







K-means是聚类算法中的一种,将样本聚类为k个簇(cluster)。
具体的算法步骤如下:
1、 随机选取k个聚类质心点(cluster centroids)为![]() 。
。
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类
![]()
对于每一个类j,重新计算该类的质心
![clip_image010[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061601468308.png)
}
K是我们事先给定的聚类数,![]() 代表样例i与k个类中距离最近的那个类,
代表样例i与k个类中距离最近的那个类,![]() 的值是1到k中的一个。质心
的值是1到k中的一个。质心![]() 代表我们对属于同一个类的样本中心点的猜测。
代表我们对属于同一个类的样本中心点的猜测。
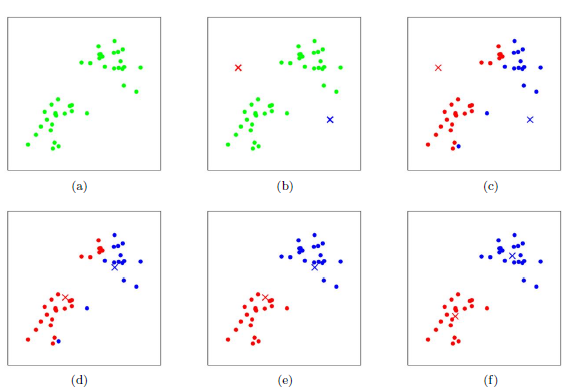
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。
K值如何选
在实际应用中,我们并不知道数据应该被聚成几类,即无法确定K。如何确定一个好的K有很多方法:
手肘法
手肘法的核心指标是SSE(sum of the squared errors,误差平方和),

其中,Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。
下图为K与SSE的关系图:

显然,肘部对于的k值为4,故对于这个数据集的聚类而言,最佳聚类数应该选4。
参考:
[1] http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
[2] https://blog.csdn.net/qq_15738501/article/details/79036255















 7117
7117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









