







 本文深入探讨了数据挖掘中的多层次关联规则,包括定义、level-reduced min-support、group-based “individualized” min-support和冗余规则。接着讨论了多维度、量化及负相关的关联规则挖掘,涉及静态离散化、数据立方、偏差分析以及负模式的两种定义。文章还触及了压缩模式的概念,强调了在大量相似模式中寻找有意义且低冗余的规则的重要性。
本文深入探讨了数据挖掘中的多层次关联规则,包括定义、level-reduced min-support、group-based “individualized” min-support和冗余规则。接着讨论了多维度、量化及负相关的关联规则挖掘,涉及静态离散化、数据立方、偏差分析以及负模式的两种定义。文章还触及了压缩模式的概念,强调了在大量相似模式中寻找有意义且低冗余的规则的重要性。
挖掘多层次的关联规则(Mining Multi-Level Associations)
定义
项经常形成层次。
如图所示
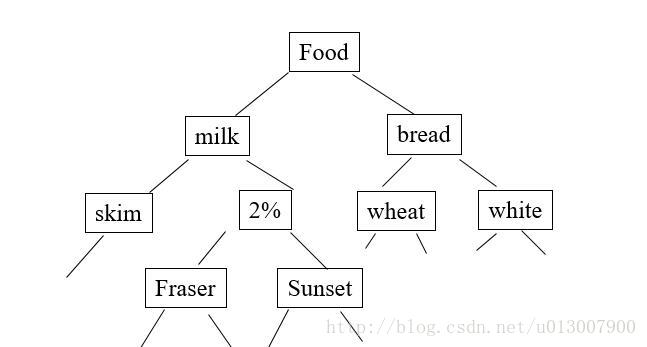
那么我们可以根据项的细化分类得到更多有趣的模式,发现更多细节的特性。
Level-reduced min-support
使用的是Level-reduced min-support方法来设置最低支持度,即,越低的层有着越低的支持度。
假设我们使用的是统一的最低支持度,那么如果支持度过低,低层的频繁项集就会较少,导致很多特性显示不出来;如果支持度过高,高层的频繁项集就过多,导致过多无用的特性被展示出来。
group-based “individualized” min-support
不同种类的物品对应的最低支持度应该是不同的,比如钻石等贵重物品出现的频率肯定是低于牛奶面包等日常用品的。
所以应该分组设置最低支持度。
Shared multi-level mining
使用最低层次的支持度来计算和传递候选集。也就是使用的是所有层中支持度最小的。
因为这样可以保证挖掘出的关联规则不会减少。
冗余规则(redundant rules)
挖掘多层关联规则时,由于项之间的“父子”关系,有些发现的规则是冗余的。
例如
已知, 14 的milk销售的是2%milk。
milk→wheatbread [support = 8%, confidence = 70%]
2%milk→wheatbread [support = 2%, confidence = 72%]
我们可以发现,第一个规则是第二个规则的祖先。而我们可以根据第一个规则的值以及比例放缩,计算出第二个规则的期望。而如果一个规则的支持度和置信度都接近“期望值”,那么我们称之为冗余规则。
挖掘多维度的关联规则(Mining Multi-Dimensional Associations)
- 单维规则:
- buys(X,"milk")→buys(X,"bread")
- 可写成形如 milk→bread 的boolean关联规则
- 多维规则:2维 或者 断言
- 维间关联规则 (no repeated predicates)
- age(X,"19−25")∧occupation(X,"student")→buys(X,"coke")
- 混合维关联规则 (repeated predicates)
- age(X,"19−25")∧buy
- 维间关联规则 (no repeated predicates)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









