







 本文详细解读了BLIP2模型,涵盖了模型结构、预训练与微调策略、数据处理和实验结果。重点讨论了模型在计算机视觉任务中的应用,包括图像描述、VQA和图文检索。
本文详细解读了BLIP2模型,涵盖了模型结构、预训练与微调策略、数据处理和实验结果。重点讨论了模型在计算机视觉任务中的应用,包括图像描述、VQA和图文检索。
一、概述
1、是什么
BLIP2 全称《BLIP-2: Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models
》,
是一个多模态视觉-文本大语言模型,隶属BLIP系列第二篇,可以完成:图像描述、视觉问答、名画名人等识别(问答、描述)。支持单幅图片输入(作为第一个输入),多轮文本对话。(不支持图文交错输入、写代码、视觉定位、JSON mode等。)
2、亮点
主要来解决图文多模态端到端重新预训练方式遇到的两个问题:
1)训练成本高:多模态模型需要大量数据,加上模型结构复杂,因此导致端到端重新预训练的成本比较高;
2)模型灾难性遗忘,LLM大模型在finetune时,可能会产生遗忘现象,因此如果直接将单模态的预训练模型加入到多模态模型中进行联合训练,可能会产生灾难性遗忘问题;
解决方案:
*采用已经训练好的单模态模型,从而避免train-from-scratch,减少训练成本;
*将单模态模型的参数进行冻结,从而避免灾难性遗忘问题,充分利用已经训练好的单模态模型;
*利用Q-Former来对图文进行对齐,从而让图像和文本产生交互,对齐冻结的图像encoder 和LLM model。
PS
*这篇论文的整体结构还是很紧凑,有条件可以阅读原文,英文不好的,可以先看本文处理好脉络再对照看原文二次摸清细节。
*这篇文章强烈建议先看看BLIP再来看,然后就是一定要先有个架构,再去看不然容易懵。两阶段预训练(一阶段3个损失函数、二阶段LLM建模损失),3个任务上fine tune、和zero-shot评估。
*这里作者解决灾难遗忘的方式略微有点粗暴,不过由于视觉token只有32个,LLM一般的支持长度还是远大于32,所以靠LLM泛化性+二阶段微调Q-former适应LLM也确实算不错的思路。其余思路比如LLM单独一个拷贝QKV来作为视觉专家模块(cogVLM),直接微调的时候增加特选的纯语言数据(千问VL)
*评测时,分zero shot 和finetune,这里的fine tune我有点不理解:是为了和其他论文对比吗,coco数据集已经出现在预训练里了,还要单独再只用coco finetune 然后评测,然后coco闭集上性能变好了,对比的zeroshot 开集却没有提供数据来比较是否掉点,所以说明预训练不够?模型参数量不够?
二、模型
1、模型结构
这里稍微有点绕,因为这个模型是两阶段预训练+ 测试时分为zero-shot 、finetune(其中有一个任务的finetune 还改变了q-former的输入),LLM又有两种结构,所以作者特意画了4个图。
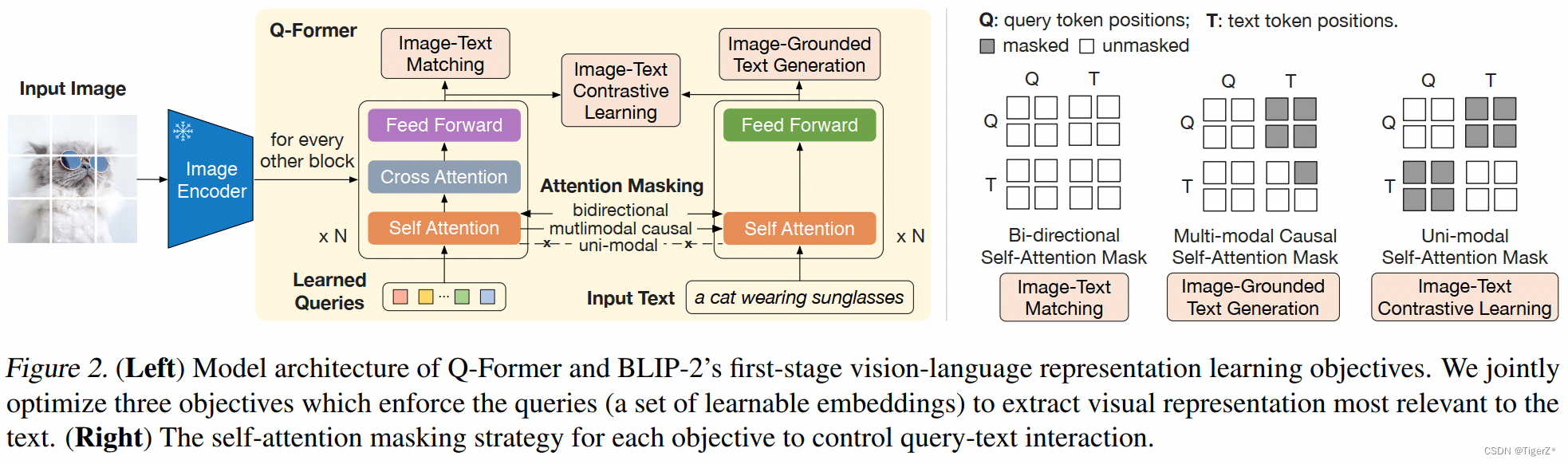
第一个图是模型的整体图,包含三部分:Image encoder,Q-former、LLM,具体来讲:
*Image encoder: ViT-L/14 from CLIP 、 ViT-g/14 from EVA-CLIP 均移除最后一层,使用倒数第二层。
*LLM:尝试两种大的类型(decoder only、encoder-decoder):unsupervised-trained OPT、 instruction-trained FlanT5 model family,具体来说有pretrain_opt2.7b, caption_coco_opt2.7b, pretrain_opt6.7b, caption_coco_opt6.7b,pretrain_flant5xl, caption_coco_flant5xl, pretrain_flant5xxl。
*Q-former:是一个轻量级 Transformer,它使用一组(最终选择32个)可学习的 Query 向量(最终选择768维的变量)从冻结的视觉编码器中提取视觉特征,并充当视觉编码器和文本编码器之间的桥梁,把关键的视觉信息传递给 LLM。使用BERT-base 参数初始化,cross-attention层为随机初始化,整体而言为188M参数(包含32个可学习queries, 每个维度768)。
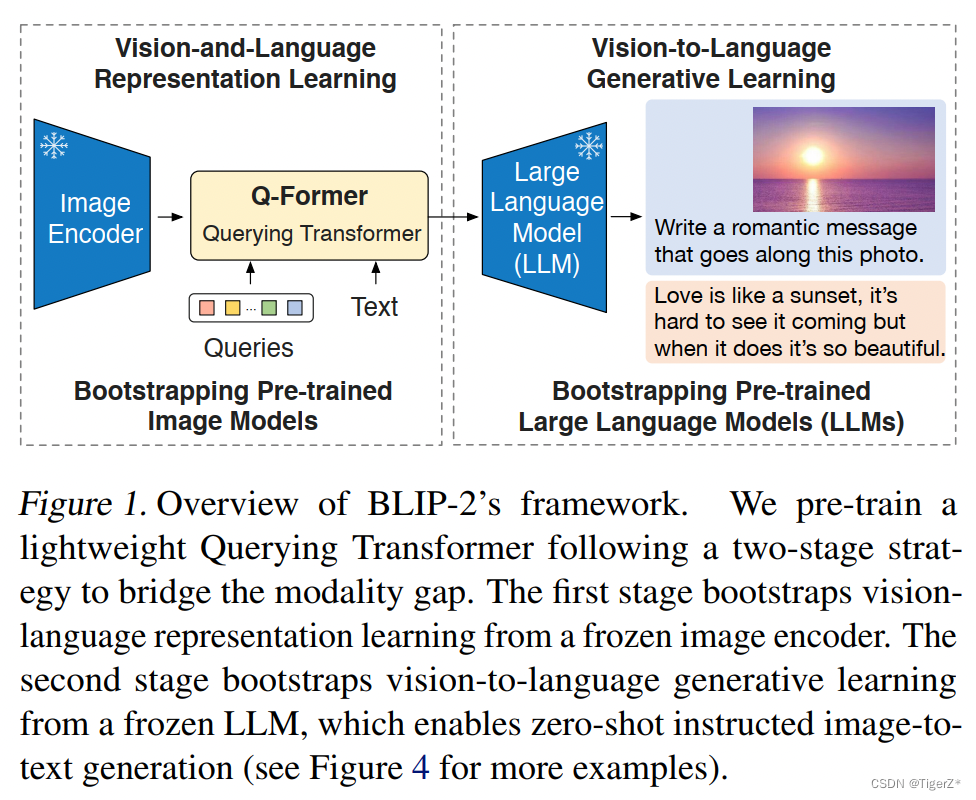
第二个图,就是针对两种不同LLM(decoder only、encoder-decoder)的细化图,也对应后面细讲的第二阶段的训练。
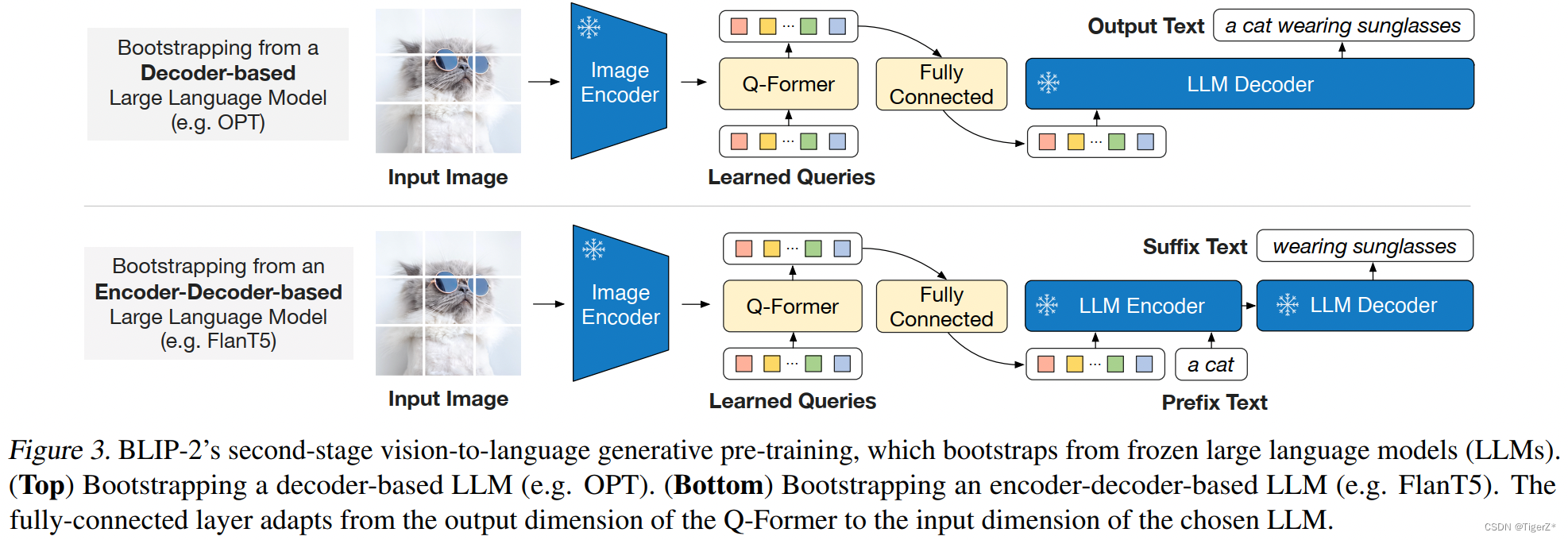
第三个图,就是将q-former 展开细讲,对应后面细讲的第一阶段的训练,注意最终推理(做文本生成)的时候只用到图二,图三的三个分支仅仅一阶段训练时候存在。Q-Former 架构是由2个 Transformer 子模块构成,其中注意 Self-Attention 是共享的(图中同颜色的部分参数共享),可以理解为 Self-Attention 的输入有2个,即:Queries 和 Text。
第1个 Transformer 子模块: 是 Image Transformer,它与图像编码器交互,用于视觉特征提取。它的输入是可学习的 Queries,它们先通过 Self-Attention 建模互相之间的依赖关系,再通过 Cross-Attention 建模 Queries 和图片特征的依赖关系。因为两个 Transformer 的子模块是共享参数的,所以 Queries 也可以与文本输入做交互。
第2个 Transformer 子模块: 是 Text Transformer,它既可以作为文本编码器,也可以充当文本解码器。
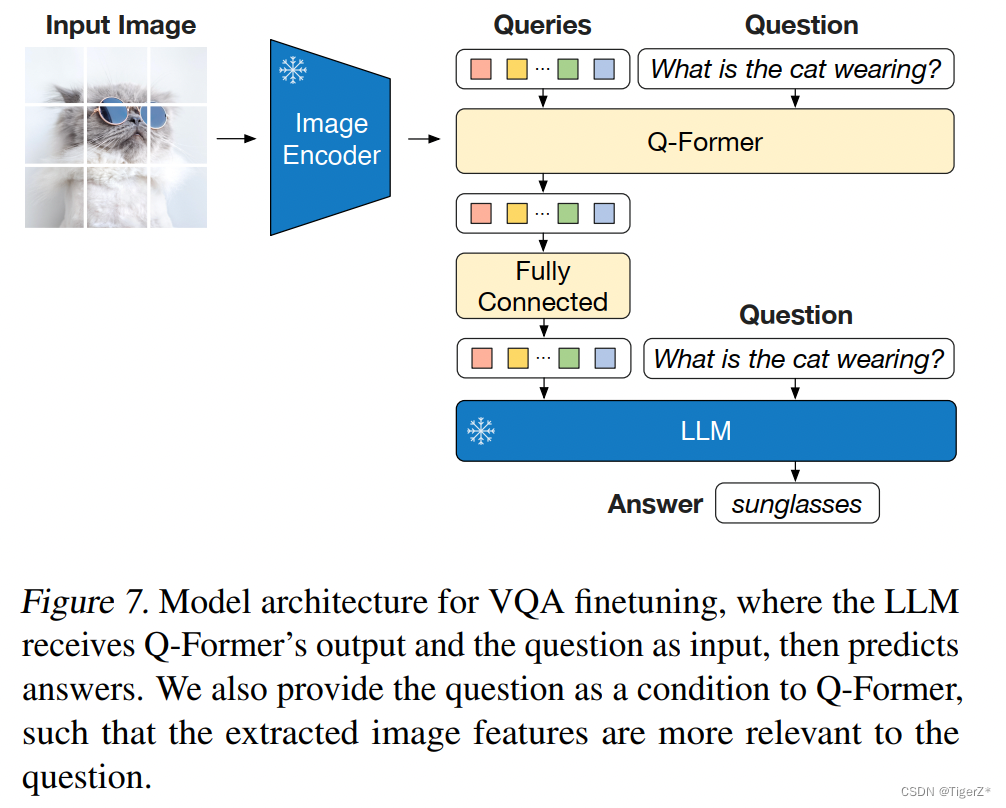
第四幅图片,这个是finetune 阶段(并且只针对VAQ任务),这个就已经有了后面的Instruct BLIP的影子。然后作者一共做了3个下游任务的finetune,下图对应视觉VQA任务。
2、模型亮点
巧妙的引用一个q-former 来连接冻结的Image encoder和LLM,降低训练难度和遗忘问题。
PS
这里一定要知道两阶段训练——都是预训练,外加为了下游测试的finetune。
三、数据
1、数据标签
Pretrain
两个阶段的pre-train本质都是用图文对,具体使用方法训练章节讲述,具体生成时候的prompt文章并没有提及。
zero-shot 评估
图像描述任务:promt 为 “a photo of”
VQA 任务:对于OPT模型,使用"Question: {} Answer:"。对于FlanT5模型,使用"Question: {} Short answer:"。在生成过程中,使用宽度为5的beam search。长度惩罚设置为-1,以鼓励更短的答案,更符合人类注释。
图文检索:prompt 为 对应的问题,比如“what is the cat wearing?”
fine tune 评估
类似zero-shot 吧,作者都是在zero-shot里讲,这里没有讲。
2、数据构成
Pretrain
构成和BLIP一样,具体的清洗等可以见BLIP论文,使用下面6个数据集,图片数加起来大概是 129M:
*COCO
*Visual Genome
*CC3M
*CC12M
*SBU Captions
*
LAION400M 中选取 115M 图像
zero-shot 评估
图像描述任务:NoCaps (val)
VQA任务:VQAv2 (val、test-dev)、OK-VQA(test)、 GQA(test-dev)
图文检索任务:Flickr (test)
fine tune 评估
图像描述任务:训练使用coco;测试使用coco(test)、NoCaps(又作为zero-shot使用)
VQA任务:训练VQAv2;测试VQAv2 (val、test-dev)
图文检索任务:训练使用coco;测试使用coco(test )、 Flickr 30K (test)(又作为zero-shot使用)
PS
*不知道是我的问题,还是作者不关系这个点,还是。。,为什么既然fine tune都有zero shot了,干脆直接对比一下不fine tune的zero shot 的掉点情况。
*VQA-v2: 是一个人工标注的、关于图像的开放式问答数据集。回答这些问题,需要对图像、语言以及常识都具备一定的理解力。2017 年 4 月发布包含265,016 张图像(源自 COCO 以及 abstract scenes 数据集),
每幅图像涉及到的问题数量大于等于 3(平均 5.4 个问题),
每个问题包含 10 个基准真相 (ground truth),
每个问题包含 3 个合理(但不一定正确)的答案。
*coco:33 万张图片提供超过 150 万条描述(对于训练集和验证集中的每张图像,都人为标注了 5 段描述)。
3、数据清洗
参考BLIP相关部分,论文中作者专门提到对于互联网图片的清洗策略(采用CapFilt方法),具体来说:使用BLIPlarge 图片描述模型对每幅图片生成了10个描述,并根据CLIP vitl /14模型产生的图像-文本相似性将生成描述与原始描述进行排序,选择前两个描述作为训练数据,并在每个预训练步骤随机抽取一个(随机抽取也算训练策略一部分吧,不强区分了)。
四、策略
1、训练过程
Pre-train
提出了一个轻量级的 Q-former,分两个阶段进行预训练。第一阶段从冻结的视觉编码器中引导多模态学习,第二阶段从冻结的视觉编码器+文本编码器中引导多模态学习,这里面第一阶段训练有三个loss。第二阶段就是标准的LLM语言建模损失。
Pre-train 超参数
整提预训练:冻结的vit和LLMs参数转换为FP16(FlanT5使用BFloat16)。使用一台16-A100(40G)的机器,与使用32位模型相比,没有发现性能下降。 所有模型都使用相同的预训练超参数集。使用AdamW 优化器,其中β1 = 0:9, β1 = 0:98,权重衰减为0.05。使用余弦学习率衰减,峰值学习率为1e-4,线性warm up为2k Step。第二阶段的最低学习率为5e-5。使用大小为224×224的图像,增强了随机调整大小的裁剪和水平翻转。
一阶段预训练250k step,使用2320/1680 batch size 训练 viti - l / viti -g。最大的型号使用viti -g和FlanT5-XXL,第一阶段需要不到6天。
二阶段预训练80k Step。使用1920/1520 batch size 训练 OPT/FlanT5。最大的型号使用viti -g和FlanT5-XXL第二阶段需要不到3天。
Pre-train stage 1
这里要结合上面模型结构的第三张图(图片底下注释为figure2)。这个阶段的训练确实算难点,整体把握住两点:
*这个阶段只有视觉编码器和Q-former(包含可学习Queries),没有LLM。然后冻结视觉编码器,只训练Q-former(包含可学习Queries)。
*训练的目标函数,遵循 BLIP 的做法,联合优化3个具有相同输入格式和模型参数的预训练目标(3个loss),每个目标函数使用不同的 mask Attention 来控制注意力的交互,对应其实推理了三大次(其中图片描述的损失就是类比标准LLM语言建模根据文本长度N推理N次)。
接下来具体来讲这三个损失函数(ITC、ITM、ITG)对应的训练方法。
图文对比学习 (Image-Text Contrastive Learning, ITC)
这是多模态预训练中的经典目标函数,旨在对齐图像和文本的表征,使其互信息最大化。
ITC 实现的方式是:让正样本 (配对的图片文本对) 的相似度尽量高,同时让负样本 (不配对的图片文本对) 的相似度尽量低。那么对于 Q-Former 作者实现 ITC 的方法是计算 Queries 的输出 Z 和 Text Transformer 的 [CLS] token 输出 tt的对比学习损失。因为 Z 包含了多个 Queries 的输出,因此作者首先计算每个 Queries 的输出和 tt之间的成对相似度,然后选择最高的一个作为最终的图文相似度。ITC 的 Attention Mask 方法 模型结构章节figure2的最右侧所示,属于 Uni-modal Self-Attention Mask,不允许 Queries 和 Text 相互看到 (相互之间的注意力值为0)。
图文匹配任务 (Image-Text Matching, ITM)
这是多模态预训练中的经典目标函数,旨在更加细粒度地对齐图像和文本的表征,使其互信息最大化。ITM 是个二分类任务,要求模型预测图像-文本对是正样本 (匹配) 还是负样本 (不匹配)。ITM 的 Attention Mask 方法如
模型结构章节figure2
的最左侧所示,属于 Bi-directional Self-Attention Mask,允许 Queries 和 Text 相互看到。
Queries 的输出 Z捕获了多模态信息,把每个输出的 Queries Embedding 通过一个二类线性分类器中以获得 logit,并将 logit 的输出做平均作为最终的分数。
BLIP-2 的 ITM 目标函数同样使用了 ALBEF 中的 hard negative mining 策略。
基于图像的文本生成 (Image-Grounded Text Generation, ITG)
ITG 给定一张输入图片,旨在训练 Q-Former 生成对应的文本描述。
要实现这一目的,视觉编码器和文本解码器之间应该有交互。而 Q-Former 恰恰阻止了这种直接交互,因此 Queries 在这里就扮演了提取出来生成文本所需要的信息,然后通过 Self-Attention 层传递给 Text token。简而言之,Queries 应该具备这样一种能力:提取捕获了所有文本信息的视觉特征。因此,ITG 的 Attention Mask 方法 如
模型结构章节figure2
中间所示,属于 Multi-modal Causal Self-Attention Mask,允许 Text 看到 Queries (Queries 里面有视觉信息),同时每个 Text token 只能看到它之前的 Text token (生成式任务的基本做法)。但是不允许 Queries 看到 Text 的信息,只能看到自己的信息。此外作者还将 [CLS] token 替换为一个新的 [DEC] token 作为第一个 Text token 来指示解码任务。
Pre-train Stage2
在生成预训练的阶段,作者把 Q-Former 和冻结参数的 LLM 连接起来,以利用 LLM 的文本生成能力。首先输入图片还是直接输入冻结参数的 Image Encoder,得到图像的表征。然后图像的表征和 Queries 一起送入 Q-Former,得到 Queries 的输出 Z,经过一个全连接层与 Text token 的维度对齐之后输入给 LLM Decoder。这个 Queries 的输出就蕴含了视觉信息,在输入给 LLM 的时候就充当了 Soft Visual Prompt 的作用。
Queries 在经过了第1阶段的训练之后,已经学习到了如何更好地结合文本提取图片信息,因此它可以有效地将最有用的图片信息提供给 LLM,同时删除不相关的视觉信息。这减少了 LLM 学习视觉语言对齐的负担。
作者尝试了2种大型语言模型,分别是基于纯 Decoder 架构的和基于 Encoder-Decoder 架构的。对于基于纯 Decoder 架构的模型,使用语言建模目标函数进行训练。冻结参数的 LLM 的任务是根据 Q-Former 提供的视觉表征来生成文本。对于基于 Encoder-Decoder 架构的模型,把文本分成两段,前缀随着 Queries 的输出喂给 LLM 的 Encoder,希望 Decoder 输出后缀。
Finetune
在三个任务上进行了finetune,分别是:图片描述、视觉问答、图文检索,训练数据集基本就是coco和VQA-2,都是30W左右体量,训练5个epoch,见到百万级的总图片量。整体的batch size 都比较小,感觉一定程度是考虑到ITM损失函数,结合coco整体80分类的较为集中的场景。
Finetune 图像描述
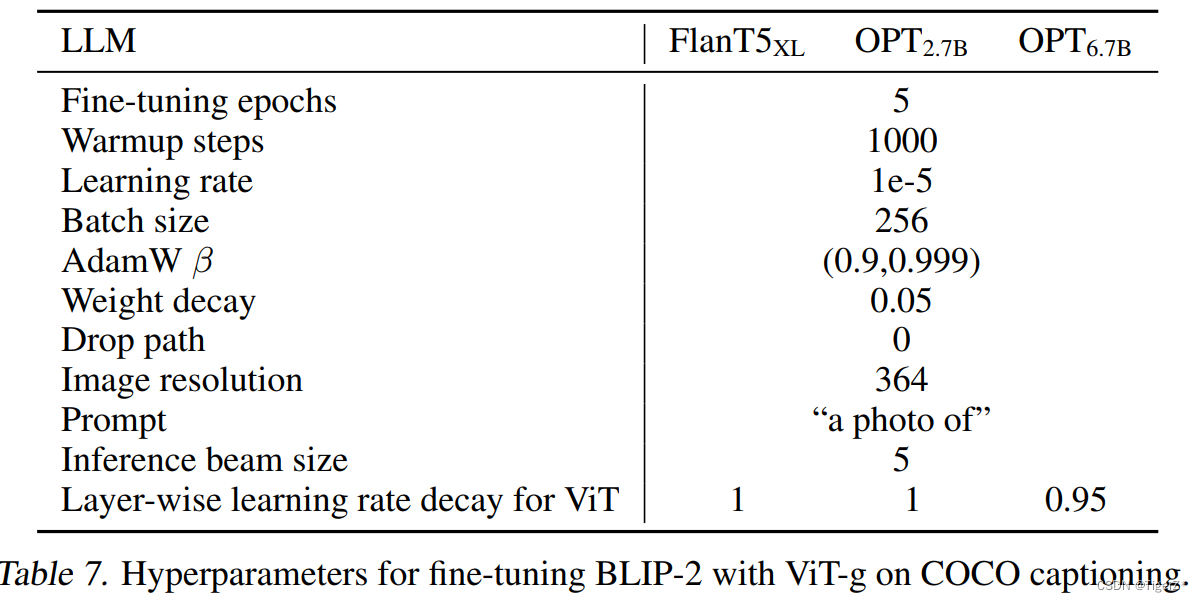
使用提示 "a photo of" 作为 LLM 的初始输入,并使用语言建模损失函数来训练模型生成字幕。作者在微调期间保持 LLM 冻结,并将 Q-Former 的参数与图像编码器一起更新。微调数据集使用 COCO,同时在 COCO 测试集和 NoCaps 验证集上评测。具体超参数如下
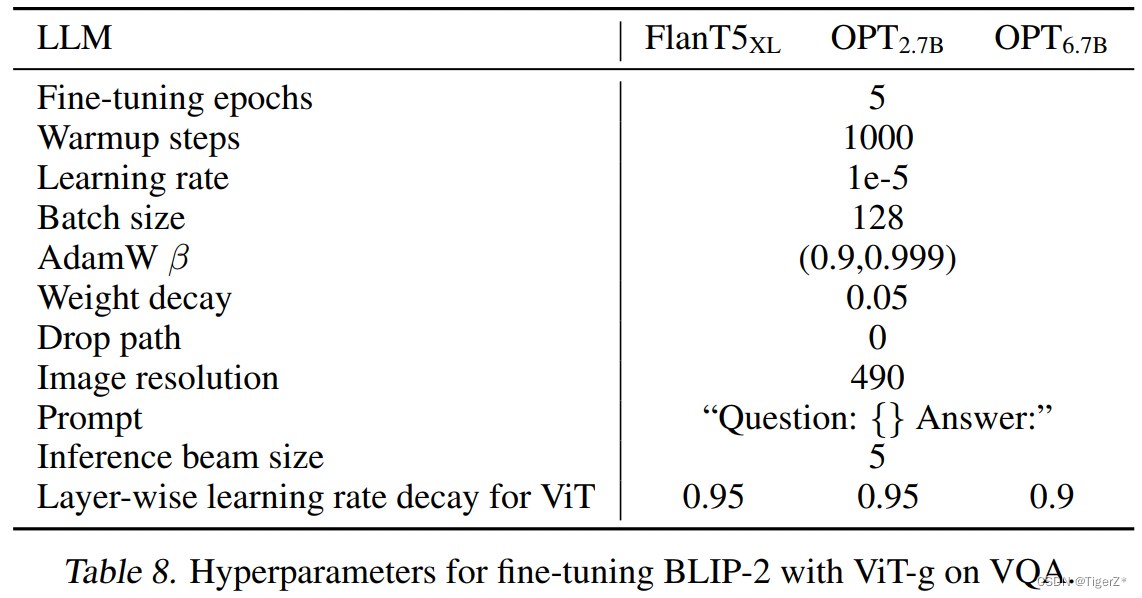
Finetune VQA
VQA-V2 数据,在保持 LLM 冻结的同时微调 Q-Former 和图像编码器的参数。VQA 微调的模型架构如图11所示,LLM 接收 Q-Former 的输出和问题作为输入,并希望生成答案。为了提取与问题更相关的图像特征,作者还给 Q-Former 额外输入问题,使其借助 Self-Attention 与可学习的 Queries 交互。结构如模型结构部分的图四。并使用语言建模损失函数来训练模型。
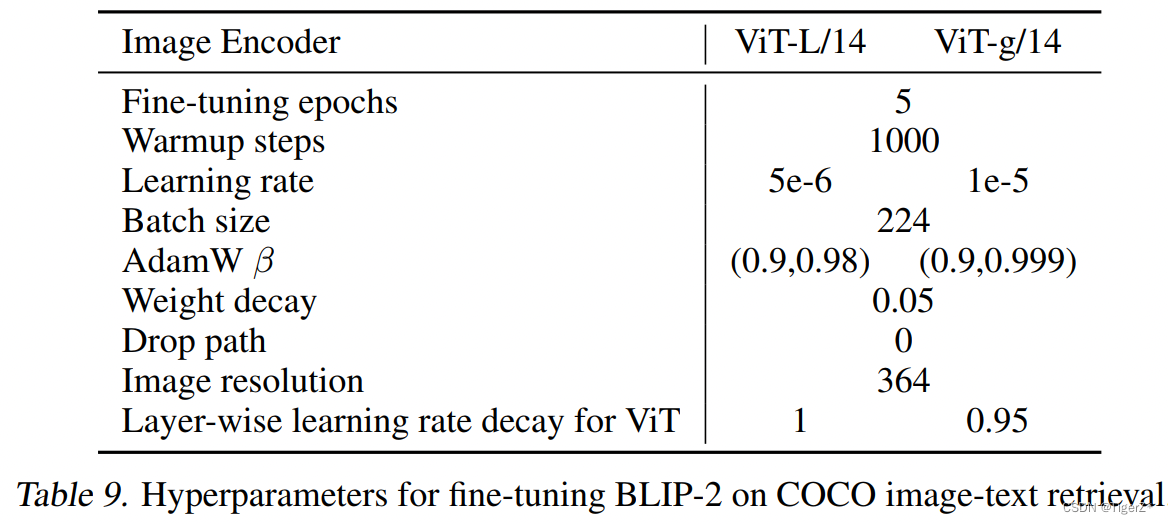
Finetune 图文检索
因为图文检索不涉及语言生成,所以直接微调第1阶段预训练模型。使用与预训练相同的目标函数,即 ITC、ITM 和 ITG,微调 Q-Former 和图像编码器。微调数据集使用 COCO,评测数据使用 COCO 和 Flickr30K,任务是 image-to-text retrieval 和 text-to-image retrieval。
2、推理过程
分为常规需要LLM的比如图片描述、VQA,不需要LLM的图文检索、抽图像特征。
参见官方git即可。
五、结果
1、多维度对比。
这里主要分为
定性:一个可视化。
定量:两大类zero-shot、finetune, 每个子类都有三个子任务:图片描述、VQA、图文检索。
可惜的地方是无法看到特定测试集finetune 后其他测试集的对比,目的是看泛化性是不是变低了。
可视化
包含视觉知识推理、视觉常识推理、视觉对话、个性化图像到文本生成。

Zero-shot 整体
BLIP-2 在各种 Zero-Shot 视觉语言任务上的性能。与之前最先进的模型相比,BLIP-2 在视觉语言预训练期间实现了更好的性能,同时需要更少的可训练参数数量。
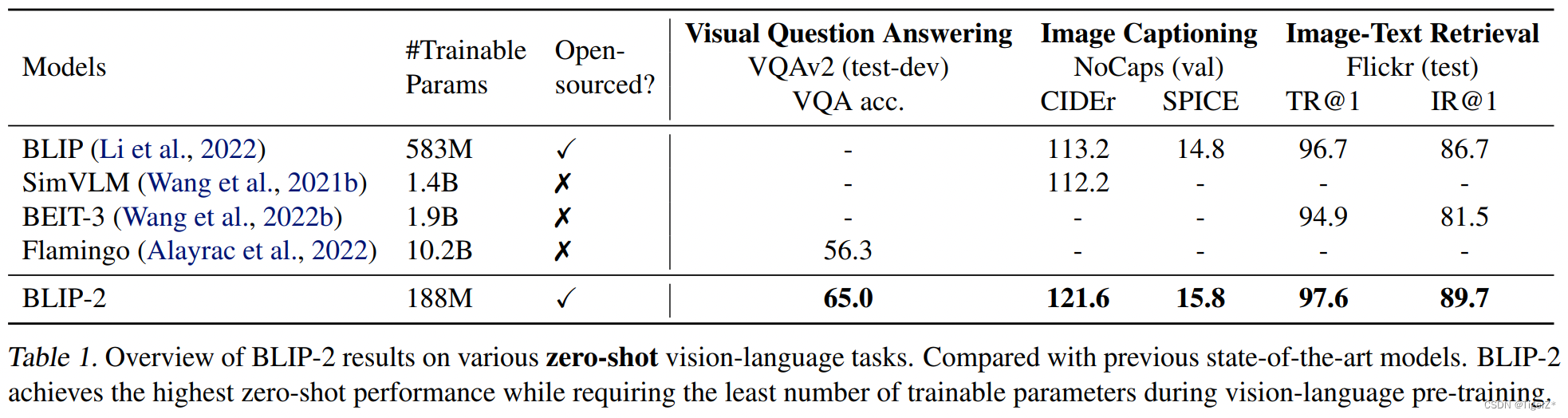
Zero-shot VQA
在可训练参数减少 54 倍的情况下,VQAv2 上的表现优于 Flamingo80B。在 OK-VQA 数据集上,BLIP-2 没打败 Flamingo80B,作者的解释是开放识别LLM模型更大,储存的知识更多。下图还说明了更大的视觉模型或者文本模型都有助于性能的提升。
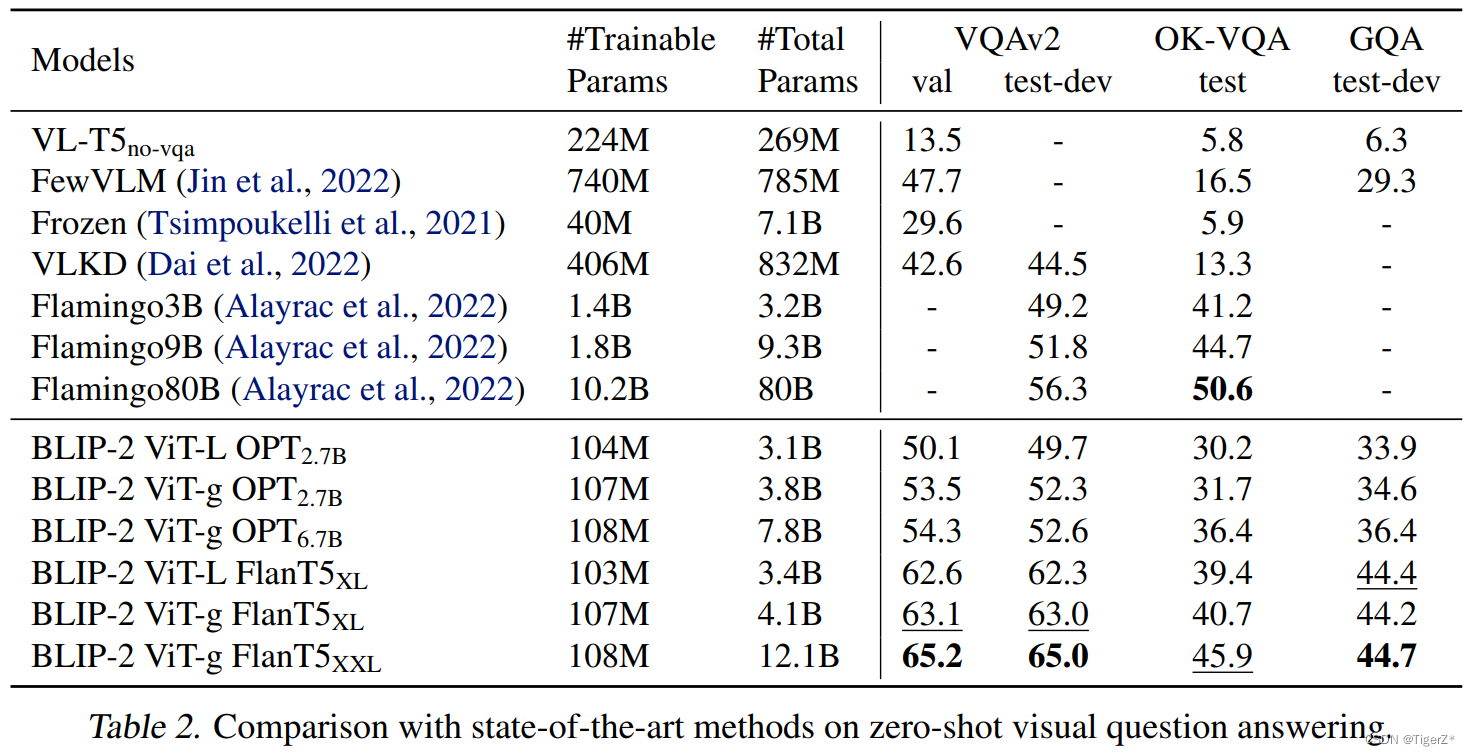
Finetune 图像描述
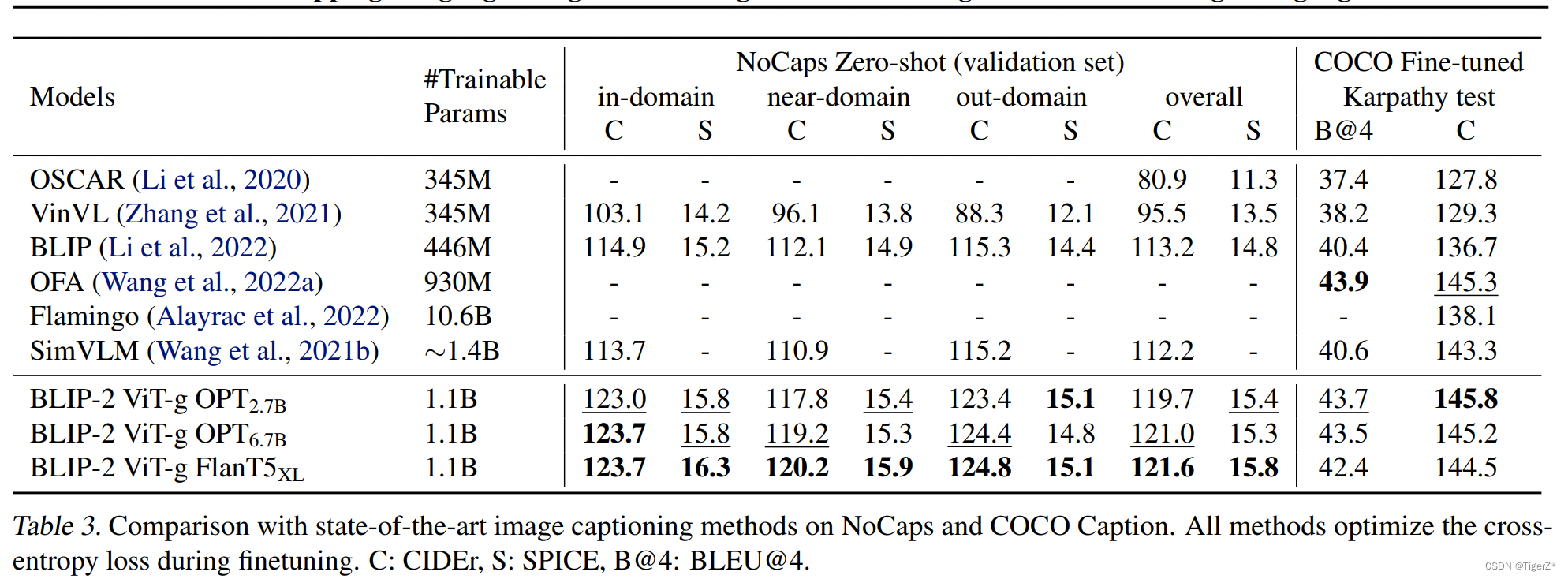
BLIP-2 在 NoCaps 上比现有方法取得了显着的改进实现了最先进的性能,显示出对域外图像的强大泛化能力。
Finetune VQA
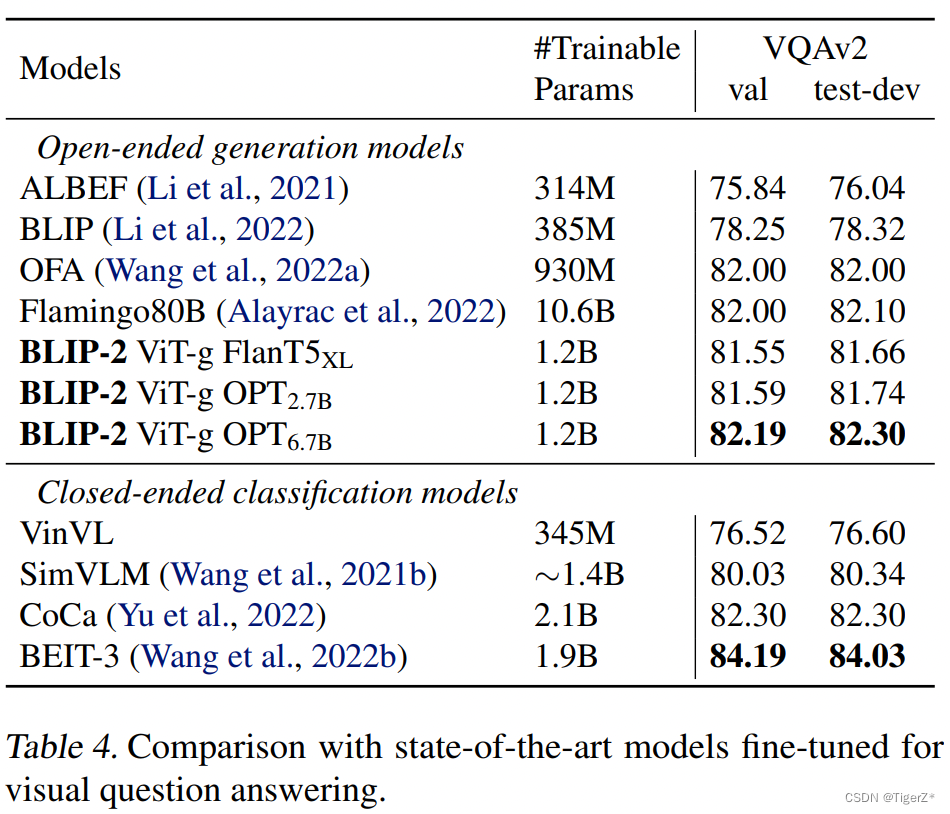
BLIP-2 属于开放式生成模型,并取得了最佳的性能。
Finetune 图文检索
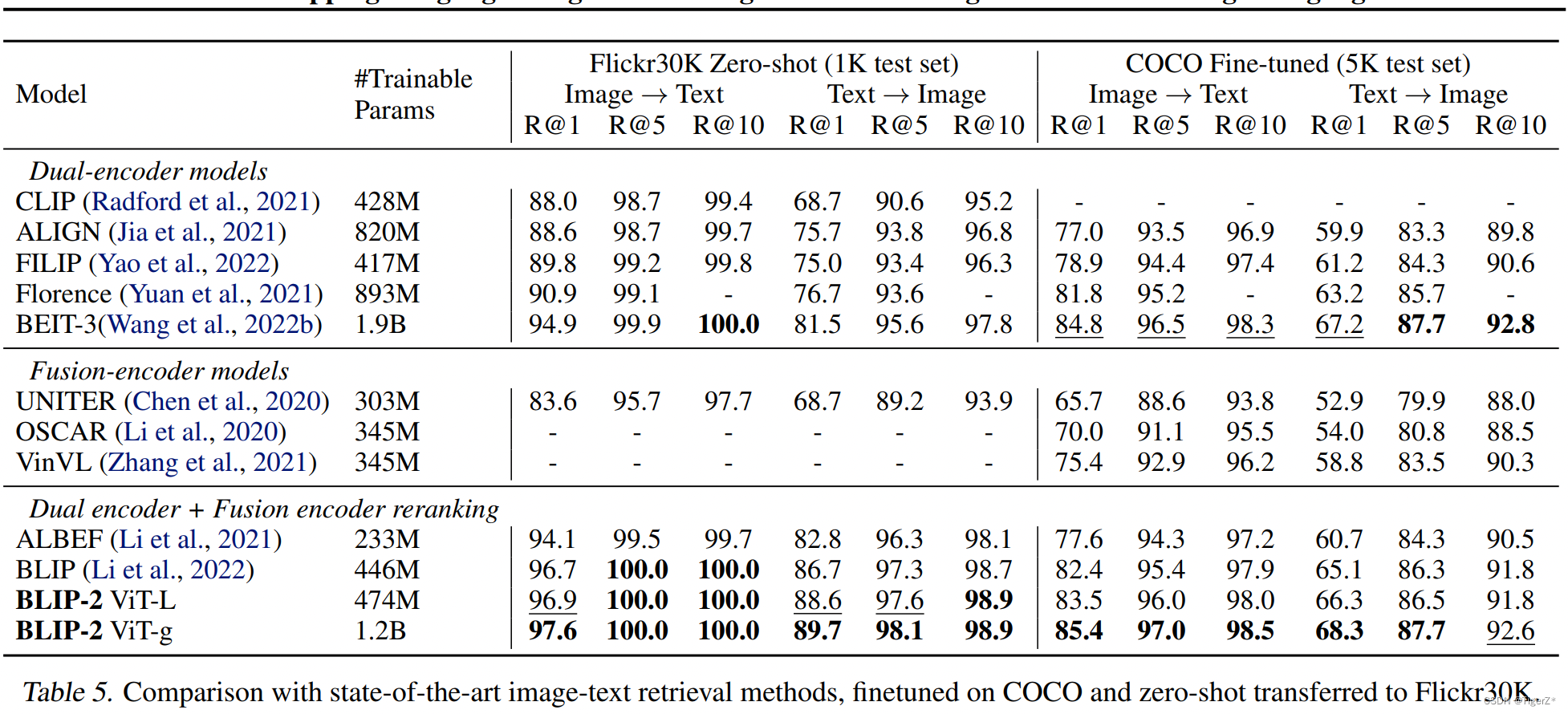
BLIP-2 在 Zero-Shot 的图像文本检索方面实现了最先进的性能,与现有方法相比有了显着改进。
2、消融实验
一阶段预训练的重要性
第一阶段的表征学习预训练 Q-Former 来学习与文本相关的视觉特征,这减少了 LLM 学习视觉语言的负担。如下所示是第一阶段的表征学习对生成学习的影响。在没有表征学习的情况下,这两种类型的 LLM 在 Zero-Shot VQA 上的性能都要低得多。而且,OPT 会有灾难性遗忘的问题,即随着训练的进行,性能会急剧下降。
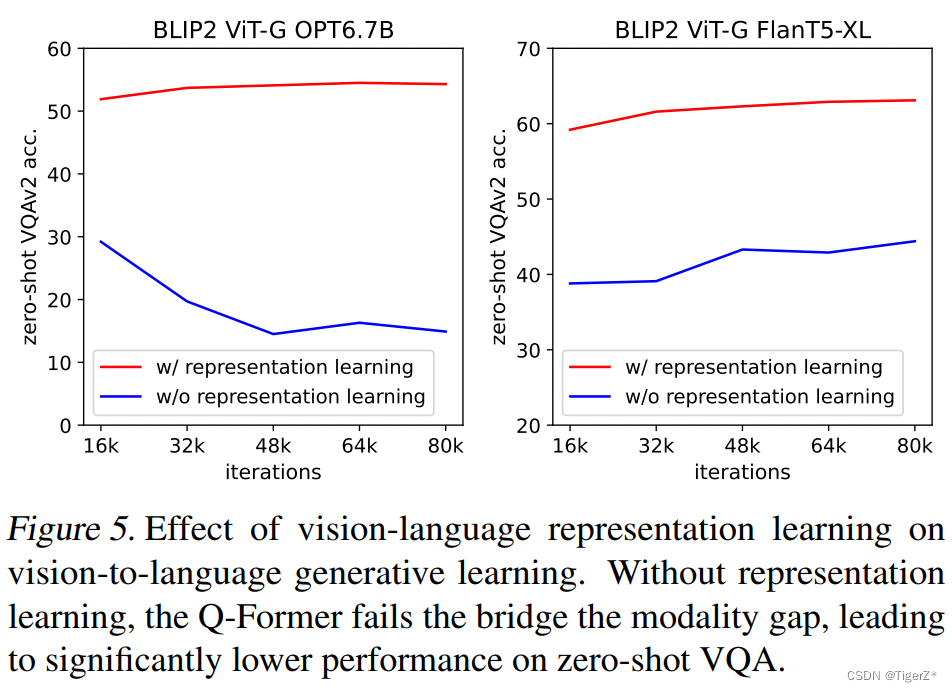
一阶段三个损失函数的重要性
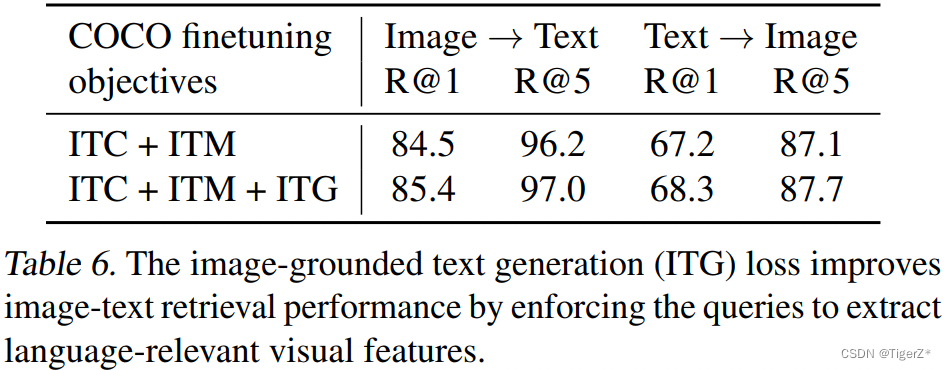
ITC和ITM损失对于图像-文本检索至关重要,因为它们直接学习图像-文本相似度。下面展示了ITG(基于图像的文本生成)损失也有利于图像文本检索。这个结果支持在设计表示学习目标时的直觉:ITG损失强制查询提取与文本最相关的视觉特征,从而提高视觉语言一致性。
六、使用方法
见git,一定要注意的是,除了做LLM图片VQA外,BLIP2 抽取的图片特征也是很好,超过了CLIP、RAM等,但是确实比较慢。
七、待解决
论文
*LLM 一般具备 In-Contet Learning 的能力,但是在 In-Context VQA 的场景下,BLIP-2 没观察到好的结果。对于这种上下文学习能力的缺失,作者把原因归结为预训练数据集中的每个数据只包含一个图像-文本对,导致 LLM 无法从中学习单个序列中多个图像-文本对之间的相关性。
*BLIP-2 的图文生成能力不够令人满意,可能是 LLM 知识不准确带来的。同时 BLIP-2 继承了冻结参数的 LLM 的风险,比如输出攻击性语言,传播社会偏见。解决的办法是指令微调,或者过滤掉有害的数据集。
自己
Promt 模板。


















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











