






1、CAT3D: Create Anything in 3D with Multi-View Diffusion Models
中文标题:CAT3D:使用多视图扩散模型以 3D 形式创建任何内容


简介:3D重建技术的进步使得高质量的3D捕捉成为可能,但创建一个3D场景通常需要用户收集数百到数千张图像。为了简化这一过程,我们提出了CAT3D方法。CAT3D利用多视角扩散模型模拟真实世界的3D捕捉过程,可以创建任何3D物体。
给定任意数量的输入图像和一组目标新视角,我们的模型能够生成高度一致的场景新视角。这些生成的视角可以作为输入,使用强大的3D重建技术来产生3D表示,并实时从任何视角进行渲染。
与现有方法相比,CAT3D在单张图像和少量视角3D场景创建方面表现出色,并且可以在一分钟内创建整个3D场景。感兴趣的读者可以访问我们的项目页面https://cat3d.github.io 查看结果和交互式演示。
2、Toon3D: Seeing Cartoons from a New Perspective
中文标题:Toon3D:从新的角度看卡通
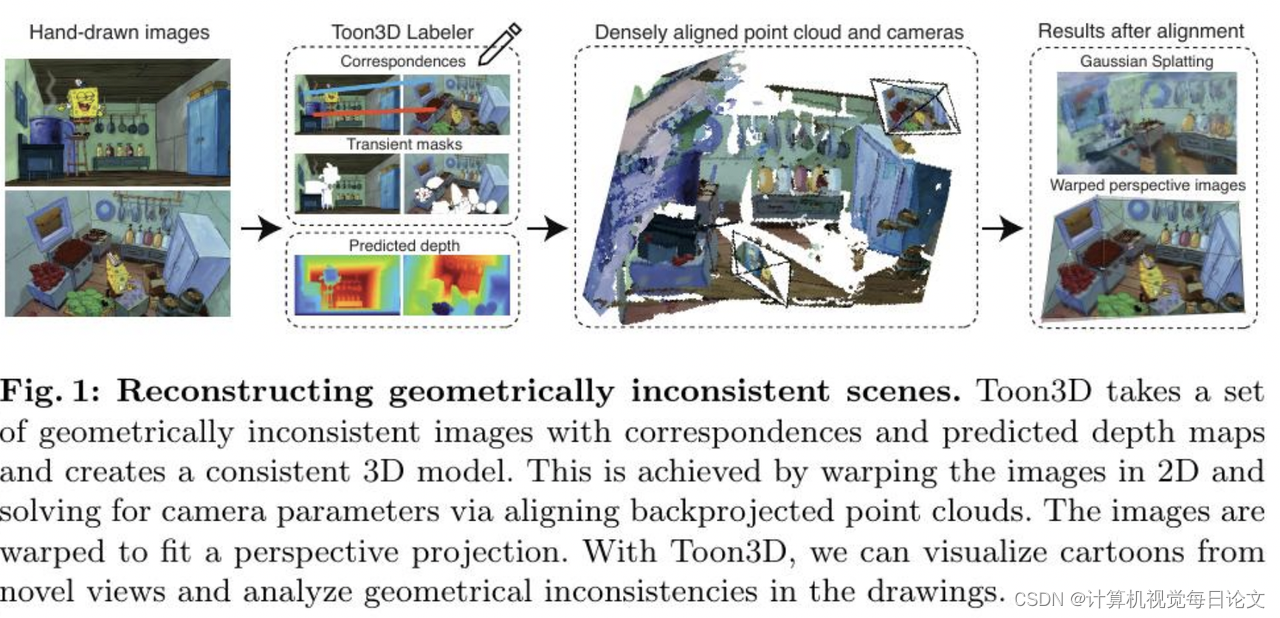

简介:在这项工作中,我们探索了从非几何一致的卡通和动漫手绘图像中恢复潜在的3D结构。这类手绘图像通常由没有3D渲染引擎的艺术家创作,其表现更多体现定性意义上的真实,而不是几何精确性。然而,人类仍能从这些不一致的输入中感知3D场景。
我们的方法旨在纠正2D绘图的不一致性,以恢复合理的3D结构,使新的绘图结果能够彼此协调一致。我们的工作流程包括用户友好的注释工具、相机姿态估计和图像变形,从而恢复密集的3D结构表征。我们将图像变形以遵守透视相机模型,使得校正后的结果可以插入到新视角合成重建方法中,从未绘制过的角度体验卡通世界。感兴趣的读者可以访问我们的项目页面https://toon3d.studio/了解更多信息。
3、Text-to-Vector Generation with Neural Path Representation
中文标题:使用神经路径表示的文本到向量生成

简介:矢量图形因其可缩放性和分层属性而广受设计师青睐,被广泛用于数字艺术创作。然而,创建和编辑矢量图形通常需要较高的创造力和专业设计知识,是一项耗时的任务。
为了简化这一过程,近期出现了基于文本到矢量(T2V)生成的方法。但是,现有的T2V技术直接优化矢量图形路径的控制点,由于缺乏几何约束常会导致路径相交或出现锯齿状。
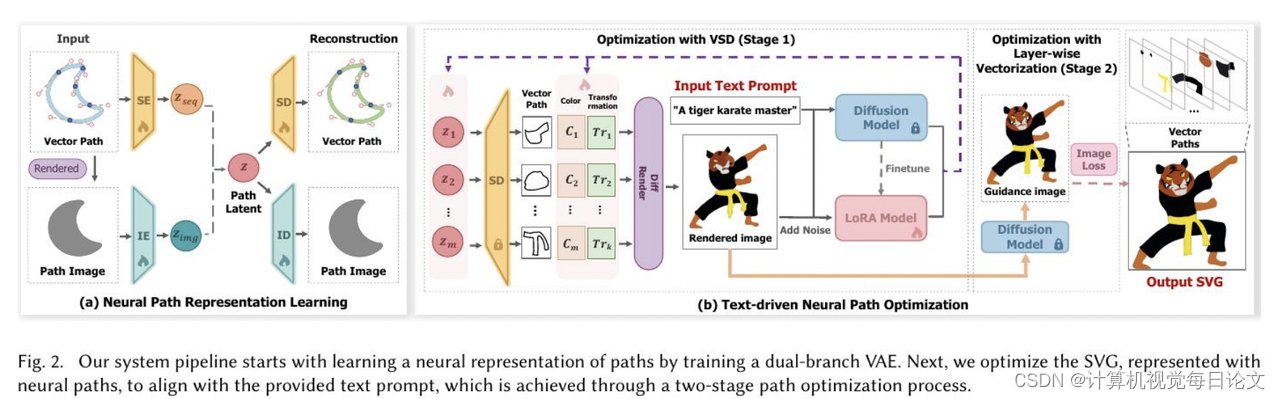
为了克服这些限制,我们提出了一种新颖的神经路径表示方法。通过设计双分支变分自编码器(VAE),我们可以从序列和图像模态中学习路径的潜在空间表示。通过优化神经路径的组合,我们可以在保持生成SVG图形表现力的同时,纳入几何约束。
此外,我们引入了一种两阶段路径优化方法,以进一步改善生成SVG的视觉和拓扑质量。第一阶段使用预训练的文本到图像扩散模型通过变分分数蒸馏(VSD)过程指导复杂矢量图形的初始生成。第二阶段则采用分层图像矢量化策略来优化图形,实现更清晰的元素和结构。
我们通过广泛的实验验证了所提方法的有效性,并展示了在各种应用中的应用潜力。感兴趣的读者可访问项目页面https://intchous.github.io/T2V-NPR了解更多信息。
















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









