









1 Summary
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。注:写文章summary切记需要通过自己的思考,用自己的语言描述。忌讳直接Ctrl + c原文。
2 Research Objective(s)
bottom-up approaches to estimate the keypoints of skeleton
3 Problem Statement
- unknow number of people that can occur at any position or scale
- interactions between people induce complex spatial interference
- runtime complexity tends to grow with the number of people in the image
4 Method(s)
输入: color image of size
w
×
h
w \times h
w×h,
输出: anatomical keypoints for each person
中间过程:feed forward network predicts a set of 2D confidence maps
S
S
S of body part locations(2b) and a set of 2D vector fields
L
L
L of part affinities, which encode the degree of association between parts (身体部分的locations 和 所有的同类,比如都是elbow)。
其中confidence map
S
S
S有
J
J
J个(图中所有key point的个数,
S
j
∈
R
w
×
h
S_j \in \mathbb{R}^{w \times h}
Sj∈Rw×h代表第
j
j
j个key point对应的location);
L
L
L有
C
C
C个,
L
c
∈
R
w
×
h
×
2
\bold{L}_c \in \mathbb{R}^{w \times h \times 2}
Lc∈Rw×h×2代表第
c
c
c个body parts(例如:手臂)的image location的2D vector(position and orientation)

Q1: 这里的image location可不可以理解为像素?
4.2.1. Simultaneous Detection and Association
The network is split into two branches:
- the top branch----> predicts the confidence maps,一个关键点对应网络生成的一个feature map,如果有J个关键点,则共有J张feature map;
- the bottom branch ----> predicts the affinity fields,用于度量两个关键点之间的紧密度(有连接关系的则说明比较紧密,注意,这里每个paf都用二维的向量表示(横纵坐标))

在上图中, F \bold{F} F是VFF-19的前10层经过微调后输出的feature map; S t = ρ t ( F ) \bold{S}^t=\rho^t(\bold{F}) St=ρt(F) 代表 t t t时刻的confidence maps; L t = ϕ ( F ) \bold{L}^t=\phi(\bold{F}) Lt=ϕ(F) 代表 t t t时刻的part affinity fields; ρ t ( ) , ϕ t ( ) \rho^t(), \phi^t() ρt(),ϕt()代表stage t t t 中的CNN 函数;
然后concate一下 feature map F \bold{F} F, detection confidence maps S t − 1 \bold{S}^{t-1} St−1, part affinity fields L t − 1 \bold{L}^{t-1} Lt−1:

然后loss函数可以表示为:

在上述公式中 S j ∗ \bold{S}^*_j Sj∗ 是 groundtruth part confidence map , L c ∗ \bold{L}^*_c Lc∗groundtruth part affinity vector field, W \bold{W} W is a binary mask with W ( p ) = 0 \bold{W(p)} = 0 W(p)=0 when the annotation is missing at an image location P \bold{P} P
The mask is used to avoid penalizing the true positive predictions during training.
整个训练过程的loss可以表示为:
Q2: how to compute the gt part confidence map and gt part affinity vector field (position and orientation)

4.2.2 Confidence Maps for Part Detection
this part introduce how to calculate the S ∗ \bold{S}^* S∗
S
j
,
k
∗
\bold{S}_{j,k}^*
Sj,k∗ means 第
k
k
k个人的第
j
j
j部分的location
则
S
j
,
k
∗
\bold{S}_{j,k}^*
Sj,k∗ 被表示为:
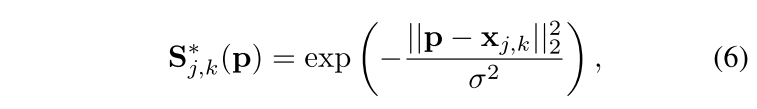
对于一副图中的多个key points(红蓝两种点)可能有下图(a)中的灰色的链接方式,接下来把正确的连接方式用黑色线表示,错误的连接方式用绿色线表示,如图(b),然后再施加PAFs(下图©中的黄色箭头)

S
j
,
k
∗
\bold{S}_{j,k}^*
Sj,k∗ 选择所有的人中最“清晰”的点
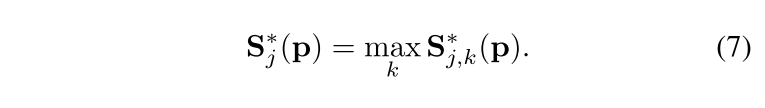
至于为什么选max而不是mean,作者专门作图研究过。
4.2.3 Part Affinity Fields for Part Association
这个问题主要是解决,哪些 ket points 属于同一个人。一般的思路是取两个key points 的中间点作为连接对象,但是这种情况不适用于 crowd people的情况,造成这样的原因是:
- midpoints仅仅收集了position,并没有收集orientation信息
- 拿一条手臂来说,整个手臂被抽象成了一个点,那么这块region的区域携带的信息就被浪费掉了
所以作者用 part affinity fields 来保存 position and orientation信息,也就是 how to calculate the
L
c
∗
\bold{L}^*_c
Lc∗ ,如下图:

假设
x
j
1
,
k
\bold{x}_{j1,k}
xj1,k,
x
j
2
,
k
\bold{x}_{j2,k}
xj2,k分别代表第
k
k
k个person 的 手臂
c
c
c中的两个点(
j
1
,
j
2
j_1, j_2
j1,j2),那么,如果点
P
P
P在手臂上,那么
L
c
,
k
∗
(
p
)
\bold{L}^*_{c,k}(\bold{p})
Lc,k∗(p) is
j
1
j_1
j1到
j
2
j_2
j2的unit vector,对于其他点来说,这个vector就是0. 下面是
L
c
,
k
∗
(
p
)
\bold{L}^*_{c,k}(\bold{p})
Lc,k∗(p) 的表达式:
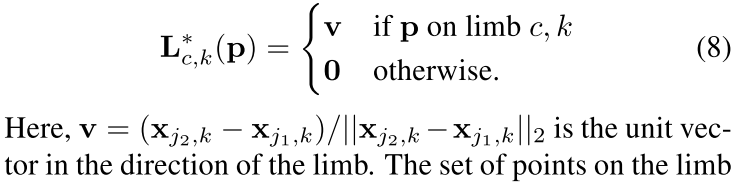
根据向量分解的关系,可以给点
p
\bold{p}
p施加一些限制:

那么,两个key point中间的所有part affinity field 可以表示为:
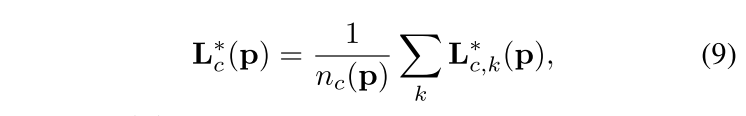
其中,
n
c
(
p
)
n_c(\bold{p})
nc(p)是这幅图中
k
k
k个人的手臂在
p
p
p 点所有不为0向量的均值(人话:通过平均
p
p
p点的向量,就可以表示这两个关键点的连接方式,就好比在正常状态下:不管在什么场景中,人的手腕和elbow之间的向量是都是固定的,所以这个玩意要是遇到一个骨折的,绝逼识别失败。)
为了证明PAF这个玩意是有效地,作者计算了候选点之间的 line integral(人话:作者计算了预选肢体的PAF的中点,alignment of the predicted PAF with the candidate limb that would be formed by connecting the detected body parts)
特别的,计算了两个候选部分的locations d j 1 \bold{d}_{j1} dj1, d j 2 \bold{d}_{j2} dj2,作者对这两个关键点连接部分进行采样,
其中:
- d j 2 − d j 1 ∣ ∣ d j 2 − d j 1 ∣ ∣ \frac{\bold{d}_{j2}-\bold{d}_{j1}}{||\bold{d}_{j2}-\bold{d}_{j1}||} ∣∣dj2−dj1∣∣dj2−dj1求得了两个点之间的单位向量
- p ( u ) = ( 1 − u ) d j 1 + u d j 2 \bold{p}(u)=(1-u)\bold{d}_{j1}+u\bold{d}_{j2} p(u)=(1−u)dj1+udj2 则是表明采样点是 d j 1 \bold{d}_{j1} dj1和 d j 2 \bold{d}_{j2} dj2之间的任意一个点
- 这俩货相乘,在信号处理领域,则是衡量二者的相似性

4.2.4. Multi-Person Parsing using PAFs
由于finding the optimal pares是一个NP难问题,因此,作者用了greedy relaxation来寻找高质量的matches。作者推测:能用这个方法的原因是,pair-wise association scores是需要考虑全局信息的,(因为这个玩意是PAF network从大的感知野中的出来的)
第一步,先从多人中检测出候选key point D J = d j m D_J={\bold{d}^m_j} DJ=djm其中, j ∈ { 1... J } j \in \{1...J\} j∈{1...J}, m ∈ { 1... N j } m \in \{1...N_j\} m∈{1...Nj}, N j N_j Nj候选连接部分 j j j的总数(人话,假设 j j j是头,那么 N j N_j Nj就代表所有可以与这个头相连的key points,可以是自己的nect,也可以是别人的neck), d j m \bold{d}_j^m djm是第 j j j个部分的 m m m个候选点。通俗一点说就是,头部的第m个候选点可以表示为: d 头 m \bold{d}_头^m d头m。下面的任务是,找到这个part的连接点。
定义一个变量
z
j
1
j
2
m
n
∈
{
0
,
1
}
z_{j_1j_2}^{mn}\in \{0, 1\}
zj1j2mn∈{0,1}代表
d
j
1
m
\bold{d}_{j1}^m
dj1m和
d
j
2
n
\bold{d}_{j2}^n
dj2n是否相连,最后的目标是找出所有相连的点,也就是尽量可能的表达出
Z
Z
Z所有连接的可能性。以下图中右屁股和neck,构造了一个图,点就是候选点
D
j
1
D_{j1}
Dj1和
D
j
2
D_{j2}
Dj2以及各种可能连接的边,目标构建二分图,保证没有图中的任意两条边都不共享一个节点,因为共享一个节点的话,就说明有个点连错了,我们的目标是find matching with maximum weight for the 已选择的边


单单公式太抽象了,具体一点,上图中2个人,从左到右分别编号为 a , b a,b a,b, J 1 J1 J1代表橙色点, J 2 J2 J2代表蓝色点, J 3 J3 J3代表绿色点,那么在©图中(也就是作者采用的tree structure)。
对象 a a a橙色的点就可以表示为 j 1 a j_1^a j1a,蓝色的点就可以表示为 j 2 a j_2^a j2a,绿色的点就可以表示为 j 3 a j_3^a j3a;
对象 b b b橙色的点就可以表示为 j 1 b j_1^b j1b,蓝色的点就可以表示为 j 2 b j_2^b j2b,绿色的点就可以表示为 j 3 c j_3^c j3c;
所以:
- D J 1 = { d 3 a , d 3 b } D_{J1}=\{ \bold{d}_3^a, \bold{d}_3^b\} DJ1={d3a,d3b},其中 N j 1 = 2 N_{j1}=2 Nj1=2代表 j 1 j_1 j1的候选点的个数;同样的, D J 3 = { d 1 a , d 1 b , d 2 a , d 2 b } D_{J3}=\{ \bold{d}_1^a, \bold{d}_1^b, \bold{d}_2^a, \bold{d}_2^b\} DJ3={d1a,d1b,d2a,d2b},其中 N j 3 = 4 N_{j3}=4 Nj3=4代表 j 3 j_3 j3的候选点的个数。
- d 1 a \bold{d}_1^a d1a代表第 a a a个人的红色点(肩膀 j 1 j_1 j1)的坐标
- z j 1 j 2 a b = 0 z_{j_1j_2}^{ab}=0 zj1j2ab=0代表: j 1 a j^a_1 j1a与 j 2 b j^b_2 j2b不相连;图中, z j 2 j 3 a a = 1 z_{j_2j_3}^{aa}=1 zj2j3aa=1代表: j 2 a j^a_2 j2a与 j 3 a j^a_3 j3a相连。
然后最后的目标函数是,find a matching with maxium weight for the chosen edges:
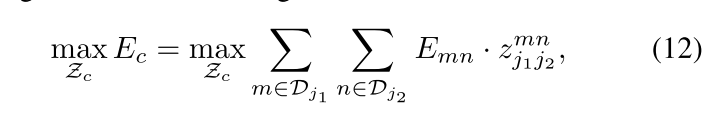
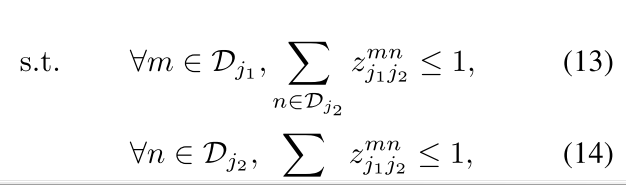
限制条件很好理解,就是所有的pair只能一一对应,就是说
j
1
m
j_1^m
j1m这个节点只能与
j
2
n
j_2^n
j2n中的一个节点匹配,同理对于
j
2
j_2
j2也是一样的
5 Evaluation
6 Conclusion
7 Notes(optional)
8 References(optional)
列出相关性高的文献,以便之后可以继续track下去。
















 2390
2390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









