







过拟合是深度学习中十分常见的问题,一个模型如果过拟合了就无法很好的适用于实际的业务场景中。
防止过拟合的方法:
(1)引入正则化
(2)dropout
(3)提前终止训练
(4)增加样本量
下面一一作出详细的介绍:
正则化
模型过拟合极有可能是模型过于复杂造成的。模型在训练的时候,在对损失函数进行最小化的同时,也需要对参数添加限制,这个限制也就是正则化惩罚项。
假设模型的损失函数为:
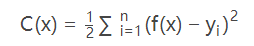
加入正则项 L 后,损失函数为

常用的正则化方法有两种:
L1正则:
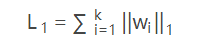
其中w代表模型的参数,k代表模型参数的个数。L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
L2正则:
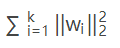
L2正则化是指权值向量w中各个元素的平方和然后再求平方根,通常表示为||w||2
它们的区别在于L1更容易得到稀疏解。
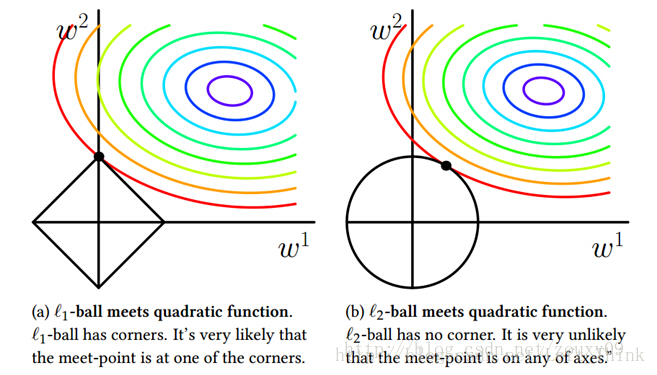
假设我们模型只有 w1,w2 两个参数,上图中左图中黑色的正方形是L1正则项的等值线,而彩色的圆圈是模型损失的等值线;右图中黑色圆圈是L2正则项的等值线,彩色圆圈是同样模型损失的等值线。因为我们引入正则项之后,我们要在模型损失和正则化损失之间折中,因此我们取的点是正则项损失的等值线和模型损失的等值线相交处。
通过上图我们可以观察到,使用L1正则项时,两者相交点常在坐标轴上,也就是 w1,w2 中常会出现0;而L2正则项与等值线常相交于象限内,也即为 w1,w2
非0。因此L1正则项时更容易得到稀疏解的。
dropout
该方法由Hinton提出的。Hinton认为在神经网络产生过拟合主要是因为神经元之间的协同作用产生的。因此在神经网络进行训练的时候,让部分神经元失活,这样就阻断了部分神经元之间的协同作用,从而强制要求一个神经元和随机挑选出的神经元共同进行工作,减轻了部分神经元之间的联合适应性。
dropout的具体流程如下:
(1)对 l 层第 j 个神经元产生一个随机数 r(l)j∼Bernouli(p)
(2)将 l 层第 j 个神经元的输入乘上产生的随机数作为这个神经元新的输入:x(l)∗j=x(l)j∗r(l)j
(3)此时第 l 层第 j 个神经元的输出为:
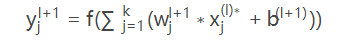
其中,k为第l层神经元的个数,f为该神经元的激活函数,b为偏置,w为权重向量。
提前终止
在对模型进行训练时,我们可以将我们的数据集分为三个部分,训练集、验证集、测试集。我们在训练的过程中,可以每隔一定量的step,使用验证集对训练的模型进行预测,一般来说,模型在训练集和验证集的损失变化如下图所示:
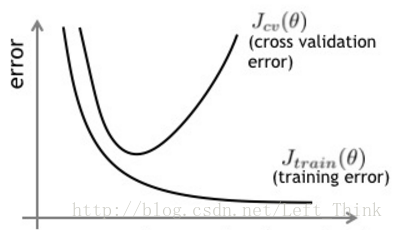
可以看出,模型在验证集上的误差在一开始是随着训练集的误差的下降而下降的。当超过一定训练步数后,模型在训练集上的误差虽然还在下降,但是在验证集上的误差却不在下降了。此时我们的模型就过拟合了。因此我们可以观察我们训练模型在验证集上的误差,一旦当验证集的误差不再下降时,我们就可以提前终止我们训练的模型。
增加样本量
增加样本量是最实在的方法。过拟合可以理解为我们的模型对样本量学习的太好了,把一些样本的特殊的特征当做是所有样本都具有的特征。
参考:
[1] http://blog.csdn.net/Left_Think/article/details/77684087















 105
105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









