







Sora两大核心技术
Spacetime Patch(时空Patch)
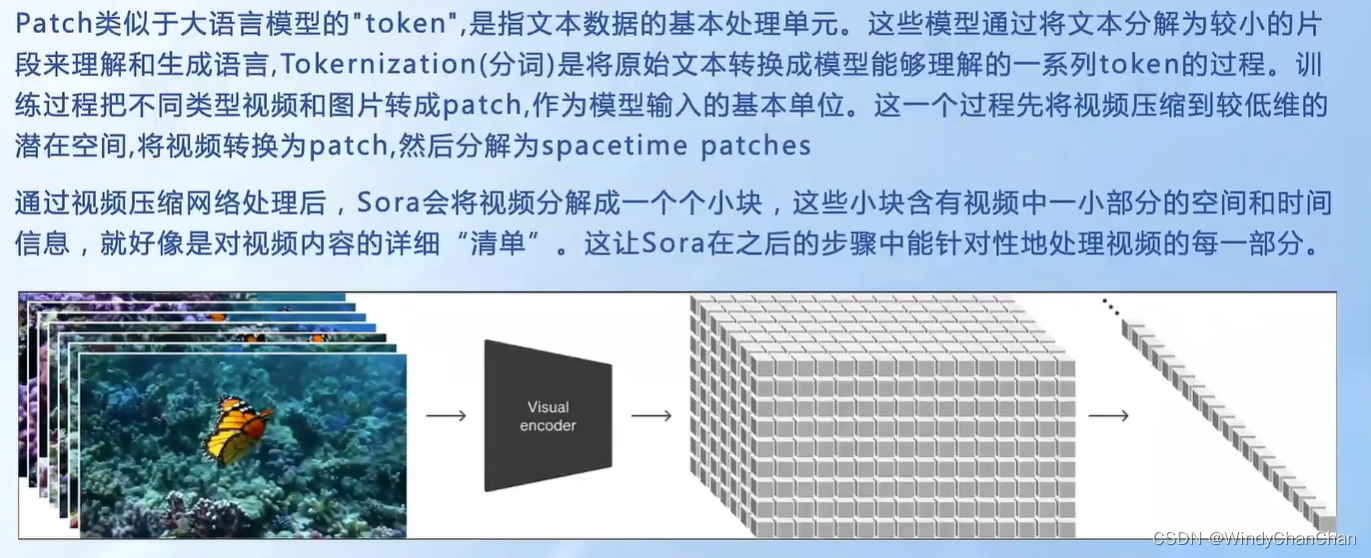
- Patch可以理解为Sora的基本单元,就像GPT-4的基本单元是Token。Token是文字的片段,Patch则是视频的片段。GPT-4被训练以处理一串Token,并预测出下一个Token。Sora遵循相同的逻辑,可以处理一系列的Patch,并预测出序列中的下一个Patch。
- Sora通过Spacetime Patch将视频视为补丁序列,Sora保持了原始的宽高比和分辨率,类似于NaViT对图像的处理。这对于捕捉视觉数据的真正本质至关重要,使模型能够从更准确的表达中学习,从而赋予Sora近乎完美的准确性。由此,Sora能够有效地处理各种视觉数据,而无需调整大小或填充等预处理步骤。
扩散型Transformer架构
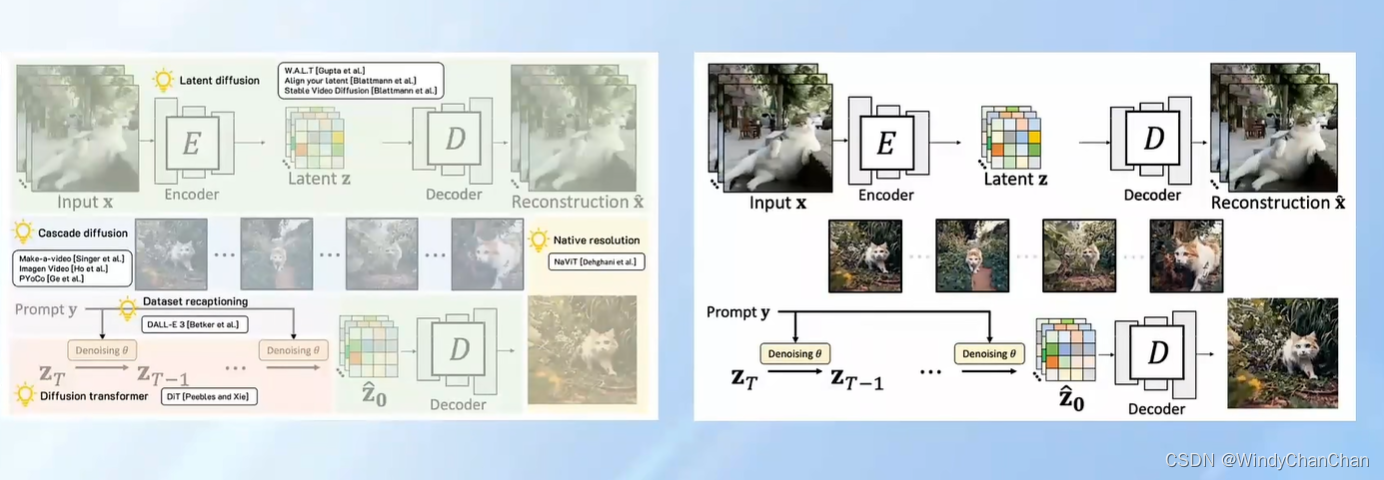
- Sora的另一个重大突破是其所使用的架构,传统的文本到视频模型通常是扩散模型(Diffusion Model),文本模型例如GPT-4则是Transformer模型,而Sora则采用了DiT架构,融合了前述两者的特性。
- 传统的扩散模型的训练过程是通过多个步骤逐渐向图片增加噪点,直到图片变成完全无结构的噪点图片,然后在生成图片时,逐步减少噪点,直到还原出一张清晰的图片。Sora采用的架构是通过Transformer的编码器-解码器架构处理包含噪点的输入图像,并在每一步预测出更清晰的图像。DiT架构结合时空Patch,让Sora能够在更多的数据上进行训练,输出质量也得到大幅提高。
Text to Video
Sora 能力对比
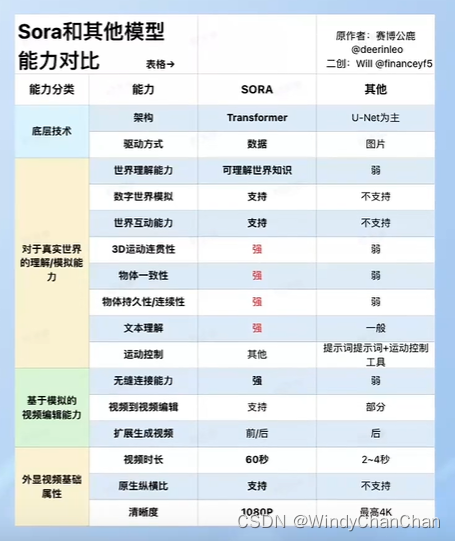
Video Compressing Network
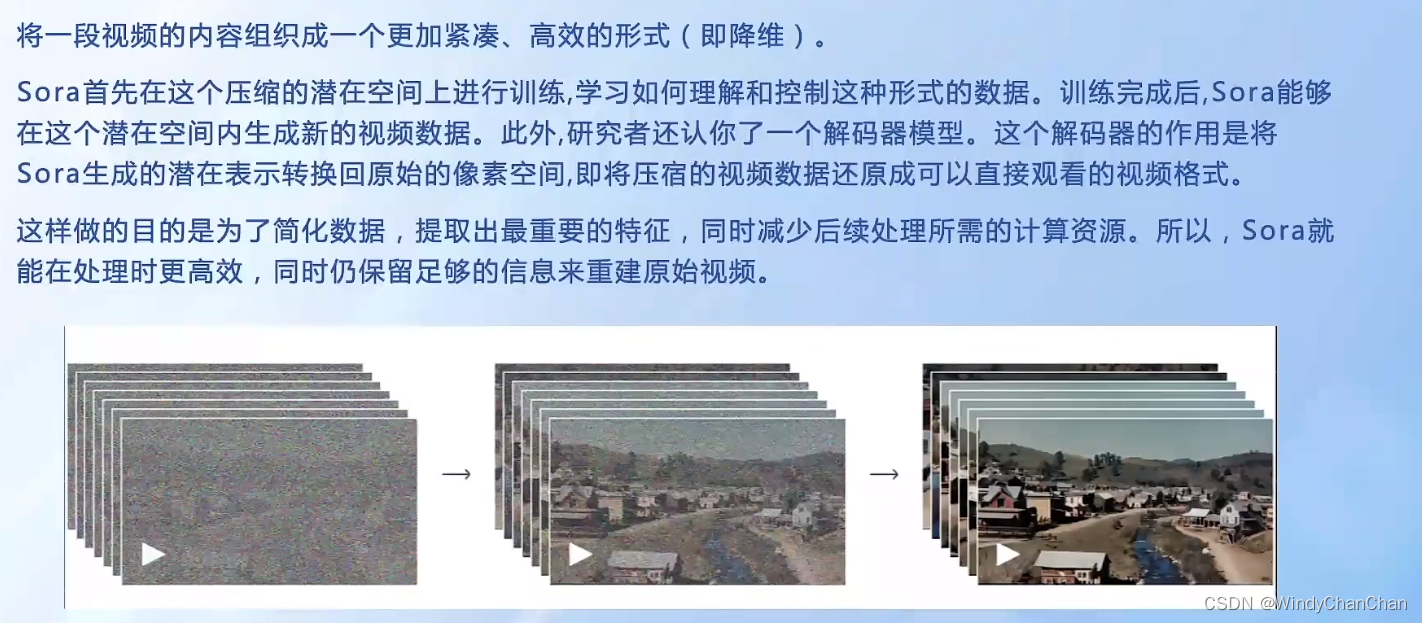
Turning Visual Data Into Patches

From Sparse Set to Consistent Content
Sora应用案列

Text to Video和Text to Motion的对比

















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









