







作者:数据与智能
链接:https://www.zhihu.com/question/307051604/answer/2146800423
1. 什么是词嵌入?及为什么要这么做?
机器学习和深度学习等统计算法处理数字。要对文本应用统计算法,你需要将文本转换为数字。例如,你不能将两个词 apples 和 oranges加起来。你需要将文本转换为数字才能对单词应用数学运算。
将文本转换为数字的过程,主要以向量的形式,称为词嵌入。在本章中,你将看到一些最常见的词嵌入方法。以下是一些最常见的词嵌入方法:
- 词袋
- N-Gram
- TFIDF 方法
- Word2Vec
在本章中,你将了解这些方法背后的理论,还将了解如何使用 Python 实现这些方法。
2. 词袋方法
Bag of Words (BOW) 是最熟悉和最古老的将单词转换为数字的方法之一。
词袋方法非常简单。让我用一个例子来解释它。
假设你有一个包含以下句子的语料库:

上面的语料库包含三个句子。词袋方法按以下步骤工作:
1. 创建一个包含语料库中所有文档中所有唯一词的词典。我们的语料库的字典看起来像这样。你可以看到字典里有11个唯一的词语。

2. 为步骤 1 中创建的词典中的每个唯一单词分配一个索引号。你可以分配任何索引号。索引号最好从 0 开始。假设我们将以下索引号分配给字典中的单词。

3. 对于原始语料库中的每个句子或文档,创建一个全为 0 的 N 维向量,其中 N 是包含该语料库词汇的词典中的单词数。在我们的例子中,我们将创建三个全为 0 的 11 维向量。
4. 对于原句中的每个词,如果该词存在于唯一词词典中,则将句子中该词的频率加到对应的11维向量索引处,如唯一词词典中所述。例如,我们语料库中的第一句话是:“He likes to watch movies.。”唯一词词典中第一个单词“He”的索引为4。由于单词“He”在句子中只出现一次,因此在该句子的11维向量中,第4个指数会加1。同样,“likes to watch movies”这个词的索引是6、8、9、7,因此这些索引会加1。句子“He likes to watch movies”的最终的词袋向量将是:[0 0 0 0 1 0 1 1 1 1 0]。请记住,索引号从 0 开始。因此,第 4 个索引实际上将位于 BOW 向量中的第 5 个位置。同样,对于句子“French movies are good to watch movies”,BOW 向量将如下所示:[1 0 1 1 0 0 0 2 1 1 0]。在上面的向量中,你可以在第七个索引处看到 2。这是因为第七个索引是为我们字典中的“movies”这个词保留的。由于“movies”这个词在句子中出现了两次,因此数字 2 被添加到第 7 个索引中。
现在让我们看看如何使用 Python 的 SKlearn 库创建词袋模型。
要使用 SKlearn 库创建词袋模型,你可以使用 sklearn.feature_extraction.text 模块中的 CountVectorizer 类。你需要将句子的语料库传递给 fit() 方法,如下所示。
接下来,要查看独特单词的词汇表,你可以使用vocabulary_attribute,如下图:

在以下输出中,你可以看到语料库中的唯一词以及分配给这些词的索引。

fit 方法只创建一个包含索引的唯一单词的字典。要将文本文档转换为词袋向量,你需要将句子传递给CountVectorizer 对象的 transform() 方法,如图下。要显示向量,你可以对每个单独的向量调用 toArray() 方法。


你还可以在创建 CountVectorizer 对象时删除停用词。你可以将停用词列表传递给“stop_words”属性。列表中传递的停用词不会添加到词汇词典中。这是一个例子。

以下脚本打印没有停用词的词袋词向量。

词袋方法的主要优点之一是它不需要大量数据来训练。此外,词袋方法很容易理解。
BOW 方法的一个主要缺点是,在大型语料库的情况下,字典的大小呈指数增长,导致矩阵稀疏。例如,如果你的语料库有一万个唯一词,则语料库中的每个文档都将用一个万维向量表示。即使句子包含 20 个单词,也必须用一万维向量来表示,从而导致巨大的空间损失。
词袋方法的另一个问题是它无法保留任何上下文信息。例如,句子“John likes cats”和“Cats likes John”将具有相同的 BOW 向量。上下文信息可以通过 N-Grams 方法部分保留。
3. N-Grams方法
在 N-Grams 方法中,不是创建唯一词字典,而是创建唯一 n-gram 字典,其中 N 可以是任意数字。例如,对于句子“He likes to eat mangoes”,字典 2-grams(也称为 bigrams)将是:

相似的,3-grams(也叫做trigrams)会像下面这样:

该过程的其余部分类似于 BOW 方法。
让我们看看如何使用 Sklearn 创建 N-Gram。为此,你可以再次使用sklearn.feature_extraction.text 模块中的 CountVectorizer 类。要指定 N-Gram 的范围,你可以使用 ngram_range 属性。它接受一个有两个数字的元组。
第一个数字是 n-gram 的下限,第二个数字对应于上限。在以下脚本中,你将看到如何使用 2-gram 方法创建数值向量。
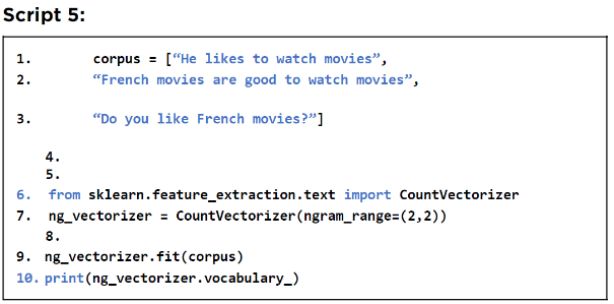
输出显示包含输入句子的 2-gram 的字典。与 BOW 一样,为每个 2-gram 分配一个索引。

接下来,你可以将输入的句子转换为 N-gram使用 CountVectorizer 的 transform() 方法,如下所示:


N-grams 方法的优点类似于 Bag of Words 方法。此外,使用 N-grams 方法,你可以保留一些上下文信息。
N-grams 方法的主要缺点之一是这种方法不太适合学习长的短语。
4. TF-IDF 方法
TF-IDF 方法类似于词袋方法。然而,与词袋不同的是,结果数值向量包含句子中词的 TF-IDF 值,而不是出现频率。
TF 指的是词频率,而 IDF 指的是逆文档频率。
词频率很容易计算:
TF = 词在文档中出现的次数。另一方面,IDF 计算如下:

计算 TF-IDF 背后的想法是,在特定文档中出现较多而在所有文档中出现较少的词是唯一的,因此与所有文档中出现并且常见的词相比,应该给予更高的权重。
让我们试着用例子找出 IDF 值。假设我们有以下语料库:

让我们试着找出单词 Likes 的 IDF 值。“Likes”这个词:

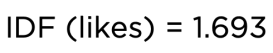
也可以使用此对数值。但是,Sklearn 使用标准化的 TF-IDF 值。以下公式用于计算特定文档中单词的最终归一化 TF-IDF 值。这里,n 是文档中的总单词数。

假设去除了停用词“He”和“to”,我们在第一个文档中只剩下三个词,即“likes”、“watch”和“movies”。第一个句子中单词 likes 的最终归一化 TF-IDF 值可以计算为:
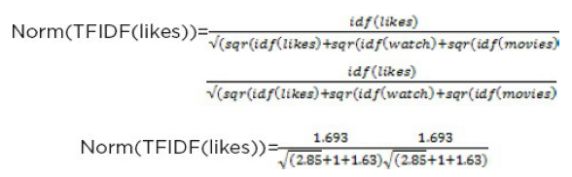

单词 likes 的最终归一化 TF-IDF 值为 0.72。
现在让我们看看如何使用 SKlearn 库构建 TF-IDF 模型。为此,你可以使用来自 sklearn.feature_extraction.text 的TfIdfVectorizer。过程是一样的。首先,你必须在语料库上调用 fit() 方法,然后调用 transform() 方法。此外,你可以传递“stop_words =‘english’”作为属性以自动从文本中删除停用词。创建包含语料库中唯一词的词汇词典的第一步如下所示:


接下来,你可以使用 toarray() 方法打印语料库中所有文档的 TF-IDF 值。

让我们打印语料库中每个唯一单词的 TF-IDF 值。
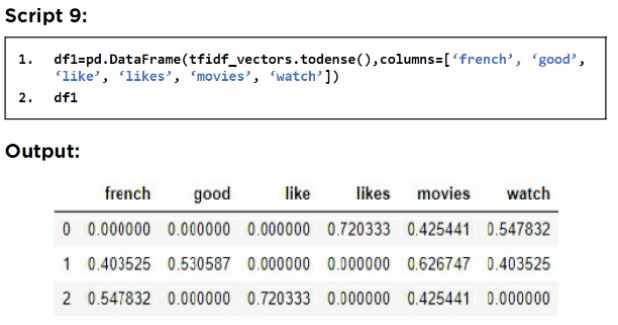
从上面的输出中可以看到,在第一个文档中,likes这个词最终归一化的TF-IDF值为0.7203,这和我们正常计算出来的差不多。
虽然 TF-IDF 嵌入通常比词袋更好,但它与词袋和 N-Grams 具有相同的局限性。TF-IDF 向量的很大,也无法保留上下文信息。
这就是 Word2Vec 词嵌入发挥作用的地方。
5. Word2Vec
Word2Vec 是一种基于神经网络的技术,其中文本文档中的每个单词都通过一个稠密向量表示。
出现在相同上下文中的词的向量具有相似的向量值。Word2Vec 方法不仅可以节省空间,还可以捕获上下文关系。Word2Vec 模型是由 Mikolov 等人在 Google 开发的。(https://bit.ly/2UvbL4t)使用 Word2Vec 技术,你可以完成惊人的任务。
例如,通过嵌入单词 king、man、woman 和 Queen 的向量,你可以执行以下任务:
king – man + women = queen 。
word2vec 操作有两种类型:Continuous Bag of Word (CBOW) 和 Skip Gram 模型。在 CBOW 模型中,输入词是相邻词(surrounding words),输出是相邻词之间的词。例如,如果你有一句话“The quick brown fox jumps over the lazy dog”,对于 CBOW 模型,其中一个输入将是“quick fox”,输出将是“brown”。对于skip gram模型,输入是“brown”,输出是“quick fox”。word2vec 模型的概述如下图所示。
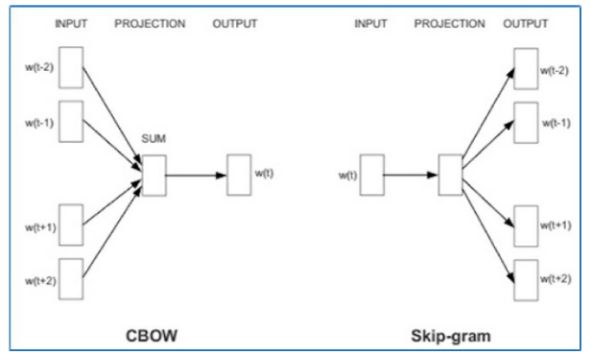
word2vec 模型通过具有一层的浅层神经网络进行训练。浅层中节点或单元的权重基本上是词的嵌入。文本中一起存在的单词将具有相似的嵌入。
有两种选择。你可以使用预训练的 Word2Vec 词嵌入,也可以创建自己的自定义词嵌入。在本节中,我们将看到这两种方法。
CBOW 模式是最常用的 Word2Vec 模型。在以下部分中,你将看到如何创建 CBOW Word2Vec 模型。
- 创建自定义 Word2Vec 词嵌入
存在可用于创建 Word2Vec 模型的各种库。我们将在本章中使用 Gensim (https://bit.ly/2BLR6Tg) 库来创建 Word2Vec 模型。
要安装 Gensim 库,请执行以下命令:

要使用 Genism 创建词嵌入,你需要一个文本语料库。Resources/Datasets 文件夹中的“simple_textfile.txt”包含一些随机文本,我们将使用它们来创建 Word2Vec 模型。以下脚本打开文本文件并读取其文本。

接下来,我们对文本进行一些预处理并从文本中删除所有特殊字符和数字。空格也被删除。预处理脚本如下:

以下脚本从语料库中删除所有停用词。


要创建 Word2Vec 嵌入,你可以使用 gensim.models 库中的 Word2Vec 对象。分词后的单词列表被传递给 Word2Vec 对象的构造函数。嵌入向量的大小传递给 size 属性。最后,我们只想要那些在语料库中至少出现两次的词的嵌入。
以下脚本使用 Resources/Datasets 文件夹中“simple_textfile.txt”中的文本创建词嵌入。

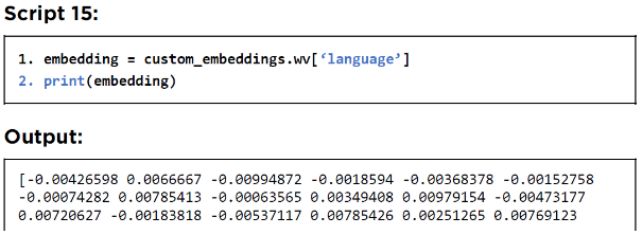
接下来,要查看特定单词的词嵌入,你可以使用“wv”属性并将要查看其嵌入的词传递给它。以下脚本打印单词“language”的嵌入。

如果你想查看嵌入类似于“processing”这个词的词,你可以使用“wv.most_similar()”方法,如下所示:

根据用于创建这些嵌入的语料库中的文本,你可以看到类似于“research”、“words”等这类词。

你可以在嵌入对象上调用“save()”方法来保存你的词嵌入。

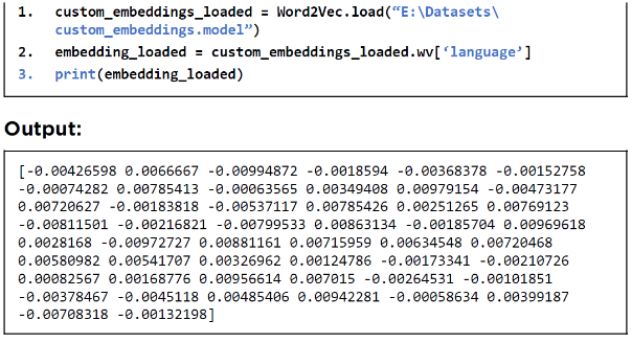
同样,要加载通过 Genism 创建的已保存词嵌入对象,你需要调用Word2Vec 对象的load()如下图:
6. 预训练的词向量嵌入
除了使用自定义词嵌入,你还可以使用来自 Stanford Glove 的预训练词嵌入(https://stanford.io/2MJW98X) 或 Google 的 Word2Vec (https://bit.ly/3hhD5Nk)。
我们将看到如何将Stanford Glove 100 维预训练词嵌入加载到我们的应用程序中。为此,你需要从Stanford Glove在线资源 (https://stanford.io/2MJW98X) 下载“glove.6B.100d.txt”。
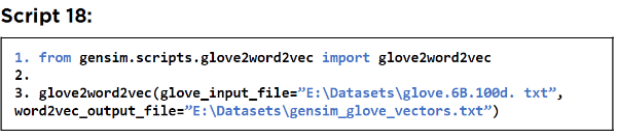
以下脚本显示了如何将glove词嵌入文本文件转换为可以加载以创建 Gensim Word2Vec 模型的格式.
输出显示我们下载的 Stanford Glove 文件中有 4,00,000 个单词,每个单词由一个 100 维向量表示。

要创建 Gensim 词嵌入,请使用“gensim_glove_vectors.txt”,执行以下脚本。以下脚本还打印“language”一词的嵌入。

单词“language”的 100 维嵌入显示在以下输出中:

要打印相似的单词,你可以使用“most_similar()”,如下所示。

- 延展阅读 – 词嵌入
要了解有关词嵌入的更多信息,请参阅以下资源:















 3912
3912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









