






Raghav Thind
计算机科学系
马里兰大学帕克分校
rthind@terpmail.umd.edu
Ling Liang
数学系
马里兰大学帕克分校
liang.ling@u.nus.edu
Youran Sun
数学系
马里兰大学帕克分校
syouran0508@gmail.com
Haizhao Yang*
数学系
计算机科学系
马里兰大学帕克分校
hzyang@umd.edu
摘要
优化在科学研究和实际应用中起着至关重要的作用,但将用自然语言描述的具体优化问题转化为数学形式,并选择合适的求解器来解决问题,需要大量的领域专业知识。我们引入了OptimAI,这是一种通过利用LLM驱动的AI代理解决用自然语言描述的优化问题的框架,在性能上优于当前最先进的方法。我们的框架基于四个关键角色:(1) 一个公式化者,将自然语言问题描述转化为精确的数学公式;(2) 一个规划者,在执行前构建高层解决方案策略;以及 (3) 一个编码者和代码评论者,能够与环境交互并反思结果以改进未来的行动。消融研究确认所有角色都是必不可少的;移除规划者或代码评论者分别会导致生产力下降5.8倍和3.1倍。此外,我们引入了基于UCB的调试调度,动态切换备选计划,从而带来了额外3.3倍的生产力提升。我们的设计强调多代理协作,使我们能够方便地探索在统一系统内结合不同模型的协同效应。我们的方法在NLP4LP数据集上达到了88.1%的准确率,在Optibench(无表非线性子集)上达到了71.2%的准确率,相比之前的最佳结果分别减少了58%和50%的错误率。
1 引言
优化在整个科学和工程学科的广泛范围内起着基础性作用,作为决策、资源分配、系统设计等的核心框架[1]。近年来,随着数据驱动方法的兴起,其重要性更加突出。特别是现代机器学习从根本上建立在解决大规模优化问题的基础上。训练模型通常涉及最小化损失函数,往往是在高维、非凸景观上进行,而诸如超参数调整、模型选择以及强化学习中的策略学习等任务同样被形式化为优化问题
[
2
,
3
]
[2,3]
[2,3]。
尽管优化处于核心地位,但一个持续存在的挑战是:现实世界的问题并非以数学术语呈现。将一个实际目标(例如,最小化交付时间、平衡风险与回报或安排有限资源)转化为一个明确提出的数学公式并求解,需要大量的领域专业知识以及对优化建模及相关求解器的熟悉程度。此外,一个优化问题往往可以以多种方式表述并由不同的求解器解决。然而,公式的选择和求解器会显著影响解决方案过程的效率和可行性。这对非专家构成了重大障碍,限制了许多应用场景中优化技术的可访问性。努力自动化从自然语言或结构化数据中建模并寻找优化问题的最优解,有可能极大地拓宽优化的影响。通过允许用户以直观的方式描述问题,同时利用能够推断和构造相应数学公式的算法,这种自动化系统可以降低进入门槛并普及强大的优化工具。鉴于最近自然语言处理和符号推理方面的进展,这一方向尤为及时,这些进展提供了弥合非正式问题描述与正式优化模型之间差距的有希望的工具。
大型语言模型(LLMs)作为一种通过自然语言与复杂任务互动的强大工具,提供了一个用户友好的界面和显著的计算能力。它们的可访问性和生成结构化解决方案的能力使其成为协助优化问题公式化和求解的有希望的代理。本工作旨在减少将现实世界问题转化为正式数学模型的障碍,支持用户解决这些问题,并调查LLMs在优化方面的推理能力。最近的研究表明,LLMs表现出一定程度的数学[4, 5]、编码[6]和逻辑[7]推理能力。我们的研究通过评估LLMs在优化任务中的推理能力,为这一不断增长的研究主体做出了贡献。表1总结了现有工作,包括它们提出的数据集、每个数据集的大小以及它们支持的优化问题类型。关于相关工作的详细讨论,请参见第2节。
表1:使用LLMs进行优化的先前工作。
| 工作 | 提出的数据集 | 大小 | 问题类型(s) |
|---|---|---|---|
| NL4Opt竞赛 [8] | NL4Opt | 289 | LP |
| Chain-of-Experts (CoE) [9] | ComplexOR | 37 | LP, MILP |
| OptiMUS [ 10 , 11 , 12 ] [10,11,12] [10,11,12] | NLP4LP | 67 | LP, MILP |
| OptiBench [13] | OptiBench | 605 | LP, NLP, MILP, MINLP |
| OR-LLM-Agent[14] | OR-LLM-Agent | 83 | LP, MILP |
在某些情况下,所提出的数据集被赋予特定名称,因此在单独一列中列出数据集名称。问题类型(s)列中的缩写:LP - 线性规划,NLP 非线性规划,MI - 混合整数。
我们介绍了OptimAI,这是一个通过利用LLM驱动的AI代理解决用自然语言描述的优化问题的框架。OptimAI包含四个阶段(见图1),每个阶段由专门的代理处理:公式化者将自然语言问题转化为数学公式;规划者提出解决方案策略;编码者生成可执行求解器代码;代码评论者进行反思性调试。OptimAI提供了几个关键优势。首先,它采用先规划后编码的策略,在启动实际代码生成之前生成多个解决方案计划。其次,我们引入了基于UCB的调试调度,在调试期间动态切换备选计划,根据观察到的反馈自适应选择计划。第三,它自然支持多代理协作,允许不同的角色由最适合每项任务的不同LLM处理。与精心设计的提示一起,这些设计选择有助于OptimAI在先前方法上的优越表现。表2比较了OptimAI和先前方法的功能能力。
表2:OptimAI和先前方法的功能能力对比。
| 功能能力 | OptiMUS | OptiBench | OptimAI |
|---|---|---|---|
| 自然语言输入 | X X X | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 编码前规划 | X X X | X X X | ✓ \checkmark ✓ |
| 切换计划 | X X X | X X X | ✓ \checkmark ✓ |
| 代码生成 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 不同LLM协作 | X X X | X X X | ✓ \checkmark ✓ |
全面实验表明,我们的方法在标准基准数据集上始终优于最先进的方法。具体来说,与之前的最佳方法相比,我们在NLP4LP上减少了58%的错误率,在四个Optibench子集(无表线性、带表线性、无表非线性和带表非线性)上分别减少了17%、20%、50%和24%的错误率。消融研究表明所有角色都是必不可少的;移除规划者或代码评论者分别会导致生产力下降5.8倍和3.1倍。此外,基于UCB的调试调度带来了额外3.3倍的生产力提升。此外,OptimAI具有广泛的适用性。除了标准的数学规划外,它还处理NP难组合优化问题,展示了强大的通用性。
2 相关工作
近年来,将LLM应用于复杂计算任务已受到越来越多的关注。我们的工作位于三个新兴研究方向的交汇处:利用LLM解决优化问题、增强其推理能力以及实现多代理协作以协调解决问题。在本节中,我们将回顾这些领域的最新进展,这些进展共同推动了我们将这些组件整合到一个统一框架中,用于解决用自然语言表达的优化任务。
2.1 LLM用于优化
近期的工作探索了使用LLM直接从自然语言描述中建模、解释和解决优化问题,从而实现了人类意图与数学问题解决之间的新接口。方法范围从用结构化问题模板提示LLM到将其与外部求解器集成以完成(混合整数)线性和非线性规划问题的任务。
NL4Opt [8] 引入了自然语言优化竞赛,其中包括两个子任务:(1) 识别优化问题实体和 (2) 生成数学公式。值得注意的是,GPT-3.5在这两项任务中都超过了竞赛获胜者的表现。然而,ChatGPT 展示了一些常见错误,如不正确的约束系数、冗余约束和遗漏变量。这些发现突显了LLM在优化中的潜力和局限性,指出了未来在将LLM应用于运筹学和数学规划研究中的有前途的方向。
OptiMUS
[
10
,
11
,
12
]
[10,11,12]
[10,11,12] 是一系列研究,探讨如何直接从自然语言描述中使用LLM解决线性规划(LP)和混合整数线性规划(MILP)问题。作为这项工作的一部分,作者引入了NLP4LP数据集,其中包含从学术教科书和讲义材料中精选的多样化的LP和MILP问题集合。该数据集作为评估LLM解释和公式化优化问题为正式数学术语的能力的基准。
OptiBench [13] 是一个全面的基准测试,旨在评估LLM在应对优化建模问题方面的熟练程度,重点在于线性和混合整数规划任务。该基准涵盖了来自物流、调度和资源分配等领域的真实场景启发的多样化问题实例,以及相应的数学公式和解决方案。在[13]中,作者介绍了ReSocratic,一种创新的数据合成方法,用于生成高质量的合成优化问题以增强训练数据集。通过利用ReSocratic,
作者证明,使用合成数据训练LLM可以显著提高其解释自然语言描述、制定准确的数学模型和产生最优解决方案的能力,从而改善复杂的优化任务的性能。因此,OptiBench成为了研究人员推进NLP与优化整合的前沿工具之一。
除了上述工作外,[15] 探讨了应用LLM解决鲁棒优化(RO)和自适应鲁棒优化(ARO)问题的应用。Chain-of-Experts框架 [9] 研究了使用LLM解决各种运筹学(OR)问题的应用。该论文还介绍了ComplexOR数据集,并提出了一个名为Chain-of-Experts的多代理协作系统,其中不同的LLM上下文作为协作框架中的专家。然而,需要注意的是,他们的“专家”是同一LLM模型在不同上下文中的变体,而不是真正的多代理系统。相比之下,OR-LLM-Agent [14] 是一个旨在为运筹学优化问题提供端到端解决方案的人工智能代理。这项工作还介绍了一个包含83个现实世界运筹学问题自然语言描述的数据集,促进了基于LLM解决方案的开发和评估,以解决实际优化任务。
2.2 LLM中的推理
最近人工智能推理的进步正从系统1(快速、直觉思考)转向系统2(缓慢、深思熟虑的思考),正如[16]所全面回顾的那样。在这种背景下,一种普遍的方法是利用奖励模型和蒙特卡罗树搜索(MCTS)来回溯解决方案过程,使用问题及其答案指导探索,然后将其整合到强化学习(RL)中。与本文最相关的文献是那些应用LLM解决数学问题 [ 17 , 4 , 5 ] [17,4,5] [17,4,5] 和编程问题 [ 6 , 18 ] [6,18] [6,18] 的文献。
2.3 多代理协作
大量研究聚焦于使用LLM进行多代理协作。关于这一领域的综合评论可以在[19, 20]中找到。在这些研究中,通常将多个LLM集成起来以处理各种各样的任务,包括推理 [21]、规划 [22]、编程 [23]、金融营销 [24, 25]、教育 [26, 27] 和科学研究 [28, 29]。在许多这些工作中,LLM被分配不同的角色以处理问题的不同方面。然而,一些方法采用了一种框架,其中代理执行几乎相同的任务,最终结果在最后汇总 [30]。这种方法虽然有效,但应被视为一种集成方法而非真正的多代理协作。
除了静态角色分配外,几项研究旨在发展更动态的角色和代理之间的互动,强调代理随着时间的推移适应和专业化的潜力 [31, 32, 33]。值得注意的是,[33] 提出了一个针对LLM为基础的多代理系统的扩展定律,表明随着规模和复杂性的增加,此类系统可能表现出可预测的行为。此外,更先进的研究探讨了使用多代理系统生成的数据进行强化学习,这有望增强LLM在合作任务中的能力 [34, 35, 36]。这一方向代表了未来LLM为基础的多代理系统研究和发展的一个令人兴奋的途径。
3 方法论
在本节中,我们将详细介绍我们提出的方法。首先概述整体管道,然后重点介绍两个关键组成部分:一个多代理协作框架和一个专为调试阶段定制的多臂老虎机策略
3.1 管道
我们的代理将优化问题的自然语言描述转化为可执行求解器及其对应的解决方案。端到端管道(如图1所示)包含四个连续阶段(S1-S4):
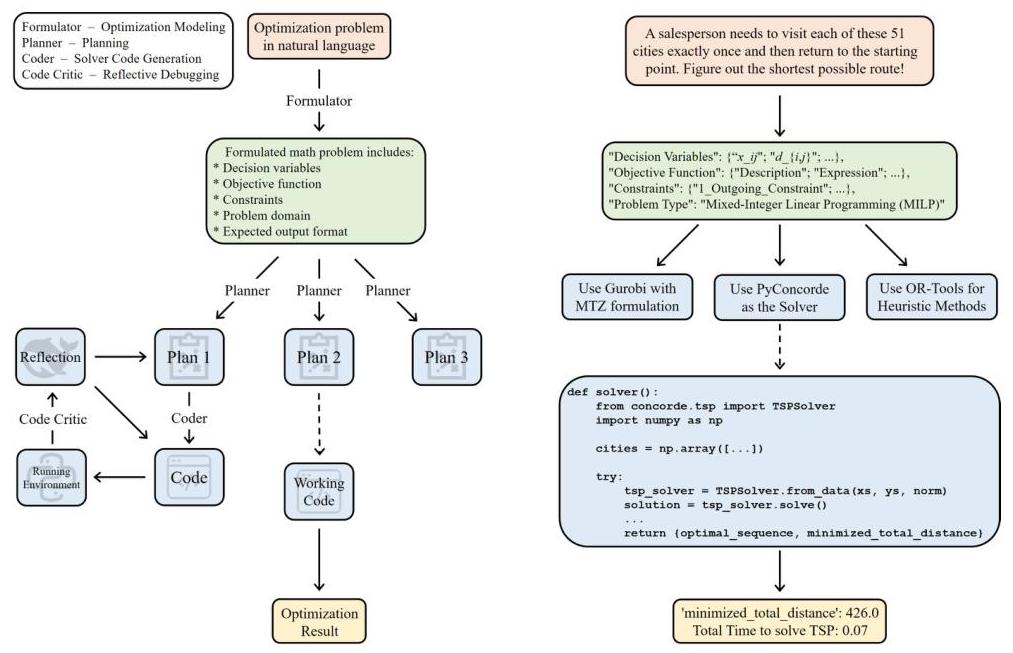
图1:管道概览。
S1 优化建模。此阶段将自然语言问题陈述转化为定义明确的数学优化问题。公式包括识别决策变量、指定要最小化或最大化的目标函数、定义必须满足的任何约束条件、表征问题域(例如,连续、离散或混合)以及确定预期的输出解决方案格式。
S2 规划。在此阶段,代理分析数学公式并提出多个候选解决方案策略。每个策略指定一个合适的优化求解器,概述要实施的算法方法(例如,(MI)LP和(MI)NLP),并提供与求解器选择和代码实现相关的其他上下文信息(如求解器功能、变量和约束类型)。在本研究中,支持的求解器包括PuLP、Pyomo、Gekko、OR-Tools、SCIP、MOSEK、IPOPT和Gurobi,涵盖广泛的线性、非线性和混合整数优化技术。
S3 求解器代码生成。给定优化问题、其数学公式和选定的解决方案策略,此阶段生成相应的Python求解器代码。生成的代码必须包括数据验证和错误处理以确保稳健性,解决方案验证以验证正确性,并提供注释以增强可读性和可维护性。
S4 反思性调试。生成的代码在运行时环境中执行,初始执行由于错误或意外行为经常失败。在此阶段,LLM分析代码和产生的错误消息,参与自我反思过程以诊断潜在问题,并制定反馈以改进当前策略。受此反思引导,LLM随后迭代调试并修改代码以解决已识别的问题并提高整体可靠性。
我们在管道中使用的完整提示集见附录A。
3.2 多代理扩展
最近的研究表明,在LLM框架中纳入多代理设置可以显著增强整体性能 [31, 32, 33]。基于这一系列
研究,我们建议将多代理架构整合到我们的系统设计中,以实现更有效的协调、专业化和问题解决能力。
有两种主要方法为LLM分配不同角色:(1) 提示工程和上下文控制:在这种方法中,每个模型都被明确告知其角色和任务。每个模型的上下文仅包含相关信息,确保粒度和范围适合特定角色。(2) 模型分配:这种方法涉及将不同模型分配给不同任务。例如,这些“不同模型”可以是使用不同数据微调的同一基础模型的版本。通常分配给LLM的角色常常反映在协作人类环境中发现的角色,如项目经理、程序员、测试工程师以及类似于导师(评论者)和学生(演员)的角色。这些角色对应于人类社会中已经确立的社会关系。这种对齐特别有趣,因为它反映了康威定律,该定律断言:“任何设计系统(广义定义)的组织都会产生一个其结构是该组织沟通结构副本的设计。”
为了充分利用多代理系统的优点,我们的管道允许将不同阶段分配给不同的LLM。对应于我们管道中的四个阶段,我们实例化了四个角色:公式化者、规划者、编码者和代码评论者。特别是,由规划者处理的规划阶段需要强大的长期推理能力,可能受益于更强大的模型。相比之下,编码者专注于细粒度调整,可能对LLM的需求较低。我们的框架提供了灵活的配置选项,允许整个管道使用单个LLM或多个LLM分配给不同角色。这种设计不仅有助于评估单个模型的性能,还使我们能够探索结合不同模型以增强成果的潜在协同效应。
备注1 显然,利用多代理架构的强化学习(RL)框架往往表现出更大的鲁棒性和适应性,特别是在复杂或不确定的环境中 [34]。将此类多代理RL技术纳入我们的框架可以增强其整体有效性,尤其是在策略选择和代码调试等动态或易错阶段。探索这种整合仍然是未来研究的一个有希望的方向。
3.3 将调试调度视为多臂老虎机
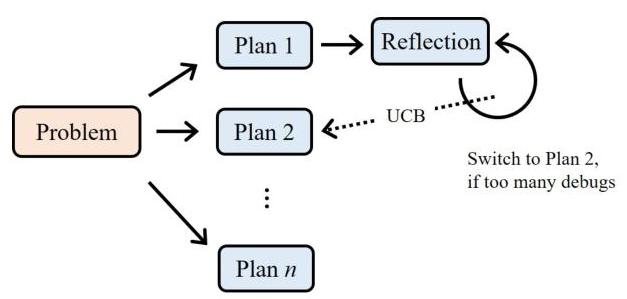
图2:基于UCB的调试调度演示。
在规划阶段,系统生成多个候选计划以解决问题。OptimAI根据来自独立语言模型的评估选择最有前途的计划开始实施。然而,随着编码的进展,最初选择的计划在经过几轮调试后可能会被证明无效。当这种情况发生时,OptimAI通过切换到另一个计划来适应,这类似于人类在解决问题时修订策略的方式。
我们将选择下一个要调试的计划的问题公式化为一个多臂老虎机问题 [37]。在这个抽象中,每个计划被视为一个臂。对于每个计划及其对应的代码,一个决定LLM提供一个分数
r
^
i
\hat{r}_{i}
r^i,反映其看起来有多有前途以及成功调试的可能性。然后使用
Upper Confidence Bound (UCB) 算法选择下一个臂(计划)
r ~ i + c ln ( ∑ j n j ) n i \tilde{r}_{i}+c \sqrt{\frac{\ln \left(\sum_{j} n_{j}\right)}{n_{i}}} r~i+cniln(∑jnj)
其中 c c c是探索系数 [38, 39], n i n_{i} ni是计划 i i i被调试的次数。在最坏的情况下,如果评论LLM给每个计划分配相同的分数(即缺乏辨别力),UCB算法自然退化为均匀采样,从而平等调试所有计划。完整的程序详见算法1,图2说明了上述操作。
算法1 基于UCB的调试调度
要求:问题描述
确保:一个可工作的代码解决方案
生成计划
(
{
Plan
1
,
…
,
Plan
n
}
)
(\left\{\operatorname{Plan}_{1}, \ldots, \operatorname{Plan}_{n}\right\})
({Plan1,…,Plann}) 使用规划者
使用编码器为每个计划生成代码 Code
(
i
)
(_{i})
(i)
初始化
(
n
i
←
1
)
(n_{i} \leftarrow 1)
(ni←1) 对于所有
(
i
)
(i)
(i)
while 无代码成功 do
获取每个
(
(
Plan
i
,
Code
i
)
)
(\left(\operatorname{Plan}_{i}, \operatorname{Code}_{i}\right))
((Plani,Codei)) 的得分
(
r
~
i
)
(\tilde{r}_{i})
(r~i) 从决定者
(
U
C
B
i
←
r
~
i
+
c
ln
(
∑
j
n
j
)
/
n
i
)
(\mathrm{UCB}_{i} \leftarrow \tilde{r}_{i}+c \sqrt{\ln \left(\sum_{j} n_{j}\right) / n_{i}})
(UCBi←r~i+cln(∑jnj)/ni)
选择
(
i
∗
←
arg
max
i
(
U
C
B
i
)
)
(i^{*} \leftarrow \arg \max _{i}\left(\mathrm{UCB}_{i}\right))
(i∗←argmaxi(UCBi))
调试代码 Code
(
i
∗
)
(_{i^{*}})
(i∗)
更新
(
n
i
∗
←
n
i
∗
+
1
)
(n_{i^{*}} \leftarrow n_{i^{*}}+1)
(ni∗←ni∗+1)
end while
返回可工作的代码
4 实验
4.1 实验设置
数据集 我们旨在通过在多个异构且具有挑战性的数据集上进行评估,展示我们方法的有效性和多功能性,如下所述。
- NLP4LP。NLP4LP数据集 [11] 是一个精心策划的包含65个LP的集合,旨在弥合自然语言处理和优化之间的差距。它包括问题描述、参数数据文件和最优解,涵盖设施选址、网络流、调度和投资组合管理等不同领域。
-
- OptiBench。OptiBench [13] 包含605个多样化的优化问题,包括有或没有表格数据的线性和非线性规划。这是第一个大规模基准,包括非线性和表格优化问题,超越了以前基准对线性规划的专注。
-
- TSPLIB。TSPLIB [40] 是一个公开可用的旅行商问题(TSP)基准实例库,作为评估TSP算法性能的标准数据集而闻名。该库包含超过100个TSP实例,从小规模到大规模问题不等,研究人员通常使用它来测试和比较他们优化算法的效率和准确性。该标准化数据集的可用性对TSP算法的发展和进步起到了重要作用,因为它允许公平和一致地比较不同方法。
-
- SelfJSP。SelfJSP数据集 [41] 是一个大规模基准,旨在通过监督学习研究神经方法解决作业车间调度问题(JSP)。它通过模拟生成了超过30,000个JSP实例,覆盖了广泛的配置,包括作业和机器数量、加工时间和操作序列。每个实例包括问题规范(例如,作业-操作-机器分配和持续时间)和高质量标签,如最优或接近最优的调度序列,使神经调度策略能够进行监督训练。
-
- 我们还考虑了一些IBM ILOG CPLEX Optimization Studio文档中的集合覆盖问题 [42]。
基线 为了评估我们方法的有效性,我们将我们的方法与两个代表性的最先进的基线进行比较:OptiMUS [11] 和 OptiBench [13]。为了确保公平比较,我们刻意避免使用明显更强大的模型。尽管OptiMUS和OptiBench使用GPT-4作为其最强模型,我们使用GPT-4o、QwQ和DeepSeek-R1进行实验,这些模型通常被认为具有与GPT-4相当的能力。我们用GPT-4o代替GPT-4,因为使用GPT-4的成本随时间显著增加(例如,大约增加了6倍到12倍),这使得它不再具有成本效益:
- 我们还考虑了一些IBM ILOG CPLEX Optimization Studio文档中的集合覆盖问题 [42]。
评估指标 我们在零样本提示设置下通过测量单次调用正确解决的问题比例(Pass@1)来评估OptimAI在多个数据集上的表现。此外,我们使用五个指标评估生成解决方案的质量:可执行性、运行时间、令牌使用、生产力和修订次数。
- 可执行性基于人类评价,如[23]中定义的那样,其中评分为4表示完全正确的解决方案;3表示轻微问题;2表示勉强可运行但存在显著问题的代码;1表示完全无法运行的输出。
-
- 运行时间测量在配备M3芯片的MacBook Air上生成的优化代码的执行时间;越低越好。
-
- 令牌使用是指解决给定问题时管道消耗的平均令牌数;越低越好。
-
- 生产力衡量每1,000个令牌生成多少行代码。更高的值表示更好的效率。
-
- 修订次数记录生成可执行代码所需的调试尝试次数。
4.2 主要结果
表3:OptimAI与最先进方法的准确率比较。
| 数据集 | NLP4LP | Optibench Linear | Optibench Nonlinear | ||
|---|---|---|---|---|---|
| Agent | w/o Table | w/ Table | w/o Table | w/ Table | |
| OptiMUS [11] | 71.6 % 71.6 \% 71.6% | - | - | - | - |
| OptiBench [13] | - | 75.4 % 75.4 \% 75.4% | 62.5 % 62.5 \% 62.5% | 42.1 % 42.1 \% 42.1% | 32.0 % 32.0 \% 32.0% |
| 我们的 w/ GPT-4o | 79.1 % 79.1 \% 79.1% | 77.7 % 77.7 \% 77.7% | 66.25 % 66.25 \% 66.25% | 64.4 % 64.4 \% 64.4% | 38.0 % 38.0 \% 38.0% |
| 我们的 w/ GPT-4o+o1-mini | 88.1 % \mathbf{8 8 . 1 \%} 88.1% | 79.2 % 79.2 \% 79.2% | 70.0 % \mathbf{7 0 . 0 \%} 70.0% | 68.2 % 68.2 \% 68.2% | 44.0 % 44.0 \% 44.0% |
| 我们的 w/ QwQ (由通义千问提供) | 79.1 % 79.1 \% 79.1% | 79.2 % 79.2 \% 79.2% | 68.8 % 68.8 \% 68.8% | 71.2 % \mathbf{7 1 . 2 \%} 71.2% | 42.0 % 42.0 \% 42.0% |
| 我们的 w/ DeepSeek-R1 | 82.1 % 82.1 \% 82.1% | 79.7 % \mathbf{7 9 . 7 \%} 79.7% | 70.0 % \mathbf{7 0 . 0 \%} 70.0% | 65.9 % 65.9 \% 65.9% | 48.0 % \mathbf{4 8 . 0 \%} 48.0% |
所有评估均在零样本提示设置下进行。GPT-4o+o1-mini指的是使用o1-mini作为规划者,同时使用GPT-4o担任所有其他角色。
表3展示了我们在NLP4LP和OptiBench数据集上的方法准确性,并与先前的最先进方法进行了比较。无论底层LLM如何,OptimAI始终优于以往的工作。
除了数学规划问题外,我们进一步在几个代表性的NP难组合优化问题上评估OptimAI,包括旅行商问题(TSP)、作业车间调度问题(JSP)和集合覆盖问题(SCP)。如表4所示,跨多样化任务的一致表现突显了我们方法的鲁棒性和通用性。值得注意的是,它无需依赖任何特定问题的定制即可有效地解决各种具有挑战性的组合问题。详细的示例说明如何解决这些问题可以在附录B中找到。
表4:OptimAI在NP难组合优化问题上的通用性。
| 数学规划 | TSP | JSP | 集合覆盖 | |
|---|---|---|---|---|
| OptimAI | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
缩写:TSP - 旅行推销员问题,JSP - 作业车间调度问题,QAP - 二次分配问题
4.3 消融研究
基于UCB的调试调度的有效性 为了评估基于UCB的调试调度的效果,我们使用GPT-4o在Optibench数据集的困难子集上进行了消融研究 2 { }^{2} 2。如表5所示,禁用基于UCB的调试调度会导致令牌使用显著增加和生产力降低。具体而言,启用基于UCB的调试调度可将令牌使用减少 3.6 × 3.6 \times 3.6×,并将生产力提高 3.3 × 3.3 \times 3.3×,同时保持相似的准确率并略微提高可执行性。这些结果表明,基于UCB的策略在优化调试效率方面非常有效,同时不会影响结果质量。
表5:基于UCB的调试调度在OptimAI中的影响的消融研究。
| 评估指标 | OptimAI w/o UCB | OptimAI w/ UCB |
|---|---|---|
| 可执行性 | 3.4 | 3.5 \mathbf{3 . 5} 3.5 |
| Pass@1 准确率 | 69 % 69 \% 69% | 69 % 69 \% 69% |
| 令牌使用 | 839,185 | 234 , 939 \mathbf{2 3 4 , 9 3 9} 234,939 |
| 生产力 | 0.70 | 2.32 \mathbf{2 . 3 2} 2.32 |
角色的有效性 为了理解不同角色的影响并确保我们管道中的每个组件都是必要的,我们逐个消除了各个阶段(角色)并观察了系统的性能。如表6所示,移除任何单一阶段都会导致性能下降,证实了每个角色对整体效果的关键贡献。特别是,移除规划者会显著削弱框架生成功能性代码的能力:它需要 4.6 × 4.6 \times 4.6×更多的修订才能达到可运行状态,导致生产力下降 5.8 × 5.8 \times 5.8×。类似地,省略代码批评者会使修订次数增加 3.6 × 3.6 \times 3.6×,并使生产力下降 3.1 × 3.1 \times 3.1×。这些结果强调了高水平规划和后生成批评在优化性能中的必要性。
表6:角色的消融研究。
| 公式化者 | 规划者 | 代码批评者 | 修订次数 | 可执行性 | 生产力 |
|---|---|---|---|---|---|
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 1.7 \mathbf{1 . 7} 1.7 | 3.6 \mathbf{3 . 6} 3.6 | 6.8 \mathbf{6 . 8} 6.8 |
| × \times × | ✓ \checkmark ✓ | ✓ \checkmark ✓ | 2.0 | 3.2 | 6.3 |
| ✓ \checkmark ✓ | × \times × | ✓ \checkmark ✓ | 7.8 | 3.1 | 1.2 |
| ✓ \checkmark ✓ | ✓ \checkmark ✓ | × \times × | 6.2 | 3.3 | 2.2 |
5 结论
我们介绍了OptimAI,这是一个利用LLM驱动的AI代理解决用自然语言指定的优化问题的框架,与当前最先进的方法相比表现出色。涉及四种LLM和五个具有挑战性的数据集的广泛实验展示了我们方法的有效性和鲁棒性。展望未来,我们确定了几个有前景的研究方向:(1) 通过RL加强框架,特别是微调决策组件,这
2
{ }^{2}
2 困难问题定义为需要超过三次调试迭代才能达到可运行状态的问题。
具有在适度计算成本下获得实质性收益的潜力;(2) 扩展OptimAI以解决通常需要一组人类专家和工程师处理的大规模问题,超越目前的范围,其性能可与单一熟练程序员相媲美。因此,OptimAI提供了一个灵活且可扩展的基础,以便进一步探索多代理LLM系统在真实世界优化场景中的应用。
致谢
作者部分得到了美国国家科学基金会DMS-2244988、DMS2206333奖项,海军研究办公室奖项N00014-23-1-2007,以及DARPA D24AP00325-00的支持。
参考文献
[1] Philip E Gill, Walter Murray, and Margaret H Wright. Practical optimization. SIAM, 2019.
[2] Stephen Boyd. Convex optimization. Cambridge UP, 2004.
[3] Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning. SIAM review, 60(2):223-311, 2018.
[4] Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rStar-Math: Small LLMs can master math reasoning with self-evolved deep thinking, 2025. URL https://arxiv.org/abs/2501.04519.
[5] Xuefeng Li, Haoyang Zou, and Pengfei Liu. LIMR: Less is more for rl scaling, 2025. URL https://arxiv.org/abs/2502.11886.
[6] Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, and Jitao Sang. o1-Coder: an o1 replication for coding, 2024. URL https://arxiv.org/
a
b
s
/
2412.00154
\mathrm{abs} / 2412.00154
abs/2412.00154.
[7] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[8] Rindranirina Ramamonjison, Timothy T. Yu, Raymond Li, Haley Li, Giuseppe Carenini, Bissan Ghaddar, Shiqi He, Mahdi Mostajabdaveh, Amin Banitalebi-Dehkordi, Zirui Zhou, and Yong Zhang. NL4Opt competition: Formulating optimization problems based on their natural language descriptions, 2023. URL https://arxiv.org/abs/2303. 08233 .
[9] Ziyang Xiao, Dongxiang Zhang, Yangjun Wu, Lilin Xu, Yuan Jessica Wang, Xiongwei Han, Xiaojin Fu, Tao Zhong, Jia Zeng, Mingli Song, and Gang Chen. Chain-of-Experts: When LLMs meet complex operations research problems. In International Conference on Learning Representations (ICLR), 2023.
[10] Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. OptiMUS: Optimization modeling using MIP solvers and large language models, 2023. URL https://arxiv. org/abs/2310.06116.
[11] Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. OptiMUS: Scalable optimization modeling with (MI)LP solvers and large language models, 2024. URL https://arxiv. org/abs/2402.10172.
[12] Ali AhmadiTeshnizi, Wenzhi Gao, Herman Brunborg, Shayan Talaei, Connor Lawless, and Madeleine Udell. OptiMUS-0.3: Using large language models to model and solve optimization problems at scale, 2025. URL https://arxiv.org/abs/2407.19633.
[13] Zhicheng Yang, Yiwei Wang, Yinya Huang, Zhijiang Guo, Wei Shi, Xiongwei Han, Liang Feng, Linqi Song, Xiaodan Liang, and Jing Tang. OptiBench meets ReSocratic: Measure and improve LLMs for optimization modeling, 2024. URL https://arxiv. org/abs/2407.09887.
[14] Bowen Zhang and Pengcheng Luo. OR-LLM-Agent: Automating modeling and solving of operations research optimization problem with reasoning large language model, 2025. URL https://arxiv.org/abs/2503.10009.
[15] Dimitris Bertsimas and Georgios Margaritis. Robust and adaptive optimization under a large language model lens. arXiv preprint arXiv:2501.00568, 2024.
[16] Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, and Cheng-Lin Liu. From system 1 to system 2: A survey of reasoning large language models, 2025. URL https://arxiv.org/abs/ 2502.17419.
[17] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https: //arxiv.org/abs/2402.03300.
[18] Zhuohao Yu, Weizheng Gu, Yidong Wang, Zhengran Zeng, Jindong Wang, Wei Ye, and Shikun Zhang. Outcome-refining process supervision for code generation, 2024. URL https://arxiv.org/abs/2412.15118.
[19] Chuanneng Sun, Songjun Huang, and Dario Pompili. Llm-based multi-agent reinforcement learning: Current and future directions, 2024. URL https://arxiv.org/abs/2405.11106 .
[20] Shuaihang Chen, Yuanxing Liu, Wei Han, Weinan Zhang, and Ting Liu. A survey on llm-based multi-agent system: Recent advances and new frontiers in application, 2025. URL https://arxiv.org/abs/2412.17481.
[21] Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic llm-powered agent network for task-oriented agent collaboration, 2024. URL https://arxiv. org/abs/2310.02170.
[22] Shyam Sundar Kannan, Vishnunandan L. N. Venkatesh, and Byung-Cheol Min. Smartllm: Smart multi-agent robot task planning using large language models, 2024. URL https://arxiv.org/abs/2309.10062.
[23] Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework, 2024. URL https://arxiv.org/abs/ 2308.00352 .
[24] Shen Gao, Yuntao Wen, Minghang Zhu, Jianing Wei, Yuhan Cheng, Qunzi Zhang, and Shuo Shang. Simulating financial market via large language model based agents, 2024. URL https://arxiv.org/abs/2406.19966.
[25] Nian Li, Chen Gao, Mingyu Li, Yong Li, and Qingmin Liao. EconAgent: Large language model-empowered agents for simulating macroeconomic activities. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15523-15536, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653 / v 1 / 2024 10.18653 / \mathrm{v} 1 / 2024 10.18653/v1/2024.acl-long.829. URL https://aclanthology. org/2024.acl-long.829/.
[26] Jifan Yu, Zheyuan Zhang, Daniel Zhang-li, Shangqing Tu, Zhanxin Hao, Rui Miao Li, Haoxuan Li, Yuanchun Wang, Hanming Li, Linlu Gong, Jie Cao, Jiayin Lin, Jinchang Zhou, Fei Qin, Haohua Wang, Jianxiao Jiang, Lijun Deng, Yisi Zhan, Chaojun Xiao, Xusheng Dai, Xuan Yan, Nianyi Lin, Nan Zhang, Ruixin Ni, Yang Dang, Lei Hou, Yu Zhang, Xu Han, Manli Li, Juanzi Li, Zhiyuan Liu, Huiqin Liu, and Maosong Sun. From mooc to maic: Reshaping online teaching and learning through llm-driven agents, 2024. URL https://arxiv.org/abs/2409.03512.
[27] Zheyuan Zhang, Daniel Zhang-Li, Jifan Yu, Linlu Gong, Jinchang Zhou, Zhanxin Hao, Jianxiao Jiang, Jie Cao, Huiqin Liu, Zhiyuan Liu, Lei Hou, and Juanzi Li. Simulating classroom education with llm-empowered agents, 2024. URL https://arxiv.org/ abs/2406.19226.
[28] Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. Researchagent: Iterative research idea generation over scientific literature with large language models, 2025. URL https://arxiv.org/abs/2404.07738.
[29] Alireza Ghafarollahi and Markus J. Buehler. Sciagents: Automating scientific discovery through multi-agent intelligent graph reasoning, 2024. URL https://arxiv.org/ abs/2409.05556.
[30] Yi Cheng, Wenge Liu, Jian Wang, Chak Tou Leong, Yi Ouyang, Wenjie Li, Xian Wu, and Yefeng Zheng. Cooper: Coordinating specialized agents towards a complex dialogue goal, 2023. URL https://arxiv.org/abs/2312.11792.
[31] Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development, 2024. URL https://arxiv.org/abs/2410.16946.
[32] Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Language agents as optimizable graphs, 2024. URL https: //arxiv.org/abs/2402.16823.
[33] Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model-based multi-agent collaboration, 2025. URL https://arxiv.org/ abs/2406.07155.
[34] Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman Ozdaglar, Kaiqing Zhang, and Joo-Kyung Kim. Maporl: Multi-agent post-co-training for collaborative large language models with reinforcement learning, 2025. URL https://arxiv.org/abs/2502. 18439.
[35] Kartik Nagpal, Dayi Dong, Jean-Baptiste Bouvier, and Negar Mehr. Leveraging large language models for effective and explainable multi-agent credit assignment, 2025. URL https://arxiv.org/abs/2502.16863.
[36] Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B. Tenenbaum, Tianmin Shu, and Chuang Gan. Building cooperative embodied agents modularly with large language models, 2024. URL https://arxiv.org/abs/2307. 02485 .
[37] Aleksandrs Slivkins et al. Introduction to multi-armed bandits. Foundations and Trends® in Machine Learning, 12(1-2):1-286, 2019.
[38] Levente Kocsis and Csaba Szepesvári. Bandit based Monte-Carlo planning. In European conference on machine learning, pages 282-293. Springer, 2006.
[39] Peter Auer and Ronald Ortner. UCB revisited: Improved regret bounds for the stochastic multi-armed bandit problem. Periodica Mathematica Hungarica, 61(1-2):55-65, 2010.
[40] G Reinhelt. {TSPLIB}: a library of sample instances for the tsp (and related problems) from various sources and of various types. URL: http://comopt. ifi. uniheidelberg. de/software/TSPLIB95, 2014.
[41] Andrea Corsini, Angelo Porrello, Simone Calderara, and Mauro Dell’Amico. Self-labeling the job shop scheduling problem. Arxiv, 2024.
[42] IBM Corporation. Ibm ilog cplex optimization studio documentation, 2025. URL https://www.ibm.com/docs/en/icos. Accessed: 2025-04-14.
A 提示示例
公式化提示
你是一位优化建模专家。
分析以下优化问题并提取其关键组成部分:
优化问题:
{state[“messages”]{0}.content}
任务:
首先分析优化问题,然后提供以下组成部分:
- 决策变量:包括它们的类型和域。使它们的名字具有描述性
-
- 目标函数:指定目标表达式。
-
- 约束条件:列出所有约束条件。
-
- 问题类型:指定优化问题的类型(例如,线性规划,混合整数线性规划,非线性规划,混合整数非线性规划,二次规划等)。此信息需要非常精确和准确。
-
响应格式:
- 以包含以下键的JSON对象形式返回你的响应:
- “决策变量”, “目标函数”, “约束条件”, 和 “问题类型”。
-
-
else: -
# 如果有人类反馈可用,则使用反馈提示 -
prompt = f"""你是一位优化建模专家。 - 根据人类反馈修订以下优化问题的提取组件。
-
优化问题:
- {state[“messages”]{0}.content}
-
当前组件:
-
- 决策变量:{state[“components”][“decision_variables”]}
-
- 目标函数:{state[“components”][“objective_function”]}
-
- 约束条件:{state[“components”][“constraints”]}
-
- 问题类型:{state[“components”][“problem_type”]}
-
人类反馈:
- {state[“components”][“user_feedback”]}
-
任务:
- 根据反馈修订组件,同时确保准确性。
-
响应格式:
- 以包含"“!you”"标签的JSON对象形式返回你的响应,其中包含以下键:
- “决策变量”, “目标函数”, “约束条件”, 和 “问题类型”。
规划提示
你是一个优化求解器代码规划专家。
你的责任是提供三种最佳策略来实现解决优化问题的源代码。
首先,仔细分析优化问题,尝试理解问题的类型,并且如果给出的话,检查用户对特定要求、偏好或领域知识的建议,这些应该影响你的解决方案方法。
接下来,彻底分析优化模型组件、约束条件、变量和目标函数。
然后,理解我们拥有的求解器和建模工具(Available_Tools)。
分析每个求解器的优缺点,并决定哪些最适合给定的问题及其类型。
然后思考可以用来生成该问题求解器代码的三种最有效的策略。
每个策略必须包括以下内容:
1)适用于该任务的优化求解器(只能使用我们提供给你的求解器和建模工具列表中的选项)
2)关于要实现的算法的详细信息
3)在实现求解器代码时需要注意的任何其他信息。(不要包括求解器安装信息)
确保你的策略详尽深入,这将有助于更好地生成代码。
只使用可靠的来源,如学术论文和官方文档,在你的工具调用中到达结论。
然而,不要在最终策略中包含这些来源。
只有在完成这个详尽的分析之后,再提供你的回应。
优化问题:
{state[“messages”]{0}.content}
### 用户建议(如果有)
(UserFeedbackRecord.user_recommendations)
### 优化模型
(state[“components”])
### 响应格式:
你的响应应该仅包含三个策略的列表,没有任何额外的格式。
决策提示
你是一位优化求解器代码实现专家。
分析以下优化问题、其组件以及解决它的策略,并按从最佳到最差的顺序排列这些策略:
### 优化问题:
(state[“messages”][0].content)
### 实现求解器代码的策略
(state[“messages”][-1].content)
### 任务:
根据最佳到最差的顺序排列实现代码以解决给定优化问题的策略:
- 考虑哪个策略会带来最高效的代码,从而给我们最准确的结果。
- 不要修改给你的任何策略。
- ### 响应格式:
- 以包含以下键的JSON对象形式返回你的响应:
- “Strategy1”, “Strategy2”, 和 “Strategy3”
- “Strategy1” 应对应最佳策略,“Strategy2” 对应次佳策略,“Strategy3” 对应最差策略。
- 确保在输出中包含完整的策略。
编码提示
你是一个解决优化问题的Python编码专家。
你的责任是提供一个解决给定优化问题的Python代码。
首先,仔细分析优化问题和优化模型组件、约束条件、变量和目标函数。
然后,理解和分析给定的策略以生成解决该问题的代码以及为所需代码指定的要求。
然后考虑使用提供的策略生成求解器代码的最有效方式。
只有在完成这个详尽的分析之后,再提供所需的Python代码。
### 优化问题:
(state[“messages”][0].content)
### 优化模型
(state[“components”])
### 实现求解器代码的策略
(state[“plans”][strategy])
### Python代码的要求
代码必须仅包含一个名为’solver’的单个函数。
生成的代码必须:
- 遵循给定的策略。
- - 包含所有必要的导入
- - 实施适当的数据验证和错误处理
- - 创建所有具有正确类型和界限的变量
- - 按照所示定义目标函数
- - 实施模型中的所有约束条件
- - 解决模型并检查解决方案状态
- - 将输出格式化为包含变量值的字典
- - 清晰报告错误,通过在字典中返回"error"来实现
- - 返回并打印最优解和目标值
- - 在函数定义中包含参数,如果有
- - 适当地处理单位转换
- - 验证输出
- - 包含注释
确保你返回的是问题中请求的值。
专注于最终解决方案的准确性,并确保它满足优化问题中给出的所有要求。
确保最终答案在逻辑上讲得通,即,当解决方案中的变量在逻辑上不可能时,不应有小数点后的值。
你返回的代码,当单独使用Python的exec()函数运行时,应给出优化问题的最终解决方案。
基本上,你的代码应该能够独立运行并给出给定优化问题的最终解决方案。
不应该需要对你的代码进行任何调整,例如调用函数、放置参数值等,以获得优化问题的期望解决方案。
### 响应格式:
你的响应应仅包含一个名为 ‘solver’ 的单一函数的Python代码,不包含任何额外的格式。
代码评论提示
你是一位分析Python优化求解器代码的专家。
你的任务是提供反馈以调试给定的代码以解决优化问题。
你会得到优化问题、优化模型、实现求解器代码的策略、解决问题的代码以及代码返回的错误,以理解问题。
### 优化问题:
(state[“messages”][0].content)
### 优化模型
(state[“components”])
### 实现求解器代码的策略
(state[“code_branches”][len(state[“code_branches”]) - 1][“strategy”])
### 解决问题的代码
(solver_code)
### 代码返回的错误
(error_mag)
### 任务
你需要提供反馈以帮助调试代码以生成给定优化问题的请求解决方案。
请记住,你提供的反馈应该是这样的,即调试后的代码能够使用Python的exec()函数独立执行,而无需任何额外步骤。
只提供简单的英语反馈以帮助调试代码;不要在你的反馈中提供任何已调试的代码。
### 响应格式
你的响应应仅包含帮助调试代码的反馈,不包含任何格式。因此,不要在你的响应中包含任何已调试的代码本身。
你的响应不应包含除此反馈以外的任何内容。
代码调试提示
你是一个解决优化问题的Python调试专家。
你的责任是调试提供的Python代码以解决给定的优化问题。
首先,仔细分析优化问题和优化模型组件、约束条件、变量和目标函数。
然后,理解和分析给定的代码、生成代码以解决该问题的策略以及为所需代码指定的要求。
然后分析错误和反馈以调试代码。
然后,考虑在保持所采用策略和代码要求的同时调试给定代码。
只有在完成这个详尽的分析之后,再提供所需的已调试Python代码。
代码必须仅包含一个名为 ‘solver’ 的单个函数。
### 优化问题:
(state[“messages”][0].content)
### 优化模型
(state[“components”])
### 实现求解器代码的策略
[(state[“code_branches”]]current_length - 1][“strategy”])
求解器代码
(state[“code_branches”])current_length - 1][“code”])
错误
(state[“code_branches”])current_length - 1][“error”])
反馈以调试代码
(state[“code_branches”])current_length - 1][“critique”])
已调试Python代码的要求
生成已调试代码而不改变所提供代码的特性。
代码必须仅包含一个名为 ‘solver’ 的单个函数。
本质上,已调试代码应:
- 遵循给定策略。
- - 包含所有必要的导入
- - 实施适当的数据验证和错误处理
- - 创建所有具有正确类型和界限的变量
- - 按照所示定义目标函数
- - 实施模型中的所有约束条件
- - 解决模型并检查解决方案状态
- - 将输出格式化为包含变量值的字典
- - 清晰报告错误,通过在字典中返回"error"来实现
- - 返回并打印最优解和目标值
- - 如果有任何参数,在函数定义中包含这些参数
- - 适当地处理单位转换
- - 验证输出
- - 包含注释
- 专注于提供的反馈以帮助调试代码。
- 确保你返回的是问题中请求的值。
- 专注于最终解决方案的准确性,并确保它满足优化问题中给出的所有要求。
- 确保最终答案在逻辑上讲得通,即,当解决方案中的变量在逻辑上不可能时,不应有小数点后的值。
- 你返回的代码,当单独使用Python的exec()函数运行时,应给出优化问题的最终解决方案。
- 基本上,你的代码应该能够独立运行并给出给定优化问题的最终解决方案。
- 不应该需要对你的代码进行任何调整,例如调用函数、放置参数值等,以获得优化问题的期望解决方案。
- ### 响应格式:
- 你的响应应仅包含一个名为 ‘solver’ 的单个函数的Python代码,不包含任何额外的格式。
B 案例研究
B. 1 包含280个城市的旅行商问题
这是来自流行的TSPLIB数据集 [40] 中的a280问题。解决TSP的总时间为0.82秒。
优化建模
"决策变量": {
"a_i1"; {
"描述": "指示从节点i到节点j的边是否包含在巡游中的二进制变量。",
"类型": "二进制",
"域": "a_ij \\in \$(0, 1\})$ 对于所有 i, j \\in \$(1, 2, \ldots, 280\}\"
},
"u_i": {
"描述": "用于消除子巡游的连续变量(Miller-Tucker-Zemlin公式),表示节点i在巡游中的位置。",
"类型": "连续",
"域": "2 \\leq u_i \\leq 280 对于所有 i \\in \$(2, 3, \ldots, 280\}\"
}
},
"目标函数": {
"描述": "最小化巡游的总欧几里得距离。",
"表达式": "最小化 \\sum_i1 \\leq i \\seq j \\leq 280) (d_ij > a_ij)",
"其中": "d_ij 是节点i和节点j之间的欧几里得距离。"
},
"约束条件": {
"i_流守恒": {
"描述": "确保从每个节点恰好有一条出边离开。",
"表达式": "\sum_(1 \\leq } \\leq 280, } \\neq i\} x_ij = 1 对于所有 i \\in \$(1, 2, ..., \
280\\!"
i,
"2_流守恒": {
"描述": "确保从每个节点恰好有一条入边进入。",
"表达式": "\sum_(1 \\leq i \\leq 280, i \\neq j} x_ij = 1 对于所有 j \\in \$(1, 2, ..., \
280\)$"
i,
"3_子巡游消除": {
"描述": "使用Miller-Tucker-Zemlin (MIZ) 约束消除子巡游。",
"表达式": "u_1 - u_j + 280 + x_ij \\leq 279 对于所有 i, j \\in \$(2, 3, ..., 280\)$, i \
\\neq j"
i,
"4_起始节点": {
"描述": "定义巡游的起始节点。",
"表达式": "u_start = 1",
"注释": "假设选择了一个特定的起始节点,否则可以省略或调整此约束。"
}
i,
"问题类型": "混合整数线性规划 (MILP)"
}
计划
-
询问用户是否想输入实现求解器代码的策略建议。人类输入 “我想要给出的TSP的最佳解决方案,并且我也希望代码能够在我的Macbook Air笔记本电脑上可行”。
-
规划代理进行以下工具调用以搜索网络:
查询:对称TSP问题的最佳代码
查询:pyconcorde解决TSP Concorde文档
查询:使用OR-Tools解决TSP
3) 最后,规划代理提供了以下策略: -
使用Pyconcorde求解器:
- 合适的求解器:Pyconcorde
-
- 算法详情:Pyconcorde是Concorde TSP求解器的Python包装器。Concorde是一种基于分支切割算法的高度优化和专业化的TSP求解器。} 它特别适合这个问题,因为它在处理大规模TSP实例时效率高,通过动态添加约束切割来消除分数解} 和分支定界树内的子路径。
-
- 其他信息:确保输入数据正确格式化为Pyconcorde。它需要邻接矩阵或城市坐标列表。考虑预处理距离使用欧几里得计算以加快数据提供。Pyconcorde将以最少的设置复杂度处理求解,适合280节点的问题。
- 使用OR-Tools和SCIP实现:
- 合适的求解器:使用SCIP后端的OR-Tools
-
- 算法详情:OR-Tools通过利用约束编程和MILP方法支持TSP路由求解器。通过OR-Tools访问的SCIP采用有效的数值计算和启发式算法,结合分支定界策略。通过OR-Tools中的约束传播和可选的LNS求解器,此策略快速收敛至最优解。
-
- 其他信息:利用OR-Tools在路由问题上下文中设置TSP。使用距离回调集成欧几里得距离矩阵。通过OR-Tools内SCIP的并行处理和启发式指导增强性能,可能通过元数据改进节点排序和路径搜索。
- 使用Gurobi进行MILP建模:
- 合适的求解器:Gurobi
-
- 算法详情:Gurobi是一个强大的MILP求解器,具有解决大规模MIP的强大算法。使用Miller-Tucker-Zemlin (MIZ) 子巡游消除约束。} Gurobi的高级预处理技术、割平面和节点级并行执行使其适合按照MILP公式精确建模TSP。
-
- 其他信息:根据MIZ模型设置问题,使用城市间路由的二进制决策变量和基于MIZ模型的子巡游消除连续变量。确保Gurobi中的模型环境设置充分利用多核处理和内存。预处理步骤应包括构建准确的距离矩阵并调整求解器参数如MIPGap、NodeLimit和启发式以平衡速度和解的精度。
决策者
决策代理:
决策代理按以下顺序对策略进行排名:
i) 使用Pyconcorde求解器
最终结果
(‘optimal_route’: 11, 2, 242, 243, 244, 241, 240, 239, 238, 237, 236, 235, 234, 233, 232, 231, 246,
245, 247, 250, 251, 230, 229, 228, 227, 226, 225, 224, 223, 222, 221, 220, 219, 218, 217,
216, 215, 214, 213, 212, 211, 210, 209, 208, 207, 206, 205, 204, 203, 202, 201, 200, 144,
145, 199, 198, 197, 196, 195, 194, 193, 192, 191, 190, 189, 188, 187, 186, 185, 184, 183,
182, 181, 176, 180, 179, 150, 178, 177, 151, 152, 156, 153, 155, 154, 129, 128, 127, 126,
125, 124, 123, 122, 121, 120, 119, 157, 156, 159, 160, 175, 161, 162, 163, 164, 165, 166,
167, 168, 169, 170, 171, 172, 173, 174, 187, 106, 105, 104, 103, 102, 101, 100, 99, 98, 97,
96, 95, 94, 93, 92, 91, 90, 89, 109, 108, 110, 111, 114, 113, 112, 88, 87, 84, 83, 82, 81,
80, 79, 78, 77, 75, 76, 74, 73, 72, 71, 70, 67, 69, 68, 58, 57, 56, 55, 54, 53, 52, 51, 50,
49, 48, 47, 46, 45, 44, 59, 63, 64, 66, 65, 85, 86, 116, 115, 117, 118, 62, 61, 60, 43, 42,
41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 22, 25, 23, 24, 14, 15, 13,
12, 11, 10, 8, 9, 7, 6, 5, 4, 277, 276, 275, 274, 273, 272, 271, 16, 17, 18, 19, 20, 21, 130,
131, 132, 133, 134, 270, 269, 135, 136, 268, 267, 137, 138, 139, 149, 149, 147, 146, 143,
142, 141, 140, 266, 265, 264, 263, 262, 261, 260, 259, 258, 257, 254, 253, 252, 255, 256,
249, 248, 278, 279, 3, 280), ‘total_distance’: 2579.0)
B. 2 包含20个作业和5台机器的作业调度问题
这是SelfJSP [41] 中的la11.jsp问题。
优化建模
"决策变量": {
"Start_Time_jk": {
"描述": "作业 } 的第 k 次操作的开始时间",
"类型": "连续",
"域": "非负实数"
},
"Makespan": {
"描述": "所有作业的整体完成时间",
"类型": "连续",
"域": "非负实数"
}
},
"目标函数": {
"表达式": "最小化 Makespan"
},
"约束条件": {
{
"描述": "每个作业内的优先级约束",
"数学形式": "对于每个作业 } 和每个操作 k > 1, Start_Time_jk \\geq \
Start_Time_j(k-1) + Processing_Time_j(k-1)"
},
{
"描述": "每台机器上无重叠",
"数学形式": "对于分配给同一台机器 m 的任意两个操作 (j1, k1) 和 (j2, k2),要么 Start_Time_j1k1 + Processing_Time_j1k1 \\geq Start_Time_j2k2 或者 \
Start_Time_j2k2 + Processing_Time_j2k2 \\leq Start_Time_jlk1"
},
{
"描述": "每个作业的完成时间不超过 Makespan",
"数学形式": "对于每个作业 }, Start_Time_jK + Processing_Time_jK \\leq Makespan"
},
{
"描述": "开始时间是非负的",
"数学形式": "对于所有作业 } 和操作 k, Start_Time_jk \\geq 0"
}
},
"问题类型": "混合整数线性规划 (MILP)"
}
计划
- 策略1:
- 合适的优化求解器:OR-Tools的CP-SAT求解器
-
- 算法:CP-SAT求解器利用SAT(可满足性测试)和常量规划方法的组合高效解决调度问题。使用间隔变量为每个操作建模,表示其开始时间和处理持续时间。利用求解器内的无重叠约束处理机器分配以避免冲突,并强制执行作业优先级约束以维持作业内的操作顺序。
- 其他注意事项:牢记求解器处理大型搜索空间的能力,使用高级搜索启发式方法,并利用求解器的目标函数功能有效地最小化makespan,同时在适当的情况下使用warstart或hinting等决策变量策略以加速求解过程。
- 策略2:
- 合适的优化求解器:OR-Tools(使用其作业车间调度和整数线性规划功能)
-
- 算法:将操作和作业嵌入到作业车间调度框架中,该框架专门设计用于处理带有约束的机器调度问题。使用整数规划将决策变量建模为整数值,从而高效计算开始时间和优先级。探索OR-Tools的对称打破约束和专用切割平面以优化调度。
-
- 其他注意事项:充分利用OR-Tools在大型调度问题实例上的可扩展性能。考虑在可能的情况下将问题分解为较小的子问题,并应用迭代求解技术如拉格朗日松弛,以确保更一致地收敛到最优解。
- 策略3:
- 合适的优化求解器:与Gurobi结合使用的Pyomo
-
- 算法:利用Pyomo灵活的建模环境表达调度问题的MILP模型,包括变量、目标和约束,如所定义的。整合Gurobi求解器的功能,其中包括强大的分支切割算法来优化makespan。这种组合允许微调变量边界和求解器参数,以高效探索解空间。
-
- 其他注意事项:Gurobi优化套件具有广泛的参数调整可能性,如调整MLP间隙容限、设置相对和绝对终止标准,并使用Gurobi的启发式方法以实现更快的解。虽然Pyomo允许简单表达复杂关系,但在处理CPU密集和耗时部分的求解过程中,确保考虑计算资源约束,特别是在评估大规模问题中的固有延迟时。
决策者
决策代理按以下顺序对策略进行排名:
- OR-Tools的CP-SAT求解器
- OR-Tools(使用其作业车间调度和整数线性规划功能)
- 合适的优化求解器:与Gurobi结合使用的Pyomo
代码代码
确保正确导入’cp_model’,验证行’from ortosis.sat.python import cp_model’存在并正确定位在任何使用’cp_model’之前。确保导入语句没有拼写错误,并且它在使用’cp_model’的范围内可访问。
最终结果
| ‘Makespan’: 1222.0, ‘Start_0_0’: 66, ‘Start_0_1’: 298, ‘Start_0_2’: 627, ‘Start_0_3’: 689, } ‘Start_0_4’: 917, ‘Start_1_0’: 680, ‘Start_1_1’: 744, ‘Start_1_2’: 842, ‘Start_1_3’: 1040, } ‘Start_1_4’: 1136, ‘Start_2_0’: 436, ‘Start_2_1’: 458, ‘Start_2_2’: 509, ‘Start_2_3’: 674, ‘Start_2_4’: 1015, ‘Start_3_0’: 0, ‘开始时间_3_1’: 66, ‘开始时间_3_2’: 438, ‘开始时间_3_3’: 798, ‘开始时间_3_4’: 932, ‘开始时间_4_0’: 353, ‘开始时间_4_1’: 637, ‘开始时间_4_2’: 822, ‘开始时间_4_3’: 913, } ‘开始时间_4_4’: 1039, ‘开始时间_5_0’: 325, ‘开始时间_5_1’: 466, ‘开始时间_5_2’: 535, ‘开始时间_5_3’: 627, } ‘开始时间_5_4’: 788, ‘开始时间_6_0’: 0, ‘开始时间_6_1’: 165, ‘开始时间_6_2’: 242, ‘开始时间_6_3’: 371, } ‘开始时间_6_4’: 458, ‘开始时间_7_0’: 242, ‘开始时间_7_1’: 325, ‘开始时间_7_2’: 666, ‘开始时间_7_3’: 707, } ‘开始时间_7_4’: 1162, ‘开始时间_8_0’: 404, ‘开始时间_8_1’: 500, ‘开始时间_8_2’: 701, ‘开始时间_8_3’: 745, } ‘开始时间_8_4’: 1166, ‘开始时间_9_0’: 93, ‘开始时间_9_1’: 223, ‘开始时间_9_2’: 423, ‘开始时间_9_3’: 560, } ‘开始时间_9_4’: 936, ‘开始时间_10_0’: 258, ‘开始时间_10_1’: 353, ‘开始时间_10_2’: 781, ‘开始时间_10_3’: } 1012, ‘开始时间_10_4’: 1103, ‘开始时间_11_0’: 517, ‘开始时间_11_1’: 540, ‘开始时间_11_2’: 931, } ‘开始时间_11_3’: 1054, ‘开始时间_11_4’: 1091, ‘开始时间_12_0’: 0, ‘开始时间_12_1’: 172, ‘开始时间_12_2’: } 658, ‘开始时间_12_3’: 1116, ‘开始时间_12_4’: 1185, ‘开始时间_13_0’: 145, ‘开始时间_13_1’: 319, } ‘开始时间_13_2’: 772, ‘开始时间_13_3’: 1098, ‘开始时间_13_4’: 1116, ‘开始时间_14_0’: 429, ‘开始时间_14_1’: } 448, ‘开始时间_14_2’: 535, ‘开始时间_14_3’: 635, ‘开始时间_14_4’: 1009, ‘开始时间_15_0’: 91, } ‘开始时间_15_1’: 778, ‘开始时间_15_2’: 815, ‘开始时间_15_3’: 922, ‘开始时间_15_4’: 968, ‘开始时间_16_0’: } 527, ‘开始时间_16_1’: 639, ‘开始时间_16_2’: 796, ‘开始时间_16_3’: 853, ‘开始时间_16_4’: 931, } ‘开始时间_17_0’: 549, ‘开始时间_17_1’: 745, ‘开始时间_17_2’: 843, ‘开始时间_17_3’: 856, ‘开始时间_17_4’: } 1056, ‘开始时间_18_0’: 91, ‘开始时间_18_1’: 189, ‘开始时间_18_2’: 329, ‘开始时间_18_3’: 707, } ‘开始时间_18_4’: 1054, ‘开始时间_19_0’: 0, ‘开始时间_19_1’: 100, ‘开始时间_19_2’: 145, ‘开始时间_19_3’: 223, } ‘开始时间_19_4’: 992}
参考论文:https://arxiv.org/pdf/2504.16918


















 12
12

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











