







 本文探讨了高速链路中码间干扰问题的解决方案,通过CTLE/FFE均衡和编码技术如4B/5B、8B/10B等来改善。8B/10B编码通过保证直流平衡和密集电平转换,提高效率并减少非实际数据传输。文章详细解析了编码原理、实例和如何通过编码表实现数据转换。
本文探讨了高速链路中码间干扰问题的解决方案,通过CTLE/FFE均衡和编码技术如4B/5B、8B/10B等来改善。8B/10B编码通过保证直流平衡和密集电平转换,提高效率并减少非实际数据传输。文章详细解析了编码原理、实例和如何通过编码表实现数据转换。
1. 线路编码技术
在高速链路中导致接收端眼图闭合的原因,很大部分并不是由于高频的损耗太大了,而是由于高低频的损耗差异过大,导致码间干扰严重,因此不能张开眼睛。针对这种情况,可以通过CTLE和FFE(包括DFE)均衡进行解决,原理无非就是衰减低频幅度或者抬高高频幅度,从而达到在接收端高低频均衡的效果。 缓解码间干扰还可以通过编码技术来实现。
说到针对于NRZ数据的编码方式,常见的有4B/5B,8B/10B,64B/66B,64/67B,128B/130B,128B/132B编码(可能各位还有其他吧),不同的编码方式针对于不同的信号协议,当然效率也是不一样的。
什么叫效率?在数据包传送的术语叫开销,意思就是除了实际需要的数据之外的一些数据bit,例如冗余校验等。那大家看上面的编码的数值比就知道了,例如8B/10B,要把8bit的实际数据扩展为10B,那开销就是20%,效率就只有80%了,更通俗来说就是增加了20%的非实际数据的传输 。所以一个好的编码方式,除了看它本身的算法优化情况外,还要注重效率高不高。
首先,为什么要编码?原来的码型有什么不好的地方吗?其中最主要的原因用下面这个图来进行解释:
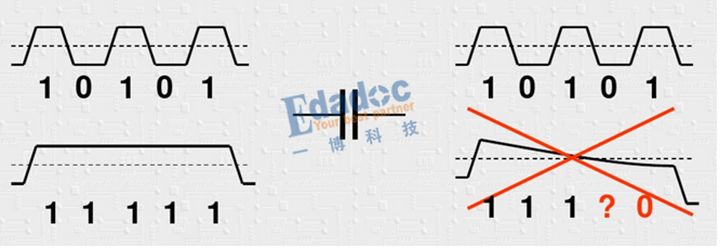
大家看明白了吧,由于我们的串行链路中会有交流耦合电容,我们知道理想电容的阻抗公式是Zc=1/2πf*C,因此信号频率越高,阻抗越低,反之频率越低,阻抗越高。因此上面的情况,当码型是高频的时候,基本上可以不损耗的传输过去,但是当码型为连续“0”或者“1”的情况时,电容的损耗就很大,导致幅度不断降低,带来的严重后果是无法识别到底是“1”还是“0”。因此编码就是为了尽量把低频的码型优化成较高频的码型,从而保证低损耗的传输过去。
而线路编码机制将输入原始数据转变为接收器可接收的数据格式,同时保证数据流中有足够的时钟信息提供给接收端的时钟恢复电路。线路编码技术提供了一种将数据对齐到字节/字的方法,可以保持良好的直流平衡,增加了数据的传输距离,提供了更为有效的错误检测机制。除此之外,线路编码技术也可以用来实现时钟修正、块同步、通道绑定和将带宽划分到子信道等。线路编码技术主要有两种:数值查找表机制和自修改数据流(扰码)。目前常用的有8B/10B编码和64B/66B编码。
2.8B/10B编码原理
8B/10B编码是1983年由IBM公司的Al Widmer和PeterFranaszek所提出的数据传输编码标准,目前已经被广泛应用到高速串行总线,如IEEE1394b、SATA、PCI-Express、Infini-band、FiberChannel、XAUI、RapidIO、USB 3.0的美好。8B/10B编码将待发送的8位数据转换成10位代码组,其目的是保证直流平衡,以及足够密集的电平转换。
8bit原始数据可以分成两部分:低位的5bit EDCBA(设其十进制数值为X)和高位的3bit HGF(设其十进制数值为Y),则该8bit数据可以记为D.X.Y。另外,8B/10B编码中还用到12个控制字符,他们可以作为传输中帧起始、帧结束、传输空闲等状态标识,与数据字符的记法类似,控制字符一般记为K.X.Y。8bit数据有256种,加上12种控制字符,总共有268种。10bit数据有1024种,可以从中选择出一部分表示8bit数据,所选的码型中0和1的个数应尽量相等。8B/10B编码中将K28.1、K28.5和K28.7作为K码的控制字符,称为“comma”。在任意数据组合中,comma只作为控制字符出现,而在数据负荷部分不会出现,因此可以用comma字符指示帧的开始和结束标志,或始终修正和数据流对齐的控制字符。
编码时,低5bit原数据 EDCBA经过5B/6B编码成为6bit码abcdei,高3bit原数据HGF经3B/4B成为4bit码fghj,最后再将两部分组合起来形成一个10bit码abcdeifghj。10B码在发送时,按照先发送低位在发送高位的顺序发送。
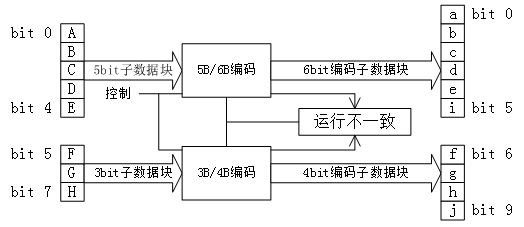
5B/6B编码和3B/4B编码的映射有标准化的表格,可以通过基于查找表的方式实现。使用 “不一致性(Disparity)”来描述编码中"1"的位数和"0"的位数的差值,它仅允许有"+2"( "0"比"1"多两个)、"0"( "0"与"1"个数相等)以及"-2"("1"比"0"多两个)这三种状况。 由于数据流不停地从发送端向接收端传输,前面所有已发送数据的不一致性累积产生的状态被称为“运行不一致性(Runing Disparity,RD)”。RD仅会出现+1与-1两种状态,分别代表位"1"比位"0"多或位"0"比位"1"多,其初始值是-1。Next RD值依赖于Current RD以及当前6B码或者4B码的Disparity。根据Current RD的值,决定5B/4B和 3B/4B编码映射方式,如下图所示。
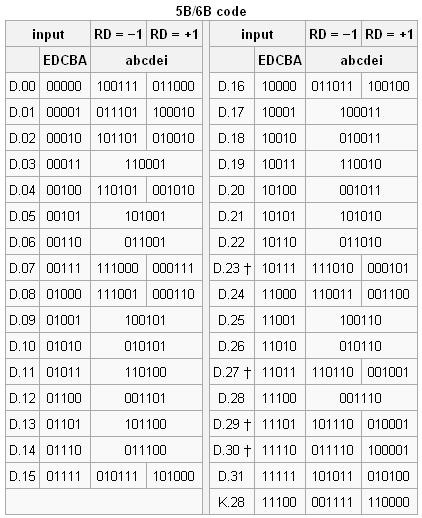

注意:当与5B/6B组合时,必须从D.x.P7和D.x.A7中选择一个来避免连续的5个0或1。
当Current RD=-1时,表示之前传输的数据中"0"的个数多于"1"的个数,若6B或4B编码的Disparity=0,则NextRD=-1;若6B或4B编码的Disparity=+2,则Next RD=+1。同样,当Current RD=+1时,表示之前传输的数据中"0"的个数多于"1"的个数,若6B或4B编码的Disparity=0,则NextRD=+1;若6B或4B编码的Disparity=-2,则Next RD=-1。

这样,经过8B/10B编码以后,连续的“1”和“0”基本上不会超过5bit,只有在使用comma时,才会出现连续的5个0或1。接收端的数据解码过程如下图所示:

3.8B/10B编码实例
我们怎么知道编码后映射成什么码型呢?因此会有一个专门的编码表,我们只需要在上面找到我们的原始码型,然后就一目了然了。编码表如下所示(部分截图):
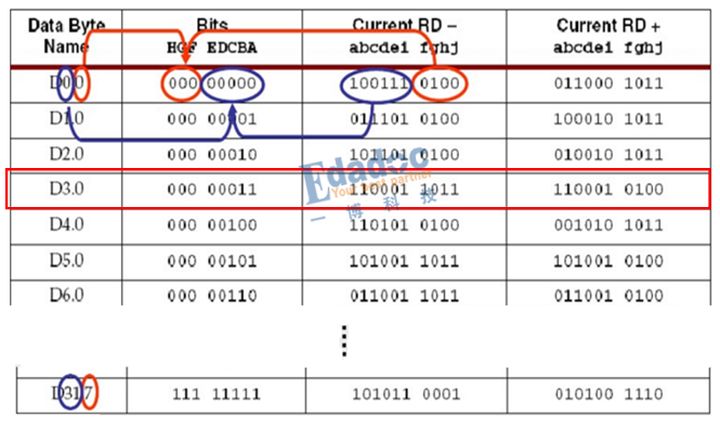
说了那么多,还不如举个例子更直观。
我们以上面的D3.0码型进行仿真验证:
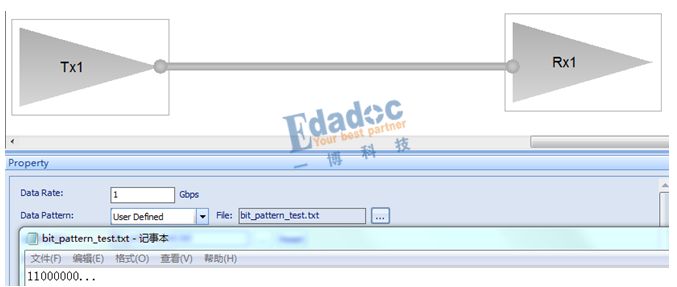
原始的码型如下:
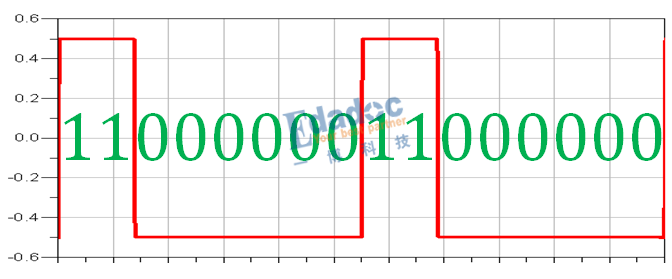
仿真得到8B/10B编码后的码型如下:

对照上面的编码表,结果完全相同,从RD-的模型出发,编码后RD-的码型“1”比较多,因此极性变成RD+的编码码型,接着RD+的编码码型“0”比较多,极性又变回RD-,因此码型就是RD-和RD+之间循环下去。
整理自:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









