







 本文回顾了六种排序算法:冒泡、选择、插入、希尔、快速和归并排序。介绍了每种排序的工作原理,并提供了C++实现及排序速度的测试结果。
本文回顾了六种排序算法:冒泡、选择、插入、希尔、快速和归并排序。介绍了每种排序的工作原理,并提供了C++实现及排序速度的测试结果。
闲来无事回顾一下原来所学的排序算法,包括冒泡、选择、插入、希尔、快速、归并排序,这六种。
首先依次讲解原理,最后放出实现及测试速度源码。
冒泡排序
我想大部分人学习的第一个排序算法就是这个。
顾名思义,如泡泡般,越到水面就越大,即经过连续不断的判断,选取大(或小)的值进行交换,一轮结束后,未排序数据最后面的就是最大(或最小)的值。
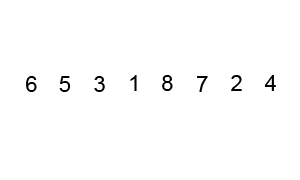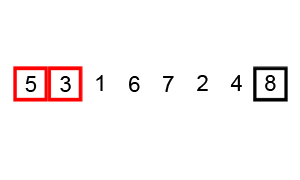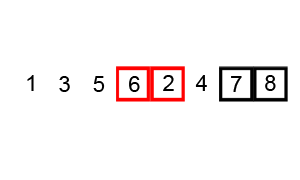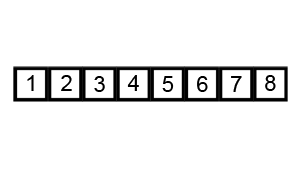
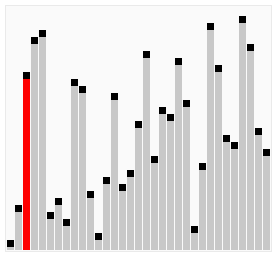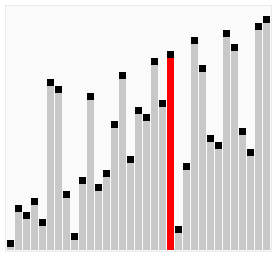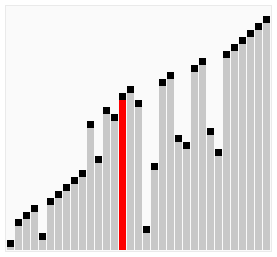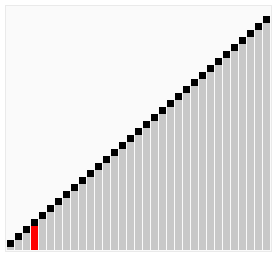

工作原理
- 比较相邻的元素,如果前一个比后一个大,就交换它们两个。
- 对每一个对相邻的元素作同样的操作,从开始的第一对到结尾的最后一对,这步骤做完后,最后的元素就是最大的元素。
- 针对所有的元素重复以上的步骤,除开最后一个。
- 持续每次对原来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
选择排序
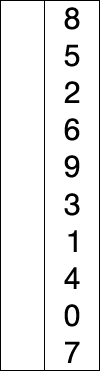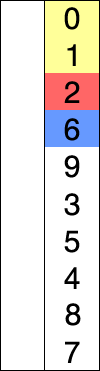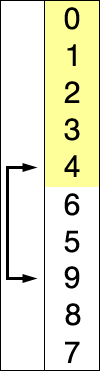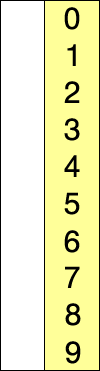
选择排序相对于冒泡排序来说,减少了数据交换的次数,在每轮比较中,仅保存大的元素的序号,在一轮结束后通过序号获取最大的元素将其移动到最后面。

工作原理
- 在为排序序列中找到最小(大)元素,存放到排序序列的起始位置(终止位置)
- 从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的起始位置(终止位置)。
- 重复上述操作直到所有元素排序完毕。
插入排序
插入的意思就是将未排序的元素插入到已排序的元素之中。将第一个元素作为已排序的元素,然后取第二个元素与第一个元素比较,小于的话就将其插入到第一个元素之前,否者不变,此时得到一个有序元素数列,然后如第三个元素依次与第二个元素和第一个元素比较,依此类推,将所有未排序的元素依次与前面所有已排序的元素进行比较,然后插入。
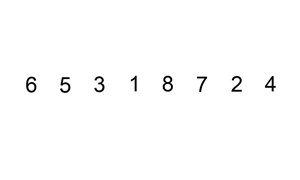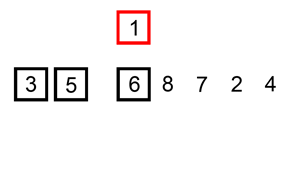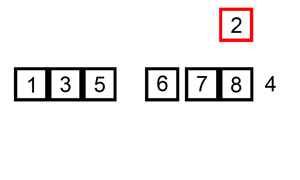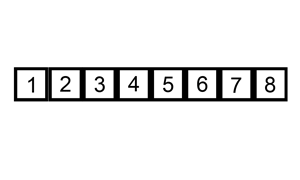

工作原理
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到对应的位置并插入。
希尔排序
又称递减增量排序算法
希尔排序是针对插入排序优化后的算法。引入了步长(增量),将元素分区处理。越到后面步长越小,直至变成普通的插入排序,此时元素已几乎排列完成,插入排序的速度是最快的。
快速排序
快速排序可以理解为挖坑填坑排序,一般情况下是将第一个元素当作坑,然后以坑元素为分界线,大的在右边,小的在左边,最后剩下的位置就是坑元素排序后的位置,然后除坑元素以外,左右分为两个元素数列,重复以上操作,直至不可分位置,即排列好所有元素。一般使用递归的方法实现。
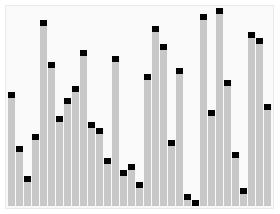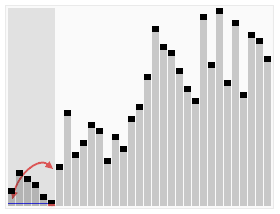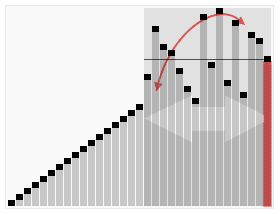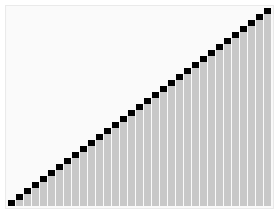
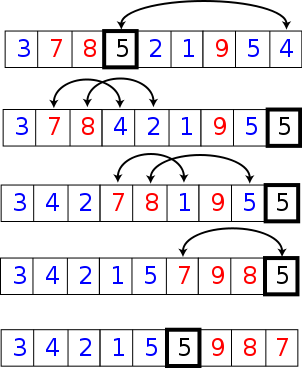
工作原理
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。
步骤为:
1. 从数列中挑出一个元素,称为”基准”(pivot)。
2. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
归并排序
可以理解为不停的分组直至组中元素不能再分,然后按照分组的顺序反向有序合并分组,最终就能的到一个有序序列。一般使用递归实现。
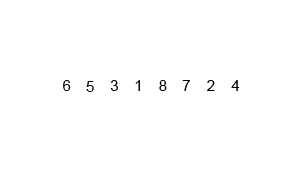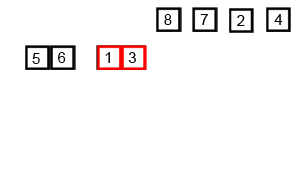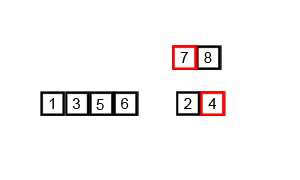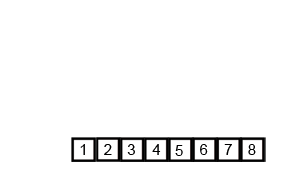

工作原理
原理如下(假设序列共有n个元素):
1. 将序列每相邻两个数字进行归并操作,形成floor(n/2) 个序列,排序后每个序列包含两个元素
2. 将上述序列再次归并,形成floor(n/4)个序列,每个序列包含四个元素
3. 重复步骤2,直到所有元素排序完毕
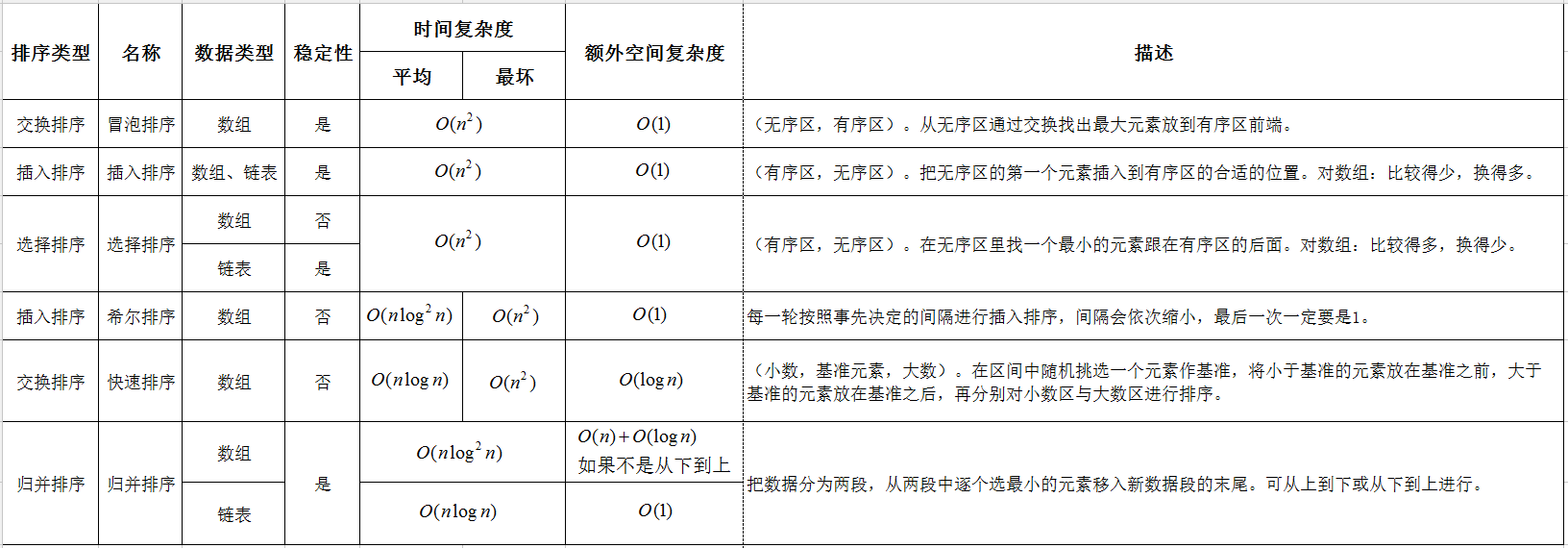
排序算法比较
排序算法C++实现及测速
# include <stdio.h>
# include <malloc.h>
# include <time.h>
# include <memory.h>
# include <stdlib.h>
//交换元素
# define SWAP(a, b){a = a+b;b = a - b;a = a - b;}
//冒泡排序
void BubbleSort(int nNumbers[], int length)
{
for (int i = 0; i < length - 1; i++)//排序需循环次数,完成一次得到一个最大的数
{
for (int j = 0; j < length - i - 1; j++)//遍历未排序相邻元素
{
if (nNumbers[j] > nNumbers[j + 1])//比较相邻元素
{
SWAP(nNumbers[j], nNumbers[j + 1]);
}
}
}
}
//插入排序
void InsertSort(int nNumbers[], int length)
{
int nBuff = 0;
int targetIndex = 0;
for (int i = 1; i < length; i++)
{
nBuff = nNumbers[i];//需插入的元素
targetIndex = i;//需插入元素的位置
for (int j = i - 1; j >= 0 && nNumbers[j] > nBuff; j--)//循环完成之后得到插入的位置
{
nNumbers[j + 1] = nNumbers[j];//元素后移
targetIndex = j;
}
if (i != targetIndex)
{
nNumbers[targetIndex] = nBuff;//插入元素
}
}
}
//选择排序
void SelectSort(int nNumbers[], int length)
{
int nMaxIndex = 0;
for (int i = length - 1; i > 0; i--)
{
nMaxIndex = i;//初始最大元素的序号
for (int j = 0; j < i; j++)//遍历未排序元素
{
if (nNumbers[nMaxIndex] < nNumbers[j])
{
nMaxIndex = j;//获取当前大元素序号
}
}
if (nMaxIndex != i)
{
SWAP(nNumbers[nMaxIndex], nNumbers[i]);//交换
}
}
}
//希尔排序
void ShellSort(int nNumbers[], int length)
{
int nBuff = 0;
int nTargetIndex = 0;
for (int nDelta = length / 2; nDelta > 0; nDelta /= 2)//设置步长,即分组。下面实现同插入排序
{
for (int i = nDelta; i < length; i += nDelta)
{
nBuff = nNumbers[i];
nTargetIndex = i;
for (int j = i - nDelta; j >= 0 && nNumbers[j] > nBuff; j -= nDelta)
{
nNumbers[j + nDelta] = nNumbers[j];
nTargetIndex = j;
}
if (i != nTargetIndex)
{
nNumbers[nTargetIndex] = nBuff;
}
}
}
}
//快速排序
void QuickSort(int nNumbers[], int nStart, int nEnd)
{
if (nStart >= nEnd)
{//当不能再分的时候,直接返回,跳出递归。
return;
}
int ns = nStart;
int ne = nEnd;
int nBuf = nNumbers[ns];//挖坑
while (ns < ne)
{
//将小的元素放到左边
while (ns < ne && nBuf <= nNumbers[ne])
{
ne--;
}
if (ns < ne)
{
SWAP(nNumbers[ns], nNumbers[ne]);
ns++;
}
//将大的元素放到右边
while (ns < ne && nBuf > nNumbers[ns])
{
ns++;
}
if (ns < ne)
{
SWAP(nNumbers[ns], nNumbers[ne]);
ne--;
}
}
nNumbers[ns] = nBuf;//填坑
//分组并递归调用
QuickSort(nNumbers, nStart, ns - 1);//左数列
QuickSort(nNumbers, ns + 1, nEnd);//右数列
}
//归并算法-排序并合并分组
void MergetSortGroup(int nNumbers[], int nStart, int nMid, int nEnd, int *temp)
{
int nGroup_1 = nStart;
int nGroup_2 = nMid + 1;
int nIndex = 0;
//有序合并元素序列
while (nGroup_1 <= nMid && nGroup_2 <= nEnd)
{
temp[nIndex++] = nNumbers[nGroup_1] < nNumbers[nGroup_2] ? nNumbers[nGroup_1++] : nNumbers[nGroup_2++];
}
//合并剩余元素
while (nGroup_1 <= nMid)
{
temp[nIndex++] = nNumbers[nGroup_1++];
}
//合并剩余元素
while (nGroup_2 <= nEnd)
{
temp[nIndex++] = nNumbers[nGroup_2++];
}
//复制到正真的元素数列
nIndex--;
while (nIndex >= 0)
{
nNumbers[nStart + nIndex] = temp[nIndex];
nIndex--;
}
}
//归并算法-分组
void MergeSplitGroup(int nNumbers[], int nStart, int nEnd, int* temp)
{
if (nStart < nEnd)
{
int mid = (nStart + nEnd) / 2;//平分元素数列
MergeSplitGroup(nNumbers, nStart, mid, temp);//左数列
MergeSplitGroup(nNumbers, mid + 1, nEnd, temp);//右数列
MergetSortGroup(nNumbers, nStart, mid, nEnd, temp);//有序合并数列
}
}
//归并算法
void MergeSort(int nNumbers[], int length)
{
int *temp = (int*)malloc(sizeof(int)*length);//初始化临时合并空间
MergeSplitGroup(nNumbers, 0, length - 1, temp);//分组
free(temp);//释放
}
//使用随机数填充数组
void InitRandNumber(int nNumbers[], int length)
{
length--;
while (length >= 0)
{
nNumbers[length] = 0 + rand() % (INT_MAX);//2147483647为int32最大范围
length--;
}
}
//检查排序是否正确
bool CheckSort(int nNumbers[], int length)
{
for (int i = 0; i < length; i++)
{
if (i - 1 > 0)
{
if (nNumbers[i] < nNumbers[i - 1])
{
return false;
}
}
if (i + 1 < length)
{
if (nNumbers[i] > nNumbers[i + 1])
{
return false;
}
}
}
return true;
}
//打印数组
void Print(int nNumbers[], int length)
{
printf("Result:\n");
for (int i = 0; i < length; i++)
{
printf("%d ", nNumbers[i]);
}
printf("\n");
}
void main()
{
clock_t start = 0, finish = 0;//设置时钟
double duration = 0;//用时
int nLength = 50000;//需排序的数据个数
int *nNumbers = nullptr;
int *nSortAry = nullptr;
int nSize = 0;
nSize = sizeof(int) * nLength;
nNumbers = (int *)malloc(nSize);
nSortAry = (int *)malloc(nSize);
InitRandNumber(nNumbers, nLength);
printf("排序 %d 个随机整型的数组。\n", nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
BubbleSort(nSortAry, nLength);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("BubbleSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength)?1:0);
//Print(nSortAry, nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
InsertSort(nSortAry, nLength);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("InsertSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength) ? 1 : 0);
//Print(nSortAry, nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
SelectSort(nSortAry, nLength);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("SelectSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength) ? 1 : 0);
//Print(nSortAry, nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
ShellSort(nSortAry, nLength);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("ShellSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength) ? 1 : 0);
//Print(nSortAry, nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
QuickSort(nSortAry, 0, nLength - 1);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("QuickSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength) ? 1 : 0);
//Print(nSortAry, nLength);
memcpy(nSortAry, nNumbers, nSize);
start = clock();//开始计时
MergeSort(nSortAry, nLength);
finish = clock();//结束计时
duration = (double)(finish - start) / CLOCKS_PER_SEC;//去掉 /CLOCKS_PER_SEC 后单位是毫秒,不去为秒
printf("MergeSort \t = \t%0.3lf seconds\t Check \t = \t%d\n ", duration, CheckSort(nSortAry, nLength) ? 1 : 0);
//Print(nSortAry, nLength);
printf("Sort All Over !\n");
free(nNumbers);
free(nSortAry);
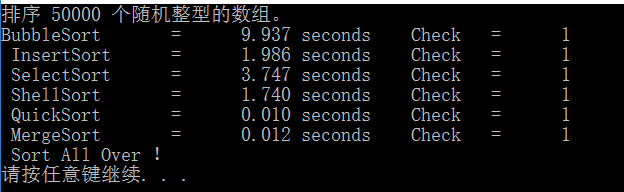
}运行结果如下:
如不清楚可查阅下列资料:
Wiki:https://zh.wikipedia.org/wiki/sorting_algorithm
















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









