









文章目录
本文首先对图数据进行介绍,其中主要包括开源数据库(eg:RDF4J、gStore)、商业数据库(eg:Virtuoso、AllegroGraph和Stardog)和原生的图数据库(eg:Neo4j、OrientDB和Titan);之后介绍一个基于Apache Jena数据的示例。
一、图数据库
1、概述
图数据库(Graph Database) 源起欧拉和图理论 (graph theory),也可称为面向/基于图的数据库。
- 基本含义:以“图”这种数据结构存储和查询数据。
- 数据模型:主要是以节点和关系(边)来体现,也可处理键值对。
- 优点:快速解决复杂的关系问题。
图具有如下特征:
- 包含:节点和边;
- 节点上有属性 (键值对),边也可以有属性;
- 边有名字和方向,并总是有一个开始节点和一个结束节点;
图数据库的分类
- 原生数据库:包括基于main memory和基于disk。
- 非原生数据库
- RDBMS:基于关系数据库
- Schema-based:需要设计表结构
- Schema-free:不需要设计表结构,eg:Triple表
- 基于NoSQL
- Key-value:eg:Redis
- Column family:列数据库
- Document store:eg:MongoDB
- Graph database:eg:Neo4j(广义上的原生数据库)
- RDBMS:基于关系数据库

2、开源数据库介绍
(1)RDF4J
- 处理RDF数据的Java框架
- 使用简单可用的API来实现RDF存储
- 支持SPARQL endpoints
- 支持两种RDF存储机制
- 支持所有主流的RDF文件格式
(2)gStore
gStore——C++编写,查询速度快,推荐使用
- gStore从图数据库角度存储和检索RDF知识图谱数据;
- gStore支持W3C定义的SPARQL 1.1标准,包括含有Union,OPTIONAL,FILTER和聚集函数的查询;gStore支持有效的增删改操作
- gStore单机可以支持1Billion(十亿)三元组规模的RDF知识图谱的数据管理任务。
3、商业数据库介绍
(1)Virtuoso
- 智能数据,可视化与整合;
- 可扩展和高性能的数据管理;
- 支持 Web 扩展和安全
(2)Allgrograph
- 一个现代的,加载速度、查询速度、高性能的,支持永久存储的图数据库;
- 基于 Restful 接入支持多语言编程
(3)Stardog
Stardog:一个企业级的知识图谱数据库。使用Stardog,可以统一、查询、搜索和分析所有数据。
4、原生数据库介绍
(1)Neo4J
Neo4J 是一个高性能的 NOSQL 图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。
Neo4J 具有以下特性:
- 图数据库 + Lucene索引
- 支持图属性
- 支持ACID
- 高可用性
- 支持320亿的结点,320亿的关系结点,640亿的属性
- REST API 接口
数据结构:
- 一个图包含的基本的数据类型:Nodes (节点) 和 Relationships (关系)。
- Nodes 和 Relationships 包含 key/value 形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
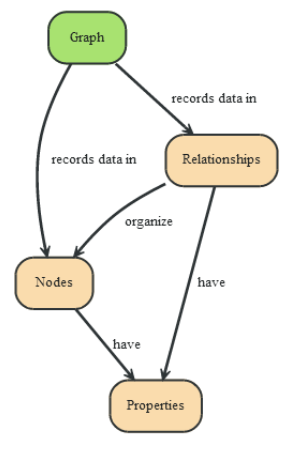
Neo4j的优点为: - 便于构建多元组:高连通数据
- 支持图计算:路径查找、A*算法
- 数据优先
Neo4j数据导入:
- Cypher
CREATE语句,为每一条数据写一个CREATE; - Cypher
LOAD CSV语句,将数据转成CSV格式,通过LOAD CSV读取数据; - 官方提供的Java API — Batch Inserter;
- 官方提供的 neo4j-import 工具;
- 第三方开发者编写的 Batch Import 工具。
Neo4j数据存储:

Neo4j查询数据:使用 Cypher 查询语言(基于遍历)

(2)OrientDB
OrientDB:一个用Java实现的开源NoSQL数据库管理系统。
它是一个多模式的数据库,支持图形、文档、键值对、对象模型和关系,也可以为图数据库的管理与记录之间的提供连接。
(3)Titan
Titan 的适用性:小规模不推荐使用
特点
- 弹性和线性增长的数据和用户的可扩展性;
- 数据分布和复制性能和容错性;
- 支持增删改查,支持一致性;
- 支持各种后端存储;
- 支持全局图数据分析,报告,并通过ETL连接大数据平台;
- 支持全文检索
5、Benchmark
网站:https://www.w3.org/wiki/RdfStoreBenchmarking

常用衡量指标:
- Load Time
- Repository Size:
- 当知识图谱越大时,希望读写性能呈线性增长时的斜率低 ==》扩展性越强
- Query Response Time
- 单Query:是否使用了Cache(缓存:系统缓存、数据库缓存)
- 多Query:mix query使得cache失效,大多存在与冷启动,即cache无预先保存与Query相关的结果情况
- Throughputs:单Query、多Query
- Inference Support
二、知识存储的示例
Jena是一个免费开源的支持构建语义网络和数据链接应用的Java框架。
- 底层存储支持基于内存、基于SDB(导入关系数据库)、基于TDB(导入原生的三元组数据)和基于custom的存储;
- 同时Jena还支持一些推理的API;
- RDF API,支持基于SPARQL语言的查询;
- 可使用Fuseki进行增删查改。

1、背景
定义一个音乐知识图谱的 Schema 如下:
- Schema中的蓝线指向属性,绿线指向实体,虚线指向图谱生成之后添加的属性,后面通过 SPARQL Update 语句添加。

2、准备工作
数据生成:
使用python脚本生成了1000个音乐知识图谱的三元组:

数据导入:
- 使用TDB导入
使用tdbloader工具的命令为:/jena-fuseki/data是存储的位置。/jena-fuseki/tdbloader --loc=/jena-fuseki/data filename - 使用Fuseki导入
启动Fuseki服务:
在导入数据之后我们可以使用接口对我们的数据进行查询,于是我们使用Fuseki Server进行查询,启动命令如下,注意此处需要指定TDB生成的文件路径和数据库名:其中 /music 是刚刚导入的数据
/jena-fuseki/fuseki-server --loc=/jena-fuseki/data --update /music
数据库查询方法:
- Fuseki界面查询;
- 使用endpoint接口查询,endpoint地址为:
- SPARQL Query: http://localhost:3030/music/query
- SPARQL Update: http://localhost:3030/music/update
- Python操作Jena
- 使用Jena SPARQL endpoint接口进行查询和更新
- 使用SPARQLWrapper包查询和更新(详见https://rdflib.github.io/sparqlwrapper/)

3、查询示例
(1)查询某一艺术家的所有歌曲
PREFIX music:<http://kg.course/music/>
SELECT DISTINCT ?trackID
WHERE {
?trackID music:track_artist music:artist_01
}
(2)查询某一艺术家的所有歌曲的歌曲名
PREFIX music:<http://kg.course/music/>
SELECT ?name
WHERE {
?trackID music:track_artist music:artist_01 .
?trainID music:track_name ?name
}
(3)查询某一首歌曲名的专辑信息
PREFIX music:<http://kg.course/music/>
SELECT ?trackID ?albumID ?name
WHERE {
?trackID music:track_name "track_name_00001" .
?trackID music:track_album ?ablumID .
?ablumID music:album_name ?name
}
(4)查询某一首歌曲名的专辑信息,使用中文来当变量名
PREFIX music:<http://kg.course/music/>
SELECT ?歌曲ID ?专辑ID ?专辑名
WHERE {
?歌曲ID music:track_name "track_name_00001" .
?歌曲ID music:track_album ?专辑ID .
?专辑ID music:album_name ?专辑名
}
(5)查询某一首歌曲名的专辑信息,变量名添加描述
PREFIX music:<http://kg.course/music/>
SELECT ?歌曲ID ?专辑ID (CONCAT("专辑名",":",?专辑名) AS ?专辑信息)
WHERE {
?歌曲ID music:track_name "track_name_00001" .
?歌曲ID music:track_album ?专辑ID .
?专辑ID music:album_name ?专辑名
}
(6)查询某个专辑里面的所有歌曲
PREFIX music:<http://kg.course/music/>
SELECT ?trackID
WHERE {
?albumID music:ablum_name "ablum_name_00002"
?trackID music:track_ablum ?albumID
}
(7)查询某个专辑里面的所有歌曲,限制前2
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?S ?P
WHERE {
?subject ?predicate "ablum_name_0002" .
?S ?P ?subject
}
limit 2
(8)对某个专辑里面的所有歌曲计数
PREFIX music: <http://kg.course/music/>
SELECT (COUNT(?trackID) as ?num)
WHERE {
?albumID music:album_name "album_name_0002" .
?trackID music:track_album ?albumID
}
(9)查询某一首歌是哪一个艺术家的作品
PREFIX music: <http://kg.course/music/>
SELECT ?trackID ?artistID
WHERE {
?trackID music:track_name "track_name_00001" .
?trackID music:track_artist ?artistID
}
(10)查询某一首歌属于什么歌曲类型
PREFIX music: <http://kg.course/music/>
SELECT ?trackID ?tag_name
WHERE {
?trackID music:track_name "track_name_00001" .
?trackID music:track_tag ?tag_name
}
(11)查询某一艺术家唱过歌曲的所有标签
PREFIX music: <http://kg.course/music/>
SELECT DISTINCT ?tag_name
WHERE {
?trackID music:track_artist music:artist_001 .
?trackID music:track_tag ?tag_name
}
(12)查询某一艺术家唱过歌曲的所有类型并排序
PREFIX music: <http://kg.course/music/>
SELECT DISTINCT ?tag_name
WHERE {
?trackID music:track_artist music:artist_001 .
?trackID music:track_tag ?tag_name
}
ORDER BY ?tag_name
(13)查询某几类歌曲标签中的歌曲的数目
PREFIX music: <http://kg.course/music/>
SELECT (count(?trackID) AS ?num)
WHERE {
{
?trackID music:track_tag "tag_name_01" .
}
UNION
{
?trackID music:track_tag "tag_name_02" .
}
}
PREFIX music: <http://kg.course/music/>
SELECT (count(?trackID) AS ?num)
WHERE {
?trackID music:track_tag ?tag_name
FILTER (?tag_name = "tag_name_001" || ?tag_name = "tag_name_002")
}
(14)查询所有歌曲中带有’xx’字符的歌曲名
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?subject ?object
WHERE {
?subject <http://kg.course/music/track_name> ?object .
FILTER regex(?object,"088")
}
(15)询问是否存在带有’xx’字符的歌曲名
PREFIX music: <http://kg.course/music/>
ASK
{
?trackID music:track_name ?track_name .
FILTER regex(?track_name,"008")
}
4、增加示例
给艺术家id新增属性艺术家名字
PREFIX music: <http://kg.course/music/>
INSERT DATA
{
music:arttist_01 music:artist_name "artist_name_01" .
music:arttist_02 music:artist_name "artist_name_02" .
music:arttist_03 music:artist_name "artist_name_03" .
}
查询测试
PREFIX music: <http://kg.course/music/>
SELECT ?artistID ?artist_name
WHERE {
?artistID music:artist_name ?artist_name
}
5、删除示例
删除增加的属性艺术家名字
PREFIX music: <http://kg.course/music/>
DELETE
{
music:artist_02 music:artist_name ?x .
}
WHERE
{
music:artist_02 music:artist_name ?x .
}
查询测试
PREFIX music: <http://kg.course/music/>
SELECT ?artistID ?artist_name
WHERE {
?artistID music:artist_name ?artist_name
}















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









