







python实现的全连接层:
class FC:
def __init__(self,in_num,out_num,lr=0.01):
self.in_num=in_num
self.out_num=out_num
self.w=numpy.random.randn(out_num,in_num)*10
self.b=numpy.zeros(out_num)
self.lr=lr
def _sigmold(self, in_data):
return 1/(1+numpy.exp(-in_data))
def forward(self, in_data):
self.topVal=self._sigmold(numpy.dot(self.w,in_data)+self.b)
self.bottomVal=in_data
return self.topVal全连接层的主要计算类型为矩阵向量乘(GEMV)。
caffe中全连接层直接将前一层的输出展开为一维向量,如果前一层的输出维度为 64 x 50 x 4 x 4,全连接层对应的输入向量的维度为 50*4*4=800。
import numpy
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def draw3D(X,Y,Z,angle):
fig=plt.figure(figsize=(15,7))
ax=Axes3D(fig)
ax.view_init(angle[0],angle[1])
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,cmap='rainbow')
plt.show()
x=numpy.linspace(-10,10,100)
y=numpy.linspace(-10,10,100)
X,Y=numpy.meshgrid(x,y)
X_f=X.flatten()
Y_f=Y.flatten()
data=zip(X_f,Y_f)
fc=FC(2,3)
fc.w=numpy.array([[0.4, 0.6],[0.3,0.7],[0.2,0.8]])
fc.b=numpy.array([0.5,0.5,0.5])
fc2 = FC(3, 1)
fc2.w = numpy.array([0.3, 0.2, 0.1])
fc2.b = numpy.array([0.5])
z1=numpy.array([fc.forward(d) for d in data])
z2=numpy.array([fc2.forward(d) for d in z1])
z2=z2.reshape(100,100)
draw3D(X,Y,z2,(40,-45))
上述代码实现了两个全连接层组成的神经网络。效果图:
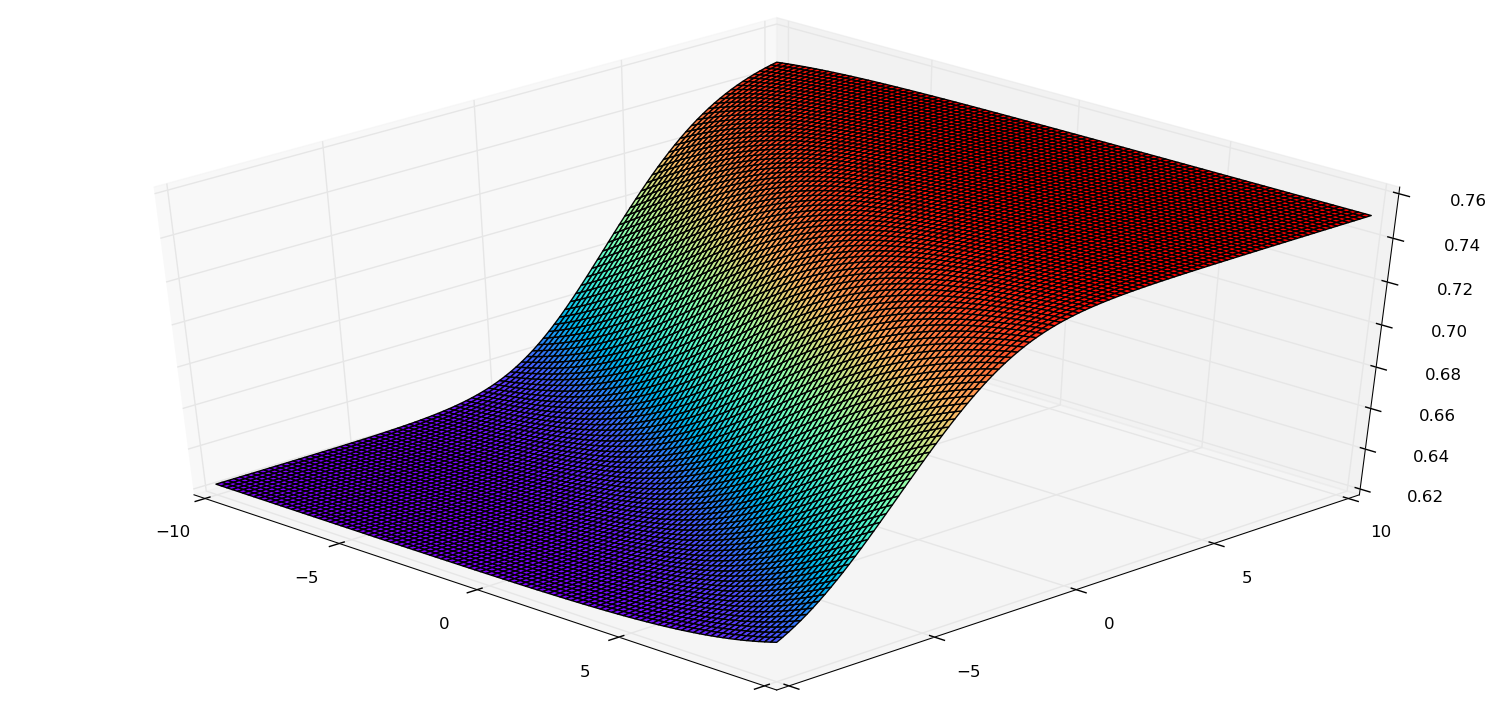
全连接层的具体含义:
作者:冯超 链接:https://zhuanlan.zhihu.com/p/21525237 来源:知乎
反向传播
实际中,计算和训练都是一批一批完成的。大多数机器学习训练都有batch的概念,而训练中batch的计算不是一个一个地算,而是一批数据集中算,那么就需要用上矩阵了。
参考:
作者:冯超 链接:https://zhuanlan.zhihu.com/p/21572419 来源:知乎
所有相关的训练数据和参数做以下的约定:
- 所有的训练数据按列存储,也就是说如果把N个数据组成一个矩阵,那个矩阵的行等于数据特征的数目,矩阵的列等于N
- 线性部分的权值w由一个矩阵构成,它的行数为该层的输入个数,列数为该层的输出个数。如果该层的输入为2,输出为4,那么这个权值w的矩阵就是一个2*4的矩阵。
- 线性部分的权值b是一个行数等于输出个数,列数为1的矩阵。
import numpy
class SquareLoss:
def forward(self,y,t):
self.loss=y-t
return numpy.sum(self.loss*self.loss) / self.loss.shape[1] / 2
def backward(self):
return self.loss
class FC:
def __init__(self,in_num,out_num,lr=0.1):
self.in_num=in_num
self.out_num=out_num
self.w=numpy.random.randn(in_num,out_num)
self.b=numpy.zeros((out_num,1))
self.lr=lr
def _sigmold(self, in_data):
return 1/(1+numpy.exp(-in_data))
def forward(self, in_data):
self.topVal=self._sigmold(numpy.dot(self.w.T,in_data)+self.b)
self.bottomVal=in_data
return self.topVal
def backward(self,loss):
grad_z=loss * self.topVal * (1-self.topVal)
grad_w=numpy.dot(self.bottomVal, grad_z.T)
grad_b=numpy.sum(grad_z)
self.w -= self.lr*grad_w
self.b -= self.lr*grad_b
grad_x=numpy.dot(grad_w,grad_z)
return grad_x
class Net:
def __init__(self,input_num=2,hidden_num=4,out_num=1,lr=0.1):
self.fc1=FC(input_num,hidden_num,lr)
self.fc2=FC(hidden_num,out_num,lr)
self.loss=SquareLoss()
def train(self, X, y): #X are arraged by col
for i in range(10000):
#forward step
layer1out=self.fc1.forward(X)
layer2out=self.fc2.forward(layer1out)
loss =self.loss.forward(layer2out,y)
#backward step
layer2loss=self.loss.backward()
layer1loss=self.fc2.backward(layer2loss)
saliency=self.fc1.backward(layer1loss)
layer1out=self.fc1.forward(X)
layer2out=self.fc2.forward(layer1out)
loss =self.loss.forward(layer2out,y)
print 'X={0}'.format(X)
print 't={0}'.format(y)
print 'y={0}'.format(layer2out)
print 'loss={0}'.format(loss)
X=numpy.array([[0,0],[0,1],[1,0],[1,1]]).T
y=numpy.array([[0],[0],[0],[1]]).T
net=Net(2,4,1,0.1)
net.train(X,y)















 1687
1687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









