







 超级会员免费看
超级会员免费看
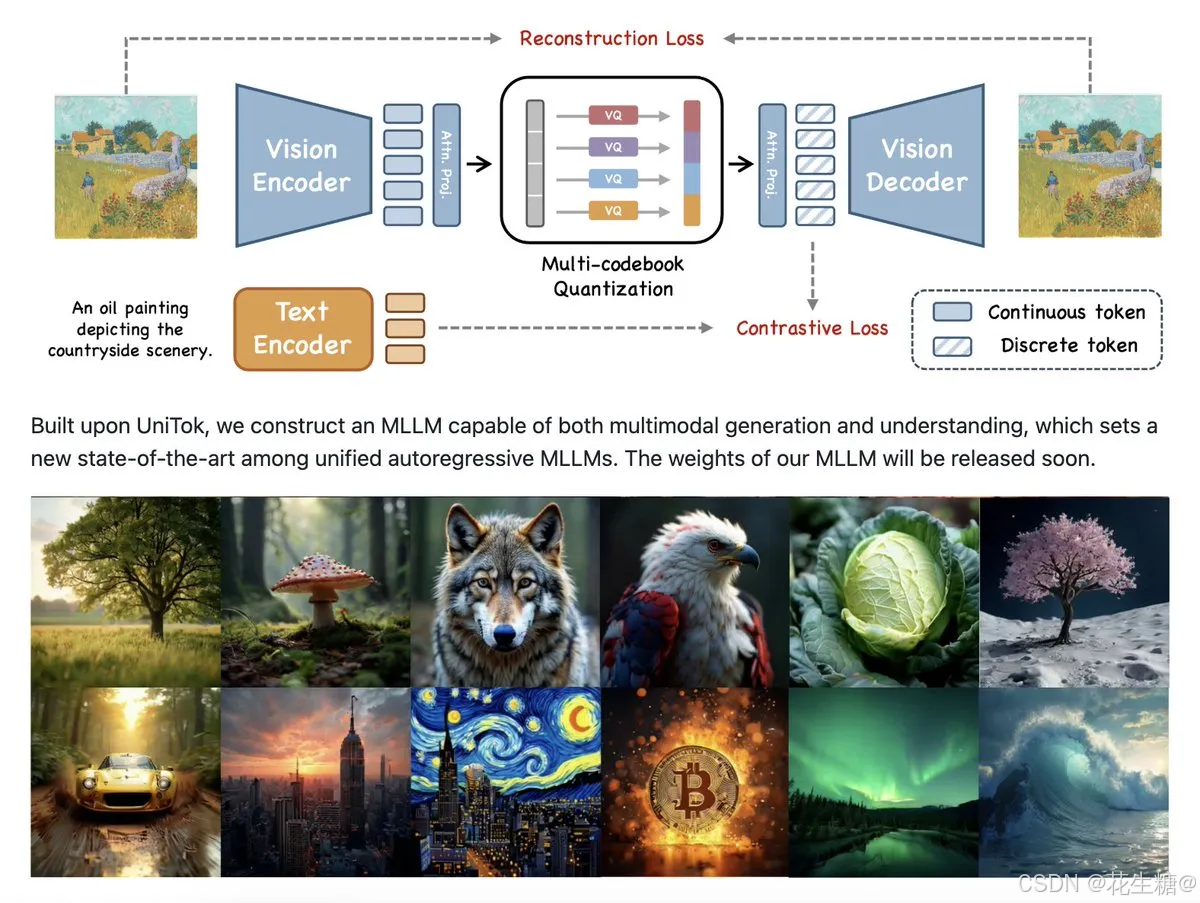 在视觉生成与理解长期割裂的困境下,字节跳动联合港中文团队开源的UniTok,以单模型双任务能力+多码本量化架构,重新定义了视觉分词器的技术边界。这一突破不仅将图文处理效率提升300%,更在ImageNet等基准测试中实现78.6%的零样本准确率,标志着多模态模型进入「生成即理解」的新纪元。
在视觉生成与理解长期割裂的困境下,字节跳动联合港中文团队开源的UniTok,以单模型双任务能力+多码本量化架构,重新定义了视觉分词器的技术边界。这一突破不仅将图文处理效率提升300%,更在ImageNet等基准测试中实现78.6%的零样本准确率,标志着多模态模型进入「生成即理解」的新纪元。
一、 技术困局与范式突破
▎传统方案的三大桎梏
- 任务割裂:生成模型(如Stable Diffusion)需独立训练VAE编码器,理解模型(如CLIP)依赖对比学习,导致双模型资源消耗
- 表征冲突:生成任务需细粒度细节编码,理解任务侧重高层语义提取,传统单码本量化难以兼顾
- 效率瓶颈:VQ-VAE等方案存在码本膨胀问题,超2万个token时训练稳定性骤降
▎UniTok的解法哲学
通过多码本量化+

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











