






- Irene Celino
Cefriel, viale Sarca 226, 20126 米兰, 意大利
irene.celino@cefriel.com
- Agnese Chiatti
米兰理工大学, Leonardo da Vinci 广场 32 号, 20133 米兰, 意大利
agnese.chiatti@polimi.it
摘要
本章探讨了人与系统之间相互理解的概念,提出神经符号人工智能(NeSy AI)方法可以通过利用显式的符号知识表示与数据驱动学习模型显著增强这种相互理解。我们首先介绍三个关键维度来表征相互理解:共享知识、交换知识和治理知识。共享知识涉及使不同代理的概念模型对齐,以实现对感兴趣领域的共同理解。交换知识涉及确保代理之间有效且准确的沟通。治理知识涉及建立规则和流程以调节代理之间的互动。然后,我们展示了几个不同的用例场景,这些场景展示了NeSy AI和知识图谱如何促进人类、人工和机器人代理之间有意义的交流。这些场景既突显了结合自上而下的符号推理与自下而上的神经学习的潜力,也引导了关于当前解决方案在共享、交换和治理知识维度上的覆盖范围的讨论。同时,这一分析有助于识别相互理解中的空白和较不发达的方面,为未来研究提供方向。
关键词:相互理解、知识共享、知识交换、知识治理、人类代理、人工代理、机器人代理、神经符号AI、知识图谱
1 引言
在他的畅销书《思考,快与慢》[35]中,丹尼尔·卡尼曼提出了他的认知理论,将人类决策过程分为两种模式——快速、直觉和情感化的系统和缓慢、更审慎和更逻辑的系统。前者更为无意识且难以解释,显示出一些类似于机器学习系统的特征;后者则更为明确和合理,表现出知识表示和推理系统中的常见特征。
因此,在设计人工智能系统时,我们可以将神经符号AI [59]视为“系统1”神经、连接主义方法与“系统2”符号智能系统的结合,以构建混合解决方案,取两者之长[8]。广义上讲,神经符号系统结合了基于人工神经网络的方法(即神经成分)与基于显式符号操作的方法。尽管符号与非符号之间的区别是一个活跃争论的主题,我们遵循[75]的观点,使用术语符号指代对象、类别和现实世界关系的语义描述(例如标签、关系、其他历史数据记录的解释)。这种混合学习过程也可以被视为一种将通过自下而上观察直观提取的模式与对环境的自上而下认知期望相结合的过程[25]。
参照人类决策和人际交往,我们习惯认为清晰而有意义的对话是产生和实现相互理解和成功结果所必需的。如果参考维特根斯坦的经典定义,我们知道这种成就是常常难以达到的:“我们所说的理解一个句子的意思是指它可以被另一个表达相同意思的句子替换;但也指它不能被任何其他句子替换”[82],这挑战了理解的概念本身。
当人们之间的互动由数字人工系统介导时,我们如何促进并实现相互理解?我们能否也促进机器之间的相互理解,支持互操作性和有意义的交流?成功应用符号方法(如知识图谱和语义网解决方案)、神经方法(如机器学习、生成式AI、机器人技术)及其组合以实现相互理解的成功案例有哪些?
在本章中,我们将试图回答这些问题,通过提出一组维度来表征相互理解(第2节),通过说明和分析采用神经符号AI和知识图谱的不同用例场景(第3-8节),并通过提供对未来工作的综合分析和挑战(第9节)。
2 相互理解的维度
人与人之间的相互理解发生在“当不同的思维相互推断他们在对某一对象、人物、地点、事件或想法的理解上达成一致时”,这通常由概念对齐支持,概念对齐是“个体的心理表征已对齐或足够兼容的状态,尽管这些个体具有独特经验和知识结构”[70]。
一项经典研究[71]关注了分析师-客户访谈中人类代理的沟通行为,指出有三个关键过程影响人与人之间的相互理解:转换视角(调整到对话者的参考框架[72]或个体以最适合特定沟通情境的方式进行关联的能力[46])、管理交易(处理构建、控制和维持对话的程序性方面的能力[81])以及建立融洽关系(人际关系的一个方面,可定义为在关系中发展出和谐、一致和协调的状态[30])。因此,在我们的研究背景下,我们将这三个关键过程置于人与系统之间、由数字人工系统介导的相互理解领域中:
- 知识共享(对应于转换视角)定义为相关代理分享关于感兴趣领域的共同概念模型的能力(例如,用于表示给定领域知识的本体);
-
- 知识交换(对应于管理交易)定义为两个或多个代理之间有意义地交换信息的能力;
-
- 知识治理(对应于建立融洽关系)定义为调节相关参与者之间知识共享和交换的一系列过程、角色和规则。
在本章中,我们旨在分析由神经符号AI支持的人与系统之间各种相互理解场景,突出它们可能需要解决的知识共享、交换和治理三大关键过程中的问题。
最后,我们将描述每个场景,通过识别参与的代理(包括人类用户和人工系统,无论他们是基于符号、次符号和神经符号AI还是其他技术)、他们在场景中扮演的角色以及他们访问的知识来源(例如数据、模式、文档、机器学习模型甚至隐性知识)。
- 知识治理(对应于建立融洽关系)定义为调节相关参与者之间知识共享和交换的一系列过程、角色和规则。
3 案例1:人类数据收集与处理
在本节中,我们解决了通过专用应用程序和问卷从人类收集结构化数据的问题,以便通过促进研究人员之间数据的交换和再利用,从而简化数据分析和重用以及纵向和比较研究。
3.1 问题场景
Jaime 发起了一项公民科学项目,邀请世界各地的人们收集有关环境污染的数据。他使用了一款游戏化应用,让人们分类图片,以帮助更好地理解污染问题。通过一场专门的宣传活动,他成功吸引了来自五大洲的数百人参与,帮助分类了数万张图片;然而,他注意到贡献者之间的质量和参与度存在差异,有些人非常活跃,而另一些人似乎随着时间的推移失去了兴趣。
Jaime 想知道是否值得继续让人们对分类任务保持参与——这间接有助于提高对环境挑战的认识——或者他应该使用已分类的图片作为机器学习分类器的训练集。此外,他还想了解哪些因素影响了他们参与他的公民科学计划的积极性,并决定进行一次调查,要求他网络中的所有参与者填写一份结构化问卷。
由于他是一名科学家,他进行了对比研究,对比了人类和机器分类,并采用了问卷设计的最佳实践和文献中的动机分析框架,因为他想将自己的发现与以前的研究进行对比。然而,他知道,一旦收集到人们的回应,他将在运行分析之前需要做大量的数据清理和准备工作。Jaime 希望找到一种解决方案,简化其问卷数据的设计、收集和分析,同时也使其他公民科学研究人员能够重复他的调查并将他们的发现进行对比。
3.2 技术解决方案
以目的为导向的游戏吸引人们参与数据收集
人类计算[41] 是致力于利用人类智能解决计算机难以解决的计算问题的研究领域;以目的为导向的游戏(GWAP)[79] 是一种人类计算方法,为了吸引人们参与解决计算问题,采用游戏应用提供内在激励。
在结构化数据(链接数据、知识图谱)的收集和意义解读中,GWAP 被证明是一种合适的解决方案以吸引人们参与。我们构建了一个框架[51],以简化链接数据应用的游戏化设置,特别是针对链接创建、链接排名和链接验证;此外,我们展示了如何动态计算人类贡献者之间的“相互理解”增量真相推断算法[15]。
我们采用了 GWAP 方法构建了 Night Knights[52],这是一个用于光污染区域图像分类的游戏化应用(另见图1),并在几个月内吸引了约 1,000 名玩家对约 40,000 张图像进行分类。
分类中人类和机器学习参与的模式
当人们参与人类计算工作以解决计算问题时,对其行为的分析揭示了几个有趣的特征,可以调查他们在其中的作用及贡献的相关性。我们研究了前面提到的 Night Knights 游戏的参与数据,以揭示游戏激励、玩家档案和任务难度之间的关系[50];部分示例发现如图2所示。
此类分析还服务于理解如何构建混合的人机数据处理管道,以充分利用两者的优点[52]。依赖人类能力让人执行任务更好,还是训练机器学习系统自动解决问题更好?答案很大程度上取决于具体情况和所需的准确性:人类可能更可靠——尤其是如果是领域专家——但自动处理可能更便宜。我们对不同的人类计算和机器学习方法进行了实验比较,以解决相同的图像分类任务:我们进行了对比分析,以得出长期结合策略来大规模解决具体问题。虽然很难确保用户的长期参与以完全依赖人类计算,但手动分类对于克服自动化数据建模的“冷启动”问题至关重要(参见图3中的混合人机工作流)。
调查研究作为研究对象
另一种研究人们参与协作努力的方式是直接询问他们对主观感知的看法,通过定量研究调查。这就是我们所做的,以分析影响积极参与公民科学和众包的因素[16]。为此,我们设计了一份调查问卷,以调查不同因素,

图1:以目的为导向的游戏用于数据链接和图像分类
我们在会话式调查工具中实现了它[14],该工具允许对问题和答案进行语义标记,并从调查本体[66]中收集结构化数据。
调查本体
1
{ }^{1}
1满足设计用于收集定量数据的问卷时经常出现的不同需求:(1) 将调查结构作为结构化数据提供,以使其知识明确;(2) 标注问题与相应的调查变量;(3) 标注答案与其数值编码,以简化数据分析;(4) 将收集的答案作为结构化数据提供,以支持比较和纵向研究;(5) 保留答案的出处,以备需要时追溯;(6) 共享调查方法,以促进研究的可重复性和可再现性。该本体重用了PROV-O和Research Object系列本体中的概念和关系[5]:这允许打包一个复合工件,代表、注释和共享问卷结构和收集的调查响应。
3.3 与相互理解框架的关系定位
此情景中的主要知识来源是人们,因为他们提供了自己的专业知识或获取重要信息的能力。随后,人们的知识被收集、保存和管理在各种信息系统中(例如GWAP应用、调查平台、数据分析工具),这些系统可能支持此类知识的长期保存。
本节中主要解决的相互理解问题是与知识共享相关的:通过人类计算方法将人们引入数据收集和处理管道意味着我们利用了他们提供专业知识和知识以解决计算任务的能力,这也为混合的人机处理铺平了道路(潜在地还包括人类-神经符号处理);此外,采用调查概念模型来描述问卷、知识图谱来收集受访者数据以及研究对象来打包方法论、数据和分析的目标是促进和标准化跨不同研究的调查方法的再利用。研究对象工件还支持知识治理挑战,因为它提供了一种跟踪整个调查活动并使其分析可重现的方式,并部分解决了知识交换挑战,因为它允许研究人员之间交换调查方法和结果以进行比较或纵向研究。
1
{ }^{1}
1 参见 https://w3id.org/survey-ontology.
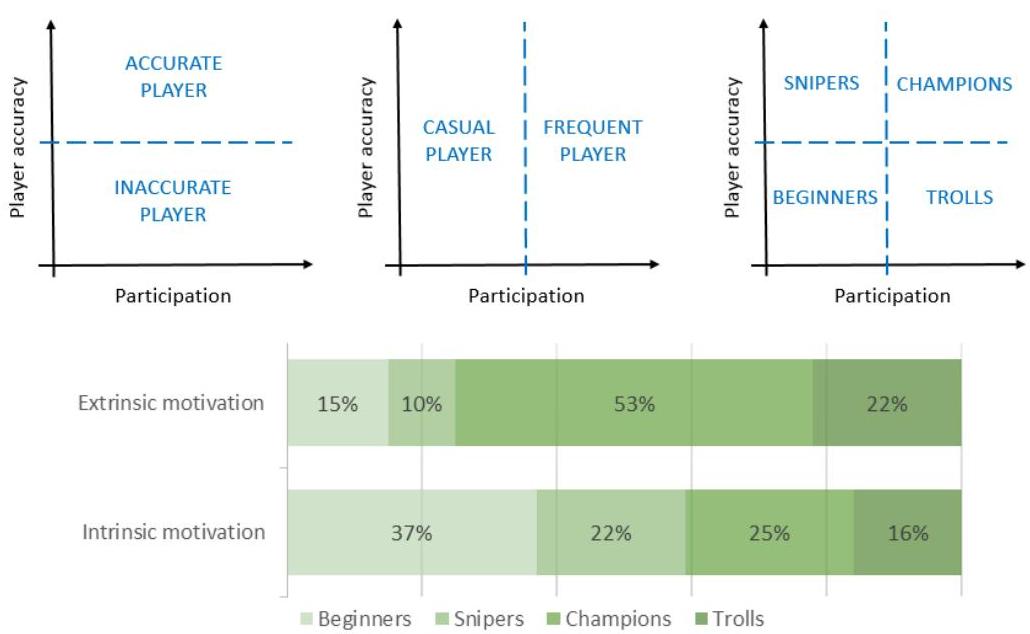
图2:GWAP玩家档案的定义及其在不同激励机制下的分布
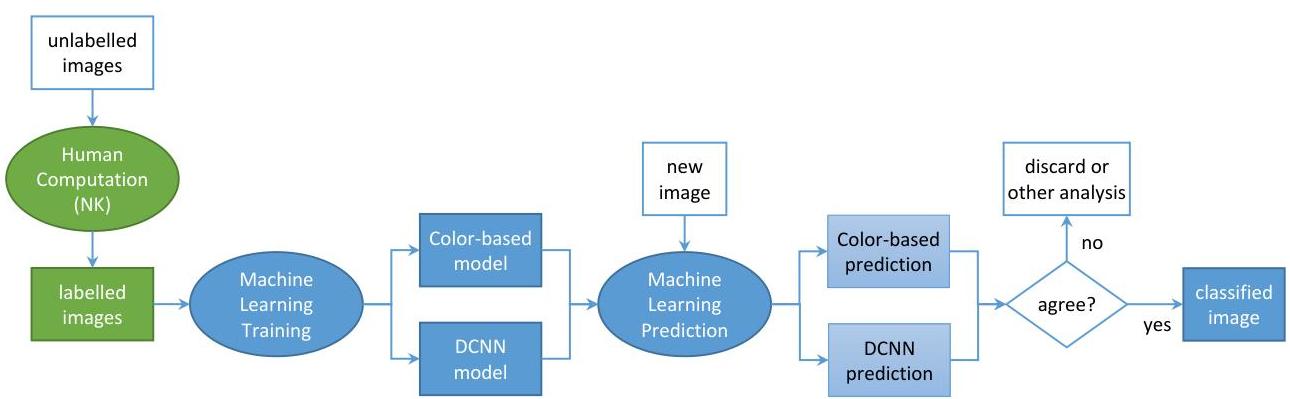
图3:混合分类解决方案中人类和机器处理的一种可能组合
3.4 开放挑战和可能扩展
结合符号和次符号方法构建数据处理的复合模式是众所周知的“盒学”设计模式[76]的主题,也是混合学习和推理系统[10]中混合机器学习-语义网系统分析的主题。进一步扩展这些工作以考虑人类组件将导致定义混合人类-神经符号设计模式,这些模式将人工和人类智能结合在一起;在这方面,最近一波生成式AI解决方案以其类似人类的能力,似乎表明这种结合将带来新一代混合系统,以更有效地解决复杂挑战。
就用于收集和分析定量数据的问卷而言,我们的会话式调查工具[14]旨在为受访者提供聊天式的互动体验以提高参与度。由于大型语言模型的兴起,会话式AI系统的持续改进很可能带来新的交互式调查系统形式。尽管文献中有多项工作强调了聊天机器人在进行访谈和增加参与者参与度[84]、信任[1]和自我披露[85]方面的能力,但通过成功结合这些神经方法与符号方法,可能会在结构化数据收集和答案分类及编码方面取得显著改进。
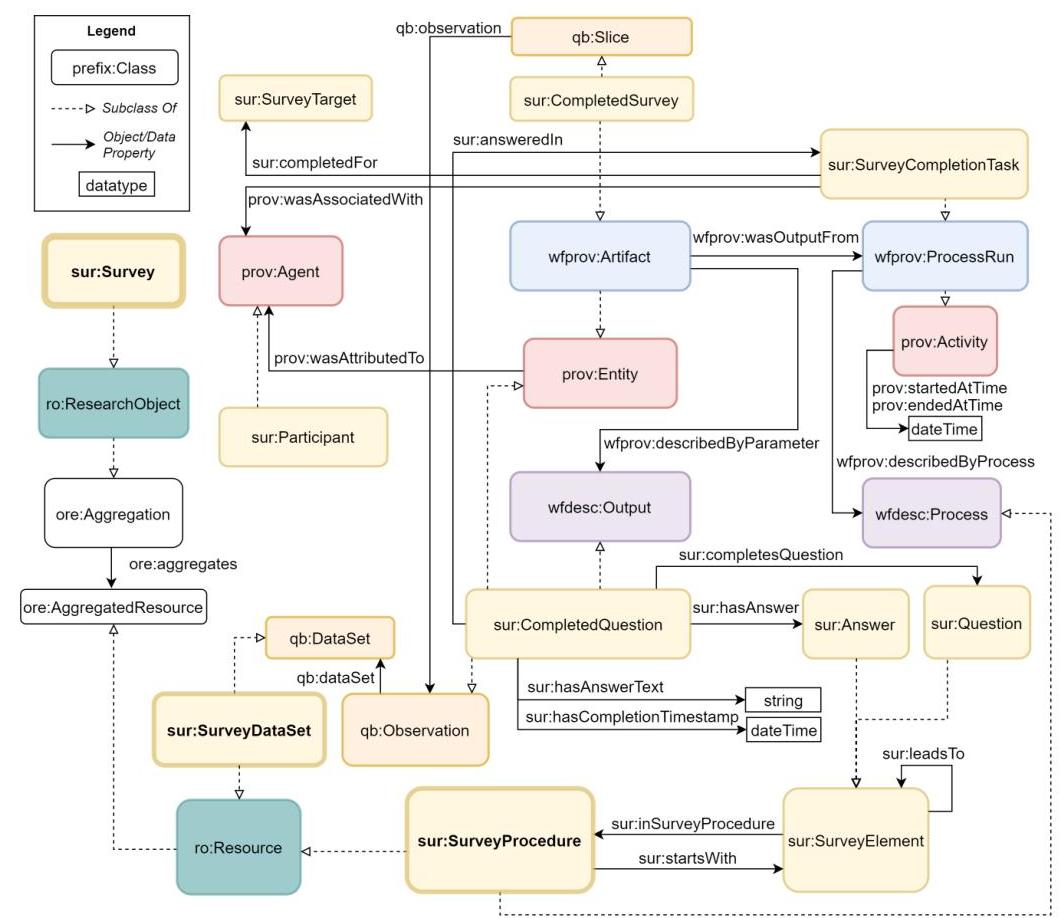
图4:调查本体概述
4 案例2:知识提取和获取
在本节中,我们解决了从非结构化数据源中提取知识并使隐性知识显式化的问题,通过涉及人们在知识获取过程中实现人与人之间的相互理解。
4.1 问题场景
珍妮是一家制造公司的产品经理。她负责确保产品的使用、维修和故障排除支持文档可用、清晰且最新。她的团队总是努力制作包含所有相关信息的手册。
然而,珍妮意识到,即使她的团队总是努力制作包含所有相关信息的手册,仍常出现两个问题:(1) 这些信息不易获取,因为手册通常很长;例如,一位维护人员在接到客户请求修理产品时,可能需要找到正确的文件,并在文件中找到大量其他不太有用细节中的相关信息;(2) 部分知识仍然隐含在人的头脑中;例如,一名新手或经验较少的员工往往需要向资深专家请教,因为并非所有相关信息都可以始终记录下来,有些知识仍然是隐性的或只能通过直接经验获得。珍妮希望找到一种解决方案,从文档中提取相关知识,并促进同事隐性知识的显性化。
4.2 技术解决方案
信息检索和结构化知识
寻找手头任务的相关信息是在工业部门中的常见挑战[56]。找到正确的知识片段或正确答案是任何信息检索和问答方法的基础和动力。最近,生成式AI的出现促使了检索增强生成方法(RAG [42])的兴起,这些方法将向量索引与预训练参数模型结合在一起。在不同的RAG方法中,基于知识图谱的RAG架构正在兴起,利用结构化信息的力量——还根据本体概念模型进行描述——与神经方法结合。
众所周知,结构化数据使得查找相关信息更加容易,知识图谱是建模、共享和保存相关实体和关系结构化描述的强大解决方案。因此,我们一直在开发一种模块化本体,以促进工业环境中文档检索和知识提取[57]。所提出的本体可以在标注、存储/索引、搜索和查询回答的不同阶段使用(参见图5)。
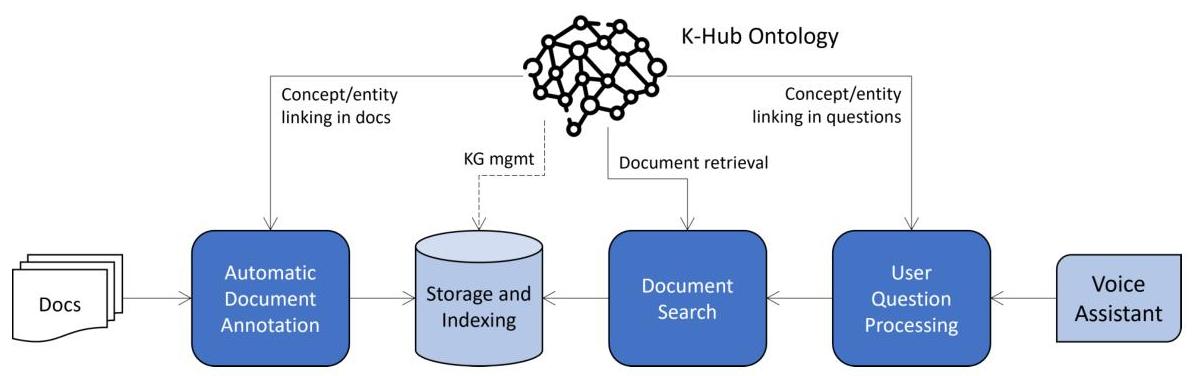
图5:K-Hub本体[57]在文档处理和搜索管道中的使用
从非结构化信息中提取知识
传统和新兴的自然语言处理技术可用于从文本和其他类型的非结构化来源中提取相关信息:当知识嵌入在文档(还有图片和其他多媒体格式)中时,通常会进行(命名)实体识别、关系提取和实体链接。目标是将非结构化信息转化为结构化描述,通常以知识图谱的形式,根据预定义的本体并可能链接到现有的知识库。
在流程和程序知识领域,有一些工作致力于从文本描述中自动或半自动提取相关信息,也利用了LLM功能[6, 54]。然而,全面解决这一挑战的整体方案尚不存在,因为文档可能是不完整的(例如,给出的假设信息、背景知识、常识、上下文数据)或需要专业知识才能解释和理解。此外,同一信息有时可以用相似但不同的方式显式化,这使得知识提取任务难以完全自动化[13]。
从人那里获取知识
为了正确从非结构化来源提取相关信息,当然也可以请有知识的人手动标注文档,尤其是在用户被引导识别和标注时采用明确的语义[55];然而,这种手动任务被认为是繁琐且昂贵的工作,而且非常容易出错。
此外,当知识完全没有文档化,而是隐含在人类专家的头脑中时,无法采用任何形式的手动或自动标注。在这种情况下,需要获取解决方案来引导用户收集和结构化他们的专业知识,以促进知识的转移和保存。无论是从文档中(半)自动提取知识还是从人那里获取知识,通常都会采用人在回路中的方法进行知识验证,正如[74]中所述:构建结合人类和机器智能的混合信息处理管道可以帮助在质量和成本之间找到最佳平衡。
4.3 与相互理解框架的关系定位
此情景中的主要知识来源是非结构化信息(尤其是文档)和再次是人(对于隐性知识);挑战在于填充和维护结构化来源以实现长期保存和访问。
本节中主要解决的相互理解问题是与知识共享相关,因为收集文档或人中的信息的目标是便于其他(人工或人类)用户日后重用。当信息被显式化和结构化后,所提取的信息也可能支持不同行动者之间的知识交换。最后,解决提取/获取挑战的整体神经符号解决方案还需要解决知识治理维度,因为它将有助于域知识的长期管理。
4.4 开放挑战和可能扩展
关于从文本中提取知识,目前有几种基于生成式AI的方法支持诸如实体识别和关系提取等任务[39, 27, 67];然而,这种提取的精度和可靠性仍然远未理想,特别是在文档没有包含完整的上下文知识时,因为它是隐含的或常识。
关于从人那里获取知识,如前所述,涉及领域专家是一项非常昂贵的任务,并且并不总是可行。为此,采用人在回路中的神经符号方法进行半自动标注/收集似乎是合适的研究方向,特别是采用混合和迭代策略:人们可以通过利用概念域模型(例如,给专家一个“结构”来跟随以使他们的知识显式化)或通过提供交互式解决方案来简化获取(例如,使用会话AI来促进知识披露[85])得到支持或指导。
5 案例3:信息系统间的互操作性
在本节中,我们解决了在信息系统间启用数据互操作性的问题。互操作性意味着协调异构数据源,以便促进集成和重用,即实现在需要有意义交换信息的不同信息系统之间实现相互理解。
5.1 问题场景
蒂亚戈在一家为城市环境实现交通管理数字解决方案的公司工作。特别地,他的团队开发了一套面向城市交通官员的决策支持系统(DSS),其中包括实时和预测的城市交通信息。该系统从多个信息源(例如公共交通车辆追踪、交通灯配置、监控车流量的摄像机等)收集数据,通过机器学习解决方案处理传入数据,并在交互式仪表板上显示当前和预测状态。
每当一个新的城市接近蒂亚戈定制DSS解决方案时,他都面临重大挑战。尽管存在(开放)数据平台收集潜在的输入数据源,蒂亚戈经常不得不处理不同的元数据模式和自定义API,这进一步复杂化了数据集成。他需要识别和理解每个可用的信息源,解码它们通常未记录的数据格式和约定,并进行广泛的数据预处理和转换以将这些数据集成到DSS中。
此外,蒂亚戈的团队需要历史数据集来支持为DSS开发定制的机器学习系统。这些数据集通常是不可用的,必须从实时数据源中收集。在这种情况下,根据公共数据格式协调数据对于考虑来自多个城市的不同信息源以训练模型至关重要。
这些任务是繁琐且昂贵的,但对于确保信息源与DSS解决方案之间的兼容性却是必不可少的。蒂亚戈正在寻求一种方法来简化实现每座城市不同信息源与其DSS之间相互理解的过程。
5.2 技术解决方案
在图6描绘的通用场景中,开放和私有数据目录描述并托管来自不同信息系统的数据。每个数据目录可能包含:(i) 不同格式和/或使用不同数据模型的数据集 (A, B, C);(ii) 依赖于不同规范和技术的数据服务 (I, II);(iii) 根据不同元数据规范描述的数据源 (d, e)。

图6:需要在信息系统间实现互操作性的通用场景。
定义解决这种异质性的适当解决方案并不简单,应面对五个挑战(定位、访问、协调、集成、提取)。
不可能找到单一解决方案来应对上述挑战,因为单个互操作性问题无法被明确表述[58]。实际上,确定的数据互操作性问题广泛多样,提出了各种需求,可能只有通过考虑适当配置的一组工具才能解决。
我们开发了一种端到端的数据互操作性解决方案,基于知识图谱技术解决了上述四个欧洲城市交通管理中的异质性问题[65]。所提出的解决方案如图7所示,处理上述挑战并提出了一组可以配置和扩展以解决通用领域互操作性问题的集成组件。
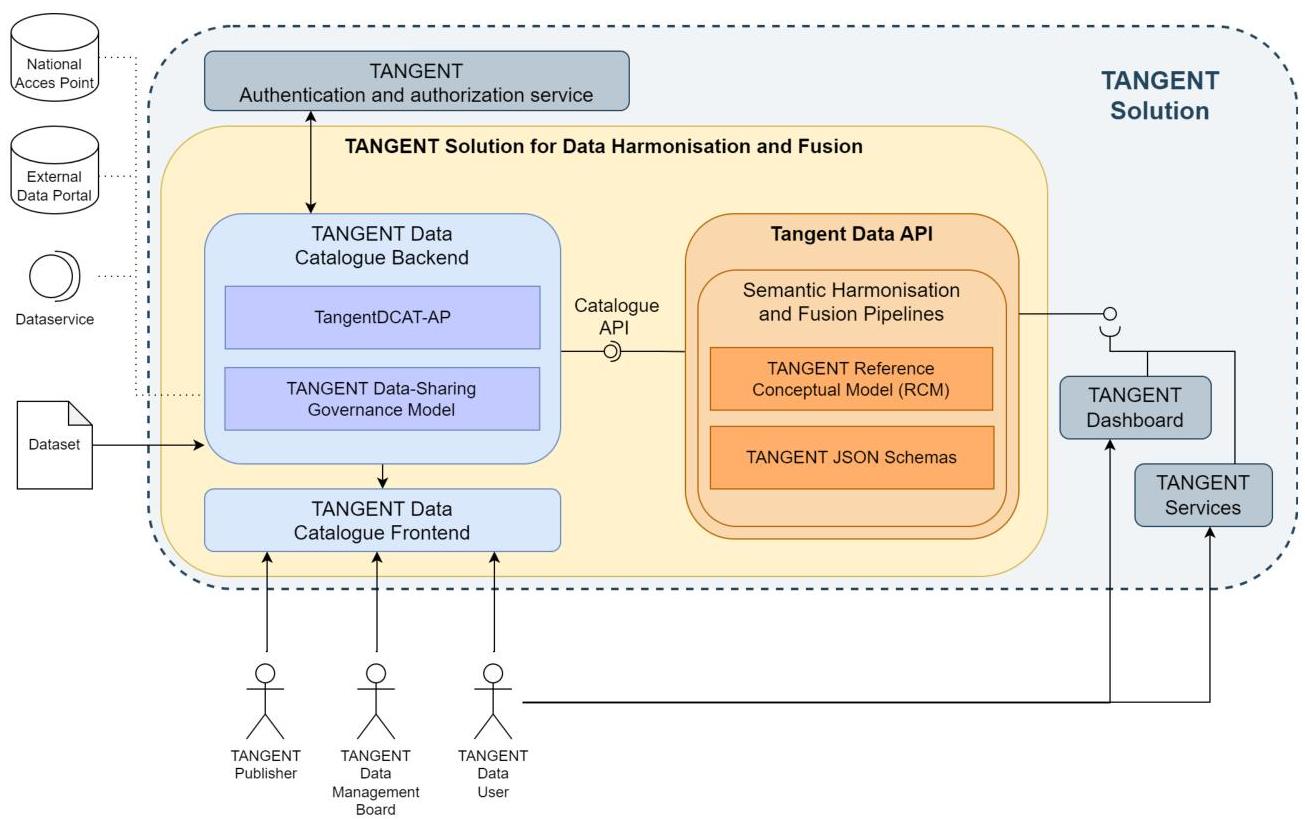
图7:TANGENT项目中的端到端数据互操作性解决方案。
第一个挑战是数据的可发现性和可查找性。如果数据无法被找到,则无法被重用和(实现)互操作性。因此,实施数据目录/门户以通过一组元数据描述数据源。挑战与需要适当的、结构化的和机器可读的数据源描述相关,该描述还可以支持不同数据目录之间的互操作性。一旦定位了数据源,第二个挑战与数据可访问性相关。数据目录采用不同的数据访问策略,主要与静态和动态数据源托管和存储的架构选择相关。挑战在于为外部信息系统提供对异构数据源的统一访问。
为此,所提解决方案的前两个核心组件是共享数据目录以实现数据源的可查找性,以及统一数据API以实现可访问性。数据目录提供用户界面和API以发现由其他数据门户收集或由用户直接描述和发布的所有相关数据源。通过采用基于知名词汇表(如DCAT-AP [77])的公共元数据规范,保证数据互操作性,该规范可以根据特定领域或客户场景的需求进行扩展。此外,作为用户与数据源交互的接入点,数据目录还支持根据公共数据共享治理模型[3]强制执行流程和规则。数据API提供对通过数据目录收集的数据源的统一访问,并作为下游信息系统访问数据源的集成点。
剩余的三个数据互操作性挑战(协调、集成和提取)与处理(元)数据以实现其集成和利用的共同语义相关。需要灵活的解决方案来解决以下方面的异质需求:(a) 模式和数据转换:信息操作以实现(元)数据的句法(结构)和语义互操作性;(b) 与现有信息系统作为数据源(即生成或存储数据的组件)和/或数据接收方(即消费或存档数据的组件)的集成。
可以采用和实施不同的方法,从针对特定场景的定制解决方案到支持多利益相关者和多种数据表示的更通用和可扩展的解决方案。基于[78]并经过[63]验证的语义任意映射方法减少了不同利益相关者实现互操作性所需的地图数量,即从一种表示到另一种表示的翻译数量。这种方法基于为感兴趣的领域识别参考模型。每个利益相关者负责定义从他们自己的数据表示到参考模型(提升)以及反之亦然(降低)的地图。此外,协调、集成和提取过程可能需要定义自定义的预处理和后处理,考虑不同的互操作性问题。
为了解决这些方面,确定了两个额外的组件以支持解决方案:参考概念模型定义共同语义和语义协调和融合管道的组成和配置。
参考概念模型支持通过常见的本体模型表示来自不同数据源的异构信息,以实现共享语义和互操作性。该模型基于现有的数据标准,采用正确的领域术语,并涵盖实现参与利益相关者之间有意义的数据交换所需的所有实体和属性的表示。
用于实现管道的灵活和可扩展技术应提供(i) 可根据特定需求配置的可重用构建块集合,以及(ii) 一种声明式方法来配置提升和降低转换,而无需开发定制且难以维护的解决方案。Chimera 2 { }^{2} 2 [29] 是一种基于Apache Camel的开源解决方案,用于定义带有不同组件的知识图谱构造、转换、验证和利用的语义数据转换管道。Chimera的优势在于其与Apache Camel的集成,提供了现成的和生产就绪的组件,以实现企业集成模式并将管道与异构系统(如HTTP API、WebSocket、MQTT)集成。
实现的管道在数据目录中记录,以发布新生成数据源的描述或将数据源的可用性描述为特定格式。数据API集成了管道的集成和执行,以根据请求的格式提供对数据源的访问。这种方法可以应用于协调异构元数据以实现现有数据门户的联合[12],或直接用于数据源的集成和融合[23]。此外,随着时间的推移应用管道以收集、协调和存储数据,可以用于生成机器学习模型的训练历史数据集。
5.3 关于相互理解框架的定位
与此场景相关的主要知识来源与信息系统管理的结构化元数据和数据有关;挑战在于实现此类知识的易于发现、访问和交换。本节提出的问题主要与知识交换挑战相关,因为相互理解问题主要涉及在信息系统之间实现有意义的数据交换的可能性。然而,采用共享概念模型也解决了知识共享维度,而目录和API层则旨在支持知识治理方面。
2 { }^{2} 2 https://github.com/cefriel/chimera
5.4 开放挑战和可能扩展
上述语义互操作性解决方案通过两种重要类型的工件促进了系统之间有意义交换信息的相互理解:(1) 数据和元数据模型,表示为本体、词汇表和元数据配置文件,(2) 编码不同来源和系统所采用的概念模型和数据格式之间对应关系的映射。考虑到第一种工件,尽管所提出的技术解决方案主要依赖于符号方法,但数据和元数据的互操作性对于支持机器学习的数据源检索和利用至关重要[2]。
关于后者,已经存在几种定义这些映射的方法。用于知识图谱构建的声明式方法可以有效支持到RDF的提升转换,但目前缺乏一种标准化的降低解决方案,以使用通用声明语言将RDF转换为任何格式[62]。除了映射的编码和执行外,一个众所周知的挑战是概念映射的识别,这是一个非常昂贵且耗时的活动。一些最近的方法旨在采用神经符号方法,通过利用语言模型识别概念之间的相似性并生成映射[48, 32, 31]。尽管完全自动化的映射生成尚未实现,但当前生成式AI解决方案的能力似乎很有前景,可以支持领域专家进行半自动的映射定义。未来的研究方向也可能调查利用非符号模型直接从一种格式转换为另一种格式的潜力。多代理方法可以通过非符号转换与符号验证结果的迭代修正合作来支持数据协调(例如,根据目标数据模式(如本体)进行符号验证)。
另一方面,开放挑战还与数据交换管道的配置有关。低代码和无代码解决方案已被提出以简化这些任务,并与从自然语言生成代码的技术集成可以进一步方便用户完成此任务[49]。
6 案例4:利益相关者之间的可重复性和可信性
在本节中,我们解决了在涉及不同利益相关者的数字环境中保证可重复性和可信性的问题,即通过数字工件实现不同角色和责任的用户执行的操作之间的相互理解。
6.1 问题场景
我们介绍了两个场景,其中多个利益相关者应在数字环境中合作并共同行动。第一个场景专注于监控依赖于基于AI的预测性维护方法的智能资产管理系统的部署、执行和使用。此场景涉及由不同利益相关者开发的组件的集成和重用,需要人与数据管道之间的相互理解。第二个场景解决了定义、应用和交换不同需合作和信任彼此的行为者之间的业务协议的挑战。目标是使涉及的利益相关者之间能够相互理解业务协议的条款和条件。
智能资产管理系统(IAMS)
Renzo 是一名基础设施经理,负责维护复杂的铁路网络。为了确保铁路的正常运营,Renzo 协调了一组不同的利益相关者,他们在数据管理、运行时交互和各方之间的信任方面面临着挑战。他们有不同的数字系统,包括用于管理维护活动的预测性和规定性机器学习模型,通过预测网络干预需求(例如未来的轨道维修工作)并安排实际的操作员工作(例如员工排班计划)。
如果事情没有按计划进行(例如,因维护问题导致网络故障),Renzo 必须审计人员和系统执行的操作,安全地重现发生的情况以确定根本原因,并将新知识注入系统,以确保未来的规划避免重复错误并从过去的经历中学习。Renzo 希望找到一种解决方案,可靠地执行和监控机器学习管道,并创建一个受信任的环境,以管理和协调不同的系统和人员,从而实现所有参与利益相关者之间的相互理解。
多模式运输的业务协议
新的拼车服务 RideWithMe 希望为司机和乘客提供可信的服务,以组织拼车并与其他运输运营商合作推广多模式旅程。通过 RideWithMe 订购的拼车可以看作是用户与提供拼车服务的司机之间的一项业务协议。每位司机可以被视为私人运输服务提供商(TSP),在特定路线提供运输服务。乘客同意支付一定价格以换取从某个地点到特定目的地的拼车服务。此类信息应以可信方式共享,以便 RideWithMe 可以确保司机与乘客之间的纠纷解决机制。RideWithMe 利用区块链和智能合约来确保各方之间的信任。同样,RideWithMe 和其他运输服务提供商同意使用智能合约来支持旅客的多模式套餐定义。在这两种情况下,即使共享数据模型确保了信息系统之间数据交换的互操作性,智能合约的实现依赖性使得难以使用适当的领域术语唯一表示协议的条款和条件。事实上,虽然采用区块链技术确保了可信性,但它影响了所实施业务协议的相互理解。
6.2 技术解决方案
所提出的技术解决方案利用知识图谱来支持多利益相关者环境中数据驱动解决方案的可重复性和区块链架构上的可信性。
IAMS 集成支持框架
采用智能维护解决方案需要从不同来源收集数据,实施特定的软件组件进行数据分析和可视化,并将它们集成以支持数据管道。一个重要的挑战在于部署这些解决方案并执行目标维护过程所涉及的各种利益相关者。
为支持这些挑战,我们提出了基于三个宏观功能的 IAMS 集成支持框架[61]:(i) 共享目录以增强数字工件的可发现性和可重用性(IAMS 共享目录);(ii) 集成部署和执行与智能维护场景相关的工件的运行时区域(IAMS 运行时区域);(iii) 区块链系统以处理用户执行的操作、工件和过程的监控和跟踪(IAMS 过程跟踪)。
图8提供了智能维护解决方案主要组件及其依赖关系的概述。我们确定了四种基本数字工件类型:数据集、软件组件、机器学习模型和维护计划。对于每种类型,我们定义了依赖于知名词汇表的元数据模式。
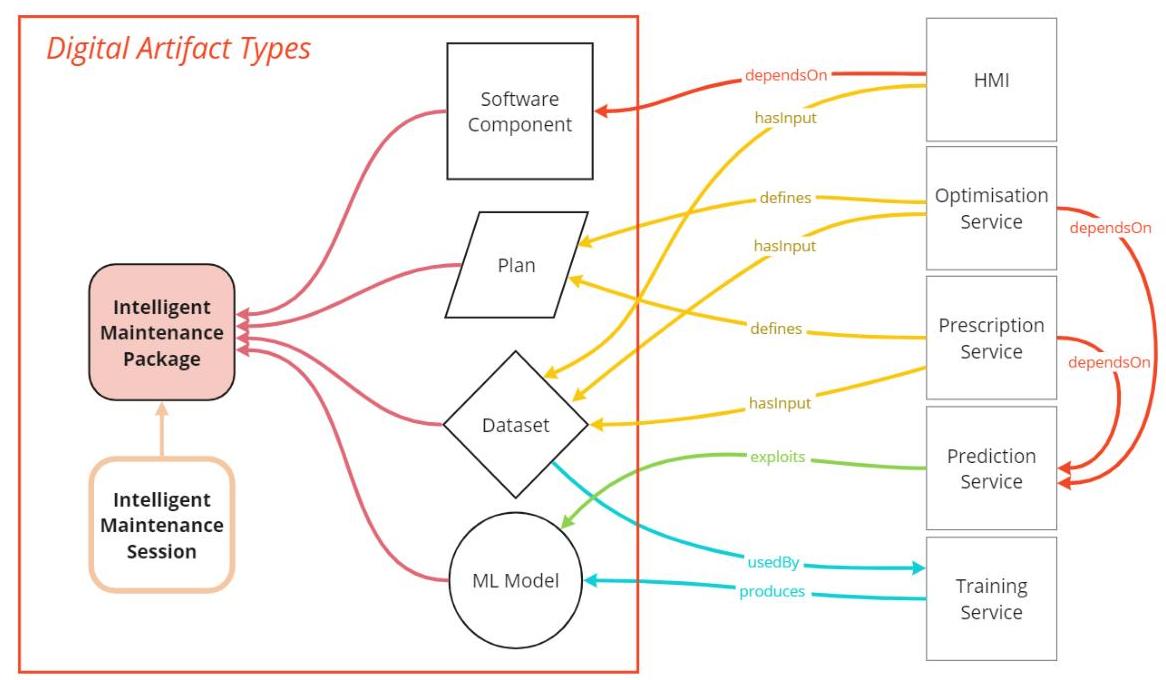
图8:IAMS 共享目录:工件类型及其依赖关系。
在整体维护场景下,仅单独描述和跟踪每个数字工件不足以促进可重复性。因此,定义了两种额外的数字工件类型以完整描述数字工件的依赖关系和使用情况:
- 智能维护包(IAM 包)描述了一个利用不同数字工件的维护场景,并可以在集成运行时环境中执行(例如,支持特定机器学习模型训练的数据集、训练软件组件和利用该模型进行预测/规定的组件);
-
- 智能维护会话(IAM 会话)描述了用户与组成智能维护包的数字工件交互时执行的操作信息(例如,某个用户请求使用不同超参数重新训练机器学习模型,然后生成基于训练模型的维护计划)。
- 包类似于第3节中提到的研究对象。它包含用于特定场景的数字工件的静态信息及其集成配置。会话包含运行时获得的包使用情况的溯源信息,例如生成机器学习模型的软件组件,并记录在区块链上。
- RO-Crate 规范可以支持此类信息的序列化。每个数字工件可以被视为 RO-Crate 中的资源,使用特定的元数据集。
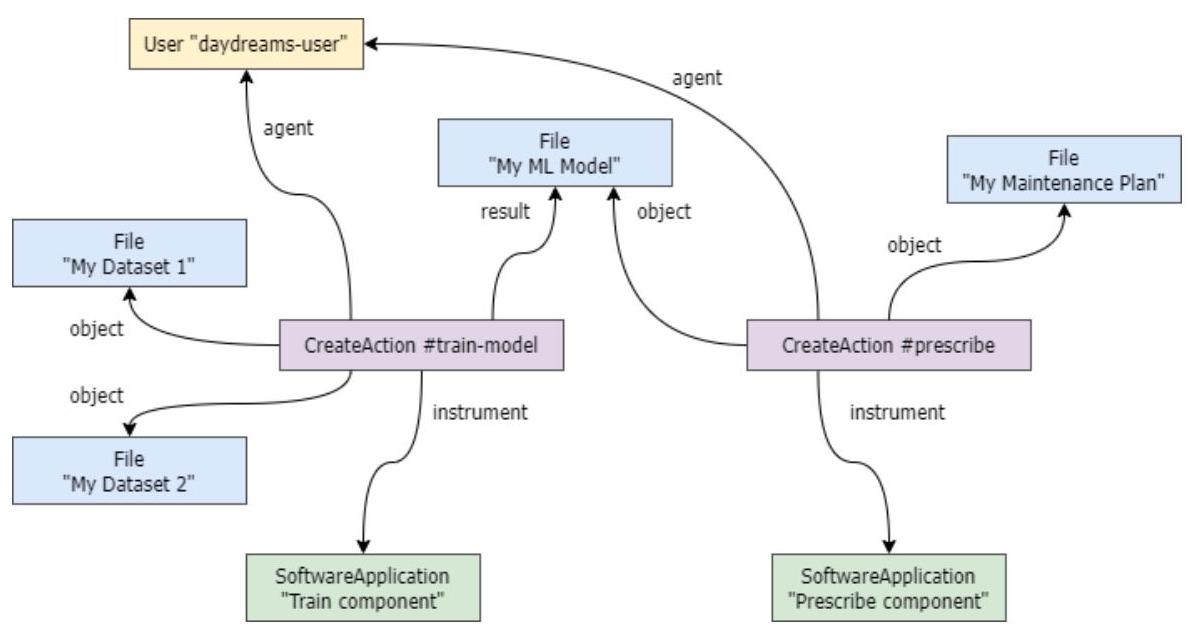
图9:DAYDREAMS项目中智能维护场景的Process RO-Crate示例。
考虑智能维护会话,Process RO-Crate配置文件[83]可用于表示包中数字工件的生命周期操作以及IAM会话内执行的所有运行时操作。图9展示了一个示例Process RO-Crate,描述了两次操作(紫色的CreateAction实体)、它们与特定数字工件(蓝色的File实体、绿色的SoftwareApplication实体)的连接以及执行这些操作的用户(黄色的User实体)。训练模型操作通过识别请求训练的用户、使用的数据集、执行的软件组件和产生的机器学习模型来描述。类似地,处方操作可通过识别请求处方过程的用户、使用的机器学习模型、执行的软件组件和产生的维护计划来描述。
将此类信息作为数字工件集成到共享目录中,支持通过IAMS集成支持框架实现的智能维护场景的可重复性和可信性。
本体智能合约用于多模式运输
在一个包含各种利益相关者的生态系统中,通过分布式账本实施业务协议提供了关于信息信任和已商定条款自动执行的若干好处。然而,这种方法并不能保证从技术和语义角度来看所定义协议的互操作性。一方面,所涉利益相关者共享的领域术语应由所建模的实体引用;另一方面,其他软件系统可以从协议的机器可读表示中受益。
我们提出了一种使用本体描述区块链上实现的智能合约的解决方案[64]。本体智能合约[11]的概念可用于建模业务协议的语义。应执行以下步骤:(i) 调查要在所考虑场景中建模的业务协议(用例和用户故事),(ii) 分析业务协议覆盖的领域术语(事实和胜任力问题),(iii) 识别覆盖相关领域实体和关系的现有词汇表,或实现支持其表示的本体,(iv) 建模每个业务协议,识别涉及的实体和协议条款,并可选地(v) 使用本体表示存储在账本上的业务协议的具体实例。这样,不同的利益相关者可以通过统一术语访问智能合约的描述及其可能的实例。
Ride2Rail协议本体(https://w3id.org/ride2rail/terms#)支持将此概念应用于上述多模式运输场景中的业务协议互操作性。拼车预订被建模为司机和乘客之间的协议,用于争议解决,以及不同运输服务提供商之间定义多模式包的协议。RDF数据集与建模的协议一起发布在https://w3id.org/ride2rail/agreements#,图10报告了拼车预订协议。
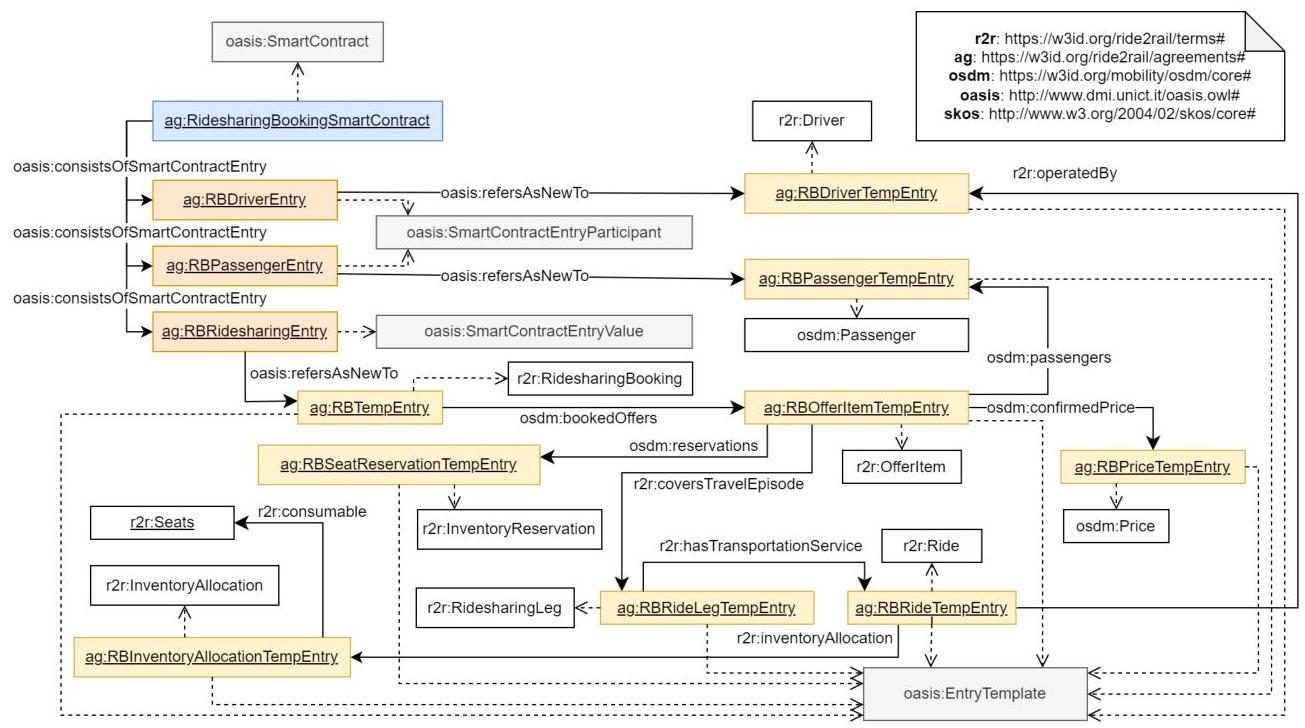
图10:描述RidesharingBookingSmartContract协议的图表
这种方法解决了相互理解的两个需求:(i) 以独立于实现的方式描述根据特定区块链解决方案定义的智能合约,(ii) 采用适当且共享的术语描述领域实体及其关系。
6.3 关于相互理解框架的定位
此情景中的主要知识来源是溯源信息,以保证用户和软件组件执行操作的可重复性和审计。挑战在于在保证利益相关者之间信任的同时追踪和收集相关信息。本节中主要解决的相互理解问题是与知识治理方面相关,因为最终目标是让不同的利益相关者正确操作并相互信任:所提出的解决方案允许以可信方式监控和审计互联的系统。所讨论的IAMS解决方案展示了符号方法如何支持神经方法的治理,实现管道的可重复性和执行操作的审计。
在解决治理方面时,目录还提供了一个环境以共享和访问相关工件(数据集、软件组件、机器学习模型等)及其各自的依赖关系,也符合FAIR原则,从而直接解决了知识共享方面的问题。这一点通过采用研究对象方法得到了加强,以实现先前会话的可重复性和理解。在解决知识治理方面时,区块链提供了一种信任机制,应通过共享概念模型(知识共享)来补充,以确保参与方之间的相互理解。
6.4 开放挑战和可能扩展
本节讨论的主要开放挑战与神经符号方法的整合有关,不仅作为混合算法的一部分,还支持数字工件的共享和治理。采用结构化元数据描述可以促进它们的可发现性和重用,如第5节中讨论的那样,但不应仅限于孤立和静态信息。关于不同数字工件如何组合以及它们在运行时使用的信息是可重复性的关键要素。在这方面,可以通过追踪组件之间的交互并进一步为神经符号组件进行更细粒度的审计来检索额外信息[9]。
另一个挑战与采用完全符号化方法编码和传达业务协议的所有相关细节的困难有关。实际上,协议常常利用难以用逻辑编码表示的法律术语的模糊边界。在这种情况下,可以采用大型语言模型(LLM)将业务协议条款结合到结构化和非结构化格式中,并为涉及的用户提供自然语言解释和答案。
7 案例5:构建共享时空理解
在本节中,我们解决了构建可靠的全球模型以支持机器人和自主代理理解复杂部署环境的问题。Lake等人最初提出了这一模型构建过程[40],作为实现机器人类智能的基本要求之一。然而,构建和维护准确的世界模型对于实现相互理解也至关重要,无论是在期望机器人服务于人类的情况下[4],还是在混合团队中机器人和人类合作实现共同目标的情况下[73]。
在此背景下,模型构建问题可以被视为设计一种统一的环境表示,该表示既可被机器读取又可被人理解。因此,模型构建概念与长期以来将观察和原始感官信息接地到符号的问题高度相关[24, 7]。在机器人学领域,针对此问题的努力已巩固了语义地图的提议,即“除了关于环境的空间信息外,还包含映射特征与已知类别的实体分配”的世界模型[47]。因此,语义地图提供了一种介于从环境中直接学习的次符号特征和可以映射到自然语言的语义符号之间的中间表示。因此,正如[19]中所述,语义地图是神经符号系统的典型例子,它综合了不同数据驱动和知识驱动组件的输入。理想情况下,语义地图不仅应具有空间上下文,还应反映目标环境的演变,提供机器人观察和活动的时空记录(例如,导航路径上遇到的航路点和物体集合)。
在本节剩余部分中,我们探讨了一种基于语义地图的模型构建方法,并在辅助机器人场景中实例化该通用方法,以从相互理解的角度讨论此解决方案的潜力。
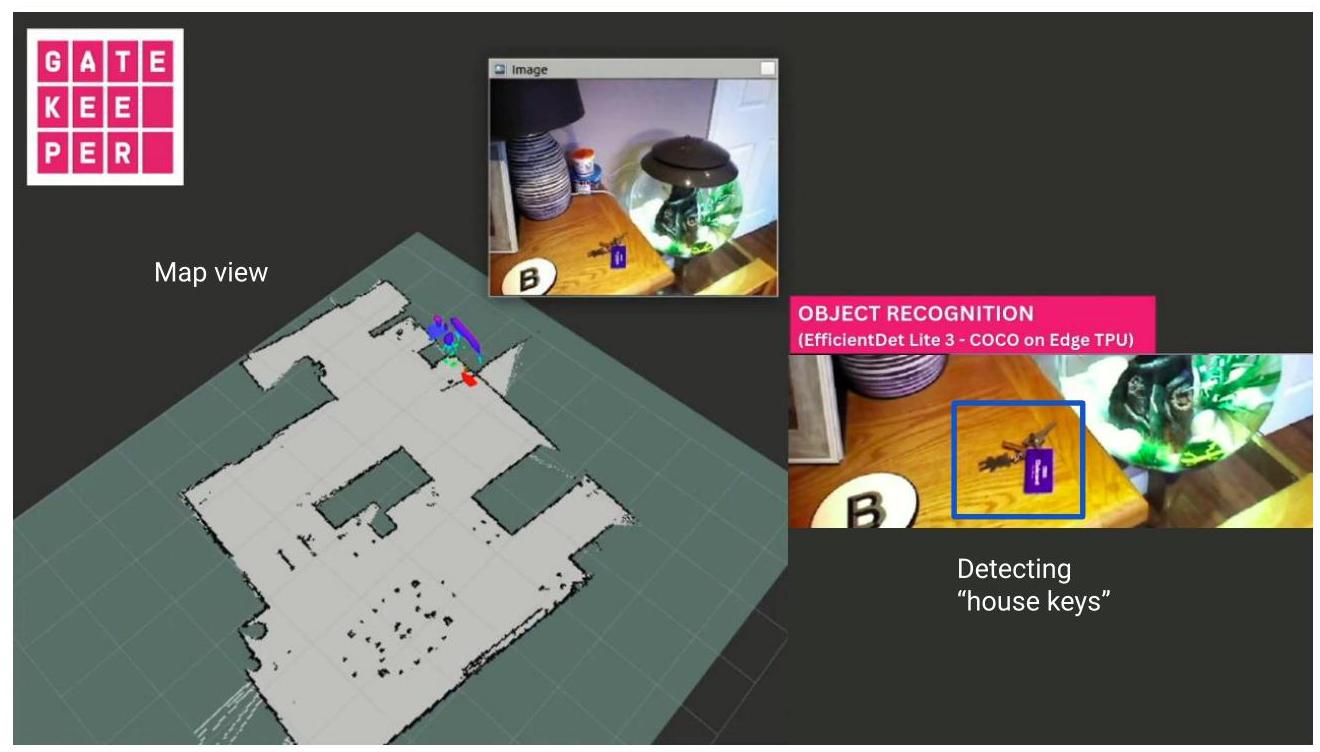
图11:对象检索例行程序的可视化。图片由Gatekeeper EU项目联盟提供。左侧:通过机器人摄像机收集的深度测量值(多色)投影到房屋平面图的二维布局上。右侧:RGB图像流被馈送到对象识别模块以检测个人物品的存在。
7.1 问题场景
布莱恩是约翰的主要护理人员,约翰开始表现出轻度痴呆症状。约翰经常放错房子钥匙的副本,并忘记他把东西放在哪里,比如他的拐杖或眼镜。布莱恩决定加入一项试点研究,在选定的家庭中部署商业人形机器人,以帮助照顾在家中的老年患者,而他们的护理人员不在时。因此,该场景涉及人类和机器人代理之间的互动。
在机器人交付到房子的那天,进行这项研究的研究团队设置了平台,以绘制布莱恩房子的整体布局。这份2D地图将为机器人在未来监控轮次中定位自己提供基础。
研究人员希望测试机器人根据指示准确检索约翰个人物品的频率。在初始设置阶段,用户选择了一些机器人必须学会识别的对象。当巡逻时,机器人识别并记录这些物品的位置。随后,用户可以请求机器人的帮助来检索特定对象。由于所测试的解决方案仍在开发中,机器人只是找到物品并通知用户,而不会实际抓取任何物品,以避免损坏设备和引发事故。图11提供了对象检索例行程序的示例可视化。
7.2 技术解决方案
为了满足移动机器人在导航过程中监测环境的要求,我们开发了一种解决方案,该方案包括物体识别和空间推理能力。重要的是,所提出的框架对机器人视点和物体方向的变化具有鲁棒性。事实上,随着机器人移动,其视点会随时间变化。此外,观察到的物体可能有不同的空间方向。因此,我们引入了一个情境化的参考框架[20],允许根据机器人的视点和附近物体的位置(例如,“花盆植物左边的车钥匙”)解释空间物体的配置。在所提出的框架中,几何空间运算符也被映射到自然语言中的常见空间谓词,以确保用户的指令(例如,“把厨房桌子上的杯子拿给我”)能够适当地解析并与相关的几何操作链接。
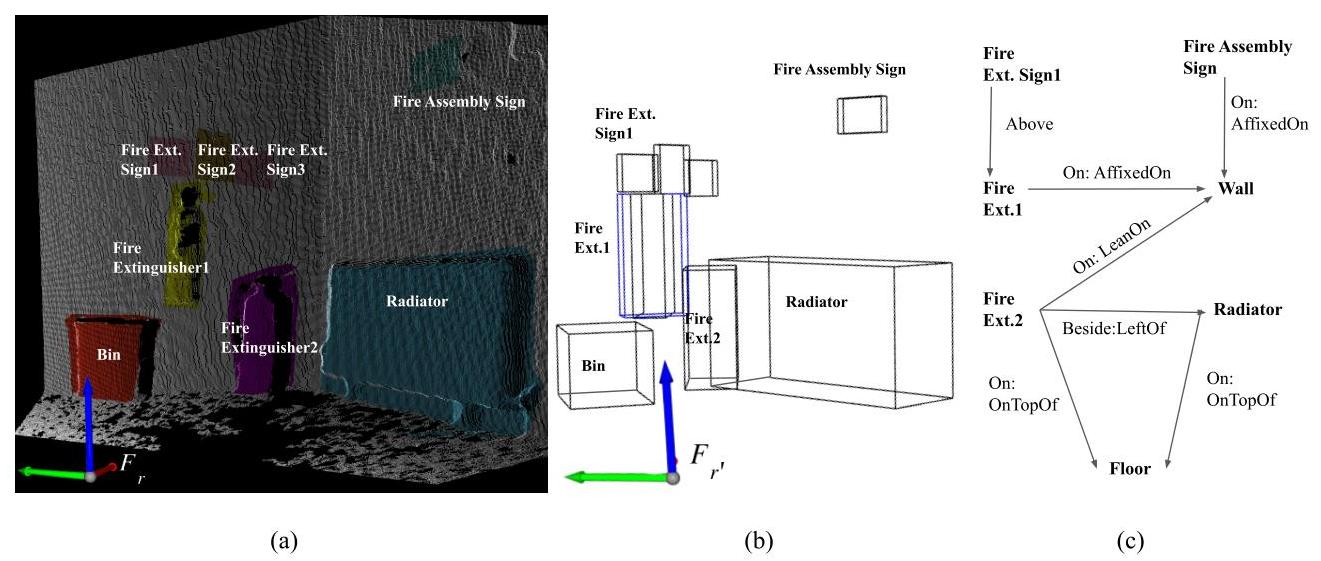
图12:操作工作流程示例,摘自[20]:(a) 对观测场景的点云进行分割并标注物体类别。然后,(b) 构建最小定向边界框和情境化边界框(蓝色)。最后,© 推导出一组定性空间关系。
该解决方案的核心是语义地图的构建。也就是说,在机器人设置阶段获取的2D布局地图通过关于物体性质(例如,椅子、桌子)、房间标签(例如,厨房、卧室)以及物体之间关系(例如,靠近桌子的椅子、走廊中的电缆)的语义信息进行了增强。实际上,我们将通过机器人RGB-Depth (RGB-D)相机识别的物体实例表示为存储在空间数据库中的锚点。锚点是通过聚合物体识别模块返回的多次测量结果形成的物理物体的3D抽象。
在每个时间帧中,测量机器人姿态与深度传感器激光检测表面的距离。这些数据,称为深度图像,可以在给定参考框架内转换为3D几何点的集合,即点云。访问点云测量值使我们能够通过将分段点云应用凸包算法转换为最小定向3D盒子来表示物体区域的2D边界框。我们将生成的空间锚点存储在PostgreSQL数据库中,以便利用PostGIS引擎和SFCGAL后端提供的3D空间运算符。借助这些空间运算符,我们可以计算检测到物体之间的空间关系。图12展示了从原始RGB-D数据提取空间关系的操作步骤。关于我们将PostGIS运算符映射到自然语言中表达的空间谓词(例如onTopOf、near、affixedTo、LeftOf等)的资格过程的更多细节,请参见[20]。
锚点本质上与机器人的感知相关联。因此,除非机器人检测到某个物体,否则该物体的锚点不存在。同样地,如果没有任何新感知确认其当前位置,则必须从语义地图中移除该锚点。通过PostgreSQL数据库中的自动触发器处理锚点生命周期。具体而言,现有锚点会通过与3D边界盒质心位置匹配的最新测量结果保持更新。每当接收到无法与任何现有锚点匹配的新测量结果时,就会生成一个新锚点。
对于物体识别模块,我们依赖于少量学习(FSL)方法,可以从有限的训练样本中学习,即仅在机器人设置阶段收集的目标个人物品的几张照片。此外,我们优先考虑能够在机器人上通过Edge TPU USB供电设备进行微调的轻量级模型。
实施的解决方案提供了一个共同的世界模型,即使当机器人助手不是唯一用于收集环境数据的设备时,也可以进一步扩展。智能家居传感器,例如,可以补充机器人的观察结果[4],例如通过智能手表或健身追踪器推断患者的地点。在这种情况下,语义地图提供了一个统一的模型来协调来自多个来源和模式的数据。
7.3 关于相互理解框架的定位
模型构建问题主要与相互理解的知识共享维度一致。确实,本节介绍的语义地图充当了机器人感知、外部环境传感器数据收集和用户请求之间的公共概念模型。通过语义地图,机器人和人类操作员可以访问基于深度学习的对象检测模型产生的感知预测,以及空间引擎计算的对象间语义关系。
为了在本场景中涉及的人类和人工行为者之间达成共同基础,已经探索了两种具体干预措施。首先,我们采用了更清楚地表达机器人视点的参考框架,从中推断出物体的相对位置(“咖啡桌上的钥匙”)。这种配置提供了一种替代方案,而不是直接依赖地图坐标系统(“主门北侧的钥匙”),后者对用户来说不够直观。其次,我们将用于从传感器数据中提取空间关系的几何空间运算符映射到自然语言中常用的描述物体间空间关系的语言谓词(例如near、rightOf)。
总之,所提出的表示模型为以下方面提供了更透明、更容易理解的界面:i) 直接与机器人互动的患者和护理人员;ii) 评估机器人理解环境能力的研究人员。
7.4 开放挑战和可能扩展
准确且可靠的世界模型构建仍然是一个开放挑战,上述解决方案开辟了许多扩展机会。以下,我们主要关注那些直接影响实现机器人与用户之间相互理解目标的改进方向。
上一节描述的解决方案意味着每当用户要求机器人检索特定对象时,只会访问该对象的最后一个已知位置。如果找不到该对象,则会搜索整个空间以更新语义地图。从导航角度来看,这种方法并不理想,并忽略了可以从先前与用户的交互中得出的关键信息先验。例如,用户可能会反复将某些物品留在典型位置,机器人可以在搜索其他区域之前访问这些位置。这种扩展有助于更明确地揭示促成相互理解的隐含用户模式和规范。它也为越来越多专注于从单个图像示例进行基于目标导航的工作提供了另一种探索方向[43]。这些完全神经管道通过端到端优化联合学习地图构建和符号接地。因此,它们限制了在环境条件变化下的特征重用[33],并且没有充分利用对监控环境的先前知识。
此外,所提出的解决方案在处理锚点更新时并未区分对象类别。然而,像家具和大型电器(沙发、冰箱、电视柜)这样的对象不太可能改变位置,而可移动对象(如个人物品、椅子和餐具)则需要更频繁地重新映射。这是我们人类在视觉上处理世界时潜意识理解的内容。事实上,只有在出现变化时,我们才会评估先前构建的心理模型,从而使我们的信息处理最为高效[68]。另一个有助于在机器人助手和人类之间建立共同认知基础的关键扩展可能是提取和整合代表对象时空轨迹的相关常识知识[21]。
上述扩展主要涉及相互理解中的知识共享。从知识交换的角度来看,所讨论的解决方案覆盖范围非常有限。在此配置中,机器人接收用户指令并开始搜索目标对象,而不会将其计划和活动反馈给用户。然而,建立双向互动将显著促进双方的相互理解,尤其是在需要适应性切换不同任务的情况下。最近基于大型语言模型(LLMs)的解决方案进展可以显著促进这一缺失环节的集成。尽管当前最先进的LLMs在有效管理机器人规划任务方面的能力有限[36, 37],但它们无疑是将编程动作(即代码)翻译和总结为自然语言的强大工具。
通过赋予辅助机器人从隐式反馈中推断患者请求的能力,这一改进可以进一步扩展。例如,在本节的动机场景中,患者表达的“外出散步”意图可以触发机器人寻找拐杖。这些隐式的用户偏好和模式可以通过直接与用户互动并观察环境来学习,从而克服为用户特定约束建模的负担。因此,此功能最好由神经方法支持,例如强化学习解决方案[44]。学习适应性机器人行为与提取典型对象位置相结合,直接有助于巩固用户对系统的信任和接受度,并促进知识治理维度。
8 案例6:机器人决策的混合推理
为了在真实世界环境中可靠运行,自主机器人应配备先进的推理和决策能力。如前所节所述,访问准确的世界模型只是方程式的一部分:还需要高级机器人决策方法 [34]。具体而言,为了确保自治代理与用户和与机器人互动的人员之间达成相互理解,至关重要的是确保这些决策过程以受控和透明的方式进行。
这一要求在安全关键应用中尤为重要,例如搜救行动、运输和医学。在这种具有挑战性的环境中,通过从感官层面获取的信息自下而上学习和推理的能力需要与关于环境的自上而下的认知期望有机结合 [25]。也就是说,通过次符号学习自下而上收集的观察结果应与建模环境的符号知识相结合,这与神经符号人工智能(NeSy) [59] 的定义一致。事实上,随着环境复杂性的增加和不确定性(即不完整和冲突的信息)的存在,低级别的模式识别和感觉运动技能不足以成功解决问题。应涌现出基于知识的行为,其中随着时间积累的心理模型支持特定计划的制定和选择 [25]。
在本节其余部分中,我们将以监控办公环境健康与安全的机器人助手为例,讨论构建支持混合(自上而下和自下而上)推理的神经符号系统的优势和开放挑战。
8.1 问题场景
健康与安全机器人检查员(HanS)预计会定期巡逻办公环境,以发现任何潜在的员工健康与安全危害原因。因此,类似于前一场景,这个用例涉及人类与机器人代理之间的互动以实现共同目标。
HanS 应当解释环境的当前状态以识别任何潜在风险。首要任务是稳健地识别物体。此外,HanS 还需考虑表征所观察物体的不同属性。此外,机器人应当了解任何约束条件,这些约束条件影响环境的安全性。
最终,给定一组观察到的物体及其相关属性和一组约束条件,机器人必须选择最适用于观察情况的健康与安全规则。如果检测到任何违反这些规则的情况,HanS 必须立即通知指定的消防管理员。
8.2 技术解决方案
为了解决通过移动机器人自主评估观察情况风险的问题,我们开发了以下模块。
语义制图 如前一用例中所述,自主构建表示机器人操作环境的语义地图。在此案例中,我们扩展了前一节中介绍的接口,允许用户在地图上注释感兴趣的区域(AoI)。对于 HanS 案例研究,我们定义了三种类型的 AoI:(i) 消防逃生路线,(ii) 垃圾收集区,以及 (iii) 表示消防呼叫点的区域。然而,同一接口可以无缝应用于定义其他类型的 AoI,如房间、特定产品存储空间或其他与最终应用相关的地标。地图(及相关空间数据库)通过以下模块生成的锚点填充。
3D 物体锚定。通过深度学习从机器人摄像机收集的 RGB 图像流预测物体预测(即其类别和 2D 边界框)(图13a)。生成的边界框用于分割原始点云,产生可以存储在空间数据库中的 3D 物体区域,以计算每个物体的大小和空间关系。如果两个观察的 3D 箱中心点之间的距离小于预定义阈值(以欧几里得距离表示),则将不同的观察链接到同一个物体(即锚点)。
尺寸和空间推理。基于估计的每个锚点的大小和空间关系,依靠支持知识库自主纠正通过深度学习(DL)选为“潜在不正确”的预测。具体而言,我们考虑了物体典型大小和空间关系的先验知识,这些知识从外部知识库(例如,马克杯通常比扶手椅小;灭火器通常固定在墙上)重新利用,以
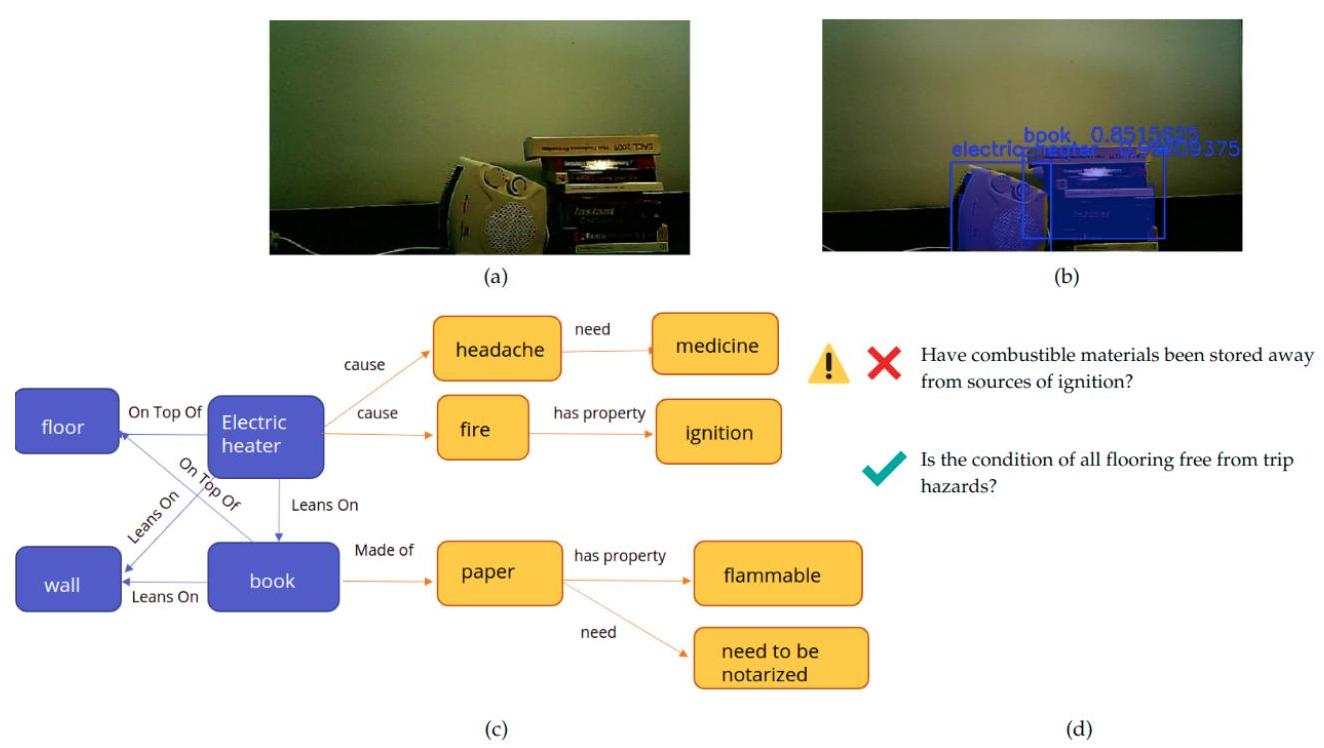
图13:发现电加热器靠近一堆书。由于易燃物接触到了点火源,这种情况代表了一个潜在的火灾隐患。
修改深度学习算法返回的预测排名。具体来说,我们从ShapeNet [60]、亚马逊和手动收集的测量数据中获取了典型尺寸,而典型空间关系则从Visual Genome [38]中提取。关于此阶段的更多细节请参见[22]。
场景图生成。合并的物体锚点和提取的空间关系用于构造场景图,即节点表示场景中物体、边表示不同物体之间关系的图。依靠这种表示允许我们自主丰富图,添加表达物体属性的附加符号知识作为三元组(主体,谓词,客体:例如,纸张是易燃的,图13c)。具体来说,我们从ShapeNet和其他因果及材料属性相关的资源Quasimodo [53]中检索物体制造材料(例如,书由纸制成)。重要的是,场景图格式使得应用基于规则的推理技术成为可能,以验证健康与安全规则的任何违反情况,如图13d所示。为此,我们将消防管理员检查清单和内部文档中的规则形式化为一阶逻辑(FOL)公理。
8.3 关于相互理解框架的定位
与前一节类似,此案例根植于机器人的模型构建能力,因此与知识共享维度密切相关。除了作为总体世界模型的语义地图外,场景图也被引入为描述连续帧序列的另一个关键表示。然而,HanS用例也在相互理解的另外两个要素上作出了初步贡献。
关于知识交换维度,所提出的NeSy框架利用大规模知识库预先整理的集体知识:i)自主验证并通过深度学习生成的机器人的预测,ii)丰富生成的场景图,添加相关的情境知识,包括物体属性和制造材料。
最终,机器人的风险评估受到一组参考规则的监管。我们从安保人员遵循的标准实践和规则手册中提取这些规则,并将其形式化为可以直接针对场景图进行测试的格式。这一步骤有助于解决相互理解中的知识治理挑战。
总的来说,本用例情景中交换和访问的知识来源类型涵盖了从用于通过深度学习方法分类物体的潜在表示到结构化知识库(如Quasimodo、Visual Genome和ShapeNet)以及描述安全规则的形式逻辑约束。
8.4 开放挑战和可能扩展
近期视觉语言模型(VLMs)在大规模图像和文本集合上预训练的发展加速了场景理解和场景图生成任务的进步[80, 18]。因此,所讨论的解决方案可以通过查询VLM而非分别设置物体识别和场景图生成两个独立模块来显著更新。从相互理解的角度来看,与VLM对话会增加用户在机器人活动中的参与度。例如,计算机视觉任务将以对话格式表达(例如,“你在这幅场景中看到了哪些物体,它们的位置在哪里?”)。然而,在这种背景下,场景图仍然是补充文本提示的重要表示工具。首先,嵌入提示中的场景图已被发现增强了VLM在视觉任务中的组合推理能力[45]。此外,场景图可以为与机器人互动的用户提供图形辅助,以理解和验证模型响应,使机器人的推理功能更加透明。
前一节中提出的神经符号推理流水线虽然利用自上而下和自下而上的推理从图像中推断物体类别,但仅在一个方向上运行:建模机器人环境的背景知识引导对次符号预测的修正。然而,可以建立有价值的反馈循环,其中机器人自下而上的环境观察告知新知识的生成,从而形成完全双向的NeSy流水线。这一改进尤其有助于提取隐性知识。事实上,隐性知识往往在日常互动中被视为理所当然,因为我们通过经验达到相互理解,因为它主要通过经验学习,且本质上难以表达和形式化[26]。
9 综合与相互理解的开放挑战
在本章中,我们总结了一系列知识图谱和神经符号AI方面的努力,并通过相互理解维度的视角对其进行了分析。所调查的工作涉及非常不同的方面:参与的代理(人类、数字和机器人),知识类型(隐性与显性、声明性与程序性与因果性),此类知识的来源(人类、数据、文档、媒体),以及采用的AI技术类型(符号、神经、神经符号)。虽然我们不声称我们的分析是详尽无遗的,但我们涵盖了一系列广泛的现实世界案例,各自有其需求和挑战,我们的愿望是这些具体而务实的例子可以作为激励研究方向和应用系统设计的依据,以为广大利益相关者提供影响[17]。
表1:解决相互理解挑战的符号和神经方法汇总(单元格中,颜色越深且标记为H表示覆盖率越高,颜色较浅且标记为L表示覆盖率较低)。
| 使用场景 | 共享 | 交换 | 治理 | |||
|---|---|---|---|---|---|---|
| 符号 | 神经 | 符号 | 神经 | 符号 | 神经 | |
| 人类数据收集与分析 | H | L | L | L | L | |
| 知识提取与获取 | H | H | L | L | L | |
| 信息系统间的互操作性 | L | H | H | L | ||
| 可重复性和可信性 | H | L | H | L | ||
| 构建共享时空理解 | H | H | L | L | ||
| 混合推理用于机器人决策 | H | H | H | H | L |
表1以图形方式总结了所展示场景中相互理解三个主要维度——知识共享、交换和治理——的达成水平。
关于共享知识维度,显然现有的解决方案,特别是在符号AI领域的解决方案,已经很好地覆盖了这一挑战:概念模型和结构化数据,特别是当其附带清晰的语义时,是不同代理之间真正相互理解的基础。在这方面,神经方法已被用于知识提取、场景理解和意义解读。仍存在通过混合神经符号AI解决方案进一步发展知识共享的明显潜力,这些解决方案结合自下而上与自上而下的领域和情境语义模型,提供更丰富和更有用的世界表示。
我们还强调了符号和神经方法在应对知识交换挑战方面的若干贡献:尽管不同代理之间的互动总是需要一些定制配置和协议以实现交换,但已有几个方向可见。数据互操作性是实现系统之间有意义交换的核心成分,而神经符号方法无疑可以帮助通过自动化某些步骤减少人力成本。特别是,大规模生成式AI系统的出现可以支持新一代会话代理,丰富和支持代理之间的沟通,从而实现知识交换。
需要进一步关注和研究的挑战与知识治理维度相关:在AI法案[28]时代的背景下,找到解决方案以完成管理代理之间互动的过程、角色和规则这一微妙任务已成为强制性要求。存在许多解决治理问题的符号方法,特别是通过提供工件、业务协议和约束的显式表示;也有几种方法从数据和背景知识中提取隐式规范和模式。我们认为,将神经符号AI应用于治理挑战将导致更多解决方案,以迭代和协作方式让不同利益相关者和代理参与,就调节他们关系和互动的过程和规则达成相互理解。
致谢
作者感谢Antonia Azzini、Ilaria Baroni、Alessio Carenini、Valentina Carriero、Marco Comerio、Marco Grassi、Gloria Re Calegari、Enrico Motta、Gianluca Bardaro、Alessio Antonini和Enrico Daga在本章总结的研究工作中提供的宝贵合作。这项工作部分由PERKS项目(资助协议ID:101120323)资助,该项目由欧盟委员会在Horizon Europe框架计划下共同资助。
参考文献
[1] Fatema Akbar, Ted Grover, Gloria Mark, and Michelle X Zhou. 虚拟代理特征对用户印象和语言使用的影响。《第23届国际智能用户界面会议附属出版物》,第56页。ACM,2018年。
[2] Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Pieter Gijsbers, Joan Giner-Miguelez, Nitisha Jain, Michael Kuchnik, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Pierre Ruyssen, Rajat Shinde, Elena Simperl, Goeffry Thomas, Slava Tykhonov, Joaquin Vanschoren, Jos van der Velde, Steffen Vogler, 和Carole-Jean Wu. Croissant: 一种适用于ML准备数据集的元数据格式。《第八届端到端机器学习数据管理研讨会论文集》,DEEM '24,第1-6页,纽约,NY,美国,2024年。Association for Computing Machinery.
[3] Antonia Azzini, Marco Comerio, Sabino Metta, 和Mario Scrocca. TANGENT治理模型用于移动数据共享。《交通转型:推进可持续和包容性移动 - 第10届TRA会议论文集》,Lecture Notes in Mobility. Springer, 2024.
[4] Gianluca Bardaro, Alessio Antonini, 和Enrico Motta. 家庭老年人护理机器人:景观分析和协同设计工具包。《国际社交机器人杂志》,14(3):657-681, 2022.
[5] Khalid Belhajjame, Jun Zhao, Daniel Garijo, Matthew Gamble, Kristina Hettne, Raul Palma, Eleni Mina, Oscar Corcho, José Manuel Gómez-Pérez, Sean Bechhofer, Graham Klyne, 和Carole Goble. 使用一系列本体保存以工作流为中心的研究对象。《Web语义学杂志》,32:16-42, 2015.
[6] Patrizio Bellan, Mauro Dragoni, 和Chiara Ghidini. 使用预训练语言模型和上下文学习从文本中提取业务流程实体和关系。《企业设计、运营与计算国际会议论文集》,第182-199页。Springer, 2022.
[7] Andrea Bonarini, Matteo Matteucci, 和Marcello Restelli. 锚定:我们需要新的解决方案来解决旧问题,还是我们已经有了解决新问题的旧方案?《AAAI关于单个和多个机器人系统中将符号锚定到传感器数据的研讨会论文集》,第79-86页,2001.
[8] Grady Booch, Francesco Fabiano, Lior Horesh, Kiran Kate, Jonathan Lenchner, Nick Linck, Andreas Loreggia, Keerthiram Murgesan, Nicholas Mattei, Francesca Rossi等. 在AI中快速和缓慢思考。《AAAI人工智能会议论文集》,第35卷,第15042-15046页,2021.
[9] Anna Breit, Laura Waltersdorfer, Fajar J. Ekaputra, Sotirios Karampatakis, Tomasz Miksa, 和Gregor Käfer. 结合语义网和机器学习进行可审核的法律关键元素提取。在Catia Pesquita, Ernesto Jimenez-Ruiz, Jamie McCusker, Daniel Faria, Mauro Dragoni, Anastasia Dimou, Raphael Troncy, 和Sven Hertling编辑的《语义网》中,第609-624页,Cham, 2023. Springer Nature Switzerland.
[10] Anna Breit, Laura Waltersdorfer, Fajar J Ekaputra, Marta Sabou, Andreas Ekelhart, Andreea Iana, Heiko Paulheim, Jan Portisch, Artem Revenko, Annette ten Teije等. 结合机器学习和语义网:系统映射研究。《ACM计算调查》,55(14s):1-41, 2023.
[11] Domenico Cantone, Carmelo Fabio Longo, Marianna Nicolosi Asmundo, Daniele Francesco Santamaria, 和Corrado Santoro. OASIS中的本体智能合约:代理、系统和服务集成的本体。《分布式智能计算十四》,Studies in Computational Intelligence,第237-247页,Cham, 2022. Springer International Publishing.
[12] Alessio Carenini, Andrea Fiano, Mario Scrocca, Marco Comerio, 和Irene Celino. 通过国家访问点联合会实现跨境旅行优惠:通过元数据协调。在David Chaves-Fraga, Pieter Colpaert, Mersedeh Sadeghi, Mario Scrocca, 和Marco Comerio编辑的《第三届国际研讨会:运输的语义与网络》,CEUR Workshop Proceedings第2939卷,在线,2021年9月。CEUR。ISSN: 1613-0073.
[13] Valentina Anita Carriero, Antonia Azzini, Ilaria Baroni, Mario Scrocca, 和Irene Celino. 使用大型语言模型从文本中提取程序知识图谱的人类评估。在Mehwish Alam, Marco Rospocher, Marieke van Erp, Laura Hollink, 和Genet Asefa Gesese编辑的《第24届国际知识工程与知识管理会议论文集》(EKAW 2024),第434-452页,Cham, 2024. Springer Nature Switzerland.
[14] Irene Celino 和Gloria Re Calegari. 通过对话界面提交调查:用户接受度和方法有效性的评估。《国际人机交互研究杂志》,139:102410, 2020.
[15] Irene Celino, Gloria Re Calegari, 和Andrea Fiano. 使用目的游戏细化链接数据。《数据情报》,2(3):417-442, 2020.
[16] Irene Celino, Gloria Re Calegari, Mario Scrocca, Jaime Zamorano, 和Esteban Gonzalez Guardia. 参与公民科学活动的动力:TESS网络案例。《科学传播杂志》,20(6):A03, 2021.
[17] David Chaves-Fraga, Oscar Corcho, Anastasia Dimou, Maria-Esther Vidal, Ana Iglesias-Molina, 和Dylan Van Assche. 知识图谱是否准备好应对现实世界?挑战与视角(Dagstuhl Seminar 24061)。Dagstuhl Reports, 14(2):1-70, 2024.
[18] Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, 和Fei Xia. SpatialVLM:赋予视觉语言模型空间推理能力。《IEEE/CVF计算机视觉与模式识别会议论文集》,第14455-14465页,2024.
[19] Agnese Chiatti, Gianluca Bardaro, Matteo Matteucci, 和Enrico Motta. 机器人感知的视觉模型构建:视角、挑战与机遇。《第三十七届AAAI人工智能会议桥接会议论文集》(AAAI-23),美国华盛顿州西雅图,第7-14页,2023年。
[20] Agnese Chiatti, Gianluca Bardaro, Enrico Motta, 和Enrico Daga. 面向常识推理的视觉智能代理空间推理框架。《第八届人工智能与认知国际研讨会论文集》(AIC 2022)。CEUR, 2022.
[21] Agnese Chiatti, Enrico Motta, 和Enrico Daga. 服务机器人视觉智能框架:认识论要求与差距分析。《国际原则知识表示与推理会议论文集》(KR)-特别会议KR & Robotics,第905-916页。IJCAI, 2020.
[22] Agnese Chiatti, Enrico Motta, 和Enrico Daga. 具备常识的机器人:通过大小和空间意识改进物体识别。《AAAI关于混合智能机器学习与知识工程研讨会论文集》(AAAI-MAKE)。CEUR, 2022.
[23] Marco Comerio, Andrea Fiano, Marco Grassi, 和Mario Scrocca. 移动数据协调:TANGENT解决方案。《运输转型:推进可持续和包容性移动 - 第十届TRA会议论文集》,Lecture Notes in Mobility。Springer, 2024.
[24] Silvia Coradeschi 和Alessandro Saffiotti. 锚定问题简介。《机器人学与自主系统》,43(2-3):85-96, 2003.
[25] Mary Cummings. 重新思考人工智能在安全关键环境中的成熟度。《AI杂志》,42(1):6-15, 2021.
[26] Ernest Davis 和Gary Marcus. 人工智能中的常识推理与常识知识。《ACM通讯》,58(9):92-103, 2015.
[27] Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Hai-Tao Zheng, 和Zhiyuan Liu. Few-NERD:少样本命名实体识别数据集。arXiv预印本 arXiv:2105.07464, 2021.
[28] 欧洲议会和欧洲联盟理事会. 欧洲议会和欧洲联盟理事会条例(EU)2024/1689,关于建立人工智能的协调规则,2024年6月13日发布,2024年。
[29] Marco Grassi, Mario Scrocca, Alessio Carenini, Marco Comerio, 和Irene Celino. 使用Chimera构建可组合的语义数据转换流水线。《第4届与第20届扩展语义网会议共同举办的第4届知识图谱构建国际研讨会论文集》,CEUR Workshop Proceedings第3471卷,希腊赫尔松尼索斯,2023年5月。CEUR。ISSN: 1613-0073.
[30] Patricia Guinan 和Robert P Bostrom. 计算机基础信息系统开发:通信框架。《ACM SIGMIS Database:信息系统进步数据库》,17(3):3-16, 1986.
[31] Marvin Hofer, Johannes Frey, 和Erhard Rahm. 使用LLM实现自配置知识图谱构建流水线——RML案例研究。在David Chaves-Fraga, Anastasia Dimou, Ana Iglesias-Molina, Umutcan Serles, 和Dylan Van Assche编辑的《第五届知识图谱构建国际研讨会论文集》,CEUR Workshop Proceedings第3718卷,希腊赫尔松尼索斯,2024年5月。CEUR。ISSN: 1613-0073.
[32] Marjan Hosseini, Safia Kalwar, Matteo Rossi, 和Mersedeh Sadeghi. 自动映射用于交通运输数据格式的语义转换。在Lucie-Aimee Kaffee, Kemele M. Endris, Maria-Esther Vidal, Marco Comerio, Mersedeh Sadeghi, David Chaves-Fraga, 和Pieter Colpaert编辑的《第一届交通运输语义国际研讨会与第一届数据互操作方法国际研讨会联合论文集》,CEUR Workshop Proceedings第2447卷,德国卡尔斯鲁厄,2019年9月。CEUR。ISSN: 1613-0073.
[33] Jie Hu, Liujuan Cao, Tong Tong, Qixiang Ye, Shengchuan Zhang, Ke Li, Feiyue Huang, Ling Shao, 和Rongrong Ji. 深度神经网络架构解耦。《IEEE/CVF国际计算机视觉会议论文集》,第672-681页,2021.
[34] Félix Ingrand 和Malik Ghallab. 自主机器人决策:综述。《人工智能》,247:10-44, 2017.
[35] Daniel Kahneman. 思考,快与慢。Farrar, Straus and Giroux, 2011.
[36] Subbarao Kambhampati. 大型语言模型能否推理和计划?《纽约科学院院刊年报》,1534(1):15-18, 2024.
[37] Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt, 和Anil B Murthy. 观点:LLM不能计划,但可以在LLM-modulo框架中帮助计划。《第四十一届国际机器学习会议》,2024.
[38] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, 等. Visual Genome:通过众包密集图像注释连接语言和视觉。《国际计算机视觉杂志》,123(1):32-73, 2017.
[39] Abhijeet Kumar, Abhishek Pandey, Rohit Gadia, 和Mridul Mishra. 使用预训练语言模型构建知识图谱以学习实体感知关系。《2020年IEEE计算、电力与通信技术国际会议论文集》(GUCON),第310-315页,2020.
Ullman, Joshua B. Tenenbaum, 和Samuel J. Gershman. 构建像人类一样学习和思考的机器。《行为与脑科学》,40, 2017.
[41] Edith Law和Luis Von Ahn. 人类计算。Morgan & Claypool Publishers, 2011.
[42] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel等. 面向知识密集型NLP任务的检索增强生成。《神经信息处理系统进展》,33:9459-9474, 2020.
[43] Baosheng Li, Jishui Han, Yuan Cheng, Chong Tan, Peng Qi, Jianping Zhang, 和Xiaolei Li. 身体AI中的目标导航:综述。《2022年第四届视频、信号与图像处理国际会议论文集》,第87-92页,2022.
[44] Marcos Maroto-Gómez, María Malfaz, José Carlos Castillo, Álvaro Castro-González, 和Miguel Ángel Salichs. 从显式和隐式用户反馈中个性化辅助社交机器人的活动选择。《国际社交机器人杂志》,第1-19页,2024.
[45] Chancharik Mitra, Brandon Huang, Trevor Darrell, 和Roei Herzig. 大型多模态模型的组合推理提示。《IEEE/CVF计算机视觉与模式识别会议论文集》,第14420-14431页,2024.
[46] Barbara M Montgomery. 婚姻中的高质量沟通形式与功能。《家庭关系》,第21-30页,1981.
[47] Andreas Nüchter 和Joachim Hertzberg. 面向移动机器人的语义地图。《机器人学与自主系统》,56(11):915-926, 2008.
[48] Alex Randles 和Declan O’Sullivan. R2[RML]-ChatGPT框架。在David Chaves-Fraga, Anastasia Dimou, Ana Iglesias-Molina, Umutcan Serles, 和Dylan Van Assche编辑的《第五届知识图谱构建国际研讨会论文集》,CEUR Workshop Proceedings第3718卷,希腊赫尔松尼索斯,2024年5月。CEUR。ISSN: 1613-0073.
[49] Nikitha Rao, Jason Tsay, Kiran Kate, Vincent Hellendoorn, 和Martin Hirzel. AI用于低代码开发AI。《第29届智能用户界面国际会议论文集》,IUI '24,第837-852页,纽约,NY,美国,2024. 计算机协会。
[50] Gloria Re Calegari 和Irene Celino. 目的游戏中游戏激励、玩家画像和任务难度的相互作用。《知识工程与知识管理:第21届国际会议论文集》,EKAW 2018,法国南锡,2018年11月12-16日,第306-321页。Springer, 2018.
[51] Gloria Re Calegari, Andrea Fiano, 和Irene Celino. 构建用于链接数据细化的目的游戏框架。《语义网-ISWC 2018:第17届国际语义网会议论文集》,美国蒙特雷,CA,2018年10月8-12日,第154-169页。Springer, 2018.
[52] Gloria Re Calegari, Gioele Nasi, 和Irene Celino. 人类计算与机器学习:图像分类实验比较。《人类计算》,5:13-30, 2018.
[53] Julien Romero 和Simon Razniewski. 探索Quasimodo常识知识的构建与使用。《第29届ACM国际信息与知识管理会议论文集》,第3445-3448页,2020.
[54] Anisa Rula 和Jennifer D’Souza. 使用大型语言模型进行程序文本挖掘。《第12届知识捕获会议论文集》2023,第9-16页,2023.
[55] Anisa Rula, Gloria Re Calegari, Antonia Azzini, Ilaria Baroni, 和Irene Celino. 从文本文档中注释和提取工业程序知识。《第12届知识捕获会议论文集》2023,第1-8页,2023.
[56] Anisa Rula, Gloria Re Calegari, Antonia Azzini, Davide Bucci, Ilaria Baroni, 和Irene Celino. 激发和整理行业中的程序知识:挑战与机遇。Qurator, 2022.
[57] Anisa Rula, Gloria Re Calegari, Antonia Azzini, Davide Bucci, Alessio Carenini, Ilaria Baroni, 和Irene Celino. K-hub:支持工业5.0中文档检索和知识提取的模块化本体。《欧洲语义网会议论文集》,第454-470页。Springer, 2023.
[58] Mersedeh Sadeghi, Alessio Carenini, Oscar Corcho, Matteo Rossi, Riccardo Santoro, 和Andreas Vogelsang. 异构系统互操作性:从需求到参考架构。《超级计算期刊》,80(7):8954-8987, 2024年5月.
[59] Md Kamruzzaman Sarker, Lu Zhou, Aaron Eberhart, 和Pascal Hitzler. 神经符号人工智能。《AI通讯》,34(3):197-209, 2021.
[60] Manolis Savva, Angel X Chang, 和Pat Hanrahan. 共同感知知识的语义丰富3D模型。《IEEE计算机视觉与模式识别研讨会论文集》(CVPRW),第24-31页。IEEE, 62015.
[61] Mario Scrocca, Ilaria Baroni, Alessio Carenini, Marco Comerio, 和Irene Celino. 支持智能资产管理系统的数据共享和过程跟踪的集成框架。《第十届运输研究论坛论文集》,Lecture Notes in Mobility。Springer, 2024.
[62] Mario Scrocca, Alessio Carenini, Marco Grassi, Marco Comerio, 和Irene Celino. 并非人人都懂RDF:不同数据表示之间的知识转换。《第五届知识图谱构建@ESWC2024国际研讨会论文集》,2024.
[63] Mario Scrocca, Marco Comerio, Alessio Carenini, 和Irene Celino. 转换交通数据以符合欧盟标准,同时启用多模式运输知识图谱。《第19届国际语义网会议论文集》,第12507卷,第411-429页。Springer, 2020.
[64] Mario Scrocca, Marco Comerio, Alessio Carenini, 和Irene Celino. 通过本体智能合约建模多模式运输领域的业务协议。《迈向知识感知AI》,第137-151页。IOS Press, 2022.
[65] Mario Scrocca, Marco Grassi, Marco Comerio, Valentina Anita Carriero, Tiago Delgado Dias, Ana Vieira Da Silva, 和Irene Celino. 通过语义互操作性实现智能城市交通管理。在Gianluca Demartini, Katja Hose, Maribel Acosta, Matteo Palmonari, Gong Cheng, Hala Skaf-Molli, Nicolas Ferranti, Daniel Hernández,
以及Aidan Hogan编辑,《第23届国际语义网会议论文集》(ISWC2024),第218-235页,瑞士Cham,2024年。Springer Nature Switzerland.
[66] Mario Scrocca, Damiano Scandolari, Gloria Re Calegari, Ilaria Baroni, 和Irene Celino. 调查本体:将调查研究打包为研究对象。《第二届链接开放科学数据与研究对象管理研讨会论文集》(DaMaLOS),与ISWC 2021共同举办,2021.
[67] Senbao Shi, Zhenran Xu, Baotian Hu, 和Min Zhang. 生成多模态实体链接。《2024年联合国际计算语言学会议、语言资源与评估会议论文集》(LREC-COLING 2024),第7654-7665页,2024.
[68] Robert Snowden, Robert J Snowden, Peter Thompson, 和Tom Troscianko. 基础视觉:视觉感知导论。牛津大学出版社,2012.
[69] Stian Soiland-Reyes等. 使用RO-Crate打包研究工件。《数据科学》,5(2):97-138,2022年1月。出版商:IOS Press.
[70] Arjen Stolk, Lennart Verhagen, 和Ivan Toni. 概念对齐:大脑如何实现相互理解。《认知科学趋势》,20(3):180-191, 2016.
[71] Margaret Tan. 系统设计中建立相互理解:实证研究。《管理信息系统期刊》,10(4):159-182, 1994.
[72] Margaret JY Tan. 系统分析师沟通行为的研究。昆士兰大学商学院,1989.
[73] Ilaria Tiddi, Victor De Boer, Stefan Schlobach, 和André Meyer-Vitali. 混合智能的知识工程。《第12届知识捕获会议论文集》2023,第75-82页,2023.
[74] Stefani Tsaneva 和Marta Sabou. 通过任务设计增强人在回路中的本体维护结果。《ACM数据与信息质量期刊》,16(1):1-25, 2024.
[75] Michael van Bekkum, Maaike de Boer, Frank van Harmelen, André Meyer-Vitali, 和Annette ten Teije. 混合学习和推理系统的设计模式分类、模式和用例。《应用智能》,51(9):6528-6546, 2021.
[76] Frank Van Harmelen 和Annette Ten Teije. 混合学习和推理系统的设计模式盒学。《Web工程杂志》,18(1-3):97-123, 2019.
[77] Bert Van Nuffelen. 欧洲数据门户的DCAT应用配置文件(DCAT-AP)。[在线;访问日期2024-0716].
[78] G. Vetere 和M. Lenzerini. 面向服务架构中的语义互操作性模型。《IBM系统期刊》,44(4):887-903, 2005.
[79] Luis Von Ahn. 目的驱动的游戏。《计算机》,39(6):92-94, 2006.
[80] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song等. CogVLM:预训练语言模型的视觉专家。arXiv预印本 arXiv:2311.03079, 2023.
[81] John M Wiemann. 沟通能力模型的阐述与测试。《人类传播研究》,3(3):195-213, 1977.
[82] Ludwig Wittgenstein. 哲学研究。John Wiley & Sons, 2009.
[83] 工作流运行RO-Crate工作组. 工作流运行RO-Crate配置文件 - 过程运行箱.
[84] Ziang Xiao, Michelle X Zhou, Q Vera Liao, Gloria Mark, Changyan Chi, Wenxi Chen, 和Huahai Yang. 告诉我关于你自己:使用AI驱动的聊天机器人进行对话调查。arXiv预印本 arXiv:1905.10700, 2019.
[85] Michelle X Zhou, Gloria Mark, Jingyi Li, 和Huahai Yang. 信任虚拟代理:性格的影响。《ACM交互式智能系统交易》,9(2-3):10, 2019.
参考论文:https://arxiv.org/pdf/2504.11200


















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











