






1、Images that Sound: Composing Images and Sounds on a Single Canvas
中文标题:有声音的图像:在单一画布上组合图像和声音


简介:这篇论文展示了声谱图作为声音的二维表示,与我们日常视觉世界中的图像截然不同。当自然图像被播放为声谱图时,会产生非自然的声音效果。作者提出了一种方法,可以生成同时看起来像自然图像又能播放出自然声音的声谱图,称之为"图像声音"。
该方法简单而零样本,利用预训练的文本到图像和文本到声谱图的扩散模型,它们在共享的潜在空间中进行操作。在反向过程中,作者同时使用图像和音频扩散模型对潜在空间进行去噪,从而得到在两个模型下都可能的样本。
通过定量评估和感知研究,作者发现该方法成功生成了与给定音频提示相符,同时又具有给定图像外观的声谱图。请访问项目页面https://ificl.github.io/images-that-sound/查看生成的视频结果。
2、Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
中文标题:多视图立体的快速广义高斯泼溅重建
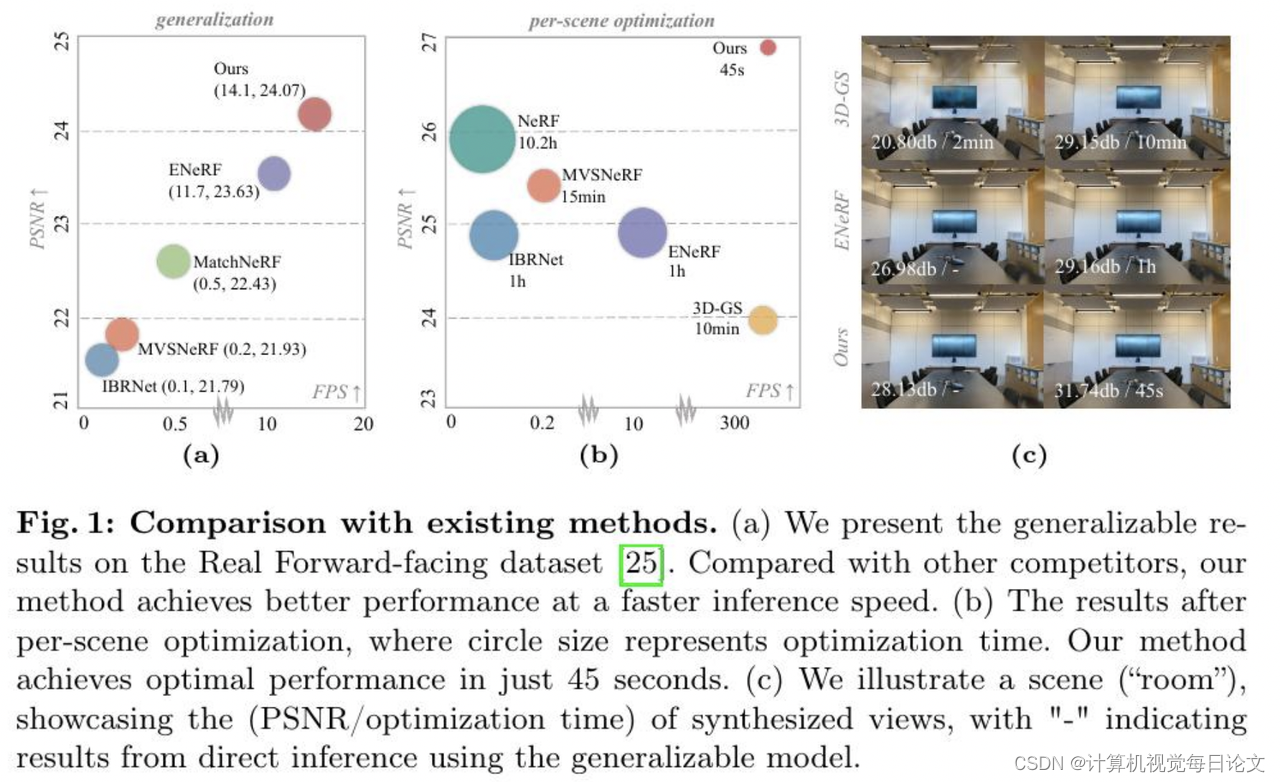
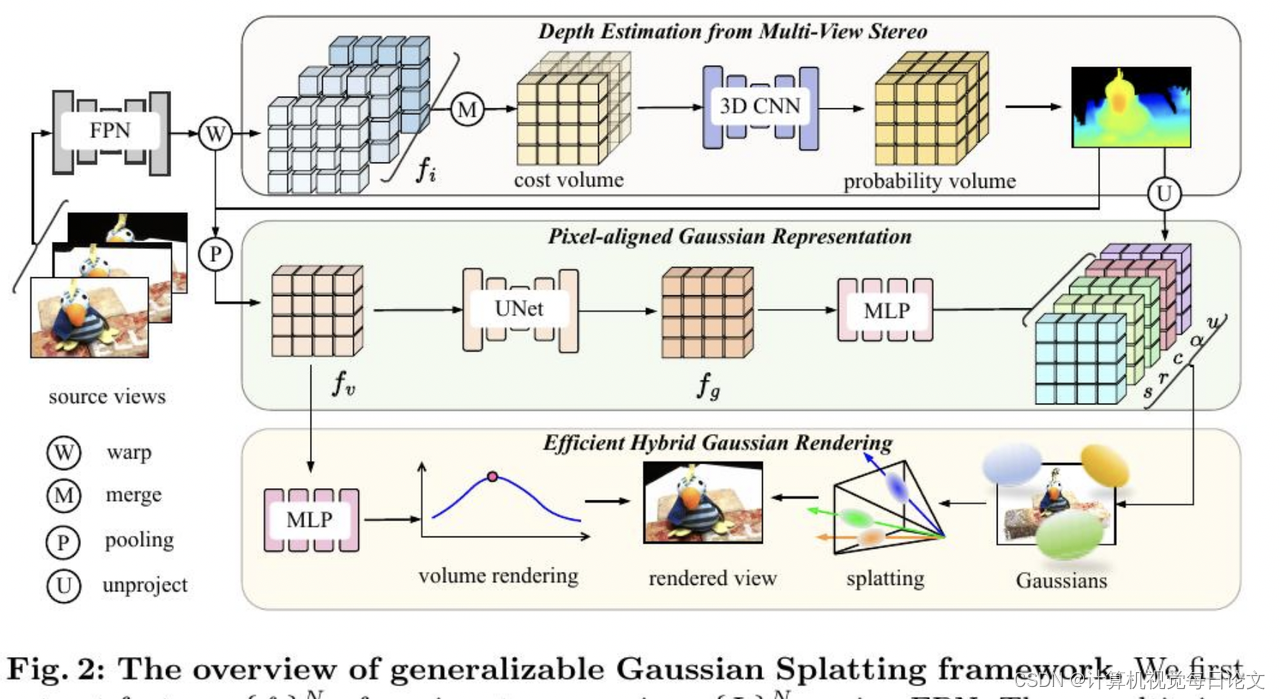
简介:我们提出了一种新的可推广的三维高斯表示方法MVSGaussian,源自多视角立体成像(MVS)技术。这种方法可以高效地重建未见过的场景:
1) 我们利用MVS对几何感知的高斯表示进行编码,并将其解码为高斯参数。
2) 为进一步提高性能,我们提出了一种混合高斯渲染方法,将有效的体积渲染设计与新视角合成相结合。
3) 为支持快速的场景特定微调,我们引入了一种多视角几何一致性聚合策略,有效地聚合通用模型生成的点云作为每个场景优化的初始化。
与以前的通用NeRF方法相比,MVSGaussian实现了实时渲染,每个场景的合成质量更好,通常只需要几分钟的微调和每个图像几秒钟的渲染时间。
与基本的3D-GS相比,MVSGaussian具有更少的训练计算成本,实现了更好的视角合成。
大量实验表明,MVSGaussian在DTU、Real Forward-facing、NeRF Synthetic和Tanks and Temples数据集上都展现出令人信服的通用性、实时渲染速度和快速的每个场景优化,达到了最先进的性能水平。
3、Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
中文标题:Slicedit:使用时空切片的文本到图像扩散模型的零镜头视频编辑


简介:本文要点是:
1. 文本到图像(T2I)扩散模型在图像合成和编辑方面取得了最先进的结果,但是将这些预训练模型用于视频编辑被认为是一个重大挑战。
2. 许多现有方法尝试通过显式的对应机制在像素空间或深度特征之间强制实现编辑视频的时间一致性,但是这些方法在处理强非刚性运动时存在困难。
3. 本文提出了一种根本不同的方法,该方法基于观察到自然视频的时空切片具有类似于自然图像的特征。因此,通常仅用作视频帧先验的相同T2I扩散模型也可以作为增强时空一致性的强先验,通过在时空切片上应用它。
4. 基于这一观察,作者提出了一种名为Slicedit的文本视频编辑方法,利用预训练的T2I扩散模型来处理空间和时空切片。该方法生成的视频保留了原始视频的结构和运动,同时遵循目标文本。
5. 通过大量实验,作者证明了Slicedit编辑各种真实世界视频的能力,并证实了它与现有竞争方法相比的明显优势。
















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









