









1、LAVIS--语言视觉库简介
LAVIS(Language-Visual Pretraining, 语言视觉预训练)是一个开源的、针对多模态任务(包括图像、文本、视频等)的预训练模型库,旨在支持对视觉和语言任务的研究和开发。它是由多个深度学习模型和工具组成,能够处理多模态数据的输入和输出,主要面向图像与文本的结合使用。
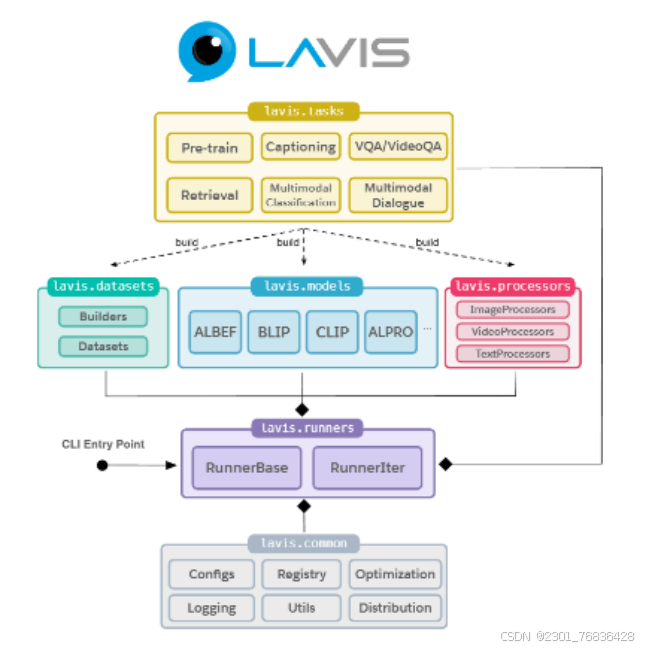
LAVIS 的主要特点包括:统一和模块化接口、轻松的现成推理和特征提取、可重复的模型库和训练配方、数据集库和自动下载工具
2、BLIP
2.1Blip2简介
BLIP-2(Bootstrapping Language-Image Pretraining 2)是BLIP模型的改进版本,旨在通过更加高效和精细的方式提升视觉-语言任务的性能。BLIP-2 由 3 个模型组成:类似 CLIP 的图像编码器、查询转换器 (Q-Former) 和大型语言模型,并在多个视觉-语言任务上表现出色。它结合了视觉模型和语言模型,特别强调了视觉信息的精确获取和生成能力,从而大幅提高了任务的处理效果。
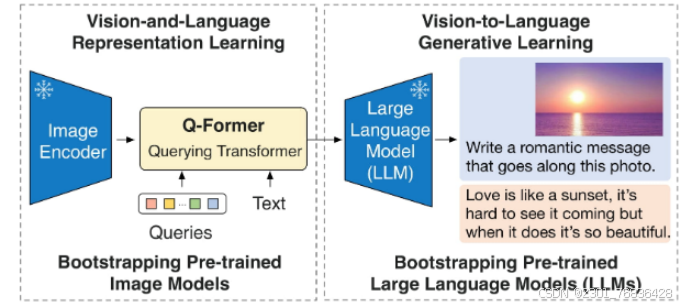
该模型可以用于以下任务:
(1)图像字幕
(2)视觉问答 (VQA)
(3)通过将图像和之前的对话作为提示输入到模型来实现类似聊天的对话
2.2 BLIP-2-OPT-2.7B介绍
本文主要介绍对BLIP-2-OPT-2.7B 进行本地部署,BLIP-2-OPT-2.7B 是 BLIP-2 系列中的一个更具体、规模更大的变种,它结合了BLIP-2的多模态学习框架和 OPT(Open Pretrained Transformer) 模型。OPT 是 Meta(前Facebook)发布的大型语言模型,它具有 2.7B 参数,专注于提升语言理解和生成能力。
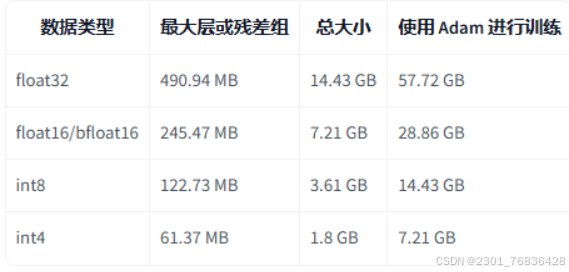
该模型可以使用不同精度进行推理进而减少对内存的需求
from transformers import Blip2Processor, Blip2ForConditionalGeneration
model=Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16, device_map="auto")通过修改torch_dtype参数来修改精度进而修改对内存需求。
3、三步完成本地部署
3.1搭建开发环境
请下载并安装Anaconda,然后用下面的命令创建并激活名为BLIP2的虚拟环境:
conda create -n BLIP2 python=3.9 #创建虚拟环境
conda activate BLIP2 #激活虚拟环境
python -m pip install --upgrade pip #升级pip到最新版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
#安装对应版本的pytorch,且在此之前已经安装好适配的cuda( https://developer.nvidia.com/cuda-toolkit )
安装lavis语言视觉库
pip install salesforce-lavis期间要是提示什么库版本不正确,对应调整库的版本 ,主要是以下几个库的版本会不兼容报错,按照以下版本安装即可:
pip install accelerate==1.0.1
pip install bitsandbytes==0.44.1
pip install transformers==4.30.0建议使用python3.9版本,其他版本的python可能会导致等会使用pip安装salesforce-lavis 时出现版本不兼容现象。
3.2.将模型安装到本地
运行以下代码把blip2-opt-2.7b模型下载到本地:
git lfs install
git clone https://huggingface.co/Salesforce/blip2-opt-2.7b如果下载速度过慢或者网络问题可以使用以下国内镜像网站进行下载:
git clone https://hf-mirror.com/Salesforce/blip2-opt-2.7b3.3 编写推理示例程序
编写blip2-opt-2.7b的推理程序,非常简单,只需要调用五个API函数:
- 编译并载入BLIP-2模型到指定DEVICE:Blip2ForConditionalGeneration.from_pretrained()
- 实例化BLIP-2模型的Processor:processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
- 加载和处理图像:raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
- 将图像和问题转换为Token序列:processor()
- 生成答案的Token序列:model.generate()
- 解码为自然语言:processor.batch_decode()
完整范例程序如下所示(在GPU上使用float16运行模型):
import torch
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = Blip2Processor.from_pretrained("C:/Users/4241/blip2-opt-2.7b") #此处修改为模型的路径可以使用绝对路径
model = Blip2ForConditionalGeneration.from_pretrained(
"C:/Users/4241/blip2-opt-2.7b", torch_dtype=torch.float16
)#此处修改为模型的路径可以使用绝对路径
model.to(device)
# 3. 加载和处理图像
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# 4. 将自然语言问题和图像转换为输入Tensor
question = "how many dogs are in the picture?"
inputs = processor(images=raw_image, return_tensors="pt").to(device, torch.float16)
# 5. 生成答案的Token序列并解码为自然语言
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)运行blip2.py:
python blip2.py运行结果,如下所示:
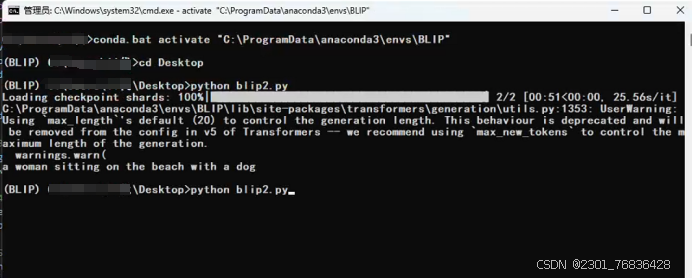
自此BLIP-2-OPT-2.7B本地部署安装完成

















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









