






 本文是对《机器学习实战》的总结,涵盖了监督学习的分类与回归算法,包括kNN、决策树、朴素贝叶斯、逻辑回归、支持向量机、AdaBoost等。此外,还涉及回归、聚类、降维方法以及机器学习基本流程和关键概念。
本文是对《机器学习实战》的总结,涵盖了监督学习的分类与回归算法,包括kNN、决策树、朴素贝叶斯、逻辑回归、支持向量机、AdaBoost等。此外,还涉及回归、聚类、降维方法以及机器学习基本流程和关键概念。
最近一段时间读了Peter Harrington 的Machine learning in action,对机器学习有个大致的了解,做个总结。
一、书的组织结构
全书分为4部分:监督学习(分类、回归)、无监督学习、其他工具。包含算法原理解释,并讲解Python实现算法的流程。读完能对机器学习方法有个大致了解。我主要细看第一部分,快速浏览了后面部分。
分类
- kNN
- 计算输入实例与训练集中各实例的距离,选出K个最近邻训练实例点,然后根据这K个点多数类进行分类。
- 三要素:k值选择、距离度量、分类决策规则
- 决策树
- 根据数据的属性采用树状结构建立决策模型
- 本书介绍了分类回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3),使用更广泛的还有C4.5
- 重要概念:
- 信息的定义: l(xi)=−log2p(xi)
- 信息熵:所有类别所有可能值包含的信息期望值:
H=−∑i=1np(xi)log2p(xi)
- 信息熵增益:目标指数的熵与特征值的熵之差
- 朴素贝叶斯
- 选择高概率对应的类别(朴素:特征值相互独立)
- 贝叶斯准则: p(c|x)=p(x|c)p(c)p(x)
- 下溢问题:通过对概率取对数解决
- 逻辑回归(Logistic Regression,LR)
- 根据现有数据对分类边界建立回归公式,以此来分类
- 数学形式:阶跃函数,以Sigmoid函数近似表示 σ=11+e−z
- 求解最佳回归系数可使用的优化算法:梯度上升算法、随机梯度上升
- 支持向量机(Support Vector Machines,SVM)
- 思想:求解最大化分隔超平面,以此完成分类
- 重要概念:
- 线性可分
- 支持向量:距离分隔超平面最近的点
- 拉格朗日乘子法:使约束条件易求
- 松弛变量:数据集不可能100%线性可分,引入松弛变量C使得部分数据点可以处在分隔面的错误一侧。
- AdaBoost元算法
- 思想:组合多个弱分类器的结果,成为集成方法或元方法
- 集成方法:boosting 和 bagging
- Adaboost:以弱分类器为基础分类器,并且输入数据,使其通过权重量进行加权。在第一次迭代当中,所有数据等权重,在后续的迭代中,增大前次迭代分错的数据。
- kNN
- 回归:对连续型数据进行预测
- 线性回归:求解最佳拟合直线,利用OLS(普通最小二乘)确定回归系数
- 局部加权线性回归:利用核函数对附近的点赋予更高的权重,常用高斯核
- 树回归
- 聚类:
- k均值聚类:随机确定K个初始点为质心,为每个点寻找最近的质心并归为质心所在的簇;更新簇的质心为该簇所有点的平均值;一直迭代直到所有点的簇分类不变
- 二分 k均值聚类:先将所有点分为一个簇,然后一分为二,选择能最大程度减小SSE(误差平方和)值得簇再一分为二,一直迭代直到得到K个簇
- Apriori算法:频繁项集(经常一起出现的物品的集合)、关联规则(具有很强联系的物品)分析。原理:如果一个项目集合不是频繁集合,那么任何包含它的项目集合也一定不是频繁集合
- FP growth算法:利用Apriori原理,构建FP树,只需遍历数据库两次,找出频繁项集
- 降维去噪:选取影响较大的特征
- 主成分分析(PCA):数据从原来的坐标系转换到新的坐标系。新的坐标系的第一个坐标轴为原始数据集方差最大的方向,第二个坐标轴为与第一个坐标轴正交且具有最大方差方向,一直重复
- 奇异值分解(SVD):SVD将矩阵分解为三个矩阵的乘积
Datam×n=Um×nΣm×nVTn×n中间的矩阵sigma为对角矩阵,对角元素的值为Data矩阵的奇异值(注意奇异值和特征值是不同的),且已经从大到小排列好了。即使去掉特征值小的那些特征,依然可以很好的重构出原始矩阵。
二、机器学习方法基本流程
1.采集数据:采集解决问题所需的数据
2.准备数据:将数据转化为便于处理的正确格式
3.分析数据:可视化数据,对数据特征进行分析
4.训练算法:将问题转化为数学模型,编码实现
5.测试算法:对算法进行测试验证,进行优化
6.使用算法:将算法应用到实际系统中,解决问题
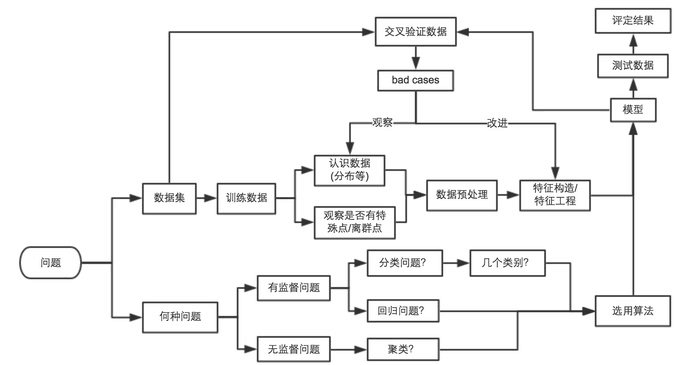
三、一些概念
缺失值处理:1.以可用特征的平均值填补;2以相似特征的平均值来填补;3.用特殊值来填补,如1、0;4.忽略有缺失值的样本;5.用其他机器学习算法预测缺失值;
可视化:利用matplotlib等对数据进行可视化,有利于数据特征分析
核函数:将数据从一个低维空间线性不可分映射到一个高维空间线性可分,最常用的径向基函数
非均衡分类问题:正负样本相差很大,解决方法:欠抽样、过抽样
分类性能指标:错误率、正确率、召回率及ROC曲线















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









