









1. dirac函数
狄拉克(dirac)函数是一个广义函数,在物理学中常用其表示质点、点电荷等理想模型的密度分布,该函数在除了零以外的点取值都等于零,而其在整个定义域上的积分等于1。

————————————————
原文链接:https://baike.baidu.com/item/%E7%8B%84%E6%8B%89%E5%85%8B%CE%B4%E5%87%BD%E6%95%B0/5760582?fr=aladdin
2. one-hot编码
2.1 one-hot 基本使用
# X shape (60,000 28x28),
X_train.reshape(X_train.shape[0], -1)
保留第一维,其余的维度,重新排列为一维,-1等同于28*28,reshape后的数据是共60000行,每一行784个数据点。
to_categorical就是将类别向量转换为二进制(只有0和1)的矩阵类型表示。其表现为将原有的类别向量转换为独热(onehot)编码的形式。
from keras.utils.np_utils import *
#类别向量定义
b = [0,1,2,3,4,5,6,7,8]
#调用to_categorical将b按照9个类别来进行转换
b = to_categorical(b, 9)
print(b)
执行结果如下:
[[1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1.]]
————————————————
版权声明:本文为CSDN博主「奔跑的小仙女」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43211132/article/details/96141409
2.2 one-hot在多分类中的不足
在使用softmax进行分类的过程中,输入结果属于某一类的概率为:
p
(
k
∣
x
)
=
e
x
p
(
z
k
)
∑
i
i
=
K
e
x
p
(
z
i
)
p(k|x)=\frac{exp(z_k)}{\sum_{i}^{i=K}exp(z_i)}
p(k∣x)=∑ii=Kexp(zi)exp(zk)
使用的损失函数为:
l
o
s
s
=
−
∑
k
=
1
K
q
(
k
∣
x
)
l
o
g
(
p
(
k
∣
x
)
)
loss=−\sum_{k=1}^{K}q(k|x)log(p(k|x))
loss=−k=1∑Kq(k∣x)log(p(k∣x))
z
i
z_i
zi:也为logits,即未被归一化的对数概率;
p
p
p:predicted probability,预测的example的概率;
q
q
q:groundtruth probablity,真实的example的label概率;对于one-hot,真实概率为Dirac函数,即
q
(
k
)
=
δ
k
,
y
q(k)=δ_{k,y}
q(k)=δk,y,其中y是真实类别。
l
o
s
s
loss
loss:Cross Entropy,采用交叉熵损失。
具体的例子:
假设选用softmax交叉熵训练一个三分类模型,某样本经过网络最后一层的输出为向量
x
=
(
1.0
,
5.0
,
4.0
)
x=(1.0, 5.0, 4.0)
x=(1.0,5.0,4.0),对x进行softmax转换输出为:
p
=
(
exp
(
x
1
)
∑
i
=
1
3
exp
(
x
i
)
,
exp
(
x
2
)
∑
i
=
1
3
exp
(
x
i
)
,
exp
(
x
3
)
∑
i
=
1
3
exp
(
x
i
)
)
=
[
0.013
,
0.721
,
0.265
]
p=(\frac{\exp(x_1)}{\sum_{i=1}^3}\exp(x_i), \frac{\exp(x_2)}{\sum_{i=1}^3}\exp(x_i), \frac{\exp(x_3)}{\sum_{i=1}^3}\exp(x_i)) =[0.013, 0.721, 0.265]
p=(∑i=13exp(x1)exp(xi),∑i=13exp(x2)exp(xi),∑i=13exp(x3)exp(xi))=[0.013,0.721,0.265]
假设该样本y=[0, 1, 0],那损失loss:
l
o
s
s
=
∑
i
=
1
3
−
y
i
∗
log
(
p
i
)
=
0.327
loss = \sum_{i=1}^{3}-y_i * \log(p_i)=0.327
loss=i=1∑3−yi∗log(pi)=0.327
按softmax交叉熵优化时,针对这个样本而言,会让0.721越来越接近于1,因为这样会减少loss,但是这有可能造成过拟合。可以这样理解,如果0.721已经接近于1了,那么网络会对该样本十分“关注”,也就是过拟合。
换句话说:对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
- 无法保证模型的泛化能力,容易造成过拟合
- 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。
另一种理解:
在分类任务中,我们通常对类别标签的编码使用
[
0
,
1
,
2
,
…
]
[0,1,2,…]
[0,1,2,…]这种形式。在深度学习中,通常在全连接层的最后一层,加入一个softmax来计算输入数据属于每个类别的概率,并把概率最高的作为这个类别的输入,然后使用交叉熵作为损失函数。这会导致模型对正确分类的情况奖励最大,错误分类惩罚最大。如果训练数据能覆盖所有情况,或者是完全正确,那么这种方式没有问题。但事实上,这不可能。所以这种方式可能会带来泛化能力差的问题,即过拟合。
————————————————
- 原文链接:https://www.cnblogs.com/zyrb/p/9699168.html
- 原文链接:https://www.datalearner.com/blog/1051561454844661
3. Lable Smoothing
在2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision.)。其中提到了Label Smoothing技术,用以减轻这个问题。
y
k
L
S
=
y
k
(
1
−
α
)
+
α
u
(
K
)
(3.1)
y_k^{LS}=y_k(1-\alpha)+\alpha u(K) \tag{3.1}
ykLS=yk(1−α)+αu(K)(3.1)
在论文中,作者假定标签分类为均匀分布,故而(3.1)式又写成:
y
k
L
S
=
y
k
(
1
−
α
)
+
α
/
K
(3.2)
y_k^{LS}=y_k(1-\alpha)+\alpha/K \tag{3.2}
ykLS=yk(1−α)+α/K(3.2)
其中
K
K
K为类别数,
α
\alpha
α为label smoothing引入的超参数,
y
k
y_k
yk在
K
K
K为正确类别时为 1,其余为0,也就是
y
K
∈
{
0
,
1
}
y_K \in \{0, 1\}
yK∈{0,1}
那么,公式(3.1)的交叉熵损失为:
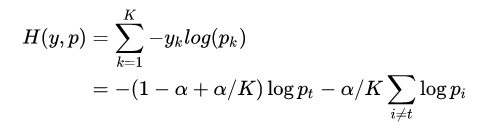
可以认为:Loss 函数为分别对【预测label与真实label】【预测label与先验分布】进行惩罚。
3.1 一个具体的例子
我们先来看一下原理。
假设我们的分类只有两个,一个是猫一个不是猫,分别用1和0表示。Label Smoothing的工作原理是对原来的
[
01
]
[0 1]
[01]这种标注做一个改动,假设我们给定Label Smoothing的值为0.1:
[
0
,
1
]
×
(
1
−
0.1
)
+
0.1
/
2
=
[
0.05
,
0.95
]
[0,1]×(1−0.1)+0.1/2=[0.05,0.95]
[0,1]×(1−0.1)+0.1/2=[0.05,0.95]
可以看到,原来的
[
01
]
[0 1]
[01]编码变成了
[
0.05
,
0.95
]
[0.05,0.95]
[0.05,0.95]了。这个label_smoothing的值假设为
ϵ
\epsilon
ϵ,那么就是说,原来分类准确的时候,
p
=
1
p=1
p=1,不准确为
p
=
0
p=0
p=0,现在变成了
p
1
=
1
−
ϵ
,
p
0
=
ϵ
p_1=1-\epsilon, p_0=\epsilon
p1=1−ϵ,p0=ϵ,也就是说对分类准确做了一点惩罚。
————————————————
- 原文链接:https://www.datalearner.com/blog/1051561454844661
- 论文链接:https://arxiv.org/abs/1512.00567
- 原文链接:https://www.cnblogs.com/zyrb/p/9699168.html
- 原文链接:https://www.datalearner.com/blog/1051561454844661
3.2 公式推导



import torch
K = 10
alpha = 0.1
lr = 0.1
a_num = torch.randn((K,)).float()
for i in range(40000):
a = torch.autograd.Variable(a_num, requires_grad=True)
b = torch.exp(-a)
c = alpha / K * a.sum() + torch.log(1 + b.sum())
c.backward()
a_num = a_num - lr * a.grad
print(a_num, c)
#output: tensor([4.4995, 4.4995, 4.4995, 4.4995, 4.4995, 4.4995, 4.4995, 4.4995, 4.4995,
# 4.4995]) tensor(0.5553, grad_fn=<AddBackward0>)
















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









