









老规矩 先贴一波参数指标
电压主要参数
电压采集:±10V 可编程增益1、10、100、1000
电压分辨率:0.1uV
采集位数:24BIT
线性度:±(0.05%读数+0.005%量程)
电流主要参数
恒流输出:±1nA~±10mA
设计
一档:200M 1nA~10nA 0.5% 500fA
二档:20M 10nA~100nA 0.5% 5pA
三档:2M 100nA~1uA 0.1% 50pA
四档:200K 1uA~10uA 0.05% 500pA
五档:20K 10uA~100uA 0.05% 5nA
六档:2K 100uA~1mA 0.05% 50nA
七档:200R 1mA~10mA 0.05% 500nA
预留了232、485、液晶常用接口
这种电路其实可以称为“半导体I-V特性测试”电路
目前简易版用的数码管显示编码器调节输出 旋转越快输出变化越快比较方便 后期会升级为触摸液晶设置方便些
电流参数基本和Keithley 2450源表10mA以内一致 甚至稳定性比他那个要高一些
自己已经做过±1nA~±1A的电流源表 对标2450的输出参数 实测都还不错 这个算是缩减版的
做的过程中需要注意的几个点
1.大电阻选型 原本设计是MC102522006DE 货源不多 实际用的参数差一点的CRHA2510AF200MFKEF
2.走线和外部接线 对nA输出有很大影响 我所知道的是只要不同导线和金属材质之间就会产生热电偶效应就会有微弱电流产生带来影响 实测接不同导线后线性度和零点都会受到影响 对这部分研究比较少 有知道的坛友可以分享下经验
3.运放选型 一定要偏置电流低的
有需要了解更多可以Call me 0x3A1D78EFA
原理图
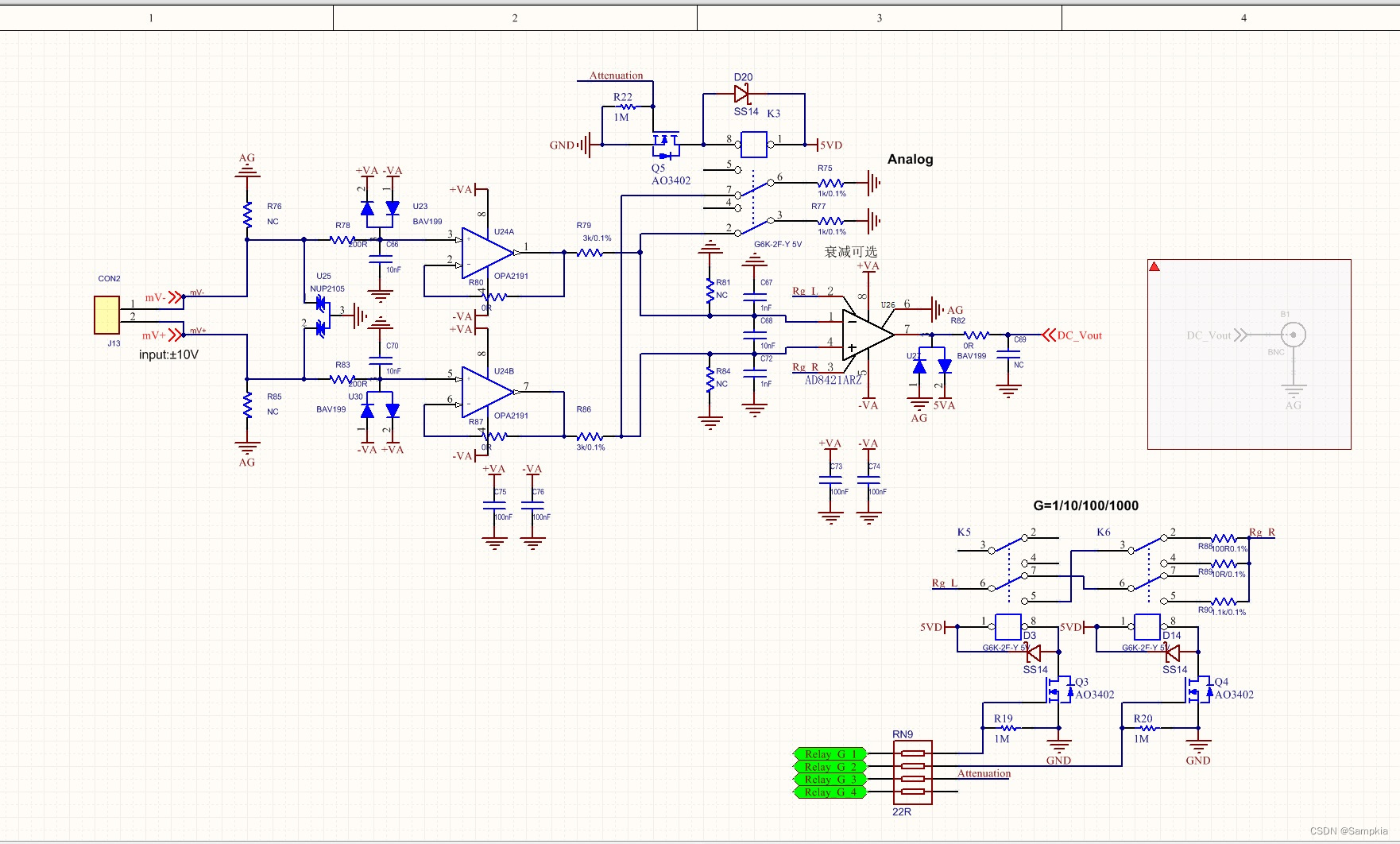
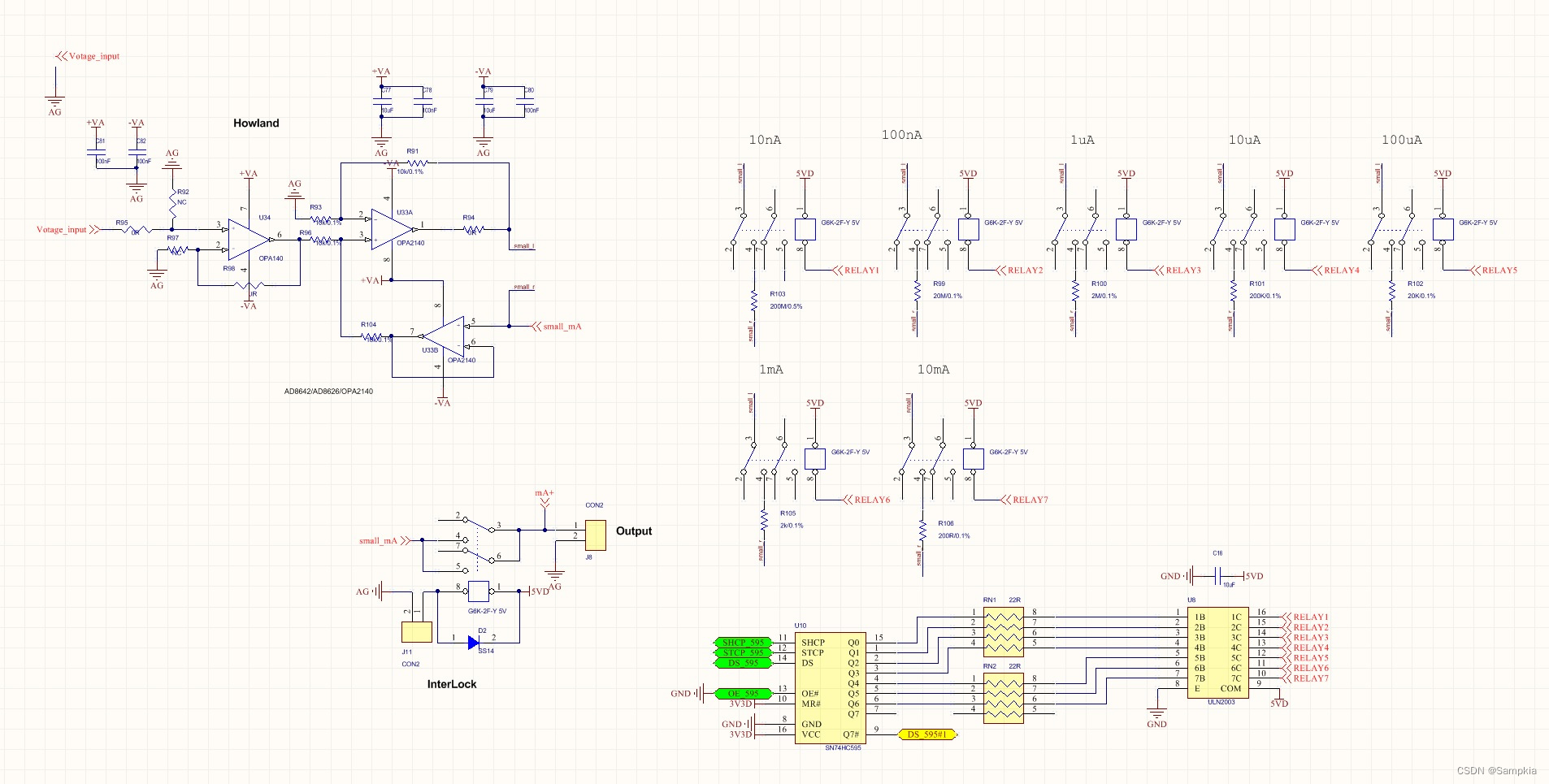

实物图



视频链接
100nA档位以下演示
https://v.youku.com/v_show/id_XN ... ~3~A&f=69028696&o=1
100nA档位以上演示
https://v.youku.com/v_show/id_XN ... ~5~A&f=69028696&o=1
接10M电阻演示
https://v.youku.com/v_show/id_XN ... ~5~A&f=69028696&o=1


















 4626
4626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











