







 这篇博客介绍了PageRank的串行迭代算法,并探讨了图的边划分和点划分方法,重点在于如何使用PySpark实现PageRank的并行化计算。通过编程实例展示了在分布式环境中并行计算PageRank的有效性。
这篇博客介绍了PageRank的串行迭代算法,并探讨了图的边划分和点划分方法,重点在于如何使用PySpark实现PageRank的并行化计算。通过编程实例展示了在分布式环境中并行计算PageRank的有效性。
🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
1. PageRank的两种串行迭代求解算法
我们在博客《数值分析:幂迭代和PageRank算法(Numpy实现)》算法中提到过用幂法求解PageRank。
给定有向图
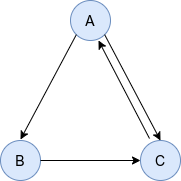
我们可以写出其马尔科夫概率转移矩阵MMM(第iii列对应对iii节点的邻居并沿列归一化)
⎛⎝⎜⎜01212001100⎞⎠⎟⎟(00112001210)\left(\begin{array}{lll}
0 & 0 & 1 \
\frac{1}{2} & 0 & 0 \
\frac{1}{2} & 1 & 0
\end{array}\right)
然后我们定义Google矩阵为
G=qnE+(1−q)MG=qnE+(1−q)MG=\frac{q}{n} E+(1-q) M
此处qqq为上网者从一个页面转移到另一个随机页面的概率(一般为0.15),1−q1−q1-q 为点击当前页面上链接的概率,EEE为元素全1的n×nn×nn\times n 矩阵( nnn 为节点个数)。
而PageRank算法可以视为求解Google矩阵占优特征值(对于随机矩阵而言,即1)对应的特征向量。设初始化Rank向量为 xxx( xixix_i 为页面iii的Rank值),则我们可以采用幂法来求解:
xt+1=Gxtxt+1=Gxtx_{t+1}=G x_{t}
(每轮迭代后要归一化)
现实场景下的图大多是稀疏图,即MMM是稀疏矩阵。幂法中计算 (1−q)Mxt(1−q)Mxt(1-q)Mx_t ,对于节点 iii 需使用reduceByKey()(key为节点编号)操作。计算 qnExtqnExt\frac{q}{n}{E}x_t 则需要对所有节点的Rank进行reduce()操作,操作颇为繁复。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2848
2848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









