






程序运行时系统的各项配置一般是按照普适性原则,尽可能满足大多数场景下的需求,并未针对特定场景进行优化,这虽然能够提高环境的通用性,但限制了性能提高的空间。运行时参数可以根据用户的需求来调整程序的运行方式和资源分配,从而提高应用程序的性能。
根据程序运行的过程,可以依次在进程布局,通信方法,内存分配多个方面进行优化。通过调整运行时参数,用户可以控制进程在NUMA上的排布,避免不合理的跨NUMA访问;可以用于控制程序运行前预加载的动态库,通过预加载动态库的方式改变所使用的内存分配库;控制MPI等通信库的行为,改变通信库所使用的算法等。
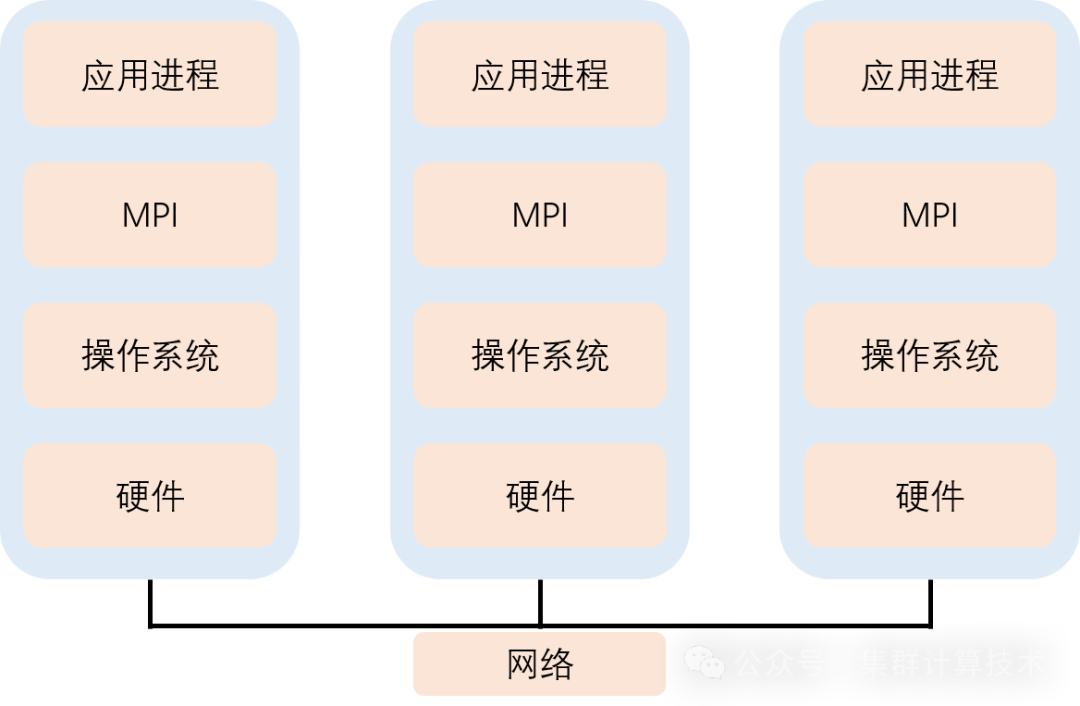
运行参数调优--NUMA
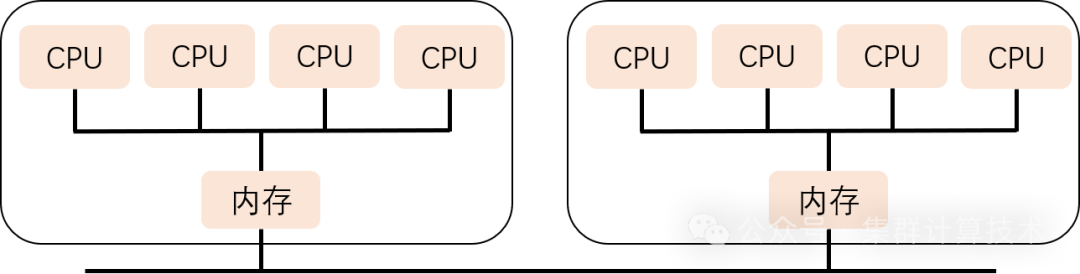
NUMA 非一致性内存访问,不同的内存器件和CPU核心从属不同的 node。
优点:扩展性好,访问本地快
缺点:访问远端慢
numactl工具可用于查看当前服务器的NUMA节点配置、状态,可通过该工具将进程绑定到指定CPU核上,由指定CPU核来运行对应进程。
不同NUMA内的CPU核访问同一个位置的内存,性能不同。在应用程序运行时要尽可能地避免跨NUMA访问内存,可以通过numactl启动程序。
如下面的启动命令表示启动程序./test,test就只能在CPU core 0到core7运行(-C控制)。
numactl -C 0-7 ./process将 process 运行在 node0,并从 node0、node1 申请内存
numactl --cpunodebind=0 --membind=0,1 process将 process 运行在 node0,并从 node0、node1 申请内存 balancing
numactl --cpunodebind=0 --balancing --membind=0,1 ./processnumstat命令主要是显示进程与每个numa节点的内存分配的统计数据和分配的成功与失败情况,可以通过numastat命令查看绑核前后numa_hit和numa_miss的差异。
运行参数调优--预加载库
系统在运行过程中,会首先加载LD_PRELOAD指定的函数库(在libc.so之前),如果函数库内包含了程序中执行的函数名,该可执行文件的函数将被重定向到LD_PRELOAD指向的函数中。
使用特定的malloc库替换默认的内存分配库,以提高内存分配的效率。例如,使用intel的qkmalloc,它提供了以下几个函数的替代:
void* malloc(size_t size)void free(void* ptr)void* calloc(size_t nobj, size_t size)void* realloc(void* ptr, size_t size)
在使用时需要设置环境变量
LD_PRELOAD=/usr/lib/libqkmalloc.so除此之外业界常见的库包括:ptmalloc(glibc标配)、tcmalloc(google)、jemalloc(facebook)。在不同场景下的优劣势不同。在此不再详述。但预加载方式相同。
运行参数调优--OpenMP参数
同一进程内的所有 OpenMP 线程共享地址空间,因此容易受到 NUMA 效应的影响。尤其是访存密集的负载在线程数超过单个 NUMA domain 的核心数时,很可能产生性能下降。因此,线程数并非越多越好,编写程序时也需要考虑到此影响。
OpenMP 进程使用以下的方式控制线程的绑定:
OMP_PROC_BIND 环境变量:控制线程绑定与否,以及线程对于绑定单元(称为 place)分布。该变量可以取以下值:
-
true:线程不能被移动
-
false:线程可以被移动
-
master:worker线程与master线程在同一个分区
-
close:worker线程在连续分区中靠近master线程,例如,如果master线程占用硬件线程0,则worker线程1将放在硬件线程1上,worker线程2放在硬件线程2上,依此类推
-
spread:worker线程分布在可用的位置上,以最大化两个相邻线程之间的空间
OMP_PLACES 环境变量:OMP_PLACES用于指定机器上放置线程的位置。然而,该变量本身并不能完全确定线程固定,因为系统仍然不知道以何种模式将线程分配给给定的位置。因此,还需要设置OMP_PROC_BIND。常用 threads/cores/sockets,threads表示一个place是单个硬件线程,即超线程将被忽略,cores表示一个place是具有相应数量的硬件线程的单个核心,sockets表示一个place就是一个socket。
示例如下:
OMP_NUM_THREADS=28 OMP_PROC_BIND=true OMP_PLACES=cores:每个线程绑定到一个 core,使用默认的分布(线程 n 绑定到 core n);
OMP_NUM_THREADS=2 OMP_PROC_BIND=true OMP_PLACES=sockets每个线程绑定到一个 socket;
OMP_NUM_THREADS=4 OMP_PROC_BIND=close OMP_PLACES=cores每个线程绑定到一个 core,线程在 socket 上连续分布(分别绑定到 core 0,1,2,3;
OMP_NUM_THREADS=4 OMP_PROC_BIND=spread OMP_PLACES=cores每个线程绑定到一个 core,线程在 socket 上尽量散开分布(分别绑定到 core 0,7,14,21;
在使用 MPI + OpenMP 混合编程时,进程绑定对性能的影响尤为关键。每个 MPI 进程需要绑定在一组核心上(通常属于同一个 NUMA domain),并把它的 OpenMP 线程绑定在其中的每个核心上。如使用 2 进程×14 线程的绑定方式为:
OMP_NUM_THREADS=14 OMP_PROC_BIND=true OMP_PLACES=cores srun -n 2 -N 1 --cpu-bind=sockets ./exe英特尔运行时库同样能够将OpenMP*线程绑定到物理处理单元。该接口是使用KMP_AFFINITY环境变量控制的。使用KMP_AFFINITY环境变量控制线程绑定。根据系统(机器)拓扑结构、应用程序和操作系统的不同,线程关联性可能对应用程序速度产生显著影响。
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
-
type = none (default):不绑定线程;
-
type = balanced:线程放置在单独的核心上;•type = compact:将线程+1接近线程<n>;
-
type = disabled:完全禁用线程关联接口;
-
type = explicit:将OpenMP线程分配给使用proclist=modifier显式指定的核心ID列表;
-
type = scatter:将线程均匀分布在整个系统中。
-
modifier = granularity=:
-
core:绑定到内核的线程在不同的线程上下文之间浮动。
-
fine/thread:每个线程绑定到单个线程上下文。
-
tile/die/node/group/socket:允许绑定到tile、die、NUMA节点、组或套接字的所有线程其中的不同线程上下文之间浮动。
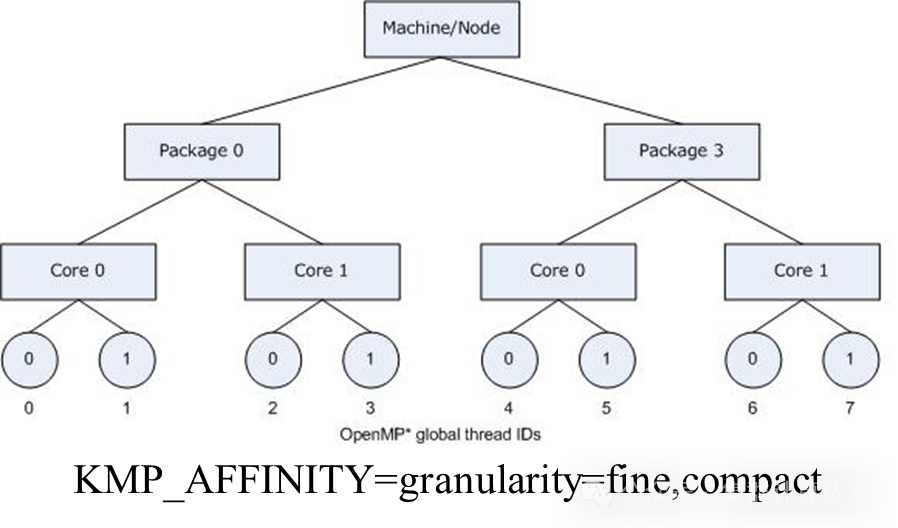
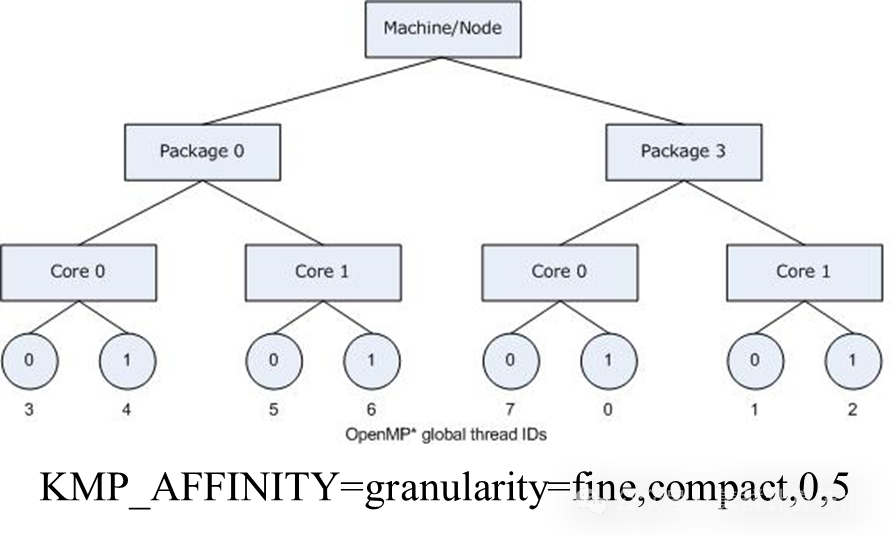
运行参数调优--进程绑定
进程绑定,即让某一个进程固定在某个CPU核上,可以避免进程在CPU 核之间切换带来的开销,可以减轻cache 争抢现象。特别是当进程数为CPU 总核数一半左右时,有时会发现测试结果不稳定,时好时坏,很可能是因为进程切换造成的,这时不妨尝试进行进程CPU 绑定。
Intel MPI进程映射与绑定
I_MPI_PIN=<arg>。以下取值表示开启绑定:enable,yes,on,1;以下取值表示关闭绑定:disable,no,off,0。
I_MPI_PIN_PROCESSOR_LIST=<list>。该列表定义处理器子集和MPI进程的映射规则。此环境变量既适用于英特尔微处理器,也适用于非英特尔微处理器,但与非英特尔微处理器相比,它可能会对英特尔微处理器执行额外的优化。
I_MPI_PIN_PROCESSOR_LIST=<proclist>。其中proclist为逻辑处理器编号和/或处理器范围的逗号分隔列表。编号为i的进程固定到列表中的第i个处理器。
I_MPI_PIN_PROCESSOR_LIST=P0, P1, P2,..., Pn
I_MPI_PIN_PROCESSOR_LIST=[<procset>][:[grain=][,shift=][,preoffset=<preoffset>][,postoffset=<postoffset>]
grain = 2,shift = 3 grains,offset = 0
此方法提供定义的处理器组(grain)沿处理器列表的循环移位,步长等于shift*grain,并在末尾的offset*grain上进行单次移位。
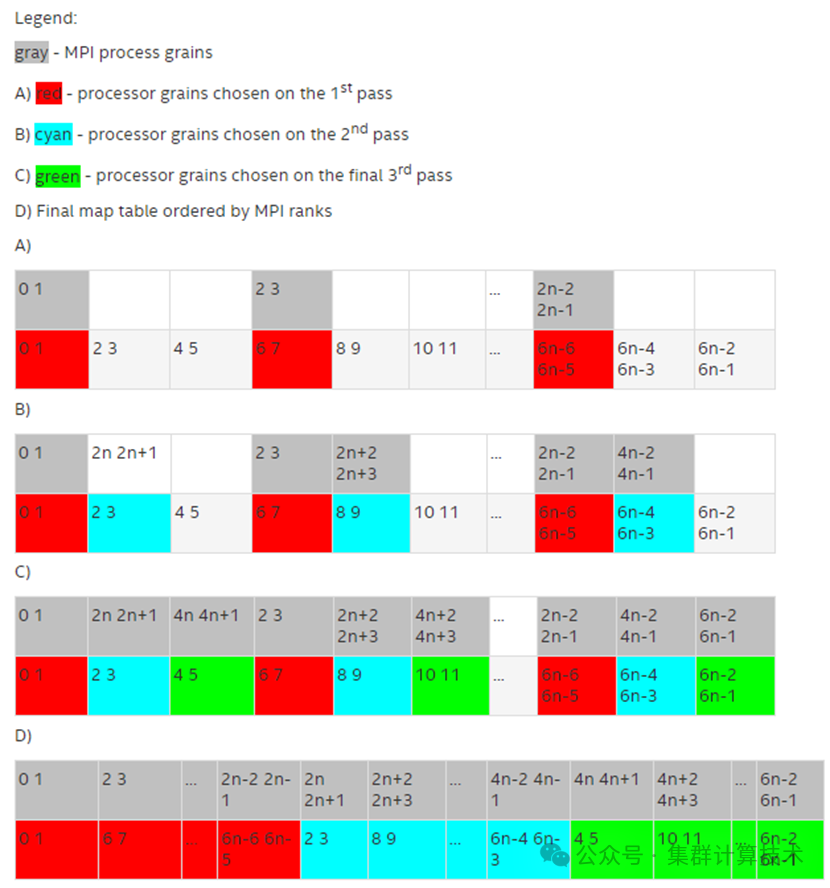
I_MPI_PIN_PROCESSOR_LIST=[<procset>][:map=<map>]
-
bunch:进程按比例映射到尽可能靠近的socket。
-
scatter:进程被尽可能远程映射,以避免共享公共资源
-
spread:进程被连续映射,并且可能不共享公共资源
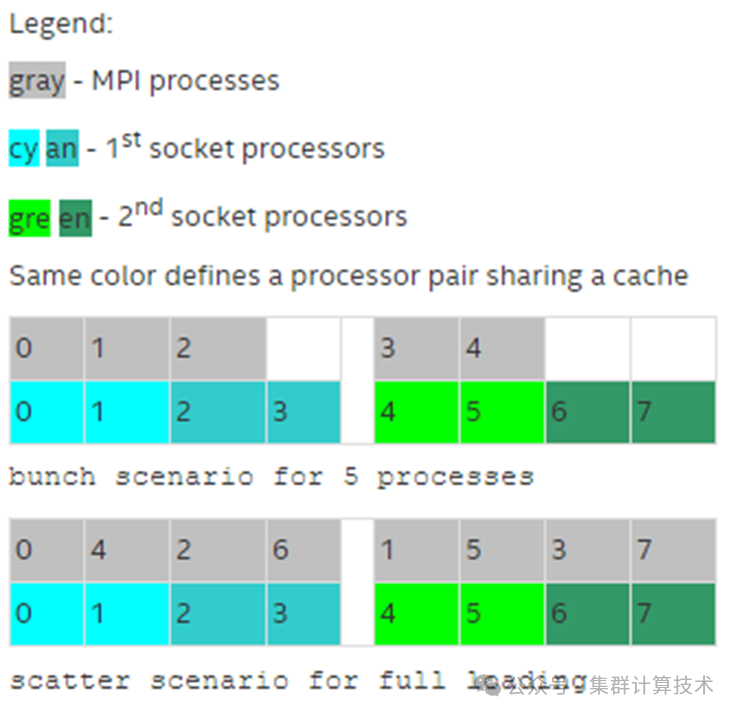
图中有两个socket,每个socket有四个核心,每个核心有一个逻辑CPU,并且每个共享缓存有两个核心。
I_MPI_PIN_DOMAIN:定义节点上逻辑处理器的多个非重叠子集,每个子集一个MPI进程。
-
=<mc-shape>::core/socket/numa/node/cache1/cache2/cache3/cache
-
=<size>[:<layout>]:
size(omp/auto/n);layout(platform/compact/scatter)
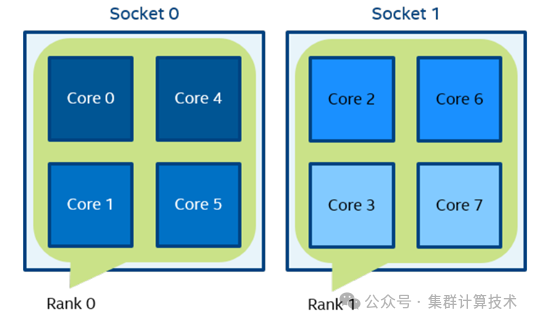
例如:当执行以下命令时,根据socket的数量定义了两个域。进程0可以在第0个socket上的所有内核上迁移。进程1可以在第1个socket上的所有内核上迁移。
mpirun -n 2 -env I_MPI_PIN_DOMAIN socket ./a.out
I_MPI_PIN_ORDER=<order>:定义MPI进程到域的映射顺序
-
range:根据处理器的BIOS编号排序的。
-
scatter:使相邻域的公共资源共享最小化。
-
compact:使相邻域尽可能多地共享公共资源。
-
spread:连续排序的,有可能不共享公共资源。
-
bunch:进程按比例映射到socket,尽可能靠近。
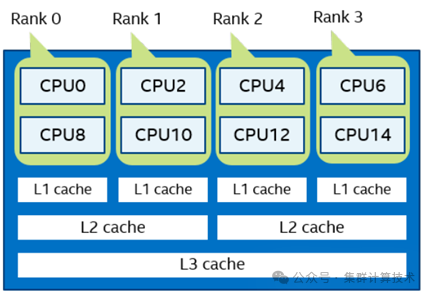
例如:
I_MPI_PIN_DOMAIN=2 I_MPI_PIN_ORDER=compact则分布如下。
OpenMPI进程映射与绑定
进程映射参数:
使用OpenMPI绑定进程,将进程映射到指定的对象,默认是core。支持的选项包括slot、hwthread、core、l1cache、l2cache、l3cache、package、numa和none。
-
mpirun --map-by slot:pe=n:将n个处理核心绑定到每个进程上
-
mpirun --map-by slot:span:根据slot负载均衡为程序分配进程
-
mpirun --nolocal:不要在运行orterun的同一节点上启动进程
-
mpirun --cpu-list:在指定的逻辑CPU列表的核心上启动进程
使用示例:
mpirun -np 16 --map-by ppr:1:l3cache:pe=4 …假设节点的总核心数是64个,共计跑了16个进程。通过hwloc-ls 查看节点有16个L3cache,此处按照l3cache 来分配资源,总核心数是64个,共计16个L3cache,则每个L3cache包含4个核心,则将pe设置成4就可以把所有核心跑满
进程绑定参数:
进程绑定是将进程绑定到指定的对象,默认是core。支持的选项包括slot、hwthread、core、l1cache、l2cache、l3cache、package、numa和none。
-
mpirun --bind-to core:将进程绑定到核心上。
-
mpirun --bind-to socket:将每个进程绑定到CPU槽位上
-
mpirun --report-bindings:报告已启动进程的任何绑定
使用示例:
mpirun --allow-run-as-root --hostfile hostfile --report-bindings --bind-to core hostname运行参数调优--MPI参数
Intel MPI参数
Intel MPI可以设置I_MPI_ADJUST_<opname>环境变量以在特定条件下为集合操作选择所需的算法。每个集合操作都有自己的环境变量和可选择的算法。在集合通信性能不佳时,根据机器特性和数据包大小特征调整集合通信所使用的算法可能能够提高性能。
具体语法为:
I_MPI_ADJUST_<opname>="<presetid>"[:<conditions>][;<presetid>:<conditions>[...]]"
下表列举了常用的集合算法及其相关的环境变量和所支持的算法,更多集合通信算法请参阅Intel MPI 手册。
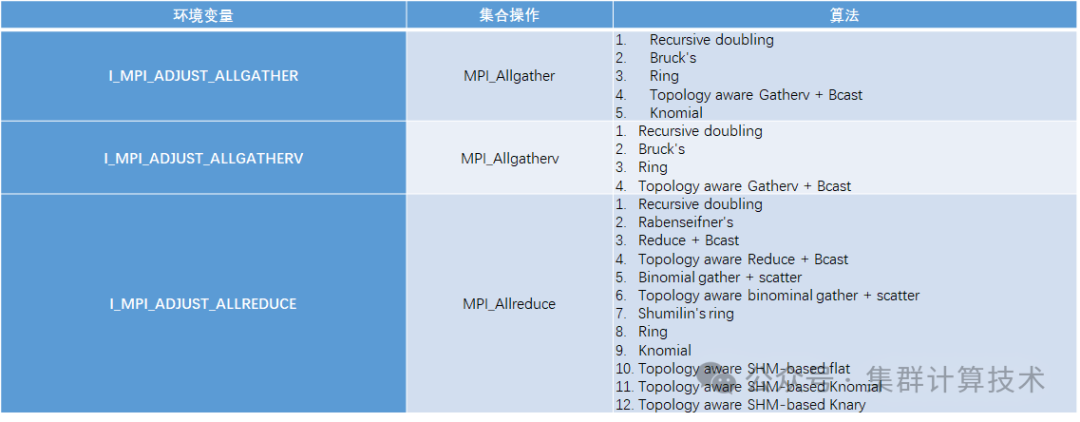
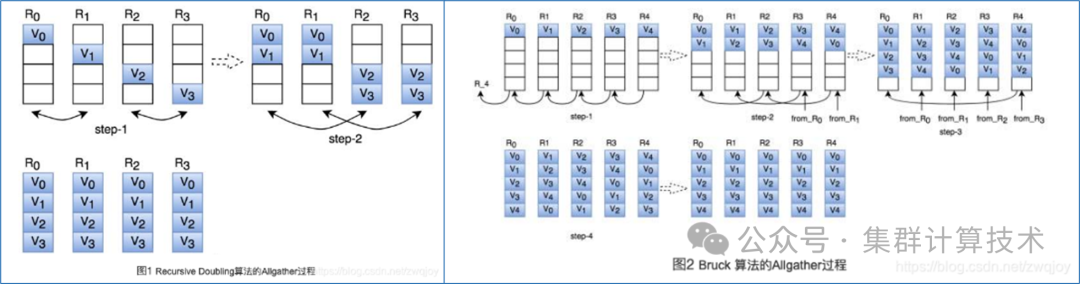
例如,在Allgather算法中,较常使用的为Bruck’s算法或Recursive Doubling算法。
I_MPI_COLL_INTRANODE:切换集合操作中的节点内部进程的通信类型,有两个可选值,pt2pt仅使用基于点对点通信的集合通信,shm启用共享内存集合通信。
I_MPI_COLL_EXTERNAL:enable/1/yes使用可用的外部集合通信操作库;disable/0/no禁用外部集合通信操作库;hcoll使用hcoll通信库。
I_MPI_FABRICS:选择要使用的特定FABRICS,可以选择ofi或shm:ofi或shm。
I_MPI_SHM:根据体系结构和指令集选择要使用的共享内存传输。可选的值有:bdw_sse、bdw_avx2、skx_sse、skx_avx2、skx_avx512、clx_sse、clx_avx2、clx_avx512、clx-ap、icx。
I_MPI_MALLOC:控制MPI库专用内存的分配器。
I_MPI_EXTRA_FILESYSTEM:控制对并行文件系统的支持,该选项虽然能够在特定场景下优化特定文件系统的性能,但可能导致死锁。
运行参数调优--UCX参数
UCX 是一个高性能网络通信库,它作为 MPI 所依赖的通信模块之一在高性能计算领域得到广泛的使用。UCX 使用 C 语言编写,提供高效且相对简单的方法来构建广泛使用的 HPC 协议。UCX框架主要由3个组件组成,即UCS、UCT和 UCP。底层的UCT适配各种通信设备,上层的UCP则是在UCT不同设备的基础上封装更抽象的通信接口,UCT是传输层,抽象了各种硬件架构之间的差异。
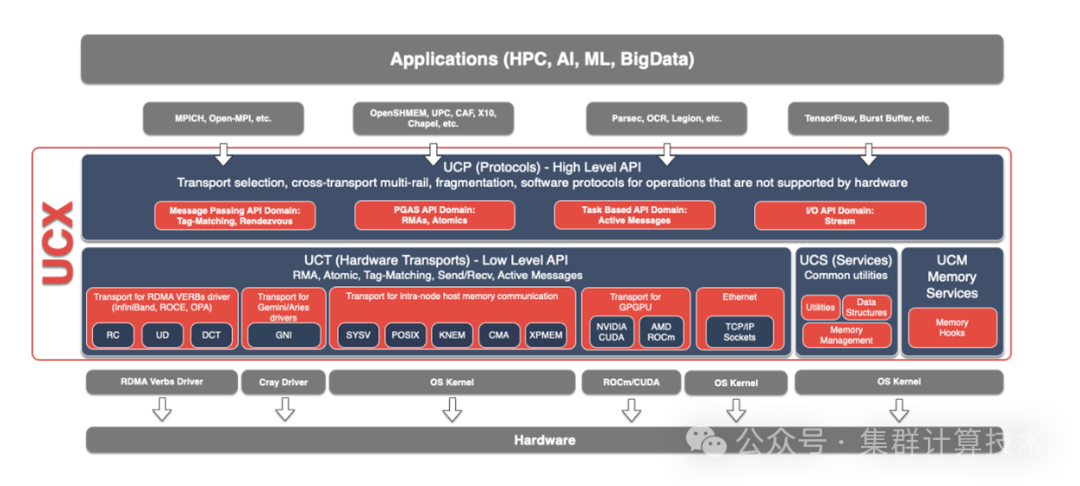
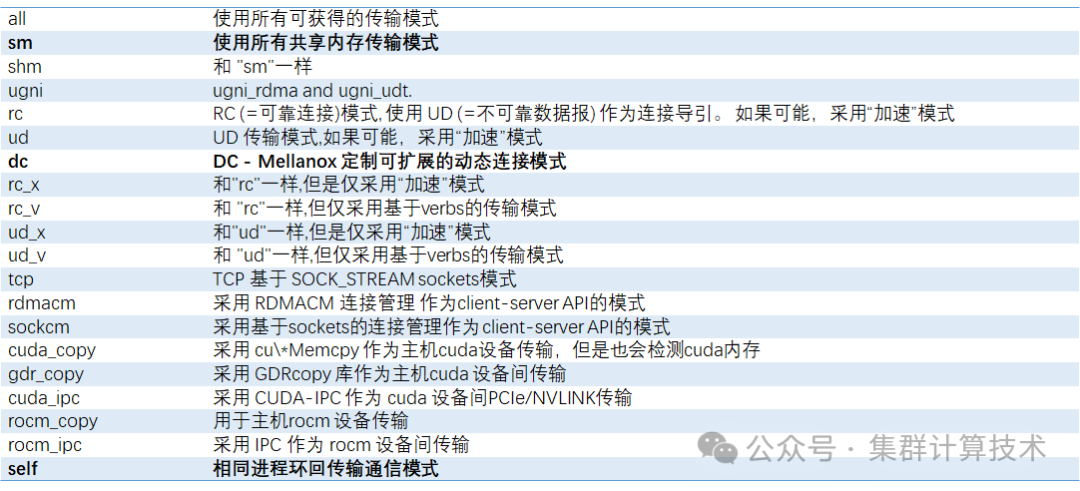
以下是一些常用的参数,更多参数请参见UCX文档。
UCX_TLS可用于调整MPI使用的通信协议。可设置的参数包括shm,rc,ud,rc_x,ud_x,dc_x等,默认的参数在某些场景下可能不是最优的。对于大规模应用,推荐采用DC模式,动态分配通信资源。下表展示了可选的通信协议,其中shm和mm二选一,rc,ud,rc_x,ud_x,dc_x 可以选一个或多个。默认不设置时等同于UCX_TLS=all.
UCX_NET_DEVICES:用于指定IB设备端口。例如UCX_NET_DEVICES=mlx5_1:1,mlx5_2:1,mlx5_0:1,mlx5_3:1用于显式指定使用4个端口设备。
UCX_IB_ADDR_TYPE:用于指定GID寻址方式。受限于IB网络协议规范,LID最大65536,对于超大规模网络,必须采用GID寻址方式进行路由,需要指定为ib_global。
UCX_MAX_EAGER_LANES、
UCX_MAX_RNDV_LANES:用于通信通道数量设置,可指定通信资源lane的数量,当使用multiRail测试应该提供足够的lane数量,否则会影响带宽性能。
UCX_BCOPY_THRESH:BCOPY针对中等消息通信加速,该参数设置启用BCOPY的阈值。
UCX_ZCOPY_THRESH:确定使用非阻塞零拷贝操作(zcopy)进行数据传输的数据包大小。
UCX_RNDV_THRESH:用于设置启用RNDV协议的阈值。如果缓冲区高于阈值,则会触发Rendezvous协议,该参数对大数据通信带宽加速明显。
硬件标记匹配(TM)允许将点对点MPI消息的处理从主机卸载到卡上。它实现了MPI消息的零拷贝,即消息直接写入用户的缓冲区,而无需中间缓冲和拷贝。有三个TM卸载相关变量可能有助于调整启用卸载后没有任何改进的特定应用程序:
UCX_TM_THRESH:定义使用硬件标记匹配卸载的阈值。小于此值的消息将在软件中处理。
UCX_TM_FORCE_THRESH:强制标记匹配卸载模式的阈值。
综上常见的UCX相关设置为(仅供参考):
export UCX_NET_DEVICES=mlx5_0:1export UCX_TLS=self,sm,rcexport UCX_IB_ADDR_TYPE=ib_globalexport UCX_RNDV_THRESH=16384export UCX_ZCOPY_THRESH=16384export UCX_MAX_EAGER_LANES=4export UCX_MAX_RNDV_LANES=4
运行参数调优--HCOLL
MPI集合通信提供了一种灵活的方式来实现组通信操作,它们被广泛用于各种科学并行应用程序,并对整体应用程序性能产生重大影响。可以尝试使用HCOLL库(Hierarchical COLLectives)优化集合通信性能。
HCOLL利用硬件多播功能来加速集体操作。为了充分利用这一独特功能,首先应在集合通信消息流量流经的每个适配器卡/端口对上配置IPoIB。首先可以使用ibdev2netdev查看所有的IB端口,再使用ifconfig 命令查看是否已经为IB端口配置了IP地址。HCOLL版本目前支持“Allgather”、“Allgatherv”、“All reduce”、“AlltoAll”、“AlltoAllv”、“Barrier”和“Bcast”的阻塞和非阻塞版本。
I_MPI_COLL_EXTERNAL=hcoll启用hcoll,使用“hcoll_info -a”可以查看各个参数的含义和可设置值,本部分仅介绍部分参数。
HCOLL自带一组通信原语,称为bcolls
-
mlnx_pp(MXM)、ucx_p2p(ucx),basesmuma(SHM)和cc(跨通道);
-
HCOLL_BCOL用于定义进程组间的通信方法。
HCOLL自带一组定义子进程组的原语,称为sbgp
-
包括Basesmsocket(Socket组)、Basesmuma(UMA组)、P2P(Network组);
-
HCOLL_SBGP用于定义进程组。
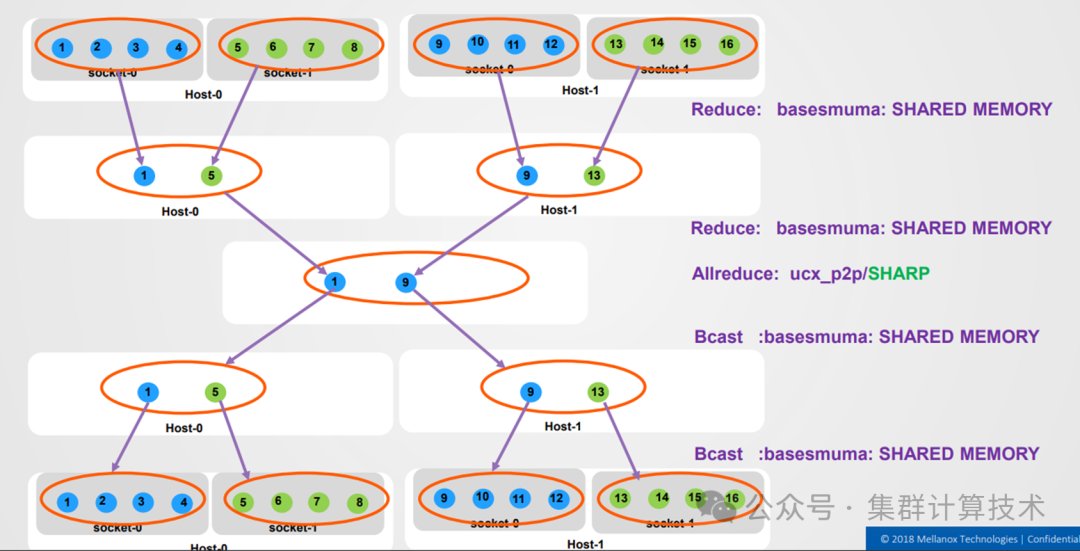
例如,在执行AllReduce时设置以下环境变量,则在同一个socket下和同一个节点内会使用shared memory方法通信,在节点间会使用p2p方法通信。
HCOLL_SBGP=basesmsocket,basesmuma,p2pHCOLL_BCOL=basesmuma,basesmuma,ucx_p2p
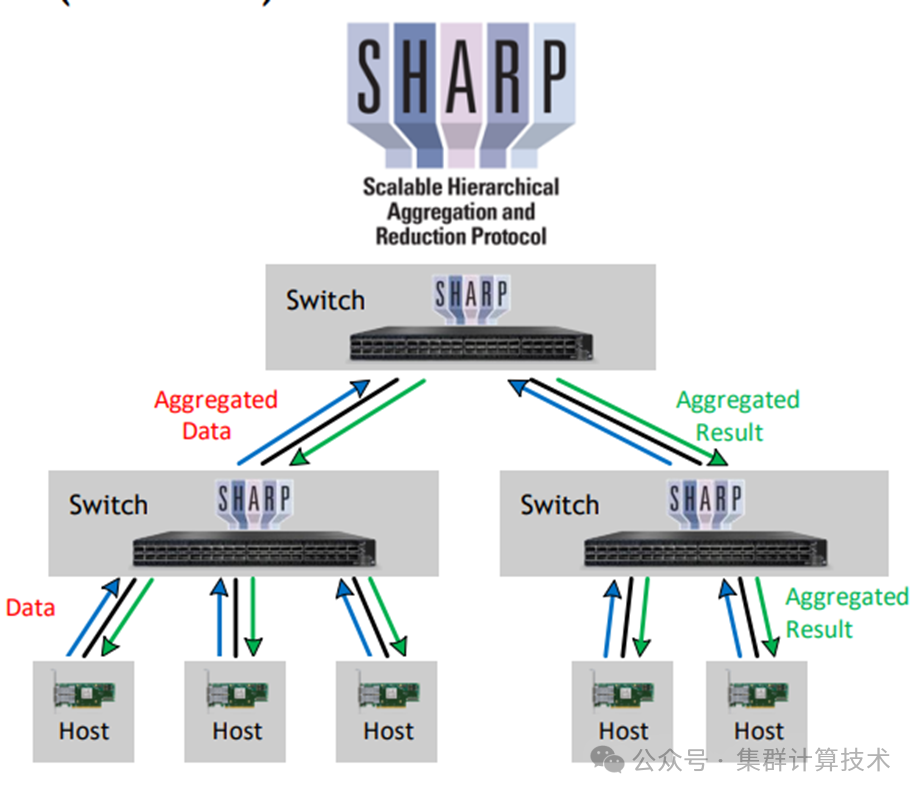
运行参数调优--SHARP
HPC-X支持NVIDIA SHARP软件加速集合通信,SHARP通过将集合通信从CPU和GPU卸载到网络,消除了在端点之间多次发送数据的需要。
HCOLL_ENABLE_SHARP:设置为1可以启动该功能,设置为2时则为强制启用该功能。
HCOLL_BCOL_P2P_ALLREDUCE_SHARP_MAX:
allreduce算法通过SHARP运行的最大小消息大小,大小小于上述值的消息将使用SHARP流聚合方法,大于该值的则回退到HCOLL不基于SHARP的算法。
HCOLL_SHARP_NP:通信器中用于创建SHARP组和使用SHARP集合通信的节点数阈值,有助于有效使用SHARP资源。默认为2,可以通过调整该值略微改善性能。
部分参数因篇幅限制,不再详细列出,具体可参考intel相关手册。
引用:
-
https://www.intel.com/content/www/us/en/docs/dpcpp-cpp-compiler/developer-guide-reference/2023-0/intel-s-memory-allocator-library.html
-
https://www.intel.com/content/www/us/en/docs/mpi-library/developer-reference-linux/2021-8/environment-variables-for-process-pinning.html
-
https://www.intel.cn/content/www/cn/zh/developer/articles/technical/improve-performance-and-stability-with-intel-mpi-library-on-infiniband.html
-
https://www.intel.com/content/www/us/en/docs/mpi-library/developer-reference-linux/2021-8/i-mpi-adjust-family-environment-variables.html
-
https://www.intel.cn/content/www/cn/zh/developer/articles/technical/improve-performance-and-stability-with-intel-mpi-library-on-infiniband.html















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









