scores = predicted_scores[i][:, c] # (441)
score_above_min_score = class_scores > min_score # torch.uint8 (byte) tensor, for indexing
n_above_min_score = score_above_min_score.sum().item()
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score] # (n_qualified), n_min_score <= 441
class_decoded_locs = decoded_locs[score_above_min_score] # (n_qualified, 4)
# Sort predicted boxes and scores by scores
class_scores, sort_ind = class_scores.sort(dim=0, descending=True) # (n_qualified), (n_min_score)
class_decoded_locs = class_decoded_locs[sort_ind] # (n_min_score, 4)
# Find the overlap between predicted boxes
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs) # (n_qualified, n_min_score)
# Non-Maximum Suppression (NMS)
# A torch.uint8 (byte) tensor to keep track of which predicted boxes to suppress
# 1 implies suppress, 0 implies don't suppress
suppress = torch.zeros((n_above_min_score), dtype=torch.uint8).to(device) # (n_qualified)
# Consider each box in order of decreasing scores
for box in range(class_decoded_locs.size(0)):
# If this box is already marked for suppression
if suppress[box] == 1:
continue
# Suppress boxes whose overlaps (with current box) are greater than maximum overlap
# Find such boxes and update suppress indices
suppress = torch.max(suppress, (overlap[box] > max_overlap).to(torch.uint8))
# The max operation retains previously suppressed boxes, like an 'OR' operation
# Don't suppress this box, even though it has an overlap of 1 with itself
suppress[box] = 0
# Store only unsuppressed boxes for this class
image_boxes.append(class_decoded_locs[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
# If no object in any class is found, store a placeholder for 'background'
if len(image_boxes) == 0:
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.LongTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
# Concatenate into single tensors
image_boxes = torch.cat(image_boxes, dim=0) # (n_objects, 4)
image_labels = torch.cat(image_labels, dim=0) # (n_objects)
image_scores = torch.cat(image_scores, dim=0) # (n_objects)
n_objects = image_scores.size(0)
# Keep only the top k objects
if n_objects > top_k:
image_scores, sort_ind = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_ind][:top_k] # (top_k, 4)
image_labels = image_labels[sort_ind][:top_k] # (top_k)
NMS非极大值抑制
- 按照类别分组,依次遍历每个类别。
- 当前类别按分类置信度排序,并且设置一个最低置信度阈值,低于这个阈值的目标框直接舍弃。
- 当前概率最高的框作为候选框,其它所有与候选框的IOU高于一个阈值的框认为需要被抑制,从剩余框数组中删除。
- 然后在剩余的框里寻找概率第二大的框,其它所有与第二大的框的IOU高于设定阈值的框被抑制。
- 依次类推重复这个过程,直至遍历完所有剩余框,所有没被抑制的框即为最终检测框。
Fast R-CNN中的NMS实现
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
# dets: 检测的 boxes 及对应的 scores;
# thresh: 设定的阈值
def nms(dets,thresh):
# boxes 位置
x1 = dets[:,0]
y1 = dets[:,1]
x2 = dets[:,2]
y2 = dets[:,3]
# boxes scores
scores = dets[:,4]
areas = (x2-x1+1)*(y2-y1+1) # 各box的面积
order = scores.argsort()[::-1] # 分类置信度排序
keep = [] # 记录保留下的 boxes
while order.size > 0:
i = order[0] # score最大的box对应的 index
keep.append(i) # 将本轮score最大的box的index保留
\# 计算剩余 boxes 与当前 box 的重叠程度 IoU
xx1 = np.maximum(x1[i],x1[order[1:]])
yy1 = np.maximum(y1[i],y1[order[1:]])
xx2 = np.minimum(x2[i],x2[order[1:]])
yy2 = np.minimum(y2[i],y2[order[1:]])
w = np.maximum(0.0,xx2-xx1+1) # IoU
h = np.maximum(0.0,yy2-yy1+1)
inter = w*h
ovr = inter/(areas[i]+areas[order[1:]]-inter)
\# 保留 IoU 小于设定阈值的 boxes
inds = np.where(ovr<=thresh)[0]
order = order[inds+1]
return keep
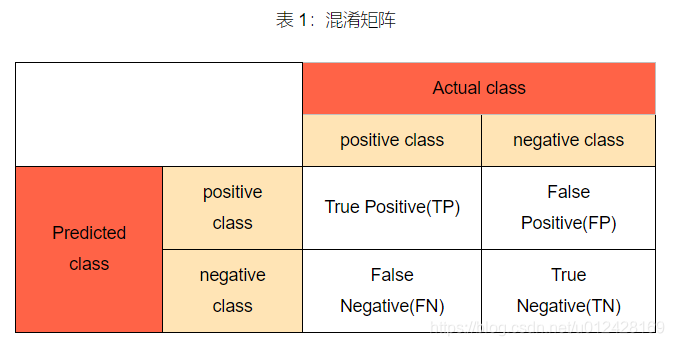
VOC测试集评测指标
- 一级指标
1. 真实值是positive,模型认为是positive的数量(True Positive=TP)
2. 真实值是positive,模型认为是negative的数量(False Negative = FN)
3. 真实值是negative,模型认为是positive的数量(False Positive = FP)
4. 真实值是negative,模型认为是negative的数量(True Negative = TN)
混淆矩阵记录了一级指标并且便于计算二级指标。
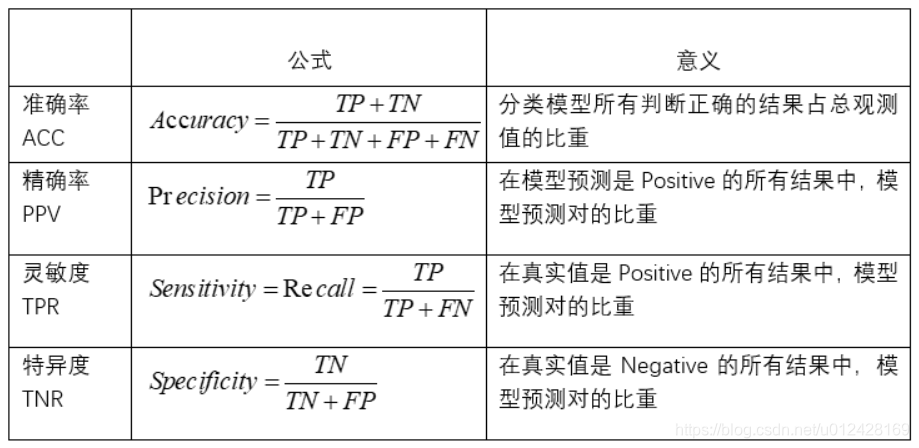
- 二级指标
1. 准确率(Accuracy)-----针对整个模型
2. 精确率(Precision)
3. 灵敏度(Sensitivity):就是召回率(Recall)
4. 特异度(Specificity)
- 三级指标
1. F1 Score
F1 Score = 2PR / P+R
其中,P代表Precision,R代表Recall(召回率)。F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1,1代表模型的输出最好,0代表模型的输出结果最差。
2. AP指标即Average Precision 即平均精确度。
3. mAP即Mean Average Precision即平均AP值,是对多个验证集个体求平均AP值,作为object
detection中衡量检测精度的指标。
P-R曲线:以precision和recall作为纵、横轴坐标的二维曲线。通过选取不同阈值时对应的精度和召回率画出。
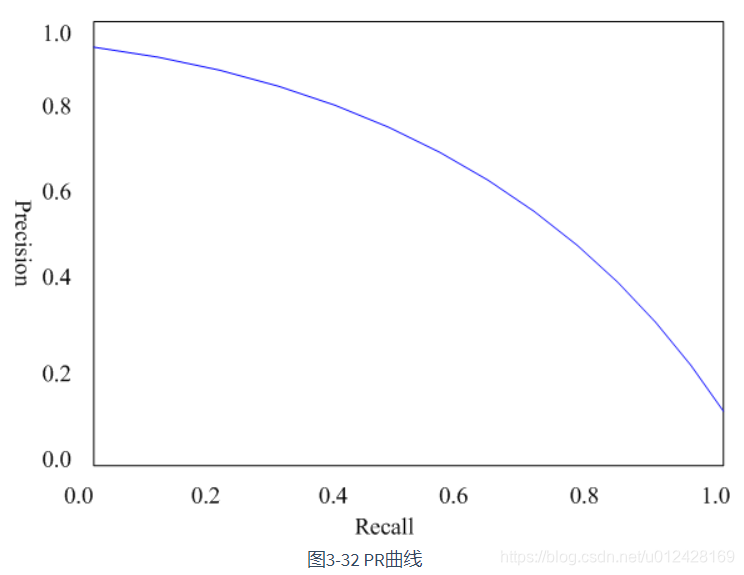
在目标检测中,每一类都可以根据recall和precision绘制P-R曲线,AP就是该曲线下的面积,mAP就是所有类的AP的平均值(VOC数据集计算方法)。














 1090
1090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









