







Training Recurrent Neural Network
这节课主要讲了怎么训练RNN,用的方法是BPTT(Backpropagation through time)。
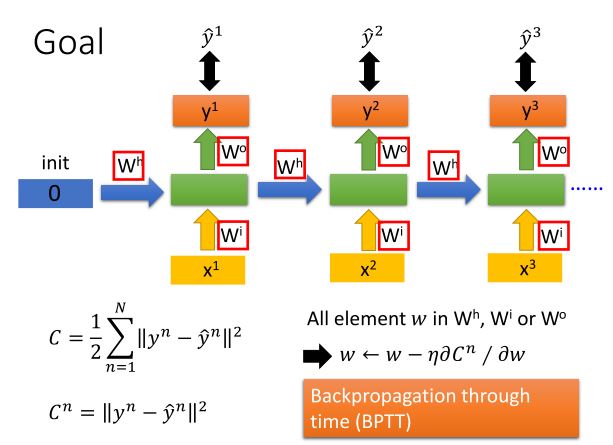
RNN的目标是训练参数
wh,wo,wi
。
BPTT的做法是,先将RNN随着时间展开,如下图:

展开之后像训练普通神经网络一样做Backpropagation就行了,唯一的区别在于RNN输入是一个连续的序列,输出也是一个连续的序列,因此在每个输出的y上都要做Backpropagation的初始化。
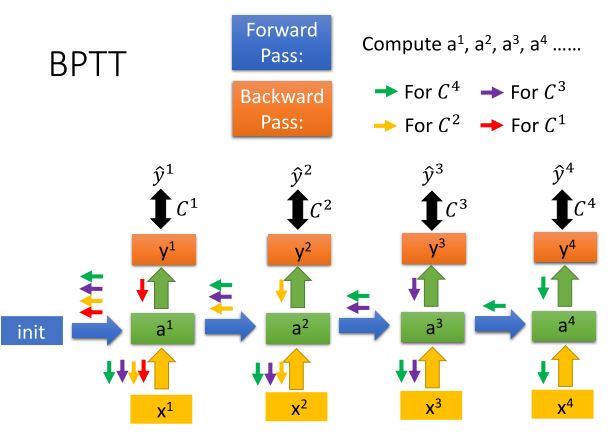
但是训练RNN没有这么容易,原因是:
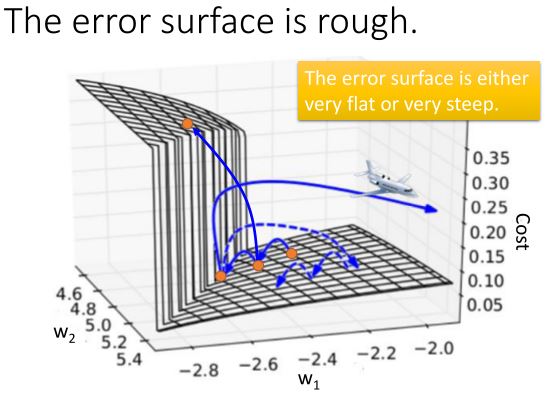
可能的解决方法有:
- Clipping the gradients,即给gradient的值做限定。
- Advanced optimization technology(NAG,RMSprop)
- LSTM(or other simpler variants)
- Better initialization
Introduction of Structured Learning
这节课介绍了Structured Learning和解决Structured Learning问题的基本框架。
Structured Learning
概念:
一些例子:

Unified Framework
解决Structured Learning的基本框架:

Three Problems
为了表示除以上框架,有三个问题需要解决:

这里联系到了HMM,并推荐了Viterbi Algorithm。
Viterbi Algorithm
给定观察空间 O={o1,o2,...,oN} ,状态空间 S={s1,s2,...,sK} ,一个观察序列 Y={y1,y2,...,yT} 。转移矩阵 A∈RK∗K , Aij 表示从状态 si 转移到 sj 的概率。放射矩阵 B∈RK∗N , Bij 表示观察点 oj 来自状态 si 的概率。路径 X={x1,x2,...,xT} 表示一个序列产生观察序列 Y={y1,y2,...,yT} 的状态序列。初始化的 π∈RK∗1 ,表示 x1==si 的概率。
在这个DP问题中,我们用到两个二维数组
T1,T2∈RK∗T
。
T1[i][j]
表示到
j
的最可能的路径
T2[i][j]
保存了这条路径。
状态转移方程:
T1[i][j]=maxk(T1[k][j−1]∗Aki∗Biyj)
,
T2[i][j]=argMaxk(T1[k][j−1]∗Aki∗Biyj)
算法的输入输出:

伪代码:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









