






原语是一种基本操作,可以在各种不同的算法和程序中使用。例如,加法、乘法、除法和随机数生成都是原语。一些原语直接由ARM指令集支持,包括32位加法和乘法。然而,许多原语在指令中没有直接支持,我们必须编写程序来实现它们(例如,除法和随机数生成)。
本章提供了常见原语的优化参考实现。前三个部分介绍了乘法和除法。第7.1节介绍了实现扩展精度乘法的原语。第7.2节介绍了规范化,这对于第7.3节中的除法算法非常有用。
接下来的两节介绍了更复杂的数学运算。第7.4节讨论了平方根。第7.5节介绍了对数、指数、正弦和余弦等超越函数。第7.6节介绍了涉及位操作的运算,第7.7节介绍了饱和和舍入等运算。最后,第7.8节介绍了随机数生成。
您可以以两种方式使用本章内容。首先,它可以作为一个直接的参考。如果您需要一个除法程序,请查找索引并找到该程序所在的部分,或者找到关于除法的部分。您可以从书籍网站上复制汇编代码。其次,本章提供了理论解释每个实现原理的知识,这对于需要更改或泛化程序的情况非常有用。例如,您可能对输入和输出操作数的精度或格式有不同的要求。因此,本文中包含许多数学公式和一些繁琐的证明。您可以根据需要选择是否跳过这些内容!
我们设计了代码示例,使其成为可以直接从网站上获取的完整函数。它们应该可以立即使用ARM提供的工具包进行汇编。为了一致性,我们在本章的所有示例中都使用ARM工具包ADS1.1。有关汇编器格式的帮助,请参阅附录中的第A.4节。您也可以使用GNU汇编器gas。有关gas汇编器格式的帮助,请参阅第A.5节。
您还会注意到,我们使用C关键字__value_in_regs。在ARM编译器armcc中,这表示函数参数或返回值应通过寄存器传递,而不是通过引用传递。在实际应用中,这不是一个问题,因为您将内联操作以提高效率。
在本章中,我们使用符号Qk表示二进制小数点位于第k-1位和第k位之间的定点表示法。例如,在Q15中表示的0.75是整数值0x6000。有关Qk表示法和定点算术的更多详细信息,请参阅第8.1节。我们说"d < 0.5 at Q15"表示d表示值d2−15,并且此值小于一半。
7.1 Double-Precision Integer Multiplication
您可以使用UMULL和SMULL指令将整数扩展到32位宽度。以下例程可以对64位有符号或无符号整数进行乘法运算,并得到64位或128位的结果。使用相同的思路,它们可以扩展到乘法运算中的任意长度的整数。更长的乘法运算对于处理long long C类型、模拟双精度固定点或浮点运算,以及公钥密码学中所需的长算术非常有用。

我们使用小端记法表示多字节值。如果一个128位整数存储在四个寄存器a3、a2、a1、a0中,那么它们分别存储的是[127:96]、[95:64]、[63:32]、[31:0]位(参见图7.1)。
7.1.1 long long Multiplication
使用以下三个指令序列将两个64位值(有符号或无符号)b和c相乘,得到一个新的64位long long值a。不包括ARM Thumb过程调用标准(ATPCS)包装器,并且在最坏情况下的输入时,此操作在ARM7TDMI上需要24个周期,在ARM9TDMI上需要25个周期。在ARM9E上,该操作需要8个周期。其中一个周期是第一个UMULL和MLA之间的流水线互锁,您可以通过与其他代码交替执行来消除它。
b_0 RN 0 ; b bits [31:00] (b low)
b_1 RN 1 ; b bits [63:32] (b high)
c_0 RN 2 ; c bits [31:00] (c low)
c_1 RN 3 ; c bits [63:32] (c high)
a_0 RN 4 ; a bits [31:00] (a low-low)
a_1 RN 5 ; a bits [63:32] (a low-high)
a_2 RN 12 ; a bits [95:64] (a high-low)
a_3 RN lr ; a bits [127:96] (a high-high)
; long long mul_64to64 (long long b, long long c)
mul_64to64
STMFD sp!, {r4,r5,lr}
; 64-bit a = 64-bit b * 64-bit c
UMULL a_0, a_1, b_0, c_0
; low*low
MLA a_1, b_0, c_1, a_1
; low*high
MLA a_1, b_1, c_0, a_1
; high*low
; return wrapper
MOV r0, a_0
MOV r1, a_1
LDMFD sp!, {r4,r5,pc}7.1.2 Unsigned 64-Bit by 64-Bit Multiply with 128-Bit Result
对于具有128位结果的无符号64位乘法运算,有两种略有不同的实现方法。第一种在ARM7M上速度更快。在这种情况下,相比于非累加版本,乘积累加指令需要额外的一个周期。ARM7M版本需要四次长乘法和六次加法,最坏情况下需要30个周期来完成。
; __value_in_regs struct { unsigned a0,a1,a2,a3; }
; umul_64to128_arm7m(unsigned long long b,
;
unsigned long long c)
umul_64to128_arm7m
STMFD sp!, {r4,r5,lr}
; unsigned 128-bit a = 64-bit b * 64-bit c
UMULL a_0, a_1, b_0, c_0 ; low*low
UMULL a_2, a_3, b_0, c_1 ; low*high
UMULL c_1, b_0, b_1, c_1 ; high*high
ADDS a_1, a_1, a_2
ADCS a_2, a_3, c_1
ADC a_3, b_0, #0
UMULL c_0, b_0, b_1, c_0 ; high*low
ADDS a_1, a_1, c_0
ADCS a_2, a_2, b_0
ADC a_3, a_3, #0
; return wrapper
MOV r0, a_0
MOV r1, a_1
MOV r2, a_2
MOV r3, a_3
LDMFD sp!, {r4,r5,pc}第二种方法在ARM9TDMI和ARM9E上效果更好。在这种情况下,乘积累加与乘法的速度相同。我们对乘法指令进行调度,以避免在ARM9E上发生结果使用互锁(有关流水线和互锁的说明,请参见第6.2节)。
; __value_in_regs struct { unsigned a0,a1,a2,a3; }
; umul_64to128_arm9e(unsigned long long b,
;
unsigned long long c)
umul_64to128_arm9e
STMFD sp!, {r4,r5,lr}
; unsigned 128-bit a = 64-bit b * 64-bit c
UMULL a_0, a_1, b_0, c_0 ; low*low
MOV a_2, #0
UMLAL a_1, a_2, b_0, c_1 ; low*high
MOV a_3, #0
UMLAL a_1, a_3, b_1, c_0 ; high*low
MOV b_0, #0
ADDS a_2, a_2, a_3
ADC a_3, b_0, #0
UMLAL a_2, a_3, b_1, c_1 ; high*high
; return wrapper
MOV r0, a_0
MOV r1, a_1
MOV r2, a_2
MOV r3, a_3
LDMFD sp!, {r4,r5,pc}在排除函数调用和返回包装的情况下,该实现在ARM9TDMI上需要33个周期,在ARM9E上需要17个周期。这个想法是,如果a、b、c和d都是无符号32位整数,那么操作ab + c + d不会导致无符号64位整数溢出。因此,您可以使用常规的竖式乘法方法来实现长乘法,其中使用了ab + c + d操作,其中c和d是水平和垂直进位。
7.1.3 Signed 64-Bit by 64-Bit Multiply with 128-Bit Result
一个有符号的64位整数可以分解为有符号的高32位和无符号的低32位。要将b的高位与c的低位相乘,需要一条有符号乘以无符号的乘法指令。尽管ARM没有这样的指令,但我们可以使用宏合成一个。
以下是宏定义USMLAL提供了一种无符号乘以有符号的累加操作。为了将无符号的b与有符号的c相乘,它首先将这两个值都视为有符号数计算乘积bc。如果b的最高位设置为1,那么这个有符号数乘积还要乘以2^32-b。在这种情况下,它通过加上c*2^32来纠正结果。类似地,SUMLAL执行有符号乘以无符号的累加运算。
MACRO
USMLAL $al, $ah, $b, $c
; signed $ah.$al += unsigned $b * signed $c
SMLAL $al, $ah, $b, $c ; a = (signed)b * c;
TST $b, #1 << 31
; if ((signed)b<0)
ADDNE $ah, $ah, $c
; a += (c << 32);
MEND
MACRO
SUMLAL $al, $ah, $b, $c
; signed $ah.$al += signed $b * unsigned $c
SMLAL $al, $ah, $b, $c
;a=b* (signed)c;
TST $c, #1 << 31
; if ((signed)c<0)
ADDNE $ah, $ah, $b
; a += (b << 32);
MEND使用这些宏,将第7.1.2节中的64位乘法转换为有符号乘法相对简单。由于有符号与无符号修复指令,这个有符号版本比对应的无符号版本多了四个周期。
; __value_in_regs struct { unsigned a0,a1,a2; signed a3; }
; smul_64to128(long long b, long long c)
smul_64to128
STMFD sp!, {r4,r5,lr}
; signed 128-bit a = 64-bit b * 64-bit c
UMULL a_0, a_1, b_0, c_0 ; low*low
MOV a_2, #0
USMLAL a_1, a_2, b_0, c_1 ; low*high
MOV a_3, #0
SUMLAL a_1, a_3, b_1, c_0 ; high*low
MOV b_0, a_2, ASR#31
ADDS a_2, a_2, a_3
ADC a_3, b_0, a_3, ASR#31
SMLAL a_2, a_3, b_1, c_1 ; high*high
; return wrapper
MOV r0, a_0
MOV r1, a_1
MOV r2, a_2
MOV r3, a_3
LDMFD sp!, {r4,r5,pc}7.2 Integer Normalization and Count Leading Zeros
当整数的最高位(或者最重要的位)处于已知的位位置时,这个整数就被称为归一化。我们需要归一化来实现牛顿-拉弗森除法(参见第7.3.2节)或者转换为浮点数格式。在计算对数(参见第7.5.1节)和某些调度例程中使用的优先级解码器时,归一化也非常有用。在这些应用中,我们需要知道归一化值和达到该值所需的移位量。
这个操作非常重要,从ARM架构ARMv5E开始提供了指令来加速归一化过程。CLZ指令用于计算第一个有效位之前的前导零数。如果根本不存在有效的1位,则返回32。CLZ的值就是您需要应用的左移量,用于将整数归一化,使得最高位位于第31位。
7.2.1 Normalization on ARMv5 and Above
在ARMv5架构上,可以使用以下代码分别执行无符号和有符号归一化。无符号归一化左移,直到最高位位于第31位。有符号归一化左移,直到第31位有一个符号位,并且最高位位于第30位。两个函数都返回一个由两个值组成的结构体,即归一化的整数和进行归一化所需的左移。
x RN 0 ; input, output integer
shift RN 1 ; shift to normalize
; __value_in_regs struct { unsigned x; int shift; }
; unorm_arm9e(unsigned x)
unorm_arm9e
CLZ shift, x
; left shift to normalize
MOV x, x, LSL shift ; normalize
MOV pc, lr
; __value_in_regs struct { signed x; int shift; }
; unorm_arm9e(signed x)
snorm_arm9e
; [ s s s 1-s x x ... ]
EOR shift, x, x, LSL#1
; [ 0 0 1 x x x ... ]
CLZ shift, shift ; left shift to normalize
MOV x, x, LSL shift ; normalize
MOV pc, lr请注意,我们通过使用逻辑异或将有符号归一化转换为无符号归一化。如果x是有符号数,则x∧(x∧1)的最高位位于x的第一个符号位的位置上。
7.2.2 Normalization on ARMv4
如果您正在使用ARM7TDMI或ARM9TDMI等ARMv4架构处理器,则没有可用的CLZ指令。但是,我们可以合成相同的功能。unorm_arm7m中的简单分治方法在性能和代码大小之间取得了良好的平衡。我们依次测试是否可以将x左移16、8、4、2和1位。
; __value_in_regs struct { unsigned x; int shift; }
; unorm_arm7m(unsigned x)
unorm_arm7m
MOV shift, #0
; shift=0;
CMP x, #1 << 16 ; if (x < (1 << 16))
MOVCC x, x, LSL#16 ;
{ x = x << 16;
ADDCC shift, shift, #16 ; shift+=16; }
TST x, #0xFF000000 ; if (x < (1 << 24))
MOVEQ x, x, LSL#8 ;
{ x = x << 8;
ADDEQ shift, shift, #8 ; shift+=8; }
TST x, #0xF0000000 ; if (x < (1 << 28))
MOVEQ x, x, LSL#4 ;
{ x = x << 4;
ADDEQ shift, shift, #4 ; shift+=4; }
TST x, #0xC0000000 ; if (x < (1 << 30))
MOVEQ x, x, LSL#2 ;
{ x = x << 2;
ADDEQ shift, shift, #2 ; shift+=2; }
TST x, #0x80000000 ; if (x < (1 << 31))
ADDEQ shift, shift, #1 ; { shift+=1;
MOVEQS x, x, LSL#1 ; x << =1;
MOVEQ shift, #32
; if (x==0) shift=32; }
MOV pc, lr如果您使用的是ARM7TDMI或ARM9TDMI等ARMv4架构处理器,最终的MOVEQ指令在x为零时将shift设置为32,并且经常可以省略。这种实现在ARM7TDMI或ARM9TDMI上需要17个周期,足够满足大多数需求。然而,这并不是在这些处理器上归一化的最快方式。为了实现最快的归一化速度,可以使用基于哈希的方法。

基于哈希的方法首先将输入操作数减少到33种不同的可能性之一,而不改变CLZ值。我们通过对移位s = 1、2、4、8迭代执行x = x | (x >> s)来实现这一点。这将导致最高位的1向右复制16次。然后我们计算x & ~(x >> 16)。这将清除复制的16个1右侧的16个比特位。表格7.1说明了这些操作的综合效果。对于每个可能的输入二进制模式,我们展示了这些操作生成的32位代码。请注意,输入模式的CLZ值与代码的CLZ值相同。
现在我们的目标是使用哈希函数和查找表从代码值获取CLZ值。有关哈希函数的详细信息,请参见第6.8.2节。
对于哈希函数,我们将乘以一个大的值,并提取结果的前六位。形如2a + 1和2a - 1的值在ARM上使用移位器进行乘法非常容易。事实上,乘以(29 - 1)(211 - 1)(214 - 1)会为每个不同的CLZ值给出不同的哈希值。作者通过计算搜索找到了这个乘法器。
您可以使用此代码在ARMv4处理器上实现基于哈希的快速归一化。该实现在ARM7TDMI上需要13个周期(不包括设置表指针的时间)。
table RN 2 ; address of hash lookup table
;__value_in_regs struct { unsigned x; int shift; }
; unorm_arm7m_hash(unsigned x)
unorm_arm7m_hash
ORR shift, x, x, LSR#1
ORR shift, shift, shift, LSR#2
ORR shift, shift, shift, LSR#4
ORR shift, shift, shift, LSR#8
BIC shift, shift, shift, LSR#16
RSB shift, shift, shift, LSL#9 ; *(2∧9-1)
RSB shift, shift, shift, LSL#11 ; *(2∧11-1)
RSB shift, shift, shift, LSL#14 ; *(2∧14-1)
ADR table, unorm_arm7m_hash_table
LDRB shift, [table, shift, LSR#26]
MOV x, x, LSL shift
MOV pc, lr
unorm_arm7m_hash_table
DCB 0x20, 0x14, 0x13, 0xff, 0xff, 0x12, 0xff, 0x07
DCB 0x0a, 0x11, 0xff, 0xff, 0x0e, 0xff, 0x06, 0xff
DCB 0xff, 0x09, 0xff, 0x10, 0xff, 0xff, 0x01, 0x1a
DCB 0xff, 0x0d, 0xff, 0xff, 0x18, 0x05, 0xff, 0xff
DCB 0xff, 0x15, 0xff, 0x08, 0x0b, 0xff, 0x0f, 0xff
DCB 0xff, 0xff, 0xff, 0x02, 0x1b, 0x00, 0x19, 0xff
DCB 0x16, 0xff, 0x0c, 0xff, 0xff, 0x03, 0x1c, 0xff
DCB 0x17, 0xff, 0x04, 0x1d, 0xff, 0xff, 0x1e, 0x1f7.2.3 Counting Trailing Zeros
末尾零位计数(Count trailing zeros)是与首位零位计数(count leading zeros)相关的操作。它计算整数中最低有效置位位下方的零位数量。等价地,这可以检测整数的最高幂次的二次方。因此,可以通过计算末尾零位来将一个整数表示为2的幂次和一个奇数的乘积。如果整数为零,则没有最低位,因此末尾零位计数返回32。

要找到一个非零整数n的最高幂次的二次方,有一个技巧。技巧在于观察到表达式(n &(-n))在n中最低位位置上有一个单独的位被置位。图7.2展示了这个技巧的工作原理。其中,x表示通配符位。
使用这个技巧,我们可以将末尾零位计数转换为首位零位计数。以下代码在ARM9E上实现了末尾零位计数。我们通过使用条件指令来处理零输入情况,以避免额外的开销。
; unsigned ctz_arm9e(unsigned x)
ctz_arm9e
RSBS shift, x, #0 ; shift=-x
AND shift, shift, x ; isolate trailing 1 of x
CLZCC shift, shift ; number of zeros above last 1
RSC r0, shift, #32 ; number of zeros below last 1
MOV pc, lr对于没有CLZ指令的处理器,类似于7.2.2节中的哈希方法可以获得良好的性能:
; unsigned ctz_arm7m(unsigned x)
ctz_arm7m
RSB shift, x, #0
AND shift, shift, x
; isolate lowest bit
ADD shift, shift, shift, LSL#4 ; *(2∧4+1)
ADD shift, shift, shift, LSL#6 ; *(2∧6+1)
RSB shift, shift, shift, LSL#16 ; *(2∧16-1)
ADR table, ctz_arm7m_hash_table
LDRB r0, [table, shift, LSR#26]
MOV pc, lr
ctz_arm7m_hash_table
DCB 0x20, 0x00, 0x01, 0x0c, 0x02, 0x06, 0xff, 0x0d
DCB 0x03, 0xff, 0x07, 0xff, 0xff, 0xff, 0xff, 0x0e
DCB 0x0a, 0x04, 0xff, 0xff, 0x08, 0xff, 0xff, 0x19
DCB 0xff, 0xff, 0xff, 0xff, 0xff, 0x15, 0x1b, 0x0f
DCB 0x1f, 0x0b, 0x05, 0xff, 0xff, 0xff, 0xff, 0xff
DCB 0x09, 0xff, 0xff, 0x18, 0xff, 0xff, 0x14, 0x1a
DCB 0x1e, 0xff, 0xff, 0xff, 0xff, 0x17, 0xff, 0x13
DCB 0x1d, 0xff, 0x16, 0x12, 0x1c, 0x11, 0x107.3 Division
ARM核心没有硬件支持除法运算。要进行除法运算,必须调用一个使用标准算术运算符计算结果的软件程序。如果无法避免除法(请参见第5.10节以了解如何避免除法和通过重复分母进行快速除法),那么您需要访问经过高度优化的除法程序。本节提供一些有用的优化除法程序。
在ARM9E上,经过积极优化的牛顿-拉弗森(Newton-Raphson)除法程序每个周期运行速度与硬件除法实现相当。因此,ARM不需要复杂的硬件除法实现。
本节描述了我们所知道的最快的除法实现。由于有许多不同的除法技术和精度需要考虑,本节的长度不可避免地很长。我们还将证明这些程序确实适用于所有可能的输入。这是必要的,因为我们不能为32位乘以32位的除法尝试所有可能的输入参数!如果您对理论细节不感兴趣,可以跳过证明部分,直接从文本中获取代码。
7.3.1节介绍了使用试减法或二分查找的除法实现。当由于小商而可能出现早期终止时,试减法很有用,或者在处理器核心中没有快速乘法指令时。7.3.2节和7.3.3节介绍了使用牛顿-拉弗森迭代收敛到结果的实现。当最坏情况性能很重要或者存在快速乘法指令时,使用牛顿-拉弗森迭代。牛顿-拉弗森实现使用ARMv5TE扩展。最后,7.3.4节讨论有符号除法而不是无符号除法。
我们需要区分整数除法和真正的数学除法。让我们固定以下符号:
- n/d = 结果的整数部分,向零舍入(与C语言相同)
- n%d = 整数余数 n - d(n/d)(与C语言相同)
- n//d = nd-1 = n除以d的真正数学结果
7.3.1 Unsigned Division by Trial Subtraction
//无符号试减法除法
假设我们需要计算无符号整数n和d的商q = n/d以及余数r = n % d。同时假设我们知道商q适合N位,即 n/d < 2^N,或者等价地说n < (d << N)。试减法算法通过逐个尝试设置每个位来计算q的N位,从最高位开始,即第N-1位。这等效于对结果进行二分查找。如果我们可以从当前余数中减去(d << k)而不产生负数结果,就可以设置第k位。示例udiv_simple给出了此算法的简单C实现:
unsigned udiv_simple(unsigned d, unsigned n, unsigned N)
{
unsigned q=0, r=n;
do
{
/* calculate next quotient bit */
N--;
/* move to next bit */
if ( (r >> N) >= d ) /* if r>=d*(1 << N) */
{
r -= (d << N); /* update remainder */
q += (1 << N); /* update quotient */
}
} while (N);
return q;
}为了证明答案的正确性,注意在我们递减N之前,等式(7.1)的不变量成立:
![]()
初始时,q = 0且r = n,根据我们假设商适合N位,因此不变式成立。现在假设对于某个N,不变式保持成立。如果r<d^(2N−1),则我们不需要做任何操作使得不变式在N-1上保持成立。如果r ≥ d^(2N−1),则通过从r中减去d^(2N−1)并将2^(N−1)加到q上来保持不变式成立。
前述的实现称为恢复试减法实现。在非恢复式实现中,总是进行减法操作。然而,如果r变为负数,则在下一轮中使用加法(d N)而不是减法,以得到相同的结果。非恢复式除法在ARM上速度较慢,因此我们不会详细介绍。以下子节给出了用于不同被除数和除数大小的试减法的汇编实现。它们可以在任何ARM处理器上运行。
7.3.1.1 Unsigned 32-Bit/32-Bit Divide by Trial Subtraction
这是C编译器所需的操作。当在C中出现表达式n/d或n%d,并且d不是2的幂时,它将被调用。该例程返回一个由商和余数组成的两个元素的结构体。
d RN 0 ; input denominator d, output quotient
r RN 1 ; input numerator n, output remainder
t RN 2 ; scratch register
q RN 3 ; current quotient
; __value_in_regs struct { unsigned q, r; }
; udiv_32by32_arm7m(unsigned d, unsigned n)
udiv_32by32_arm7m
MOV q, #0
; zero quotient
RSBS t, d, r, LSR#3 ; if ((r >> 3)>=d) C=1; else C=0;
BCC div_3bits
; quotient fits in 3 bits
RSBS t, d, r, LSR#8 ; if ((r >> 8)>=d) C=1; else C=0;
BCC div_8bits
; quotient fits in 8 bits
MOV d, d, LSL#8 ; d = d*256
ORR q, q, #0xFF000000 ; make div_loop iterate twice
RSBS t, d, r, LSR#4 ; if ((r >> 4)>=d) C=1; else C=0;
BCC div_4bits
; quotient fits in 12 bits
RSBS t, d, r, LSR#8 ; if ((r >> 8)>=d) C=1; else C=0;
BCC div_8bits
; quotient fits in 16 bits
MOV d, d, LSL#8 ; d = d*256
ORR q, q, #0x00FF0000 ; make div_loop iterate 3 times
RSBS t, d, r, LSR#8 ; if ((r >> 8)>=d)
MOVCS d, d, LSL#8
;{d= d*256;
ORRCS q, q, #0x0000FF00 ; make div_loop iterate 4 times}
RSBS t, d, r, LSR#4 ; if ((r >> 4)<d)
BCC div_4bits
; r/d quotient fits in 4 bits
RSBS t, d, #0
; if (0 >= d)
BCS div_by_0
; goto divide by zero trap
; fall through to the loop with C=0
div_loop
MOVCS d, d, LSR#8 ; if (next loop) d = d/256
div_8bits
; calculate 8 quotient bits
RSBS t, d, r, LSR#7 ; if ((r >> 7)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#7 ; if (C) r -= d << 7;
ADC q, q, q
; q=(q << 1)+C;
RSBS t, d, r, LSR#6 ; if ((r >> 6)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#6 ; if (C) r -= d << 6;
ADC q, q, q
; q=(q << 1)+C;
RSBS t, d, r, LSR#5 ; if ((r >> 5)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#5 ; if (C) r -= d << 5;
ADC q, q, q
; q=(q << 1)+C;
RSBS t, d, r, LSR#4 ; if ((r >> 4)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#4 ; if (C) r -= d << 4;
ADC q, q, q
; q=(q << 1)+C;
div_4bits
; calculate 4 quotient bits
RSBS t, d, r, LSR#3 ; if ((r >> 3)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#3 ; if (C) r -= d << 3;
ADC q, q, q
; q=(q << 1)+C;
div_3bits
; calculate 3 quotient bits
RSBS t, d, r, LSR#2 ; if ((r >> 2)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#2 ; if (C) r -= d << 2;
ADC q, q, q
; q=(q << 1)+C;
RSBS t, d, r, LSR#1 ; if ((r >> 1)>=d) C=1; else C=0;
SUBCS r, r, d, LSL#1 ; if (C) r -= d << 1;
ADC q, q, q
; q=(q << 1)+C;
RSBS t, d, r
; if (r>=d) C=1; else C=0;
SUBCS r, r, d
; if (C) r -= d;
ADCS q, q, q
; q=(q << 1)+C; C=old q bit 31;
div_next
BCS div_loop
; loop if more quotient bits
MOV r0, q
; r0 = quotient; r1=remainder;
MOV pc, lr
; return { r0, r1 } structure;
div_by_0
MOV r0, #-1
MOV r1, #-1
MOV pc, lr
; return { -1, -1 } structure;要了解这个例程的工作原理,首先看一下在标签div_8bits和div_next之间的代码。这段代码计算8位商r/d,将余数保存在r中,并将商的8位插入到q的低位中。该代码使用了试减法算法。它尝试从r中依次减去128d、64d、32d、16d、8d、4d、2d和d。对于每次减法操作,如果减法是可行的,则将carry设置为1,否则为0。这个carry构成了要插入到q中的下一个结果位。
接下来注意,我们可以从div_4bits或div_3bits进入该代码,如果我们只想进行4位或3位的除法运算。
现在看一下例程的开头。我们希望计算r/d,将余数保存在r中,并将商写入q。我们首先检查商q是否能容纳3位或8位。如果是的话,我们可以直接跳转到div_3bits或div_8bits,分别计算出结果。这种提前终止在C语言中很有用,因为商通常较小。如果商需要超过8位,那么我们将d乘以256,直到r/d能够容纳8位为止。我们记录了我们通过高位的q将d乘以256的次数,每次乘法设置8位。这意味着在计算完8位r/d之后,我们会回到div_loop并为前面每次乘法都将d除以256。通过这种方式,我们将除法转化为一系列的8位除法。
7.3.1.2 Unsigned 32/15-Bit Divide by Trial Subtraction
在第7.3.1.1节中的32/32除法中,每次试减法操作需要每位商三个周期。然而,如果我们将分母和商限制为15位,那么每位商的试减法操作只需要两个周期。您会发现这种操作在16位DSP中非常有用,因为两个正Q15数的除法需要进行30/15位整数除法(参见第8.1.5节)。
在下面的代码中,被除数n是一个32位无符号整数。分母d是一个15位无符号整数。该例程返回一个包含15位商q和余数r的结构体。如果n ≥ (d << 15),那么结果会溢出,我们返回最大可能的商0x7fff。
m RN 0 ; input denominator d then (-d << 14)
r RN 1 ; input numerator n then remainder
; __value_in_regs struct { unsigned q, r; }
; udiv_32by16_arm7m(unsigned d, unsigned n)
udiv_32by16_arm7m
RSBS m, m, r, LSR#15
; m = (n >> 15) - d
BCS overflow_15
; overflow if (n >> 15)>=d
SUB m, m, r, LSR#15
; m = -d
MOV m, m, LSL#14
; m = -d << 14
; 15 trial division steps follow
ADDS r, m, r
; r=r-(d << 14); C=(r>=0);
SUBCC r, r, m
; if (C==0) r+=(d << 14)
ADCS r, m, r, LSL #1
; r=(2*r+C)-(d << 14); C=(r>=0);
SUBCC r, r, m
; if (C==0) r+=(d << 14)
ADCS r, m, r, LSL #1
; ... and repeat ...
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
ADCS r, m, r, LSL #1
SUBCC r, r, m
; extract answer and remainder (if required)
ADC r0, r, r
; insert final answer bit
MOV r, r0, LSR #15 ; extract remainder
BIC r0, r0, r, LSL #15 ; extract quotient
MOV pc, lr
; return { r0, r }
overflow_15
; quotient oveflows 15 bits
LDR r0, =0x7fff ; maximum quotient
MOV r1, r0
; maximum remainder
MOV pc, lr
; return { 0x7fff, 0x7fff }我们首先将m设置为-d214。与将分母的位移版本从余数中减去不同,我们将取负的分母加到位移后的余数中。在第k次试减法步骤之后,r的最低k位保存商的最高k位。r的上32-k位保存余数。每个ADC指令执行三个功能:
- 它将余数左移一位。
- 它插入最后一次试减法的下一个商位。
- 它从余数中减去d << 14。
经过15步操作,r的最低的15位包含商,而最高的17位包含余数。我们将它们分别记为r0和r1。除了返回之外,在ARM7TDMI上,该除法需要35个周期来完成。
7.3.1.3 Unsigned 64/31-Bit Divide by Trial Subtraction
这种操作在需要除以Q31定点整数时非常有用(参见第8.1.5节)。它可以使得在第7.3.1.2节中的除法精度加倍。被除数n是一个无符号64位整数,除数d是一个无符号的31位整数。下面的例程返回一个包含32位商q和余数r的结构体。如果n ≥ d^232,那么结果会溢出,我们返回最大可能的商0xffffffff。这个例程使用三位每周期试减法,在ARM7TDMI上需要99个周期。在代码注释中,我们使用[r, q]来表示一个64位值,其中高32位是r,低32位是q。
m RN 0 ; input denominator d, -d
r RN 1 ; input numerator (low), remainder (high)
t RN 2 ; input numerator (high)
q RN 3 ; result quotient and remainder (low)
; __value_in_regs struct { unsigned q, r; }
; udiv_64by32_arm7m(unsigned d, unsigned long long n)
udiv_64by32_arm7m
CMP t, m
; if (n >= (d << 32))
BCS overflow_32 ; goto overflow_32;
RSB m, m, #0 ; m = -d
ADDS q, r, r ; { [r,q] = 2*[r,q]-[d,0];
ADCS r, m, t, LSL#1 ; C = ([r,q]>=0); }
SUBCC r, r, m ; if (C==0) [r,q] += [d,0]
GBLA k
; the next 32 steps are the same
k SETA 1
; so we generate them using an
WHILE k<32
; assembler while loop
ADCS q, q, q ; { [r,q] = 2*[r,q]+C - [d,0];
ADCS r, m, r, LSL#1 ; C = ([r,q]>=0); }
SUBCC r, r, m ; if (C==0) [r,q] += [d,0]
k SETA k+1
WEND
ADCS r0, q, q ; insert final answer bit
MOV pc, lr ; return { r0, r1 }
overflow_32
MOV r0, #-1
MOV r1, #-1
MOV pc, lr ; return { -1, -1 }这个想法与32/15位除法类似。在第k次试减法后,64位值[r, q]包含最高的64-k位余数。最低的k位包含最高的k位商。经过32次试减法之后,r保存余数,q保存商。两个ADC指令将[r, q]左移一位,在底部插入最后一个答案位,并从上32位中减去分母。如果减法溢出,我们通过加回分母来修正余数r。
7.3.2 Unsigned Integer Newton-Raphson Division
//无符号整数的牛顿-拉弗森除法
牛顿-拉弗森迭代是一种用于数值求解方程的强大技术。一旦我们有了方程解的良好近似值,迭代将非常快速地收敛于该解。实际上,收敛通常是二次的,随着每次迭代有效小数位数的大约加倍。牛顿-拉弗森方法被广泛用于计算高精度的倒数和平方根。我们将使用牛顿-拉弗森方法来实现16位和32位整数和小数除法,尽管我们将要讨论的思想可以推广到任何大小的除法。
牛顿-拉弗森技术适用于任何形式为f(x) = 0的方程,其中f(x)是可微函数,其导数为f'(x)。我们从对方程的解x的近似值xn开始。然后我们应用以下迭代方法,以获得更好的近似值xn+1:

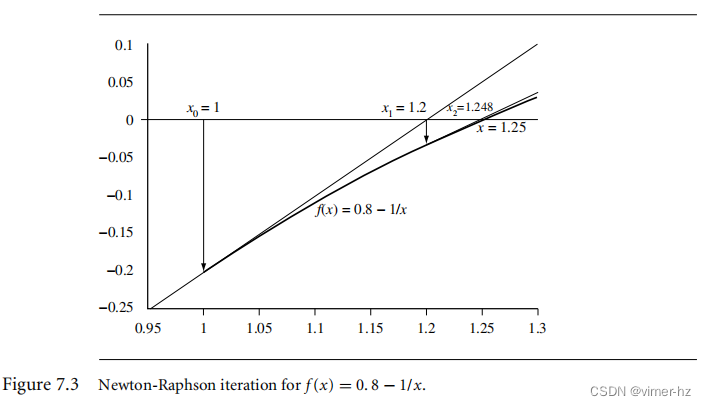
图7.3说明了用于求解f(x) = 0的牛顿-拉弗森迭代。以迅速收敛到解1.25。
我们选择x0 = 1作为初始近似值。前两个步骤是x1 = 1.2和x2 = 1.248。
对于许多函数f,迭代会迅速收敛到解x。从图形上看,我们将估计值xn+1放置在曲线在估计值xn处与x轴相交的位置上。
我们将使用牛顿-拉弗森迭代来仅使用整数乘法运算来计算2N d−1。我们允许乘以2N的因素,因为这在估计232/d时非常有用,正如第7.3.2.1节和第5.10.2节所使用的那样。考虑以下函数:

方程f(x) = 0在x = 2N d−1处有一个解,导数f'(x) = 2N x−2。
通过代入法,可以得到牛顿-拉弗森迭代的表达式:
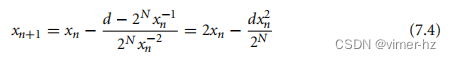
从某种意义上说,迭代将我们的除法翻转了过来。我们不再乘以2N并除以d,而是现在乘以d并除以2N。有两种情况特别有用:
■ 当N = 32且d是一个整数时。在这种情况下,我们可以快速近似计算232d−1,并使用该近似值来计算n/d,即两个无符号32位数的比值。有关使用N = 32的迭代,请参见第7.3.2.1节。
■ 当N = 0且d是以固定点格式表示的分数,满足0.5 ≤ d < 1时。在这种情况下,我们可以使用迭代来计算d−1,这对于计算一系列固定点值n的nd−1很有用。有关使用N = 0的迭代,请参见第7.3.3节。
7.3.2.1 Unsigned 32/32-Bit Divide by Newton-Raphson
本节提供了一个替代第7.3.1.1节中常用例程的方法。以下例程具有非常好的最坏情况性能,并利用了ARM9E上更快的乘法器。我们使用N = 32和整数d的牛顿-拉弗森迭代来近似计算整数232/d。然后,我们将此近似值乘以n并除以232,得到商q = n/d的估计值。最后,我们计算余数r = n − qd,并根据任何舍入误差来纠正商和余数。
q RN 0 ; input denominator d, output quotient q
r RN 1 ; input numerator n, output remainder r
s RN 2 ; scratch register
m RN 3 ; scratch register
a RN 12 ; scratch register
; __value_in_regs struct { unsigned q, r; }
; udiv_32by32_arm9e(unsigned d, unsigned n)
udiv_32by32_arm9e ; instruction number : comment
CLZ s, q
; 01 : find normalizing shift
MOVS a, q, LSL s
; 02 : perform a lookup on the
ADD a, pc, a, LSR#25 ; 03 : most significant 7 bits
LDRNEB a, [a, #t32-b32-64] ; 04 : of divisor
b32 SUBS s, s, #7
; 05 : correct shift
RSB m, q, #0
; 06 : m = -d
MOVPL q, a, LSL s
; 07 : q approx (1 << 32)/d
; 1st Newton iteration follows
MULPL a, q, m
; 08:a= -q*d
BMI udiv_by_large_d ; 09 : large d trap
SMLAWT q, q, a, q
; 10 : q approx q-(q*q*d >> 32)
TEQ m, m, ASR#1
; 11 : check for d=0 or d=1
; 2nd Newton iteration follows
MULNE a, q, m
; 12:a= -q*d
MOVNE s, #0
; 13:s=0
SMLALNE s, q, a, q
; 14:q= q-(q*q*d >> 32)
BEQ udiv_by_0_or_1 ; 15 : trap d=0 or d=1
; q now accurate enough for a remainder r, 0<=r<3*d
UMULL s, q, r, q
; 16:q= (r*q) >> 32
ADD r, r, m
; 17 : r = n-d
MLA r, q, m, r
; 18 : r = n-(q+1)*d
; since 0 <= n-q*d < 3*d, thus -d <= r < 2*d
CMN r, m
; 19 : t = r-d
SUBCS r, r, m
; 20 : if (t<-d || t>=0) r=r+d
ADDCC q, q, #1
; 21 : if (-d<=t && t<0) q=q+1
ADDPL r, r, m, LSL#1 ; 22 : if (t>=0) { r=r-2*d
ADDPL q, q, #2
; 23 :
q=q+2 }
BX lr
; 24 : return {q, r}
udiv_by_large_d
; at this point we know d >= 2∧(31-6)=2∧25
SUB a, a, #4
; 25 : set q to be an
RSB s, s, #0
; 26 : underestimate of
MOV q, a, LSR s
; 27 : (1 << 32)/d
UMULL s, q, r, q
; 28:q= (n*q) >> 32
MLA r, q, m, r
; 29 : r = n-q*d
; q now accurate enough for a remainder r, 0<=r<4*d
CMN m, r, LSR#1
; 30 : if (r/2 >= d)
ADDCS r, r, m, LSL#1 ; 31 : { r=r-2*d;
ADDCS q, q, #2
; 32 : q=q+2; }
CMN m, r
; 33 : if (r >= d)
ADDCS r, r, m
; 34 : { r=r-d;
ADDCS q, q, #1
; 35 : q=q+1; }
BX lr
; 36 : return {q, r}
udiv_by_0_or_1
; carry set if d=1, carry clear if d=0
MOVCS q, r
; 37 : if (d==1) { q=n;
MOVCS r, #0
; 38 :
r=0; }
MOVCC q, #-1
; 39 : if (d==0) { q=-1;
MOVCC r, #-1
; 40 :
r=-1; }
BX lr
; 41 : return {q,r}
; table for 32 by 32 bit Newton Raphson divisions
; table[0] = 255
; table[i] = (1 << 14)/(64+i) for i=1,2,3,...,63
t32 DCB 0xff, 0xfc, 0xf8, 0xf4, 0xf0, 0xed, 0xea, 0xe6
DCB 0xe3, 0xe0, 0xdd, 0xda, 0xd7, 0xd4, 0xd2, 0xcf
DCB 0xcc, 0xca, 0xc7, 0xc5, 0xc3, 0xc0, 0xbe, 0xbc
DCB 0xba, 0xb8, 0xb6, 0xb4, 0xb2, 0xb0, 0xae, 0xac
DCB 0xaa, 0xa8, 0xa7, 0xa5, 0xa3, 0xa2, 0xa0, 0x9f
DCB 0x9d, 0x9c, 0x9a, 0x99, 0x97, 0x96, 0x94, 0x93
DCB 0x92, 0x90, 0x8f, 0x8e, 0x8d, 0x8c, 0x8a, 0x89
DCB 0x88, 0x87, 0x86, 0x85, 0x84, 0x83, 0x82, 0x81证明这段代码有效相当复杂。为了使证明和解释更简单,我们在每条指令上加上行号进行注释。请注意,其中一些指令是有条件的,注释只适用于执行该指令时。
根据分母d的大小,执行会按照代码中的几个不同路径进行。我们将这些情况分别处理。我们将使用Ik作为前述代码中编号为k的指令的简写符号。
情况1:d = 0,ARM9E芯片需要27个时钟周期,包括返回。
我们明确检查了这种情况。通过使加载在q ≠ 0时条件成立,我们避免了I04处的表查找。这确保我们不会读取表的开头。由于I01设置s = 32,因此在I09处没有分支跳转。I06设置m = 0,所以I11设置Z标志并清除进位标志。我们在I15处跳转到特殊情况代码。
情况2:d = 1,ARM9E芯片需要27个时钟周期,包括返回。
这种情况类似于d = 0的情况。I05处的表查找确实发生,但我们忽略了结果。I06设置m = -1,所以I11设置Z和进位标志。I37处的特殊代码返回了q = n,r = 0的平凡结果。
情况3:2 ≤ d < 225,ARM9E芯片需要36个时钟周期,包括返回。
这是最困难的情况。首先,我们使用d的前导位的表查找来生成232/d的估计值。I01找到一个移位s,使得231 ≤ d2s < 232。I02设置a = d2s。I03和I04对a的前七位进行表查找,我们将其称为i0。i0是介于64和127之间的索引。将d截断为七位会引入误差f0:
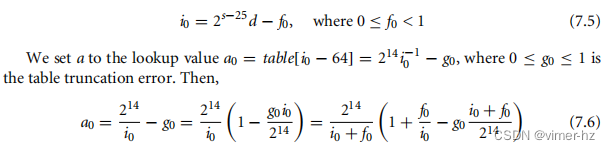

这是232d−1的一个很好的初始近似值,现在我们通过牛顿-拉弗逊迭代两次来增加近似值的精度。I08和I10根据方程(7.9)更新寄存器a和q的值为a1和q1。I08使用m = −d计算a1。由于d ≥ 2,所以当d = 2时q0 < 231,然后f0 = 0,i0 = 64,g0 = 1,e0 = 2−8。因此,我们可以在I10处使用带符号乘加指令SMLAWT来计算q1。
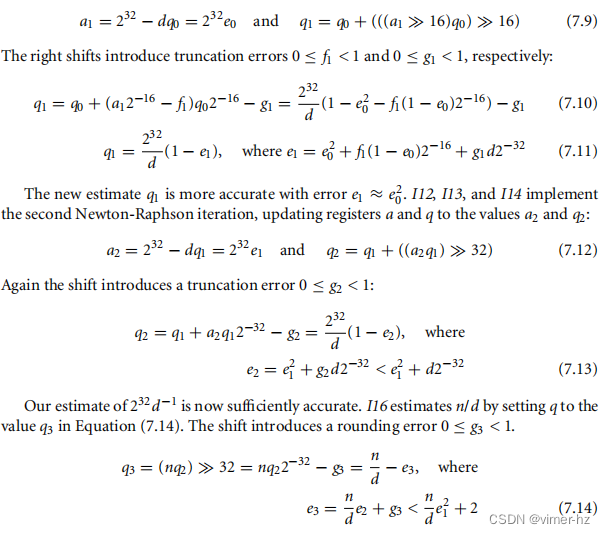
误差e3肯定是正的且很小,但有多小呢?我们将证明0 ≤ e3 < 3,通过证明e2 < d2−32。我们将其拆分为几个子情况:

情况3.1 2 ≤ d ≤ 16
在这种情况下,由于相应的截断没有丢弃任何位,所以f0 = f1 = g1 = 0。因此,e1 = e0/2,并且e0 = i0g02−14。我们可以在表格7.2中明确计算i0和g0。
情况3.2 16 < d ≤ 256
然后f0 ≤ 0.5意味着|e0| ≤ 2−7。由于f1 = g1 = 0,所以e2 < 2−28 < d2−32。
情况3.3 256 <d< 512
然后f0 ≤ 1意味着|e0| ≤ 2−6。由于f1 = g1 = 0,所以e2 < 2−24 < d2−32。
情况3.4 512 ≤ d < 225
然后f0 ≤ 1意味着|e0| ≤ 2−6。因此,e1 < 2−12 + 2−15 + d2−32。设D = √d2−32。那么2−11.5 ≤ D < 2−3.5。因此,e1 < D(2−0.5 + 2−3.5 + 2−3.5) < D,得到所需的结果。
现在我们知道e3 < 3,I16到I23计算了三个可能结果q3、q3 + 1、q3 + 2中哪一个是n/d的正确值。指令计算余数r = n − dq3,并且从余数中减去d,同时增加q,直到0 ≤ r < d。
情况4 225 ≤ d:在ARM9E上需要32个周期,包括返回
这种情况与情况3的开始方式相同。我们有相同的方程用于i0和a0。然而,然后我们在I25处分支,从a0中减去四,并进行一个右移7 − s。这给出了方程(7.15)中的估计q0。减去四迫使q0低估了232d−1。对于一些截断误差0 ≤ g0 < 1:
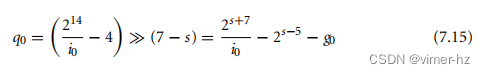

7.3.3 Unsigned Fractional Newton-Raphson Division
这一部分介绍了你可以用来进行分数除法的牛顿-拉弗森(Newton-Raphson)技术。分数值是使用定点算术表示的,对于DSP应用非常有用。
对于分数除法,我们首先将分母缩放到0.5 ≤ d < 1.0的范围内。然后我们使用查找表来提供对d−1的估计值x0。最后,我们使用N = 0进行牛顿-拉弗森迭代。根据第7.3.2节,迭代过程如下:
![]()
随着i的增加,xi变得更加准确。为了实现最快的计算,当i较小时我们使用低精度的乘法运算,并在每次迭代时增加精度。
结果是一个简短而高效的程序。第7.3.3.3节给出了一个用于15位分数除法的例程,而第7.3.3.4节则给出了一个用于31位分数除法的例程。同样,最困难的部分是证明我们对所有可能的输入都能得到正确的结果。对于31位除法,我们无法测试所有的分子和分母的组合。我们必须有一个代码可行性的证明。第7.3.3.1和7.3.3.2节涵盖了我们在第7.3.3.3和7.3.3.4节中所需的数学理论证明。如果你对这个理论不感兴趣,可以直接跳到第7.3.3.3节。
在整个分析过程中,我们坚持以下符号约定:
- d 是一个分数值,缩放后满足 0.5 ≤ d < 1。
- i 是迭代的阶段数。
- ki 是xi使用的精度位数。我们确保 ki+1 > ki ≥ 3。
- xi 是一个ki位的估计值,满足 0 ≤ xi ≤ 2 − 22−ki。
- xi 是 2^(1-ki) 的倍数。
- ei = d - xi 是逼近值xi的误差。我们确保 |ei| ≤ 0.5。
每次迭代时,我们增加ki并减小误差ei。首先让我们看看如何计算一个良好的初始估计值x0。
7.3.3.1 Theory: The Initial Estimate for Newton-Raphson Division
如果你对牛顿-拉弗森理论不感兴趣,可以跳过接下来的两节,直接跳到第7.3.3.3节。
为了确定初始估计值x0到d−1,我们使用一个查找表来处理d的最高有效位。为了在表的大小和估计精度之间获得良好的平衡,我们使用d的前八个小数位作为索引,返回一个九位的估计值x0。由于d和x0的前导位都是1,因此我们只需要一个由128个八位条目组成的查找表。
假设a是由d的前导1后面的七位组成的整数。那么d的范围是 (128 + a)2−8 ≤ d < (129 + a)2−8。选择 c = (128.5 + a)2−8 作为中点,我们通过以下公式定义查找表:
table[a] = round(256.0/c) - 256;
这是一个浮点数公式,其中 round 表示四舍五入到最近的整数。如果你没有浮点数支持,我们可以将其简化为更容易计算的整数公式:
table[a] = (511*(128-a))/(257+2*a);
显然,所有的表项都在0到255的范围内。为了开始牛顿-拉弗森迭代,我们设置 x0 = 1 + table[a]2−8 并且 k0 = 9。现在我们稍微提前看一下第7.3.3.3节的内容。我们将对以下误差项的值感兴趣:

7.3.3.2 Theory: Accuracy of the Newton-Raphson Fraction Iteration
这一节分析了每个小数牛顿-拉弗森迭代引入的误差:
xi+1 = 2xi − dxi^2 (7.26)
精确计算这个迭代通常是很慢的。由于xi的精度最多为ki,所以计算超过2ki位的精度没有太大意义。以下步骤给出了一种实际计算迭代的方法。这些迭代保持了我们在第7.3.3节中定义的xi和ei的限制条件。

7.3.3.3 Q15 Fixed-Point Division by Newton-Raphson
我们计算一个Q15表示的比值nd−1,其中n和d是16位的正整数,范围为0 ≤ n < d < 215。换句话说,我们计算
q = (n << 15)/d;
你可以使用第7.3.1.2节中的udiv_32by16_arm7m例程通过试减法来进行计算。然而,以下例程计算完全相同的结果,但在ARMv5E核心上使用更少的周期。如果你只需要结果的估计值,那么你可以删除指令I15到I18,这些指令纠正了初始估计的误差。
该例程在许多地方都接近不准确,因此后面跟着证明它的正确性。证明使用了第7.3.3.2节的理论。如果代码需要适应或优化为另一个ARM核心,该证明将是一个有用的参考。该例程在ARM9E上需要24个周期,包括返回指令。如果d ≤ n < 215,则返回饱和值0x7fff。
q RN 0 ; input denominator d, quotient estimate q
r RN 1 ; input numerator n, remainder r
s RN 2 ; normalisation shift, scratch
d RN 3 ; Q15 normalised denominator 2∧14<=d<2∧15
; unsigned udiv_q15_arm9e(unsigned d, unsigned q)
udiv_q15_arm9e ; instruction number : comment
CLZ s, q
; 01 : choose a shift s to
SUB s, s, #17
; 02 : normalize d to the
MOVS d, q, LSL s
; 03 : range 0.5<=d<1 at Q15
ADD q, pc, d, LSR#7 ; 04 : look up q, a Q8
LDRNEB q, [q, #t15-b15-128] ; 05 : approximation to 1//d
b15 MOV r, r, LSL s ; 06 : normalize numerator
ADD q, q, #256
; 07 : part of table lookup
; q is now a Q8, 9-bit estimate to 1//d
SMULBB s, q, q
; 08 : s = q*q at Q16
CMP r, d
; 09 : check for overflow
MUL s, d, s
; 10 : s = q*q*d at Q31
MOV q, q, LSL#9
; 11 : change q to Q17
SBC q, q, s, LSR#15 ; 12:q= 2*q-q*q*d at Q16
; q is now a Q16, 17-bit estimate to 1//d
SMULWB q, q, r
; 13 : q approx n//d at Q15
BCS overflow_15
; 14 : trap overflow case
SMULBB s, q, d
; 15 : s = q*d at Q30
RSB r, d, r, LSL#15 ; 16 : r = n-d at Q30
CMP r, s
; 17 : if (r>=s)
ADDPL q, q, #1
; 18 : q++
BX lr
; 19 : return q
overflow_15
LDR q, =0x7FFF
; 20:q= 0x7FFF
BX lr
; 21 : return q
; table for fractional Newton-Raphson division
; table[a] = (int)((511*(128-a))/(257+2*a)) 0<=a<128
t15 DCB 0xfe, 0xfa, 0xf6, 0xf2, 0xef, 0xeb, 0xe7, 0xe4
DCB 0xe0, 0xdd, 0xd9, 0xd6, 0xd2, 0xcf, 0xcc, 0xc9
DCB 0xc6, 0xc2, 0xbf, 0xbc, 0xb9, 0xb6, 0xb3, 0xb1
DCB 0xae, 0xab, 0xa8, 0xa5, 0xa3, 0xa0, 0x9d, 0x9b
DCB 0x98, 0x96, 0x93, 0x91, 0x8e, 0x8c, 0x8a, 0x87
DCB 0x85, 0x83, 0x80, 0x7e, 0x7c, 0x7a, 0x78, 0x75
DCB 0x73, 0x71, 0x6f, 0x6d, 0x6b, 0x69, 0x67, 0x65
DCB 0x63, 0x61, 0x5f, 0x5e, 0x5c, 0x5a, 0x58, 0x56
DCB 0x54, 0x53, 0x51, 0x4f, 0x4e, 0x4c, 0x4a, 0x49
DCB 0x47, 0x45, 0x44, 0x42, 0x40, 0x3f, 0x3d, 0x3c
DCB 0x3a, 0x39, 0x37, 0x36, 0x34, 0x33, 0x32, 0x30
DCB 0x2f, 0x2d, 0x2c, 0x2b, 0x29, 0x28, 0x27, 0x25
DCB 0x24, 0x23, 0x21, 0x20, 0x1f, 0x1e, 0x1c, 0x1b
DCB 0x1a, 0x19, 0x17, 0x16, 0x15, 0x14, 0x13, 0x12
DCB 0x10, 0x0f, 0x0e, 0x0d, 0x0c, 0x0b, 0x0a, 0x09
DCB 0x08, 0x07, 0x06, 0x05, 0x04, 0x03, 0x02, 0x01证明:
该例程首先通过指令I01、I02、I03、I06对d和n进行归一化处理,以使得214 ≤ d < 215。由于我们将分子和分母左移相同的位数,这不会影响结果。将d视为Q15格式的定点小数,其中0.5 ≤ d < 1。
指令I09和I14是溢出陷阱,用于捕捉n ≥ d的情况。这包括了d = 0的情况。假设从现在开始没有溢出,指令I04、I05、I07根据第7.3.1.1节的描述,将q设置为9位Q8初始估计值x0到d−1。由于d在范围0.5 ≤ d < 1内,我们在表查找时减去128,使得0.5对应于表的第一个条目。
接下来,我们执行一次牛顿-拉弗森迭代。指令I08将a设置为x0的精确Q16平方,指令I10将a设置为dx0^2的精确Q31值。这里有一个微妙之处。我们需要检查这个值是否会溢出无符号Q31表示。实际上:
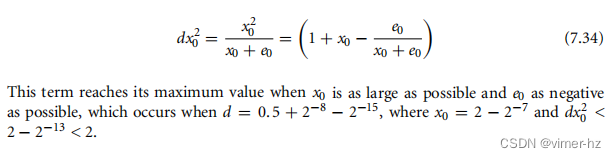

7.3.3.4 Q31 Fixed-Point Division by Newton-Raphson
我们计算nd−1的Q31比例表示,其中n和d是32位正整数,范围为0 ≤ n<d< 231。换句话说,我们计算
q = (unsigned int)(((unsigned long long)n << 31)/d);
您可以使用第7.3.1.3节中的udiv_64by32_arm7m例程通过试减法来完成这个计算。然而,下面的例程计算出完全相同的结果,但在ARM9E上使用较少的周期。如果您只需要一个估计值,那么可以删除指令I21到I29,这些指令纠正了初始估计的错误。
与前一节一样,我们先展示汇编代码,然后进行正确性证明。该例程在ARM9E上使用46个周期,包括返回。该例程使用的查找表与第7.3.3.3节中的Q15例程相同。
q RN 0 ; input denominator d, quotient estimate q
r RN 1 ; input numerator n, remainder high r
s RN 2 ; normalization shift, scratch register
d RN 3 ; Q31 normalized denominator 2∧30<=d<2∧31
a RN 12 ; scratch
; unsigned udiv_q31_arm9e(unsigned d, unsigned q)
udiv_q31_arm9e ; instruction number : comment
CLZ s, q
; 01 : choose a shift s to
CMP r, q
; 02 : normalize d to the
MOVCC d, q, LSL s
; 03 : range 0.5<=d<1 at Q32
ADDCC q, pc, d, LSR#24 ; 04 : look up q, a Q8
LDRCCB q, [q, #t15-b31-128] ; 05 : approximation to 1//d
b31 MOVCC r, r, LSL s
; 06 : normalize numerator
ADDCC q, q, #256
; 07 : part of table lookup
; q is now a Q8, 9-bit estimate to 1//d
SMULBBCC a, q, q
; 08 : a = q*q at Q16
MOVCS q, #0x7FFFFFFF ; 09 : overflow case
UMULLCC s, a, d, a
; 10:a= q*q*d at Q16
BXCS lr
; 11 : exit on overflow
RSB q, a, q, LSL#9 ; 12:q= 2*q-q*q*d at Q16
; q is now a Q16, 17-bit estimate to 1//d
UMULL a, s, q, q
; 13 : [s,a] = q*q at Q32
MOVS a, a, LSR#1
; 14 : now halve [s,a] and
ADC a, a, s, LSL#31 ; 15 : round so [N,a]=q*q at
MOVS s, s, LSL#30 ; 16 : Q31, C=0
UMULL s, a, d, a
; 17 : a = a*d at Q31
ADDMI a, a, d
; 18 : if (N) a+=2*d at Q31
RSC q, a, q, LSL#16 ; 19:q= 2*q-q*q*d at Q31
; q is now a Q31 estimate to 1/d
UMULL s, q, r, q
; 20 : q approx n//d at Q31
; q is now a Q31 estimate to num/den, remainder<3*d
UMULL s, a, d, q
; 21 : [a,s] = d*q at Q62
RSBS s, s, #0
; 22 : [r,s] = n-d*q
RSC r, a, r, LSR#1 ; 23 : at Q62
; [r,s]=(r << 32)+s is now the positive remainder<3*d
SUBS s, s, d
; 24 : [r,s] = n-(d+1)*q
SBCS r, r, #0
; 25 : at Q62
ADDPL q, q, #1
; 26 : if ([r,s]>=0) q++
SUBS s, s, d
; 27 : [r,s] = [r,s]-d
SBCS r, r, #0
; 28 : at Q62
ADDPL q, q, #1
; 29 : if ([r,s]>=0) q++
BX lr
; 30 : return q证明:
我们首先检查n<d。如果不是,则会发生一系列的条件指令,在I11处返回饱和值0x7fffffff。否则,d和n将归一化为Q31表示,230 ≤ d < 231。如同在第7.3.3.3节中一样,I07将q设置为x0的Q8表示,即初始近似值。
I08、I10和I12实现了第一次牛顿-拉弗森迭代。I08将a设置为x0^2的Q16表示。I10将a设置为dx0^2 - g0的Q16表示,其中舍入误差满足0 ≤ g0 < 2^-16。I12将x设置为x1的Q16表示,即对d-1的新估计值。方程(7.33)告诉我们,该估计值的误差为e1 = de2^0 - g0。
I13到I19实现了第二次牛顿-拉弗森迭代。I13到I15将a设置为a1 = x2^1 + b1的Q31表示,其中b1为某个误差。由于我们在I15处使用了ADC指令,计算会向上舍入,因此0 ≤ b1 ≤ 2^-32。ADC指令不会溢出,因为233 - 1和234 - 1都不是完全平方数。然而,a1可能会溢出Q31表示。I16清除进位标志,并在N标志中记录溢出情况,以使a1 ≥ 2。I17和I18将a设置为y1 = da1 - c1的Q31表示,其中舍入误差0 ≤ c1 < 2^-31。由于进位标志被清除,I19将q设置为新的低估的Q31表示:

7.3.4 Signed Division
到目前为止,我们只讨论了无符号除法的实现。如果您需要对有符号值进行除法运算,则将其转换为无符号除法,并将符号重新加回结果中。商值只有在被除数和除数的符号相反时才为负。余数的符号与被除数的符号相同。以下示例展示了如何将有符号整数除法转化为无符号除法,并计算商和余数的符号。
d RN 0 ; input denominator, output quotient
r RN 1 ; input numerator , output remainder
sign RN 12
; __value_in_regs struct { signed q, r; }
; udiv_32by32_arm7m(signed d, signed n)
sdiv_32by32_arm7m
STMFD sp!, {lr}
ANDS sign, d, #1 << 31 ; sign=(d<0 ? 1 << 31 : 0);
RSBMI d, d, #0
; if (d<0) d=-d;
EORS sign, sign, r, ASR#32 ; if (r<0) sign=∼sign;
RSBCS r, r, #0
; if (r<0) r=-r;
BL udiv_32by32_arm7m ; (d,r)=(r/d,r%d)
MOVS sign, sign, LSL#1 ; C=sign[31], N=sign[30]
RSBCS d, d, #0
; if (sign[31]) d=-d;
RSBMI r, r, #0
; if (sign[30]) r=-r;
LDMFD sp!, {pc}我们使用r12寄存器来保存商和余数的符号,因为udiv_32by32_arm7m会保留r12寄存器(参见第7.3.1.1节)。
7.4 Square Roots
平方根可以使用与除法相同的技术来处理。您可以选择使用试减法或基于牛顿-拉弗森迭代的实现方法。对于精度低于16位的低精度结果,可以使用试减法,但对于高精度结果,应切换到牛顿-拉弗森方法。分别在第7.4.1节和第7.4.2节中介绍了试减法和牛顿-拉弗森方法。
7.4.1 Square Root by Trial Subtraction
我们计算一个32位无符号整数d的平方根。答案是一个16位无符号整数q和一个17位无符号余数r,满足以下条件:
![]()
我们从设置q = 0和r = d开始。接下来,我们逐个尝试设置q的每个位,从最高位bit 15开始递减。如果新的余数是正数,我们可以设置该位。具体来说,如果通过将2^n添加到q来设置第n位,那么新的余数将是:
![]()
因此,为了计算新的余数,我们试图减去值2n(2q + 2n)。如果减法成功并得到非负结果,则设置q的第n位。以下是C代码示例,说明了计算2N位输入d的N位平方根q的算法:
unsigned usqr_simple(unsigned d, unsigned N)
{
unsigned t, q=0, r=d;
do
{
/* calculate next quotient bit */
N--;
/* move down to next bit */
t = 2*q+(1 << N); /* new r = old r - (t << N) */
if ( (r >> N) >= t ) /* if (r >= (t << N)) */
{
r -= (t << N); /* update remainder */
q += (1 << N); /* update root */
}
} while (N);
return q;
}使用以下优化的汇编代码来实现前面的算法,只需50个周期,包括返回。关键在于在计算答案的第N位之前,寄存器q保存值(1 << 30)|(q >> (N + 1))。如果我们将该值左旋转2N + 2位,或者等效地右旋转30 − 2N位,那么我们就得到了之前用于试减的值t<<N。
q RN 0 ; input value, current square root estimate
r RN 1 ; the current remainder
c RN 2 ; scratch register
usqr_32 ; unsigned usqr_32(unsigned q)
SUBS r, q, #1 << 30
; is q>=(1 << 15)∧2?
ADDCC r, r, #1 << 30
; if not restore
MOV c, #3 << 30
; c is a constant
ADC q, c, #1 << 31
; set bit 15 of answer
; calculate bits 14..0 of the answer
GBLA N
N SETA 14
WHILE N< >-1
CMP r, q, ROR #(30-2*N) ; is r >= t << N ?
SUBCS r, r, q, ROR #(30-2*N) ; if yes then r -= t << N;
ADC q, c, q, LSL#1
; insert next bit of answer
N SETA (N-1)
WEND
BIC q, q, #3 << 30
; extract answer
MOV pc, lr7.4.2 Square Root by Newton-Raphson Iteration
牛顿-拉弗逊迭代法实际上计算的是值d-0.5的结果,而不是平方根本身。你可能会发现这个结果比平方根本身更有用。例如,要对一个向量(x, y)进行归一化,你可以乘以该向量的倒数的平方根。

如果你确实需要√d,那么只需要将d-0.5乘以d即可。方程f(x) = d-x-2 = 0有一个正解x = d-0.5。用于求解这个方程的牛顿-拉弗逊迭代法如下(参见7.3.2节):
![]()
要实现这个方法,你可以使用我们在7.3.2节中讨论过的相同方法。首先将d归一化到范围0.25 ≤ d < 1。然后使用表格查找d的前导数字生成初始估计x0。迭代上述公式,直到达到你的应用所需的精度。每次迭代将大致使结果精确位数翻倍。 以下代码计算了一个输入整数d的值d-0.5的Q31表示。它使用表格查找,然后进行两次牛顿-拉弗逊迭代,并且在最大误差为2^-29的情况下是准确的。在ARM9E上,该代码需要34个周期,包括返回。
q RN 0 ; input value, estimated reciprocal root
b RN 1 ; scratch register
s RN 2 ; normalization shift
d RN 3 ; normalized input value
a RN 12 ; scratch register/accumulator
rsqr_32 ; unsigned rsqr_32(unsigned q)
CLZ s, q
; choose shift s which is
BIC s, s, #1
; even such that d=(q << s)
MOVS d, q, LSL s ; is 0.25<=d<1 at Q32
ADDNE q, pc, d, LSR#25 ; table lookup on top 7 bits
LDRNEB q, [q, #tab-base-32] ; of d in range 32 to 127
base BEQ div_by_zero ; divide by zero trap
ADD q, q, #0x100 ; table stores only bottom 8 bits
; q is now a Q8, 9-bit estimate to 1/sqrt(d)
SMULBB a, q, q
; a = q*q at Q16
MOV b, d, LSR #17 ; b = d at Q15
SMULWB a, a, b
; a = d*q*q at Q15
MOV b, q, LSL #7 ; b = q at Q15
RSB a, a, #3 << 15 ; a = (3-d*q*q) at Q15
MUL q, a, b
; q = q*(3-d*q*q)/2 at Q31
; q is now a Q31 estimate to 1/sqrt(d)
UMULL b, a, d, q
; a = d*q at Q31
MOV s, s, LSR #1 ; square root halves the shift
UMULL b, a, q, a
; a = d*q*q at Q30
RSB s, s, #15
; reciprocal inverts the shift
RSB a, a, #3 << 30 ; a = (3-d*q*q) at Q30
UMULL b, q, a, q
; q = q*(3-d*q*q)/2 at Q31
; q is now a good Q31 estimate to 1/sqrt(d)
MOV q, q, LSR s ; undo the normalization shift
BX lr
; return q
div_by_zero
MOV q, #0x7FFFFFFF ; maximum positive answer
BX lr
; return q
tab ; tab[k] = round(256.0/sqrt((k+32.3)/128.0)) - 256
DCB 0xfe, 0xf6, 0xef, 0xe7, 0xe1, 0xda, 0xd4, 0xce
DCB 0xc8, 0xc3, 0xbd, 0xb8, 0xb3, 0xae, 0xaa, 0xa5
DCB 0xa1, 0x9c, 0x98, 0x94, 0x90, 0x8d, 0x89, 0x85
DCB 0x82, 0x7f, 0x7b, 0x78, 0x75, 0x72, 0x6f, 0x6c
DCB 0x69, 0x66, 0x64, 0x61, 0x5e, 0x5c, 0x59, 0x57
DCB 0x55, 0x52, 0x50, 0x4e, 0x4c, 0x49, 0x47, 0x45
DCB 0x43, 0x41, 0x3f, 0x3d, 0x3b, 0x3a, 0x38, 0x36
DCB 0x34, 0x32, 0x31, 0x2f, 0x2d, 0x2c, 0x2a, 0x29
DCB 0x27, 0x26, 0x24, 0x23, 0x21, 0x20, 0x1e, 0x1d
DCB 0x1c, 0x1a, 0x19, 0x18, 0x16, 0x15, 0x14, 0x13
DCB 0x11, 0x10, 0x0f, 0x0e, 0x0d, 0x0b, 0x0a, 0x09
DCB 0x08, 0x07, 0x06, 0x05, 0x04, 0x03, 0x02, 0x01类似地,要计算d的-k次方根d^(-1/k),可以使用牛顿-拉弗逊迭代法求解方程f(x) = d - x^(-k) = 0。
7.5 Transcendental Functions: log, exp, sin, cos
您可以通过使用表格查找和级数展开的组合来实现超越函数。我们来看一下最常见的四个超越运算:对数(log),指数(exp),正弦(sin)和余弦(cos)。在数字信号处理(DSP)应用中,对数和指数函数用于在线性和对数格式之间进行转换。而三角函数正弦和余弦在二维和三维图形以及映射计算中非常有用。
本节中的所有示例例程生成的答案精确到32位,这对于许多应用来说是过于精确的。您可以通过缩小级数展开的范围来加快性能,虽然会损失一些精度。
7.5.1 The Base-Two Logarithm
假设我们有一个32位整数n,并且我们想要找到以2为底的对数s = log2(n),使得n = 2^s。由于s在范围0 ≤ s < 32内,我们实际上会找到一个Q26表示q的对数,以便q = s * 2^26。我们可以使用CLZ或第7.2节中的其他方法轻松计算s的整数部分。这将将我们限制在区间1 ≤ n < 2内。首先,我们对近似值a进行表格查找,以找到log2(a)和a−1。

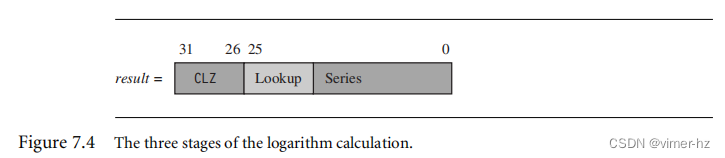
其中ln表示以e为底的自然对数。总结起来,我们通过以下三个阶段计算对数,如图7.4所示:
■ 使用CLZ找到结果的位[31:26]。
■ 使用前五个小数位的表格查找来找到一个近似值。
■ 使用级数展开更准确地计算近似值的误差。
您可以使用以下代码在ARM9E处理器上实现这一过程,其中31个周期不包括返回。答案的误差精度为2的-25次方。
n RN 0 ; Q0 input, Q26 log2 estimate
d RN 1 ; normalize input Q32
r RN 2
q RN 3
t RN 12
; int ulog2_32(unsigned n)
ulog2_32
CLZ r, n
MOV d, n, LSL#1
MOV d, d, LSL r ; 1<=d<2 at Q32
RSB n, r, #31
; integer part of the log
MOV r, d, LSR#27 ; estimate e=1+(r/32)+(1/64)
ADR t, ulog2_table
LDR r, [t, r, LSL#3]! ; r=log2(e) at Q26
LDR q, [t, #4]
; q=1/e at Q32
MOV t, #0
UMLAL t, r, d, r
; r=(d/e)-1 at Q32
LDR t, =0x55555555 ; round(2∧32/3)
ADD n, q, n, LSL#26 ; n+log2(e) at Q26
SMULL t, q, r, t
; q = r/3 at Q32
LDR d, =0x05c551d9 ; round(2∧26/ln(2))
SMULL t, q, r, q
;q=r∧2/3 at Q32
MOV t, #0
SUB q, q, r, ASR#1 ; q = -r/2+r∧2/3 at Q32
SMLAL t, r, q, r
;r-r∧2/2 + r∧3/3 at Q32
MOV t, #0
SMLAL t, n, d, r
; n += r/log(2) at Q26
MOV pc, lr
ulog2_table
; table[2*i] =round(2∧32/a) where a=1+(i+0.5)/32
; table[2*i+1]=round(2∧26*log2(a)) and 0<=i<32
DCD 0xfc0fc0fc, 0x0016e797, 0xf4898d60, 0x0043ace2
DCD 0xed7303b6, 0x006f2109, 0xe6c2b448, 0x0099574f
DCD 0xe070381c, 0x00c2615f, 0xda740da7, 0x00ea4f72
DCD 0xd4c77b03, 0x0111307e, 0xcf6474a9, 0x0137124d
DCD 0xca4587e7, 0x015c01a4, 0xc565c87b, 0x01800a56
DCD 0xc0c0c0c1, 0x01a33761, 0xbc52640c, 0x01c592fb
DCD 0xb81702e0, 0x01e726aa, 0xb40b40b4, 0x0207fb51
DCD 0xb02c0b03, 0x0228193f, 0xac769184, 0x0247883b
DCD 0xa8e83f57, 0x02664f8d, 0xa57eb503, 0x02847610
DCD 0xa237c32b, 0x02a20231, 0x9f1165e7, 0x02bef9ff
DCD 0x9c09c09c, 0x02db632d, 0x991f1a51, 0x02f7431f
DCD 0x964fda6c, 0x03129ee9, 0x939a85c4, 0x032d7b5a
DCD 0x90fdbc09, 0x0347dcfe, 0x8e78356d, 0x0361c825
DCD 0x8c08c08c, 0x037b40e4, 0x89ae408a, 0x03944b1c
DCD 0x8767ab5f, 0x03acea7c, 0x85340853, 0x03c52286
DCD 0x83126e98, 0x03dcf68e, 0x81020408, 0x03f469c27.5.2 Base-Two Exponentiation
这是第7.5.1节操作的逆过程。给定一个表示0 ≤ x < 32的Q26表示形式,我们计算以2为底的指数2^x。我们首先将x分为整数部分n和小数部分d。然后,2^x = 2^d × 2^n。要计算2^d,首先找到一个近似值a来表示d,并查找2^a。
接下来,
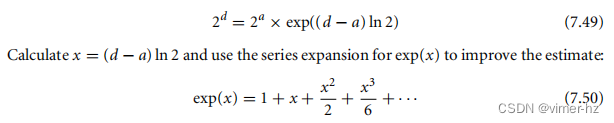
您可以使用以下汇编代码来实现上述算法。结果的最大误差为4。该程序在ARM9E上执行需要31个周期,不包括返回。
n RN 0 ; input, integer part
d RN 1 ; fractional part
r RN 2
q RN 3
t RN 12
; unsigned uexp2_32(int n)
uexp2_32
MOV d, n, LSL#6 ; d = fractional part at Q32
MOV q, d, LSR#27 ; estimate a=(q+0.5)/32
LDR r, =0xb17217f8 ; round(2∧32*log(2))
BIC d, d, q, LSL#27
;d=d- (q/32) at Q32
UMULL t, d, r, d ; d = d*log(2) at Q32
LDR t, =0x55555555 ; round(2∧32/3)
SUB d, d, r, LSR#6
;d=d- log(2)/64 at Q32
SMULL t, r, d, t ; r = d/3 at Q32
MOVS n, n, ASR#26 ; n = integer part of exponent
SMULL t, r, d, r
;r=d∧2/3 at Q32
BMI negative
; catch negative exponent
ADD r, r, d
; r = d+d∧2/3
SMULL t, r, d, r
;r=d∧2+d∧3/3
ADR t, uexp2_table
LDR q, [t, q, LSL#2] ; q = exp2(a) at Q31
ADDS r, d, r, ASR#1
; r = d+d∧2/2+d∧3/6 at Q32
UMULL t, r, q, r ; r = exp2(a)*r at Q31 if r<0
RSB n, n, #31
; 31-(integer part of exponent)
ADDPL r, r, q
; correct if r>0
MOV n, r, LSR n ; result at Q0
MOV pc, lr
negative
MOV r0, #0
; 2∧(-ve)=0
MOV pc, lr
uexp2_table
; table[i]=round(2∧31*exp2(a)) where a=(i+0.5)/32
DCD 0x8164d1f4, 0x843a28c4, 0x871f6197, 0x8a14d575
DCD 0x8d1adf5b, 0x9031dc43, 0x935a2b2f, 0x96942d37
DCD 0x99e04593, 0x9d3ed9a7, 0xa0b05110, 0xa43515ae
DCD 0xa7cd93b5, 0xab7a39b6, 0xaf3b78ad, 0xb311c413
DCD 0xb6fd91e3, 0xbaff5ab2, 0xbf1799b6, 0xc346ccda
DCD 0xc78d74c9, 0xcbec14ff, 0xd06333db, 0xd4f35aac
DCD 0xd99d15c2, 0xde60f482, 0xe33f8973, 0xe8396a50
DCD 0xed4f301f, 0xf281773c, 0xf7d0df73, 0xfd3e0c0d7.5.3 Trigonometric Operations
如果需要低精度的三角函数运算(通常用于生成正弦波和其他音频信号,或者用于图形处理),可以使用查找表。对于高精度图形或全球定位,可能需要更高的精度。我们在这里讨论的例程可以生成32位准确的正弦和余弦值。
标准C库函数sin和cos要求以弧度为单位指定角度。当处理优化的定点函数时,弧度作为单位选择是不方便的。首先,在任何角度相加时,需要在2π范围内执行算术模运算。其次,它需要涉及到π的范围检查,以确定一个角度位于圆的哪个象限。与其模2π运算,我们将模232运算,这是任何处理器上非常简单的操作。
让我们定义新的二进制基数三角函数s和c,其中角度是按照一个完整旋转(2π弧度或360度)为232来指定的。为了添加这些角度,我们使用标准的模整数加法:
![]()
在这个形式中,x是角度所表示的旋转比例的Q32表示。x的前两位告诉我们角度所在的圆的象限。首先,我们使用x的前三位将s(x)或c(x)减少到一个角度在零到1/8个旋转之间的正弦或余弦。然后,我们选择一个近似值a来代替x,并使用表格查找s(a)和c(a)的值。正弦和余弦的加法公式将问题简化为求解一个小角度的正弦和余弦:

您可以使用以下汇编代码来实现上述算法以计算正弦和余弦。结果以Q30格式返回,最大误差为4 × 2^(-30)。这个例程在ARM9E上执行需要31个周期,不包括返回。
n RN 0 ; the input angle in revolutions at Q32, result Q30
s RN 1 ; the output sign
r RN 2
q RN 3
t RN 12
cos_32 ; int cos_32(int n)
EOR s, n, n, LSL#1 ; cos is -ve in quadrants 1,2
MOVS n, n, LSL#1 ; angle in revolutions at Q33
RSBMI n, n, #0 ; in range 0-1/4 of a revolution
CMP n, #1 << 30 ; if angle < 1/8 of a revolution
BCC cos_core ; take cosine
SUBEQ n, n, #1 ; otherwise take sine of
RSBHI n, n, #1 << 31 ; (1/4 revolution)-(angle)
sin_core
; take sine of Q33 angle n
MOV q, n, LSR#25 ; approximation a=(q+0.5)/32
SUB n, n, q, LSL#25 ; n = n-(q/32) at Q33
SUB n, n, #1 << 24 ; n = n-(1/64) at Q33
LDR t, =0x6487ed51 ; round(2*PI*2∧28)
MOV r, n, LSL#3
; r = n at Q36
SMULL t, n, r, t ; n = (x-a)*PI/2∧31 at Q32
ADR t, cossin_tab
LDR q, [t, q, LSL#3]! ; c(a) at Q30
LDR t, [t, #4] ; s(a) at Q30
EOR q, q, s, ASR#31 ; correct c(a) sign
EOR s, t, s, ASR#31 ; correct s(a) sign
SMULL t, r, n, n ; n∧2 at Q32
SMULL t, q, n, q ; n*c(a) at Q30
SMULL t, n, r, s ; n∧2*s(a) at Q30
LDR t, =0xd5555556 ; round(-2∧32/6)
SUB n, s, n, ASR#1 ; n = s(a)*(1-n∧2/2) at Q30
SMULL t, s, r, t ; s=-n∧2/6
at Q32
ADD n, n, q
; n += c(a)*n at Q30
MOV t, #0
SMLAL t, n, q, s ; n += -c(a)*n∧3/6 at Q30
MOV pc, lr
; return n
sin_32;int sin_32(int n)
AND s, n, #1 << 31 ; sin is -ve in quadrants 2,3
MOVS n, n, LSL#1 ; angle in revolutions at Q33
RSBMI n, n, #0 ; in range 0-1/4 of a revolution
CMP n, #1 << 30 ; if angle < 1/8 revolution
BCC sin_core ; take sine
SUBEQ n, n, #1 ; otherwise take cosine of
RSBHI n, n, #1 << 31 ; (1/4 revolution)-(angle)
cos_core
; take cosine of Q33 angle n
MOV q, n, LSR#25 ; approximation a=(q+0.5)/32
SUB n, n, q, LSL#25 ; n = n-(q/32) at Q33
SUB n, n, #1 << 24 ; n = n-(1/64) at Q33
LDR t, =0x6487ed51 ; round(2*PI*2∧28)
MOV r, n, LSL#3
; r = n at Q26
SMULL t, n, r, t ; n = (x-a)*PI/2∧31 at Q32
ADR t, cossin_tab
LDR q, [t, q, LSL#3]! ; c(a) at Q30
LDR t, [t, #4] ; s(a) at Q30
EOR q, q, s, ASR#31 ; correct c(a) sign
EOR s, t, s, ASR#31 ; correct s(a) sign
SMULL t, r, n, n ; n∧2 at Q32
SMULL t, s, n, s ; n*s(a) at Q30
SMULL t, n, r, q ; n∧2*c(a) at Q30
LDR t, =0x2aaaaaab ; round(+2∧23/6)
SUB n, q, n, ASR#1 ; n = c(a)*(1-n∧2/2) at Q30
SMULL t, q, r, t ; n∧2/6 at Q32
SUB n, n, s
; n += -sin*n at Q30
MOV t, #0
SMLAL t, n, s, q ; n += sin*n∧3/6 at Q30
MOV pc, lr
; return n
cossin_tab
; table[2*i] =round(2∧30*cos(a)) where a=(PI/4)*(i+0.5)/32
; table[2*i+1]=round(2∧30*sin(a)) and 0 <= i < 32
DCD 0x3ffec42d, 0x00c90e90, 0x3ff4e5e0, 0x025b0caf
DCD 0x3fe12acb, 0x03ecadcf, 0x3fc395f9, 0x057db403
DCD 0x3f9c2bfb, 0x070de172, 0x3f6af2e3, 0x089cf867
DCD 0x3f2ff24a, 0x0a2abb59, 0x3eeb3347, 0x0bb6ecef
DCD 0x3e9cc076, 0x0d415013, 0x3e44a5ef, 0x0ec9a7f3
DCD 0x3de2f148, 0x104fb80e, 0x3d77b192, 0x11d3443f
DCD 0x3d02f757, 0x135410c3, 0x3c84d496, 0x14d1e242
DCD 0x3bfd5cc4, 0x164c7ddd, 0x3b6ca4c4, 0x17c3a931
DCD 0x3ad2c2e8, 0x19372a64, 0x3a2fcee8, 0x1aa6c82b
DCD 0x3983e1e8, 0x1c1249d8, 0x38cf1669, 0x1d79775c
DCD 0x3811884d, 0x1edc1953, 0x374b54ce, 0x2039f90f
DCD 0x367c9a7e, 0x2192e09b, 0x35a5793c, 0x22e69ac8
DCD 0x34c61236, 0x2434f332, 0x33de87de, 0x257db64c
DCD 0x32eefdea, 0x26c0b162, 0x31f79948, 0x27fdb2a7
DCD 0x30f8801f, 0x29348937, 0x2ff1d9c7, 0x2a650525
DCD 0x2ee3cebe, 0x2b8ef77d, 0x2dce88aa, 0x2cb2324c7.6 Endian Reversal and Bit Operations
本部分介绍了用于操作寄存器内位的优化算法。第7.6.1节介绍了端序反转,这是在小端内存系统中从大端文件读取数据时非常有用的操作。第7.6.2节介绍了在一个字中对位进行置换,例如,翻转位。我们展示了如何支持各种位置换。另请参阅第6.7节,了解有关打包和拆包位流的讨论。
7.6.1 Endian Reversal
//端序反转
为了最大限度地利用ARM核心的32位数据总线,您可能希望一次性以四个字节的方式加载和存储8位和16位数组。然而,如果一次性加载多个字节,则处理器的端序会影响它们在寄存器中出现的顺序。如果这与您所期望的顺序不符,则需要反转字节顺序。
您可以使用以下代码片段来反转一个字内的字节顺序。第一个代码片段使用两个临时寄存器,在常数设置周期之后,每个反转的字需要三个周期。第二个代码片段只使用一个临时寄存器,适用于反转一个单独的字。
n RN 0 ; input, output words
t RN 1 ; scratch 1
m RN 2 ; scratch 2
byte_reverse
;n=[ a, b, c, d ]
MVN m, #0x0000FF00 ; m = [0xFF,0xFF,0x00,0xFF ]
EOR t, n, n, ROR #16 ; t = [ a∧c, b∧d, a∧c, b∧d ]
AND t, m, t, LSR#8
;t=[ 0,a∧c, 0 , a∧c ]
EOR n, t, n, ROR #8 ; n = [ d , c , b , a ]
MOV pc, lr
byte_reverse_2reg
; n = [ a , b , c, d ]
EOR t, n, n, ROR#16
;t=[a∧c, b∧d, a∧c, b∧d ]
MOV t, t, LSR#8
;t=[ 0,a∧c, b∧d, a∧c ]
BIC t, t, #0xFF00
;t=[ 0,a∧c, 0 , a∧c ]
EOR n, t, n, ROR #8 ; n = [ d , c , b , a ]
MOV pc, lrARM桶移位器提供了在一个字内反转半字的功能,因为它与向右旋转16位相同,所以是免费提供的。
7.6.2 Bit Permutations

在第7.6.1节中的字节反转是位置换的一种特殊情况。还有许多其他重要的位置换,您可能会遇到(请参见表7.3):
- 字节反转
- 位反转:交换位k和31-k的值。
- 位扩展:将位间隔开,使得对于k < 16,位k移动到位2k,对于k ≥ 16,位2k - 31。
- DES初始置换:DES代表数据加密标准,它是一种常用的大规模数据加密算法。该算法在加密轮之前和之后对数据应用64位的置换。

编写实现这种置换的优化代码很简单,当您手头上有一个位置换原语的工具箱时,就像我们将在本节中开发的工具箱一样(见表7.4)。它们比逐个检查每个位的循环要快得多,因为它们一次处理32位。
让我们从符号表示开始。假设我们处理一个2k位的值n,并且我们想要对n的位进行置换。那么我们可以使用一个k位索引bk−12k−1 +···+ b12 + b0来表示n中的每个位位置。因此,对于在32位值内部置换位,我们取k = 5。
我们将研究将位于位置bk−12k−1 +···+ b12 + b0的位移动到位置ck−12k−1 +···+ c12 + c0的置换,其中每个ci都是bj或1 − bj。我们用下面的符号表示这种置换:
[bk−1, ... , b1, b0]→[ck−1, ... ,c1,c0] (7.55)
例如,Table 7.3显示了我们迄今为止讨论的置换的符号表示和操作。
这样做的目的是什么呢?实际上,我们可以使用表7.4中的三个基本置换序列来实现任何这些置换。事实上,我们只需要前两个,因为C等于B紧接着A两次。然而,我们可以直接实现C以获得更快的结果。
7.6.2.1 Bit Permutation Macros
以下宏实现了对32位字n的三个置换原语。如果常量值已经在寄存器中设置好,每个置换只需要四个周期。对于更大或更小的宽度置换,相同的思想也适用。
mask0 EQU 0x55555555 ; set bit positions with b0=0
mask1 EQU 0x33333333 ; set bit positions with b1=0
mask2 EQU 0x0F0F0F0F ; set bit positions with b2=0
mask3 EQU 0x00FF00FF ; set bit positions with b3=0
mask4 EQU 0x0000FFFF ; set bit positions with b4=0
MACRO
PERMUTE_A $k
; [ ... b_k ... ]->[ ... 1-b_k ... ]
IF $k=4
MOV n, n, ROR#16
ELSE
LDR m, =mask$k
AND t, m, n, LSR#(1 << $k) ; get bits with index b_k=1
AND n, n, m
; get bits with index b_k=0
ORR n, t, n, LSL#(1 << $k) ; swap them over
ENDIF
MEND
MACRO
PERMUTE_B $j, $k
; [ .. b_j .. b_k .. ] -> [ .. b_k .. b_j .. ] and j>k
LDR m, =(mask$j:AND::NOT:mask$k) ; set when b_j=0 b_k=1
EOR t, n, n, LSR#(1 << $j)-(1 << $k)
AND t, t, m
; get bits where b_j!=b_k
EOR n, n, t, LSL#(1 << $j)-(1 << $k) ; change if bj=1 bk=0
EOR n, n, t
; change when b_j=0 b_k=1
MEND
MACRO
PERMUTE_C $j, $k
; [ .. b_j .. b_k .. ] -> [ .. 1-b_k .. 1-b_j .. ] and j>k
LDR m, =(mask$j:AND:mask$k) ; set when b_j=0 b_k=0
EOR t, n, n, LSR#(1 << $j)+(1 << $k)
AND t, t, m
; get bits where b_j==b_k
EOR n, n, t, LSL#(1 << $j)+(1 << $k) ; change if bj=1 bk=1
EOR n, n, t
; change when b_j=0 b_k=0
MEND7.6.2.2 Bit Permutation Examples
现在,让我们看看这些宏如何在实践中帮助我们。位反转将位置b上的位移动到位置31-b上;换句话说,它会逐个取反五位索引b的每个位。我们可以使用五个A类型的变换来实现位反转,逻辑上依次取反每个位索引位置。
bit_reverse
; n= [ b4 b3 b2 b1 b0 ]
PERMUTE_A 0 ; -> [ b4 b3 b2 b1 1-b0 ]
PERMUTE_A 1 ; -> [ b4 b3 b2 1-b1 1-b0 ]
PERMUTE_A 2 ; -> [ b4 b3 1-b2 1-b1 1-b0 ]
PERMUTE_A 3 ; -> [ b4 1-b3 1-b2 1-b1 1-b0 ]
PERMUTE_A 4 ; -> [ 1-b4 1-b3 1-b2 1-b1 1-b0 ]
MOV pc, lr我们可以使用四个B类型的变换来实现更复杂的位扩展置换。这只需要16个周期(忽略常量设置),比逐个测试每个位的循环要快得多。
bit_spread
; n= [ b4 b3 b2 b1 b0 ]
PERMUTE_B 4,3 ; -> [ b3 b4 b2 b1 b0 ]
PERMUTE_B 3,2 ; -> [ b3 b2 b4 b1 b0 ]
PERMUTE_B 2,1 ; -> [ b3 b2 b1 b4 b0 ]
PERMUTE_B 1,0 ; -> [ b3 b2 b1 b0 b4 ]
MOV pc, lr最后,C类型的置换允许我们同时进行位反转和位扩展,而且使用相同数量的周期。
bit_rev_spread
; n= [ b4 b3 b2 b1 b0 ]
PERMUTE_C 4,3 ; -> [ 1-b3 1-b4 b2 b1 b0 ]
PERMUTE_C 3,2 ; -> [ 1-b3 1-b2 b4 b1 b0 ]
PERMUTE_C 2,1 ; -> [ 1-b3 1-b2 1-b1 1-b4 b0 ]
PERMUTE_C 1,0 ; -> [ 1-b3 1-b2 1-b1 1-b0 b4 ]
MOV pc, lr7.6.3 Bit Population Count
位计数(bit population count)用于统计一个字中设置为1的位数。例如,如果您需要找到中断屏蔽寄存器中设置为1的中断数量,位计数就非常有用。逐个测试每个位的循环速度较慢,因为可以使用ADD指令并行地对位进行求和,前提是求和操作不会相互干扰。"除以三再征服"的方法是将32位的字分割成位三元组。每个位三元组的和是一个范围在0到3的2位数字。我们并行计算这些和,然后以对数方式求和。使用以下代码进行单个字的位计数。该操作需要10个周期,并加上2个周期用于常量设置。
bit_count
; input n = xyzxyzxyzxyzxyzxyzxyzxyzxyzxyzxy
LDR m, =0x49249249 ; 01001001001001001001001001001001
AND t, n, m, LSL #1 ; x00x00x00x00x00x00x00x00x00x00x0
SUB n, n, t, LSR #1 ; uuzuuzuuzuuzuuzuuzuuzuuzuuzuuzuu
AND t, n, m, LSR #1 ; 00z00z00z00z00z00z00z00z00z00z00
ADD n, n, t ; vv0vv0vv0vv0vv0vv0vv0vv0vv0vv0vv
; triplets summed, uu=x+y, vv=x+y+z
LDR m, =0xC71C71C7 ; 11000111000111000111000111000111
ADD n, n, n, LSR #3 ; ww0vvwww0vvwww0vvwww0vvwww0vvwww
AND n, n, m ; ww000www000www000www000www000www
; each www is the sum of six adjacent bits
ADD n, n, n, LSR #6 ; sum the w’s
ADD n, n, n, LSR #12
ADD n, n, n, LSR #24
AND n, n, #63 ; mask out irrelevant bits
MOV pc, lr7.7 Saturated and Rounded Arithmetic
饱和操作可以将结果剪裁到一个固定的范围内,以防止溢出。您最有可能需要16位和32位的饱和操作,其定义如下:
■ 饱和16(x) = x 剪裁到范围 -0x00008000 到 +0x00007fff(包括两端)
■ 饱和32(x) = x 剪裁到范围 -0x80000000 到 +0x7fffffff(包括两端)
尽管您可以将16位饱和示例转换为8位饱和或任何其他长度,但我们将集中讨论这些操作。以下各节给出了您可能需要的基本饱和和舍入操作的标准实现。它们使用了一个标准技巧:对于一个32位有符号整数x,x >> 31 = sign(x) = -1(如果x < 0)和0(如果x ≥ 0)。
7.7.1 Saturating 32 Bits to 16 Bits
这个操作在DSP应用中经常出现。例如,声音采样通常在存储到内存之前被饱和到16位。这个操作需要3个周期,前提是一个常量m在寄存器中事先设置好。
; b=saturate16(b)
LDR m, =0x00007FFF ; m = 0x7FFF maximum +ve
MOV a, b, ASR#15
; a = (b >> 15)
TEQ a, b, ASR#31 ; if (a!=sign(b))
EORNE b, m, b, ASR#31 ; b = 0x7FFF ∧ sign(b)7.7.2 Saturated Left Shift
在信号处理中,可能会导致溢出的左移操作需要对结果进行饱和处理。这个操作对于一个常量的位移需要三个周期,对于一个变量位移c则需要五个周期。
; a=saturate32(b << c)
MOV m, #0x7FFFFFFF ; m = 0x7FFFFFFF max +ve
MOV a, b, LSL c ; a = b << c
TEQ b, a, ASR c ; if (b != (a >> c))
EORNE a, m, b, ASR#31 ; a = 0x7FFFFFFF∧sign(b)7.7.3 Rounded Right Shift
一个舍入右移操作对于一个常量的位移需要两个周期,对于一个非零的变量位移需要三个周期。请注意,如果进位标志清除,零变量位移才能正常工作。
; a=round(b >> c)
MOVS a, b, ASR c
; a = b >> c, carry=b bit c-1
ADC a, a, #0 ; if (carry) a++ to round7.7.4 Saturated 32-Bit Addition and Subtraction
在ARMv5TE核心上,新的指令QADD和QSUB提供了饱和加法和减法。如果您使用的是ARMv4T或更早版本的核心,则可以使用以下代码序列替代。该代码需要两个周期和一个保持常量的寄存器。
; a = saturate32(b+c)
MOV m, #0x80000000 ; m = 0x80000000 max -ve
ADDS a, b, c
; a = b+c, V records overflow
EORVS a, m, a, ASR#31 ; if (V) a=0x80000000∧sign(a)
; a = saturate32(b-c)
MOV m, #0x80000000 ; m = 0x80000000 max -ve
SUBS a, b, c
; a = b-c, V records overflow
EORVS a, m, a, ASR#31 ; if (V) a=0x80000000∧sign(a)7.7.5 Saturated Absolute
如果输入参数是 -0x80000000,绝对值函数会发生溢出。以下的两个周期的代码序列处理了这种情况:
; a = saturate32(abs(b))
SUB a, b, b, LSR #31 ; a = b - (b<0)
EOR a, a, a, ASR #31 ; a = a ∧ sign(a)在类似的情况下,一个累积的、非饱和的绝对值函数也需要两个周期:
; a = b+abs(c)
EORS a, c, c, ASR#32
;a=c∧sign(c) = abs(c)-(c<0)
ADC a, b, a
;a=b+a+ (c<0)7.8 Random Number Generation
要生成真正的随机数,需要特殊的硬件作为随机噪声的来源。然而,对于许多计算机应用程序(如游戏和建模),生成速度比统计纯度更为重要。这些应用程序通常使用伪随机数。
伪随机数实际上并不是真正的随机数;它们是由一个重复的序列生成的数字。然而,该序列非常长,并且分散得很广,使得这些数字看起来是随机的。通常,我们通过迭代一个关于 Rk−1 的简单函数来获取伪随机序列的第 k 个元素 Rk:
![]()
为了获得快速的伪随机数生成器,我们需要选择一个容易计算并且输出看起来随机的函数 f(x)。在重复之前,序列必须非常长。对于一个32位数字的序列而言,最长的长度显然是 2^32。
线性同余生成器使用以下形式的函数:
f(x) = (a*x+c) % m;
这些函数在《Knuth, Seminumerical Algorithms》的3.2.1节和3.6节中有详细研究。为了进行快速计算,我们希望取 m = 2^32。《Knuth》中的理论保证,如果 a%8 = 5 并且 c = a,则生成的序列具有 2^32 的最大长度,并且很可能看起来是随机的。例如,假设 a = 0x91e6d6a5。那么下面的迭代将生成一个伪随机序列:
MLA r, a, r, a ; r_k = (a*r_(k-1) + a) mod 2^32
由于 m 是2的幂,序列的低位并不是很随机。使用高位来生成较小范围内的伪随机数。例如,设置 s = r << 28 来生成一个范围在0到15之间的四位随机数 s。更一般地,以下代码可以生成一个介于0和n之间的伪随机数:
; r is the current random seed
; a is the multiplier (eg 0x91E6D6A5)
; n is the random number range (0...n-1)
; t is a scratch register
MLA r, a, r, a ; iterate random number generator
UMULL t, s, r, n ; s = (r*n)/2∧32
; r is the new random seed
; s is the random result in range 0 ... n-17.9 Summary
ARM指令只实现了简单的基本操作,如加、减和乘法。要执行更复杂的操作,如除法、平方根和三角函数,需要使用软件例程。有许多有用的技巧和算法来提高这些复杂操作的性能。本章介绍了一些标准操作的算法和代码示例。
标准技巧包括:
■ 使用二分查找或试减法计算小商
■ 使用牛顿-拉夫逊迭代快速计算倒数和提取根号
■ 使用表查找和级数展开的组合来计算超越函数,如exp,log,sin和cos
■ 使用带有桶位移动的逻辑操作执行比逐个测试位更高效的位置换
■ 使用乘积累加指令生成伪随机数
















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









