







Unsloth是一个开源的大模型训练加速项目,使用OpenAI的Triton对模型的计算过程进行重写,大幅提升模型的训练速度,降低训练中的显存占用。Unsloth能够保证重写后的模型计算的一致性,实现中不存在近似计算,模型训练的精度损失为零。Unsloth支持绝大多数主流的GPU设备,包括V100, T4, Titan V, RTX 20, 30, 40x, A100, H100, L40等,支持对LoRA和QLoRA的训练加速和高效显存管理,支持Flash Attention。
- Unsloth Github项目:https://github.com/unslothai/unsloth

在线使用
Unsloth支持主流的Llama、Mistral、Gemma等大模型,且对上述模型的微调性能级内存占用有显著提升,如下图所示:
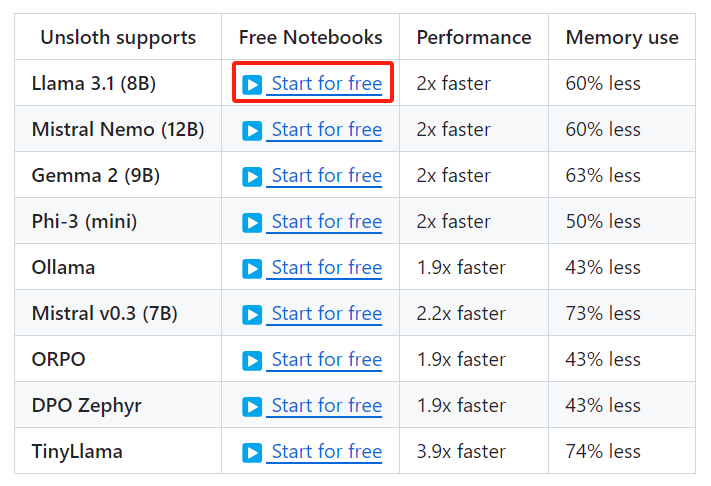
通过点击“Start for free”按钮,可以启动Google的colab笔记本,这里Google为新账号免费提供几个小时的云端GPU服务器资源(Tesla T4)供大家使用。在colab笔记本训练得到的微调模型可以导出为GGUF格式,并上传至Hugging Face网站上。
以Llama 3.1(8B)为例,Google的colab网址为:https://colab.research.google.com/drive/1Ys44kVvmeZtnICzWz0xgpRnrIOjZAuxp?usp=sharing
colab中给出了在线运行的代码,我们配置好基础环境后只需按序执行代码即可。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit", # Llama-3.1 15 trillion tokens model 2x faster!
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"unsloth/Meta-Llama-3.1-405B-bnb-4bit", # We also uploaded 4bit for 405b!
"unsloth/Mistral-Nemo-Base-2407-bnb-4bit", # New Mistral 12b 2x faster!
"unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"unsloth/mistral-7b-v0.3-bnb-4bit", # Mistral v3 2x faster!
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/Phi-3-mini-4k-instruct", # Phi-3 2x faster!d
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/gemma-2-9b-bnb-4bit",
"unsloth/gemma-2-27b-bnb-4bit", # Gemma 2x faster!
] # More models at https://huggingface.co/unsloth
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
输出如下:

模型加载起来很丝滑,内存占用也比较低
trainer_stats = trainer.train()

整个训练过程只需要7分钟,显存最大占用量约为8G,性能确实很赞了。
关于Unsloth微调Llama-3的代码详解,可参考博客:【大模型】基于Unsloth微调Llama-3.1 8b代码详解
本地安装
Unsloth的安装可以参考项目官网:https://github.com/unslothai/unsloth
安装方式主要分为两种:
- Conda安装:
- 对于 CUDA 11.8:安装pytorch-cuda=11.8
- 对于 CUDA 12.1:安装pytorch-cuda=12.1
- pip安装:注意,如果环境中有Conda的话,不要使用pip安装的方式!
Unsloth的基础环境安装起来比较麻烦,对于python和cuda的版本都有要求,这里详细的安装建议参考博客:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









