







1. 引言
在ubuntu上安装完caffe后,按照官网的教程学习caffe。看得第一个例子是Lenet(LeCun et al., 1998),分别用命令行和python对其进行了训练。结合这两种训练方式及官网的教程,初步了解了caffe的结构。
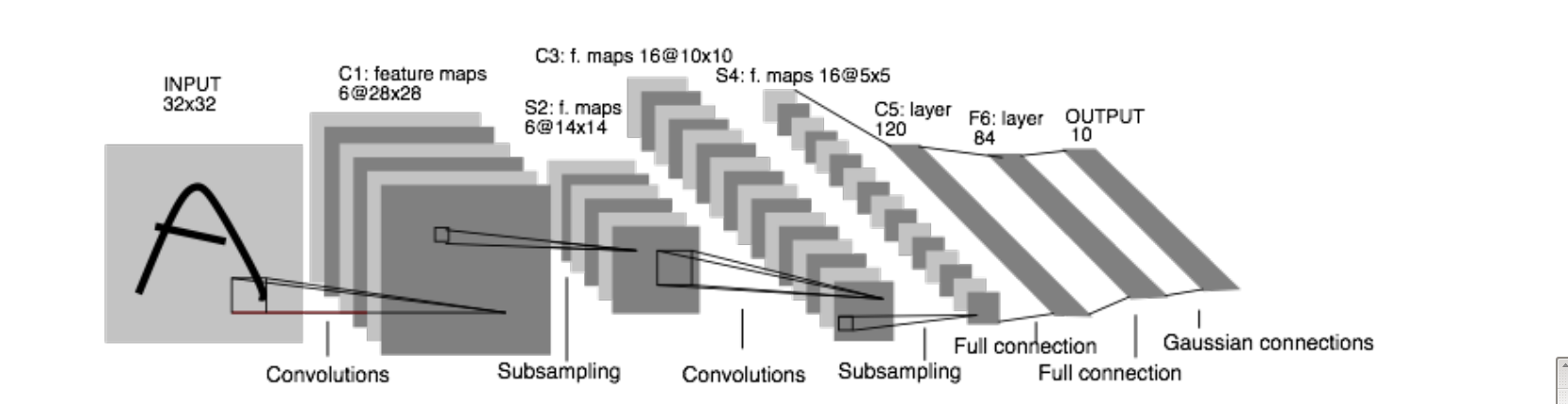
首先看命令行的训练过程,包括四步:
- 将输入(Mnist数据库)转换成caffe可以接收的格式,比如LMDB或者leveldb;
- 定义Net,主要是定义所有的Layers,也定义了与Layer相连的Blobs;
- 定义Solver,使用的优化方法是(SGD+momentum),给定了优化过程中的各种参数;
- 用caffe训练模型,这儿仅需要一条指令:caffe train –solver,具体为:./build/tools/caffe train –solver=examples/mnist/lenet_solver.prototxt;
可以看出,理解caffe的关键是中间两步,其中包括caffe重要的四个模块Net,Layers,Blobs和Solver。下面详细介绍这四个模块。
2. Nets
caffe的Net包括训练Net和测试Net,其保存在.prototxt文件中,训练Net的内容包括:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
transform_param {
scale: 0.00392156862745
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3341
3341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









