






张杰、Cezara Petrui、Kristina Nikolić、Florian Tramèr
苏黎世联邦理工学院
摘要
现有的用于评估大型语言模型(LLMs)数学推理能力的基准主要依赖于竞赛题目、形式化证明或人为设置的难题,未能捕捉到实际研究环境中遇到的数学本质。我们引入了ReALMATH,这是一个直接从研究论文和数学论坛中提取的新基准,用于评估LLMs在真实数学任务中的表现。我们的方法解决了三个关键挑战:获取多样化的研究级内容、通过可验证陈述实现可靠的自动化评估以及设计一个可不断更新的数据集以缓解污染风险。对多个LLMs的实验结果揭示了其处理研究数学的能力令人惊讶地优于竞赛问题,表明当前模型尽管在高度复杂的问题上存在局限性,但可能已能作为工作数学家的宝贵助手。ReALMATH的代码和数据集已公开可用 1 { }^{1} 1。
1 引言
大型语言模型(LLMs)的数学能力已成为评估其推理和知识保留能力的重要视角。虽然在基础数学 [5, 11]、竞赛级数学 [8, 10, 17, 19, 20] 和形式化证明生成 [23, 24, 25] 方面投入了大量精力来评估LLMs,但这些评估可能不足以反映LLMs在现实世界数学研究环境中的潜在实用性。
目前的数学基准主要分为三类:(1) 来自课程材料 [5, 11] 或竞赛考试 [8](例如IMO或AIME)的基准,提供了大量带有解答的问题;(2) 集中于形式定理证明的基准,其中验证可以自动化 [24, 25];(3) 由数学专家设计的尽可能具有挑战性的基准 [9, 16]。然而,这些基准仅捕捉到了数学实践的一小部分。在野外遇到的数学——特别是在研究环境中——与竞赛题目的结构和主题大相径庭,很少依赖形式化证明,并且考虑的是并非(专门)设计为最大化难度的陈述和结果。
这种脱节引发了一个根本性的问题:
LLMs今天作为执业数学家助手的有效性如何?
为回答这一问题,我们引入了一种新基准,旨在评估LLMs在从文献中直接提取的研究级数学上的表现。构建这样的基准面临三大显著挑战:
1
{ }^{1}
1 代码可在以下地址获取:Github;数据集可在以下地址获取:Huggingface。
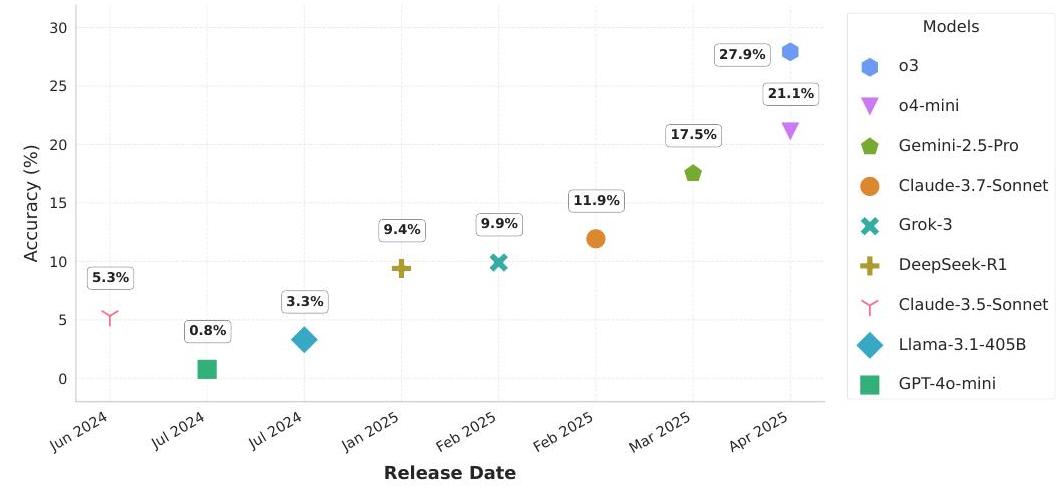
图1:LLM在arXiv数学论文的困难子集REALMATH上的表现。
首先,我们需要获取能够真实代表当代数学研究多样性和复杂性的内容。
其次,我们需要一种可靠的方法来评估正确性。与拥有标准化解答的竞争问题或形式化证明问题不同,研究数学提出了评估难题:人类专家验证资源密集且限制了可扩展性,而使用LLMs作为评判者则引发了可靠性担忧。
第三,我们必须应对随时间推移测试集污染的问题,因为纳入基准的数学内容可能会被吸收进未来模型的训练数据集中。
在本文中,我们提出了ReALMATH,这是一个通过以下方式解决这些挑战的数学基准:
- 从研究论文(如arXiv)和数学论坛(如Stack Exchange)中提取可验证数学陈述的数据管道,创建丰富的研究级内容语料库。
-
- 专注于可验证答案而非证明评估的评估方法,允许进行自动正确性检查。
-
- 可持续更新的数据集设计,利用庞大的数学文献体,定期用新内容更新以缓解污染问题。
我们系统地将数学陈述转化为问答对,保留理解所需的上下文。例如,一条定理指出“对于 n ≥ 1 n \geq 1 n≥1,长度为 n n n的浅层、避免123模式的中心对称排列的数量为 n 2 2 + 1 \frac{n^{2}}{2}+1 2n2+1,当 n n n为偶数时”[1] 转化为一个问题,“当 n n n为偶数时,长度为 n n n的避免123模式的中心对称排列的数量是多少?” 其可验证的答案为“ n 2 4 + 1 \frac{n^{2}}{4}+1 4n2+1”,并提供相关定义和符号作为上下文。
从大约9,000篇数学相关的学术论文中收集了九个月,我们的自动化管道精选了633个高质量样本,并且每个月可以生成超过70个新样本。我们对前沿LLMs的评估揭示了数学能力方面的有趣模式,这些模式与其他近期基准所观察到的不同。特别是,模型在我们的研究数学基准上的表现优于故意设计的高难度数据集,如数学竞赛或FrontierMath [9](见图1),这表明LLMs即使无法解决最先进问题,也可能已经在研究环境中提供了有价值的帮助。
尽管我们的方法侧重于陈述验证而非证明生成或验证,但它仍然为LLMs作为数学助手的潜力提供了有价值的信号。我们的发现表明,当前模型尽管在最具挑战性的数学问题上继续挣扎,但可能已经可以在数学研究环境中作为有用的工具。
总结来说,这项工作做出了若干贡献:它确立了使用有机研究数学评估LLMs数学能力的新范式;提供了抵抗污染的可持续基准创建方法;并对当前模型在代表真实数学实践的任务中的相对优势提供了见解。
- 可持续更新的数据集设计,利用庞大的数学文献体,定期用新内容更新以缓解污染问题。
2 相关工作
来自考试和竞赛的数学基准。近年来,在数学任务上评估LLMs取得了快速进展。早期数据集来源于学校材料或入门级数学竞赛,如GSM8K [5]、GHOSTS [7] 或MATH [11],并且接近饱和。对此,新的基准现在从高级数学竞赛中获取问题,如IMO [2, 15, 19]、AIME或Putnam竞赛 [20]。
来自研究专家的数学基准。越来越多的工作试图评估研究级别的数学推理。FrontierMath [9](以及HLE [16]的一部分)评估了由数学专家精心设计的极其具有挑战性的问题。这些基准集中在当前数学实践的一小部分(处于人类专业知识的前沿),并且需要极高的劳动强度才能整理。为了防止测试集污染,FrontierMath将测试集保密,这引入了可重复性障碍。相比之下,ReALMATH基准涵盖了整个数学研究实践范围,并能随着新研究的发布自动刷新。
定理证明基准。与我们的工作正交的是专注于形式化证明生成和机器可验证数学的基准,如LeanDojo [24] 和MiniF2F [25]。这些基准评估了LLMs在交互式定理证明器内生成形式化证明的能力,支持自动验证正确性。虽然这类工作对推进形式化方法和证明自动化至关重要,但它并不代表大多数未完全形式化的数学研究。
LLM能力“在野外”的基准。我们的工作补充了一个正在增长的研究领域,该领域旨在评估LLMs在现实世界任务中的能力,而不是经过精心策划的代理任务。例如,与其评估LLMs在编程竞赛中的编码能力 [12],像SWE-bench [13]、Lancer [14] 或BaxBench [21] 这样的项目更关注在现实世界的软件工程任务中评估LLMs。类似的变化也可以在评估LLMs进攻性网络能力的领域中观察到,其中一些最新的基准集中于评估真实的漏洞利用能力
[
4
,
6
]
[4,6]
[4,6],而不是解决策划好的夺旗竞赛的能力 [18]。
3 构建研究级数学基准
3.1 设计标准
为确保我们收集的数据质量,我们建立了以下设计准则:
- 实际应用重点:我们的收集方法优先考虑那些真正代表实际场景中遇到的数学问题。我们从学术研究出版物(如arXiv预印本)中获取问题,研究人员在此解决数学挑战以推动科学知识的进步,并从教育平台(如Mathematics Stack Exchange)中获取问题,学习者在此参与数学概念以发展他们的理解和解决问题的能力。与竞赛导向的基准不同,我们关注实际实践中遇到的代表性数学任务,强调程序性和技术驱动方面,而非比赛风格的创造性。
-
- 自动化验证:我们生成具有明确、无歧义验证标准的构造性问题(如[2]),通常问题是单个精确的数值或符号答案。这种方法排除了允许多个解决方案或涉及定性评估的问题,例如不等式(如下界、上界)或渐近关系,这会复杂化验证过程并可能引入歧义。这一选择也意味着我们省略了主要难点在于找到非构造性证明的陈述(例如,如果一篇论文的定理说“ P ≠ N P \mathrm{P} \neq \mathrm{NP} P=NP”,那么有趣的部分仅仅是证明,而不是陈述本身的构造)。
-
- 持续获取:领先的LLMs可能基于互联网数据进行训练,因此重要的是避免数据污染。为此,我们仅从公开可用的来源(如arXiv和StackExchange)收集数据,这些来源可以通过最少的人工干预实现自动收集。在每次新模型发布后,我们可以自动从互联网收集新鲜数据以评估模型,确保评估集保持未受污染且最新。

图2:arXiv论文的数据收集管道。核心步骤是确保从arXiv论文中提取的每个定理都有单一的确切答案。为保持数据质量,我们应用过滤机制,例如提示LLM丢弃容易解决的琐碎样本。
3.2 自动化和可刷新的数据收集管道
我们在图2中详细介绍了数据收集管道。本文其余部分主要使用arXiv论文的数据来说明我们的方法。附录A.5中提供了关于Stack Exchange数据集的更详细讨论。作为一个具体例子,我们使用2022年5月至9月期间选取的4,000篇arXiv论文的一个子集来说明数据收集管道的每个阶段。
| 步骤 | 可用样本数量 |
|---|---|
| 检索论文 | 05 / 2022 − 09 / 2022 05 / 2022-09 / 2022 05/2022−09/2022 (4,000篇论文) |
| 提取LaTeX源文件 | 3,922篇论文 |
| 提取定理 | 14,747条定理 |
| 确定具有固定答案的构造性定理 | 407条定理 |
| 生成问答(QA)对 | 401对QA |
| 过滤琐碎问题 | 280对QA |
表1:管道步骤示例及每阶段的可用样本数量。
我们的管道包括五个阶段:
- 检索论文。我们在指定的时间窗口内收集所有与数学相关的arXiv论文。此过程涉及查询arXiv API以获取数学或计算机科学类别的论文。举例来说,我们可以在五个月内从数学领域获取大约4,000篇论文,即从2022年5月至9月。
-
- 提取LaTeX源文件。对于每篇论文,我们下载并解析原始LaTeX源文件以准确保留数学符号。由于arXiv API响应偶尔出现错误或文件可用性问题(例如缺失或损坏的LaTeX源文件),成功处理的论文数量通常低于最初检索到的总数量。在我们的案例中,从4,000篇论文中,我们获得了3,922个可用样本。
-
- 确定具有固定答案的构造性定理。我们使用一个 L L M 2 \mathrm{LLM}^{2} LLM2来识别涉及构造单一确切答案的定理。LLM分析每个提取的定理,并根据其是否呈现清晰的数学陈述和无歧义的结果对其进行分类。我们特别排除涉及不等式或允许多个解决方案的定理,例如“如果条件 A A A满足,则关系 B B B发生”的定理,但条件 A A A不是唯一导致 B B B发生的条件,且关系 B B B不是等式或固定的数值关系。从3,922篇处理过的论文中,我们提取了407条被我们的评估模型分类为高质量的定理,总共检测到14,747条定理。
-
- 生成问答(QA)对。对于每个选定的定理,我们使用LLM将其转换为问答对。LLM总是尝试生成QA对,即使生成的问题答案容易回答。对于407条定理,我们获得了401对QA。
-
- 过滤琐碎问题。我们还实施了一个后处理阶段,其中LLM审查每个生成的QA对。此步骤过滤掉低质量样本,例如那些答案容易猜测的样本,或者从提供给LLM的上下文中显而易见的答案(例如,论文的引言部分经常非正式地陈述定理的结果)。最终,我们获得了280对准备用于评估阶段的QA对。
2 { }^{2} 2 默认情况下,我们使用OpenAI的o3-mini作为评估模型。详细的提示在附录A.1中提供。
对于每个测试样本,我们提供上下文(即定理前的所有相关文本)以及LLM生成的问题给前沿LLMs。只有当响应完全匹配地面真相答案时才视为正确。我们在图3中展示了一些详细示例。
- 过滤琐碎问题。我们还实施了一个后处理阶段,其中LLM审查每个生成的QA对。此步骤过滤掉低质量样本,例如那些答案容易猜测的样本,或者从提供给LLM的上下文中显而易见的答案(例如,论文的引言部分经常非正式地陈述定理的结果)。最终,我们获得了280对准备用于评估阶段的QA对。
定理到QA转换
原始定理
([3]中的定理1.1) 设
q
=
p
2
t
q=p^{2 t}
q=p2t,其中
p
≡
3
p \equiv 3
p≡3
(
m
o
d
4
)
(\bmod 4)
(mod4) 是一个素数且
t
t
t是一个正整数。那么Peisert图
P
∗
(
q
)
P^{*}(q)
P∗(q)中阶为3的团的数量为
k
3
(
P
∗
(
q
)
)
=
q
(
q
−
1
)
(
q
−
5
)
48
k_{3}\left(P^{*}(q)\right)=\frac{q(q-1)(q-5)}{48}
k3(P∗(q))=48q(q−1)(q−5)。
生成的问答对
Q: 设
q
=
p
2
t
q=p^{2 t}
q=p2t,其中
p
≡
3
p \equiv 3
p≡3
(
m
o
d
4
)
(\bmod 4)
(mod4)。表达为
q
q
q的函数,Peisert图
P
∗
(
q
)
P^{*}(q)
P∗(q)中阶为3的团的数量是多少?
A:
q
(
q
−
1
)
(
q
−
5
)
48
\frac{q(q-1)(q-5)}{48}
48q(q−1)(q−5)
([22]中的定理22) 自同构
φ
α
∘
(
Φ
,
∧
d
(
Φ
)
)
\varphi_{\alpha} \circ(\Phi, \wedge d(\Phi))
φα∘(Φ,∧d(Φ)),其中
α
∈
C
∗
\alpha \in \mathbb{C}^{*}
α∈C∗,可以提升到
Π
\Pi
Π-对称超Grassmannian
Π
G
r
2
k
,
k
\Pi \mathrm{Gr}_{2 k, k}
ΠGr2k,k,其中
k
≥
2
k \geq 2
k≥2,当且仅当
α
=
±
i
\alpha= \pm i
α=±i。
Q: 确定
α
∈
\alpha \in
α∈
C
∗
\mathbb{C}^{*}
C∗ 的值,使得自同构
φ
α
∘
(
Φ
,
∧
d
(
Φ
)
)
\varphi_{\alpha} \circ(\Phi, \wedge d(\Phi))
φα∘(Φ,∧d(Φ))可以提升到超Grassmannian
Π
G
r
2
k
,
k
\Pi \mathrm{Gr}_{2 k, k}
ΠGr2k,k,其中
k
≥
2
k \geq 2
k≥2。
A:
α
=
±
i
\alpha= \pm i
α=±i
过滤掉的例子
例1: 设 X \mathbb{X} X是一个一致凸Banach空间。那么 Γ ( X ) < 1 2 \Gamma(\mathbb{X})<\frac{1}{2} Γ(X)<21。
LLM可能会给出较弱但仍有效的界限(例如 Γ ( X ) < 1 \Gamma(\mathbb{X})<1 Γ(X)<1),这些答案并不等价。更强的答案(例如 < 0.4 <0.4 <0.4)需要评估模型进行更高级的验证。
例2: 对于任意凸体 K K K在 R n \mathbb{R}^{n} Rn中,存在 Φ ∈ G L ( n ) \Phi \in \mathrm{GL}(n) Φ∈GL(n)使得:
S ( Φ K ) n ∣ Φ K ∣ n − 1 ≤ S ( Δ n ) n ∣ Δ n ∣ n − 1 = n 3 n / 2 ( n + 1 ) ( n + 1 ) / 2 n ! \frac{S(\Phi K)^{n}}{|\Phi K|^{n-1}} \leq \frac{S\left(\Delta^{n}\right)^{n}}{\left|\Delta^{n}\right|^{n-1}}=\frac{n^{3 n / 2}(n+1)^{(n+1) / 2}}{n!} ∣ΦK∣n−1S(ΦK)n≤∣Δn∣n−1S(Δn)n=n!n3n/2(n+1)(n+1)/2
这是一个非构造性存在定理。它不能转换成固定答案的QA,这样LLM法官很容易验证。
图3:定理到QA转换过程的插图和过滤掉的样本。顶部面板展示了从包含固定、可验证答案的数学定理生成的高质量问答对示例。底部面板提供了因模糊或缺乏固定答案而被过滤掉的定理示例。
这个管道确保我们的基准保持最新、未受污染,并代表研究中面临的实际数学挑战。通过自动化收集过程,我们可以在研究社区中出现新的数学问题时不断刷新数据集。
关于标签噪声的讨论。我们的数据管道中的两个主要噪声来源是:(1) 源材料的固有质量;(2) 使用LLMs评估和转换数学内容的可靠性。尤其是来自Mathematics Stack Exchange的样本往往质量较低:问题常常表述不佳,包含数学错误,或缺乏论坛上的答案。因此,从这个来源获取高质量样本需要过滤大量的用户提交内容。此外,我们的管道依赖于LLMs评估提取定理的质量并生成QA对。因此,LLMs评估能力的任何限制或偏差可能会进一步引入数据集中的不准确性。
总体而言,我们的管道从arXiv论文中产生超过
94
%
94 \%
94%的高质量样本,无需任何人工注释。例如,在Mathematics类别中,我们处理了超过9,000份
表3:前沿LLMs在回答从研究论文和数学论坛中提取的数学问题时表现出色。请参阅图4和附录B. 2,以获取基于问题估计难度的更精细评估。
| 数据集 | o3 | o4 mini | Gemini 2.5-pro | Deepseek R1 | Grok 3 | Claude 3.7-Sonnet | Claude 3.5-Sonnet | Llama 3.1-405B | GPT 4o-mini |
|---|---|---|---|---|---|---|---|---|---|
| Math.arXiv | 49.1 \mathbf{4 9 . 1} 49.1 | 43.4 | 32.5 | 30.5 | 29.5 | 34.1 | 18.3 | 16.4 | 12.5 |
| CS.arXiv | 44.1 \mathbf{4 4 . 1} 44.1 | 42.3 | 25.2 | 31.5 | 25.2 | 31.5 | 16.2 | 15.3 | 7.2 |
| Math.StackExchange | 70.7 | 70.8 \mathbf{7 0 . 8} 70.8 | 60.9 | 62.2 | 54.8 | 61.1 | 37.6 | 32.1 | 40.8 |
论文并提取出633条被我们的评估模型分类为高质量的定理。然后我们手动审查每个样本,发现大约
6
%
6 \%
6%未达到我们的质量标准;这些被过滤掉了。这些结果表明,即使在处理不完美的现实世界来源时,我们的管道也能可靠地生成高质量数据,而无需太多人工干预(详见附录A. 3以获取更多详情)。
尽管我们的数据构建本质上假设从arXiv论文中获取的数学定理是正确的,但这当然并不能保证。arXiv论文不一定经过同行评审,可能存在错误或模糊的声明。
4
{ }^{4}
4 一方面,错误的陈述可能会在我们的结果中产生一些噪音(我们认为这是很小的)。另一方面,我们认为陈述或符号中的可能模糊是有益的,因为它真正代表了“野生”数学,相比正式竞赛设置中更精致和审查的内容。
4 实验
4.1 实验设置
我们使用第3节(和附录A)中描述的数据管道从三个数据源中提取超过1,200对问答对,分别是Math.arXiv、CS.arXiv和Math.StackExchange(见表3以获取汇总统计)。然后我们在这些数据集上评估了多个前沿模型——OpenAI o3和o4-mini、Claude 3.7 Sonnet、Gemini 2.5 Pro、Grok-3和DeepSeek-R1。为了比较,我们还包括了几种早期模型,如GPT-4o mini、Claude 3.5 Sonnet和LLaMA-3.1-405B。
表2:用于评估的最终数据集摘要。
| 数据集 | 时间跨度 | QA对数量 |
|---|---|---|
| Math.arXiv | 05 / 2022 − 09 / 2022 05 / 2022-09 / 2022 05/2022−09/2022 | 633 |
| CS.arXiv | 12 / 2024 − 03 / 2025 12 / 2024-03 / 2025 12/2024−03/2025 | 111 |
| Math.StackExchange | 04 / 2024 − 03 / 2025 04 / 2024-03 / 2025 04/2024−03/2025 | 542 |
输入格式在数据集之间略有不同以匹配其结构。对于CS.arXiv和Math.arXiv,每个模型接收LLM生成的问题以及目标定理之前的完整相关上下文,通常从介绍开始直至(但不包括)定理本身。相比之下,对于Math.StackExchange,输入仅包含LLM生成的问题,反映了原始论坛帖子的格式。
4.2 主要实验结果
前沿LLMs的结果。表3突出了我们在三个数据集上测试的各种LLMs的性能。十种模型在准确性上有所差异,o3和o4mini在所有数据集上领先。更具体地说,o3在CS.arXiv和Math.arXiv上实现了最高准确性,而o4-mini在Math.StackExchange样本上略微超过了它。其他模型,如Deepseek-R1和Gemini-2.5-pro,在arXiv数据集上的准确率在 25.6 % − 32.5 % 25.6 \% - 32.5 \% 25.6%−32.5%之间,而在Math.StackExchange上的准确率更高,达到 60.9 % − 62.2 % 60.9 \% - 62.2 \% 60.9%−62.2%。
4
{ }^{4}
4 另一种方法是将管道限制在同行评审的来源,但这会显著减少可用材料的多样性和覆盖范围。
我们承认我们的完整基准伴随着相对较高的初始性能,这可能引发对其持久性的质疑。事实上,最近的一些基准常见的趋势是设计尽可能具有挑战性的问题,导致接近零的性能 [9, 16]。然而,由于我们的基准旨在跟踪在真实、有机数学研究任务上的表现,我们并不认为这是一个问题。虽然一些基准追踪LLMs解决(少数)最困难数学问题的初步能力,但在ReAlMath上的性能提高可能更能反映LLMs在常见数学研究任务上的实用性。尽管如此,在以下实验中,我们也展示了我们数据集中的问题难度高度不均一,并且有一个“困难”子集,当前LLMs在其上的表现明显较差。
按难度级别细分。我们分析了模型在不同难度级别问题上的表现。为了确定这些难度级别,我们评估了较旧、较弱的模型在数据集样本上的表现。根据它们的表现,我们将样本分为不同的难度级别,详情见附录B.2。如图4所示,随着问题难度增加,准确度持续下降。例如,表现最好的模型o3在简单问题上的准确率为97.5%,在中等问题上下降到
81.4
%
81.4 \%
81.4%,在困难问题上进一步下降到仅
27.9
%
27.9 \%
27.9%。Gemini-2.5-Pro和DeepSeek-R1也显示出类似的下降趋势。这种模式突显了当前模型在处理更复杂和研究级别的数学时面临的重大挑战。
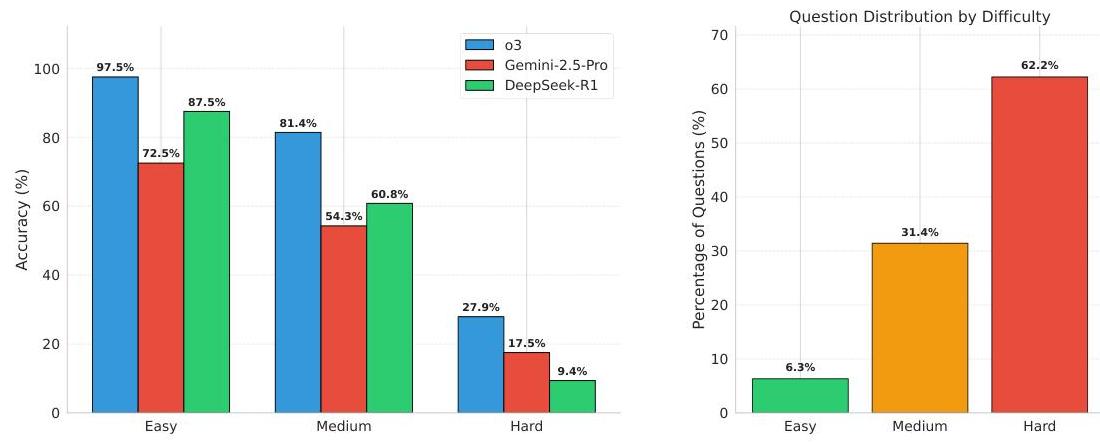
图4:(a) 最佳表现模型在Math.arXiv不同难度级别上的准确率和 (b) Math.arXiv的难度级别分布。更多细节和结果见附录B.2。
在研究子类别的表现分析。我们收集的数据集包含广泛学科的数学问题。使用人类报告的类别(arXiv类别或StackExchange标签),我们可以更细致地评估LLMs在特定领域的表现。附录B.4中的表4显示了Math.arXiv数据集的类别细分,其中数论(math.NT)和组合学(math.CO)的样本占主导地位,各自占比超过 20 % 20 \% 20%。这种分布与其他最近的基准一致,例如MathConstruct [2]和FrontierMath [9],源于多种因素(见附录A.4中的图9):(1) 该主题的论文数量较多;(2) 平均每篇论文中的定理数量较多;(3) 固定答案的构造性定理比例较高。
为了说明LLM在Math.arXiv上的表现,图5展示了该数据集上两个最佳模型o3和Gemini 2.5-pro在各类别中的准确率。对于o3,准确率最高的子类别是表示理论(math.RT)、数论(math.NT)和偏微分方程分析(math.AP),每个类别准确率超过
60
%
60 \%
60%。表现最差的子类别是优化与控制(math.OC)、离散数学(cs.DM)和机器学习(cs.LG),其中后者准确率仅为
23.8
%
23.8 \%
23.8%。
然而,这种能力特征在不同模型间并不统一。Gemini 2.5-pro在机器学习(cs.LG)、优化与控制(math.OC)和概率(math.PR)上表现最佳,而在组合学(math.CO)、表示理论(math.RT)和群论(math.GR)上表现最差。值得注意的是,Gemini 2.5-pro表现最佳的两类——机器学习和优化与控制——正是o3得分最低的类别!
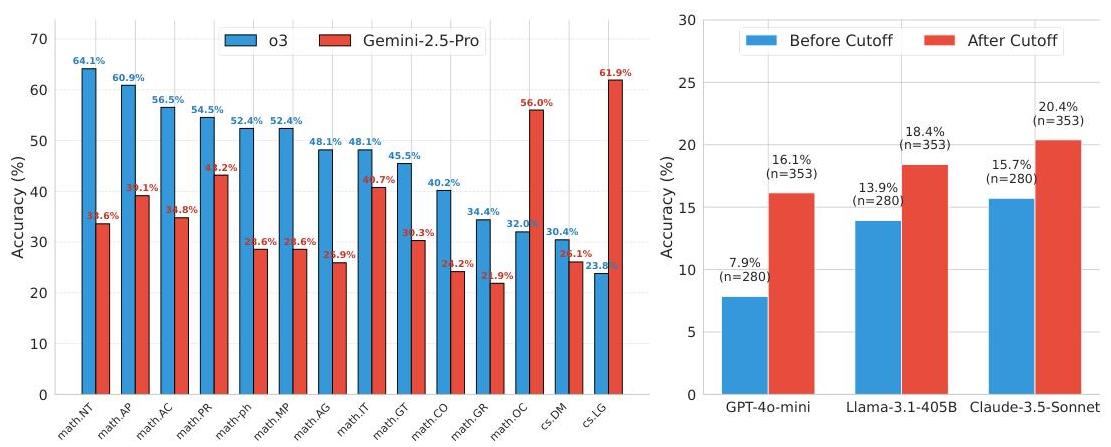
图5:在Math.arXiv数据集上,按领域和时间维度评估模型表现。左:两个模型在数学领域上的准确率,显示出显著的主题差异。右:GPT-4o-mini、Llama-3.1-405B和Claude-3.5Sonnet在训练截止日期前后的题目上的准确率。
总体而言,我们观察到o3在高度理论任务上表现良好,例如来自表示理论的任务,而Gemini 2.5-pro在具有更多实际应用的领域中表现最佳,例如机器学习或优化。
4.3 进一步分析
分析LLM的错误。为了更好地评估模型表现,我们引入了一个管道,将LLMs的输出与人类撰写的解决方案进行比较,这些解决方案取自原论文或经验证的StackExchange答案。这些解决方案提供给评估模型o3-mini,以评估LLMs的推理是否与人类解决方案一致。常见错误包括算术错误、错误论证、缺少关键洞察或逻辑不一致。在图6中,我们展示了o3、Gemini 2.5-pro和DeepSeek R1在Math.arXiv数据集上的错误分类。多数错误来自于推理缺陷,其次是概念误解和遗漏洞察。这表明,即使是最优表现的模型在解决方案中仍难以维持多步逻辑连贯性。
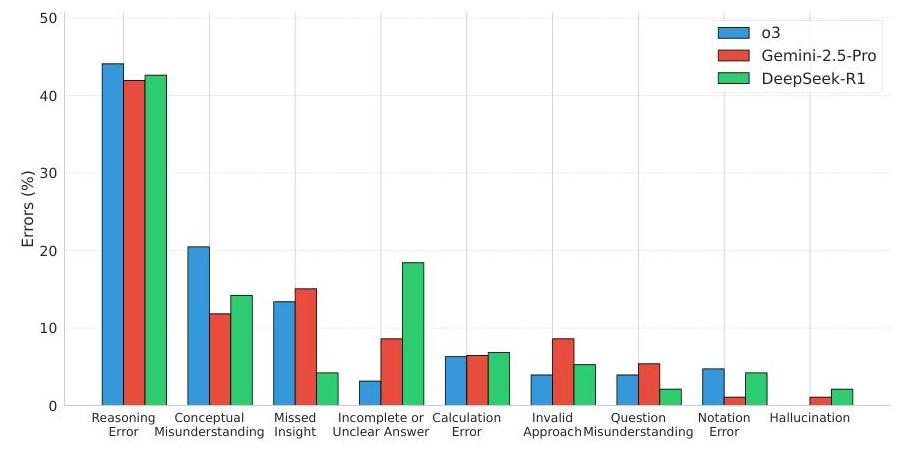
图6:o3、Gemini 2.5-pro和DeepSeek R1在Math.arXiv数据集上的错误类型。
定理的上下文有多重要?回想一下,在Math.arXiv和CS.arXiv中的问题,我们会向LLM提供定理的完整上下文,即定理陈述之前的整个研究论文。这种上下文对于理解定理的符号和陈述可能是至关重要的。然而,令人惊讶的是,即使没有提供这种上下文,LLMs仍然表现得相当不错。这表明许多定理使用的概念或符号可以在孤立的情况下被理解和推断。例如,在CS.arXiv数据集中,o4-mini模型在没有任何上下文的情况下达到了
21.6
%
21.6 \%
21.6%的准确率
问题1:设
F
\mathcal{F}
F是一个
n
×
m
n \times m
n×m费雷尔图表,其中
m
≥
n
m \geq n
m≥n,并设
1
≤
d
≤
n
1 \leq d \leq n
1≤d≤n为整数。假设对
(
F
,
d
)
(\mathcal{F}, d)
(F,d)是MDS-可构造的,并设
κ
=
κ
(
F
,
d
)
\kappa=\kappa(\mathcal{F}, d)
κ=κ(F,d)。请问
lim
q
→
+
∞
δ
q
(
F
,
κ
,
d
)
\lim _{q \rightarrow+\infty} \delta_{q}(\mathcal{F}, \kappa, d)
limq→+∞δq(F,κ,d)的值是什么?
问题2:给定参数 σ 1 2 , σ 2 2 \sigma_{1}^{2}, \sigma_{2}^{2} σ12,σ22,和 c ≤ c ( σ 1 2 , σ 2 2 ) c \leq c\left(\sigma_{1}^{2}, \sigma_{2}^{2}\right) c≤c(σ12,σ22),请问 lim n → ∞ C s ( σ 1 2 , σ 2 2 , c n , n ) n \lim _{n \rightarrow \infty} \frac{C_{s}\left(\sigma_{1}^{2}, \sigma_{2}^{2}, c \sqrt{n}, n\right)}{n} limn→∞nCs(σ12,σ22,cn,n)用 σ 1 2 , σ 2 2 \sigma_{1}^{2}, \sigma_{2}^{2} σ12,σ22和 c c c表示的值是什么?
问题3:请问 lim odd k → ∞ α ( f 1 ( k + 1 ) / 2 ) , k ) ρ ( f 1 ( k + 1 ) / 2 ) , k ) \lim _{\text {odd } k \rightarrow \infty} \frac{\alpha\left(f_{1(k+1) / 2), k}\right)}{\rho\left(f_{1(k+1) / 2), k}\right)} limodd k→∞ρ(f1(k+1)/2),k)α(f1(k+1)/2),k)的值是什么?
图7:无需任何上下文即可由LLMs解决的问题。有趣的是,LLMs可以推断出问题2中
C
s
C_{s}
Cs的含义以及问题3中
α
,
ρ
,
f
\alpha, \rho, f
α,ρ,f的含义。附录B. 5包含LLMs在没有上下文时无法解决的问题示例。
尽管没有提供任何上下文,准确率仍达到
21.6
%
21.6 \%
21.6%(与提供完整上下文时的
42.3
%
42.3 \%
42.3%相比)。我们在图7中展示了一些无需上下文即可解决的问题示例。
测量数据污染的影响。ReALMATH的核心特性之一是它可以不断更新新的有机样本,使基准与当代数学保持同步并防止数据污染。这一特性使REALMATH区别于其他研究级基准,后者要么需要专家进行广泛的手动整理
[
9
,
16
]
[9,16]
[9,16],要么只能每年扩展几个新样本
[
2
,
19
]
[2,19]
[2,19]。
为了测试数据污染,我们根据GPT-4o-mini、Llama-3.1-405B和Claude-3.5-Sonnet的截止日期,将Math.arXiv数据集分成两批。图5显示了截止日期前后发表的论文的准确率(即2022年的论文与2025年的论文)。有趣的是,我们发现模型在2025年的新样本上的表现优于2022年的旧样本。一种解释可能是数学研究从2022年到2025年变得显著更容易(至少对于LLMs来说),这似乎不太可能。相反,我们相信一个可能的解释是当前LLMs已经接受了大量的接近其截止日期的数学数据训练,因此LLMs可能对当前数学研究中探讨的主题更为熟悉。
我们注意到,ReALMATH的一个很好的应用将是研究数学研究(和LLMs的表现)随时间的演变,这一分析留待未来工作。
微调影响分析。为了评估ReALMATH是否可以用来提高LLMs的数学能力,我们使用Math.arXiv数据集中随机抽取的500个样本对GPT-4o-mini进行了微调,并评估了其在剩余133个样本上的表现。令人惊讶的是,微调并没有带来准确率的提高(详见附录B. 1以获取更多详情)。这表明基准的难度并非源于当前LLMs的问题分布之外。相反,当前模型似乎缺乏解决某些问题所需的专门数学知识或技能,这些知识或技能无法通过简单的微调有效获得。
5 结论
我们的工作引入了ReALMATH,这是一种评估LLMs在研究级数学表现的新基准。我们展示了当前前沿模型在研究数学中表现出乎意料的强大能力,领先模型在Math.arXiv论文上准确率达到
43
−
49
%
43-49 \%
43−49%,在Math.StackExchange问题上准确率高达
70
%
70 \%
70%。这表明这些模型可能已经在数学研究环境中作为有价值的助手,尽管它们在最困难的问题上仍然挣扎。
ReALMATH的一个核心特性是它不是一个固定的基准,而是一个可刷新的数据收集管道,反映当前数学实践同时防止数据污染。我们相信ReALMATH可以作为一种有价值的工具,用于评估和改进LLMs的数学能力。其设计符合数学家的实际需求,有助于推动AI助手在研究中的应用。随着模型在我们的基准上表现提升,LLMs可能在数学研究和教育中作为协作工具得到更广泛的应用。
参考文献
[1] Kassie Archer, Aaron Geary, and Robert P. Laudone. Pattern-avoiding shallow permutations, 2025.
[2] Mislav Balunović, Jasper Dekoninck, Nikola Jovanović, Ivo Petrov, and Martin Vechev. Mathconstruct: Challenging llm reasoning with constructive proofs. arXiv preprint arXiv:2502.10197, 2025.
[3] Anwita Bhowmik and Rupam Barman. Number of complete subgraphs of peisert graphs and finite field hypergeometric functions. Research in Number Theory, 10(2):26, 2024.
[4] Nicholas Carlini, Javier Rando, Edoardo Debenedetti, Milad Nasr, and Florian Tramèr. Autoadvexbench: Benchmarking autonomous exploitation of adversarial example defenses, 2025.
[5] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021.
[6] Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. Llm agents can autonomously exploit one-day vulnerabilities, 2024.
[7] Simon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, Tommaso Salvatori, Thomas Lukasiewicz, Philipp Petersen, and Julius Berner. Mathematical capabilities of chatgpt. Advances in neural information processing systems, 36:27699-27744, 2023.
[8] Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. Omni-math: A universal olympiad level mathematic benchmark for large language models. CoRR, abs/2410.07985, 2024.
[9] Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, Shreepranav Varma Enugandla, and Mark Wildon. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai, 2024.
[10] Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. CoRR, abs/2402.14008, 2024.
[11] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the NeurIPS Datasets and Benchmarks Track, 2021.
[12] Yiming Huang, Zhenghao Lin, Xiao Liu, Yeyun Gong, Shuai Lu, Fangyu Lei, Yaobo Liang, Yelong Shen, Chen Lin, Nan Duan, and Weizhu Chen. Competition-level problems are effective llm evaluators. CoRR, abs/2312.02143, 2023.
[13] Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? CoRR, abs/2310.06770, 2023.
[14] Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn 1 million from real-world freelance software engineering?, 2025.
[15] Ivo Petrov, Jasper Dekoninck, Lyuben Baltadzhiev, Maria Drencheva, Kristian Minchev, Mislav Balunović, Nikola Jovanović, and Martin Vechev. Proof or bluff? evaluating LLMs on 2025 USA math olympiad. arXiv preprint arXiv:2503.21934, 2025.
[16] Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Daron Anderson, Tung Nguyen, Mobeen Mahmood, Fiona Feng, Steven Y. Feng, Haoran Zhao, Michael Yu, Varun Gangal, Chelsea Zou, Zihan Wang, Jessica P. Wang, Pawan Kumar, Oleksandr Pokutnyi, Robert Gerbicz, Serguei Popov, John-Clark Levin, Mstyslav Kazakov, Johannes Schmitt, Geoff Galgon, Alvaro Sanchez, Yongki Lee, Will Yeadon, Scott Sauers, Marc Roth, Chidozie Agu, Søren Riis, Fabian Giska, Saiteja Utpala, Zachary Giboney, Gashaw M. Goshu, Joan of Arc Xavier, Sarah-Jane Crowson, Mohinder Maheshbhai Naiya, Noah Burns, Lennart Finke, Zerui Cheng, Hyunwoo Park, Francesco Fournier-Facio, John Wydallis, Mark Nandor, Ankit Singh, Tim Gehrunger, Jiaqi Cai, Ben McCarty, Darling Duclosel, Jungbae Nam, Jennifer Zampese, Ryan G. Hoerr, Aras Bacho, Gautier Abou Loume, Abdallah Galal, Hangrui Cao, Alexis C. Garretson, Damien Sileo, Qiuyu Ren, Doru Cojoc, Pavel Arkhipov, Usman Qazi, Lianghui Li, Sumeet Motwani, Christian Schröder de Witt, Edwin Taylor, Johannes Veith, Eric Singer, Taylor D. Hartman, Paolo Rissone, Jaehyeok Jin, Jack Wei Lun Shi, Chris G. Willcocks, Joshua Robinson, Aleksandar Mikov, Ameya Prabhu, Longke Tang, Xavier Alapont, Justine Leon Uro, Kevin Zhou, Emily de Oliveira Santos, Andrey Pupasov Maksimov, Edward Vendrow, Kengo Zenitani, Julien Guillod, Yuqi Li, Joshua Vendrow, Vladyslav Kuchkin, and Ng Ze-An. Humanity’s last exam. CoRR, abs/2501.14249, January 2025.
[17] Tomohiro Sawada, Daniel Paleka, Alexander Havrilla, Pranav Tadepalli, Paula Vidas, Alexander Perikles Kranias, John J Nay, Kshitij Gupta, and Aran Komatsuzaki. ARB: Advanced reasoning benchmark for large language models, 2024.
[18] Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Haoran Xi, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. Nyu ctf bench: A scalable open-source benchmark dataset for evaluating llms in offensive security. In NeurIPS, 2024.
[19] Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, Lei Fang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models, 2025.
[20] George Tsoukalas, Jasper Lee, John Jennings, Jimmy Xin, Michelle Ding, Michael Jennings, Amitayush Thakur, and Swarat Chaudhuri. Putnambench: A multilingual competitionmathematics benchmark for formal theorem-proving. In AI for Math Workshop @ ICML 2024, 2024.
[21] Mark Vero, Niels Mündler, Victor Chibotaru, Veselin Raychev, Maximilian Baader, Nikola Jovanović, Jingxuan He, and Martin Vechev. Baxbench: Can llms generate correct and secure backends?, 2025.
[22] Elizaveta Vishnyakova and Mikhail Borovoi. Automorphisms and real structures for a
π
\pi
π symmetric super-grassmannian. Journal of Algebra, 644:232-286, 2024.
[23] Kaiyu Yang and Jia Deng. Learning to prove theorems via interacting with proof assistants. CoRR, abs/1905.09381, 2019.
[24] Kaiyu Yang, Aidan M Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. Leandojo: Theorem proving with retrievalaugmented language models. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
[25] Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. minif2f: a cross-system benchmark for formal olympiad-level mathematics. In International Conference on Learning Representations, 2022.
A 数据收集与评估
A. 1 法官模型的提示
我们使用了以下两个系统提示,提供给LLM(o3-mini)以实现:(1) 过滤定理以保留仅具有唯一答案的定理;(2) 从定理生成高质量的问答对。
SYSTEM_PROMPT_THEOREM = r"“”
2}\mathrm{ You are an expert in mathematics and computer science. Your task is to
verify if a theorem has a single, numerical answer, easy to be
verified. The theorems should be at least graduate level.
3
4 The theorems should have a fixed numerical answer, not an
approximation. Some common examples:
5}\mathrm{ - Necessary and Sufficient Conditions: e.g., “X holds if and only if
condition A holds” only when at least one of A and X is specific,
numerical quantity. We want results of the form “If condition A
holds, then condition X holds” ONLY WHEN X is a NUMERICAL VALUE.
We don’t want “if some conditions are met, then the quantity
satisfies a particular equation, then we can get X” when X is not
a strict numerical value relation, because this does not have
fixed unique solutions. Please be very strict about these rules!
6 - Existence and Uniqueness Theorems: e.g., “There exists a unique X
that satisfies A.”, but we don’t want “There exists an X that
satisfies A”, because the latter is not a fixed unique solution.
7 - Exact Formula Calculations: e.g., “The answer of formula (1) is 10”,
or “The solution for formula (1) is X”, then both are fixed
unique solutions.
8 - Unique Maximum/Minimum Points: e.g., “The maximum value of function
f is 10 at point x=1”, but we don’t want “The maximum value of
function f is at least 10”, because the latter is not a fixed
unique solution.
9 - Exact Complexity Results in Computational Complexity: e.g., “The
time complexity of algorithm A is exactly $\Theta(n^2)$” (not $
Omega(n^2)$ or $0(n^2)$, because big-0 and big-omega are not exact
10 - Explicit number of solutions of an equation: e.g. “X has a unique
solution y \in Y” is accepted even if the numerical value of the
number of solutions is not specified because it can trivially be
deduced that the number of solutions is 1, which is a fixed answer
. We also accept “If X, there are no solutions y \in Y” (implies 0
solutions). BUT we DON’T WANT the previous examples if the set Y
in which we look for answers is not clear.
11 - Equality of two numerical equations: e.g., \sum_{k=1}^n k^2 = \frac{
n(n-1)}(2) because we can assume the numerical fixed answer to be
the difference of the 2 which is 0. You MUST include these
equalities even if $n$ is not fixed but rather a variable. You
MUST also include equations of the form “limit of f(n) = integral
of g(x)”
12
13
14}\mathrm{ Some examples of theorems that we don’t want:
15}\mathrm{ - We DON’T want the theorems that contain if and only if when neither
of the sides is numerical ($x \in T$ does not represent a
numerical value), e.g. “A graph is bipartite if and only if it
contains no cycles of odd length.”
16 - We DON’T want theorems of the type “A holds if and only if there
exists x such that X(x) holds”, but we DO WANT “A holds if and
only if for all x, X(x) holds”, where X(x) is a fixed numerical
value.
17 - We DON’T want the theorems that have any approximations, or any
inequalities, or any other non-deterministic statement. e.g. The
theorems for which the main result involves the Big-0 notation, or
where the main result proven in the theorem is that a certain
relation holds "if and only if n \geq x or n \leq y" MUST be
rejected. We DO NOT consider any theorems where the answer is not
an equality or a fixed answer, i.e. results of the type "n \geq 5"
should NOT be considered, so just SKIP these types of theorems.
- We DON'T want the theorems that state "X $\in \backslash$ in\$ complexity class Y"
- since Y can belong to a bigger complexity class Z, so the answer
- is not unique.
- - We DON'T want the theorems that state "X is isomorphic or
- homomorphic with Y", e.g., Chinese Remainder Theorem.
- Important guidelines:
- - if you cannot find a single, definitive answer, you should return an
- empty result
- - please be very strict about the theorem, if there is any ambiguity,
- you should return a "false"
- - Respond only in the specified JSON format
- return in this exact JSON format:
- {
- "single_unique_answer": "true" if the theorem has a single,
- definitive answer, otherwise "false"
- "explanation": "explanation of if this theorem has a single,
- definitive answer, otherwise an empty string",
- }
- " " "
SYSTEM_PROMPT_GENERATE_QA = r"“”
You are a skilled problem setter for graduate-level mathematics and
theoretical computer science. You are provided with a set of
theorems (called theorems_dataset), each of which has already been
verified to contain a single, definitive, and numerical answer.
Your task is to convert each verified theorem into a precise **
question-answer (QA) pair**. MAKE SURE TO NOT MENTION THE ANSWER
TO THE QUESTION IN THE QUESTION ITSELF.
Your outputs must follow these rules:
- 问题应为一个清晰表述的数学或理论问题,清楚地让研究生水平的学生理解。不要提出无需任何数学推理即可轻易回答的问题或容易猜测答案的问题。你绝不应在问题开头使用“证明以下”
-
- 问题必须基于定理中的信息原则上可以解决,并且有唯一的数值或数学答案。
-
- 答案必须是:
-
- 严格且唯一确定。
-
- 表达为数字、封闭形式表达式或公式。
- 不要引入额外假设或背景。只使用定理中明确陈述或暗示的内容。
-
- 如果问题自然遵循恒等式的结构(例如,“…的和是多少?”),按这种方式构建问题。
-
- 所有问答对必须反映定理的确切范围。不要概括、削弱或加强其主张。
-
- 不要生成问答对如果定理含糊不清。不要为定理的主要结果是不等式或大O符号的定理生成问答对。我们绝不包括任何形式的不等式、关于下界/上界的问题或任何算法的渐进运行时间,即不要为定理的主要结果是类型“n ≥ 5”的定理生成问答对。
10.8. 不要在问题中包含答案,例如,如果定理陈述“X的极限等于Y”,其中Y是一个由定理中定义的参数表达式,将问题表述为“在给定参数的情况下,X的极限是什么?”,关联的答案为“X的极限是Y”。不要以“证明以下关系…”的形式构建问题,因为答案已经包含在问题中。此外,如果定理的主要结果询问某个关系成立时参数的值,在问题中不要提及该结果,而是问“关系成立时参数的值是多少?”。
- 不要生成问答对如果定理含糊不清。不要为定理的主要结果是不等式或大O符号的定理生成问答对。我们绝不包括任何形式的不等式、关于下界/上界的问题或任何算法的渐进运行时间,即不要为定理的主要结果是类型“n ≥ 5”的定理生成问答对。
- 如果定理说明某个方程有特定数量的解(单个/唯一解、无解、无限多解等),但未给出解的实际值,考虑问答对的形式为“这个方程有多少个解?”,即即使定理没有明确的数值表达作为答案,也可以将其视为具有固定答案的定理,其中固定答案是方程的解的数量。然而,如果定理声明中提到解的数值或闭合形式,则最好将问题构建成“以下方程的解是什么…?”而不是询问解的数量。
11.10. 对于形式为“ X X X 具有某种属性当且仅当 Y Y Y 具有某种属性”的定理,将问题构建成使得答案是“当且仅当”语句中指示明确数值表达的一侧,而非抽象定义的一侧,即如果定理陈述“X是Pareto最优当且仅当 \ Phi ( X ) = 0 \backslash \operatorname{Phi}(X)=0 \Phi(X)=0 ”,考虑问题是“如果 X X X是Pareto最优, \ Phi ( X ) \backslash \operatorname{Phi}(X) \Phi(X) 的值是多少?”而答案为“ \ P h i \backslash \mathrm{Phi} \Phi (X) = 0 ′ ′ =0^{\prime \prime} =0′′,因为关系 \ Phi ( X ) = 0 \backslash \operatorname{Phi}(X)=0 \Phi(X)=0 是数值性的,而另一部分“当且仅当语句”,即“X是Pareto最优”是一个抽象属性。因此,你绝不应考虑问题是“How is X if \ Phi ( X ) = 0 \backslash \operatorname{Phi}(\mathrm{X})=0 \Phi(X)=0 ?” 因为答案“X是Pareto最优”不是一个唯一答案。 - 对于形式为“以下恒等式成立: X = Y X=Y X=Y ”的定理,如果恒等式两边 X X X和 Y Y Y都是既非封闭形式也非固定数值的数学表达式(即如果我们有复杂公式的两个和相等,而非类型“ X = 5 X=5 X=5 ”的等式),不要问“ X X X的值是多少?”并将答案设为“Y”,因为 Y Y Y可能不是该问题的唯一答案。相反,你应该将问题构建成“ X − Y X-Y X−Y的值是多少?”并给出固定的明确答案“X-Y = 0”。在这个包含明确问答对的定理池中,不要考虑那些假设 X X X是极限且 Y Y Y是极限值的定理,因为这种情况应按照条件8处理。
-
- 对于形式为“以下恒等式成立: X = Y + c t X=Y+\mathrm{ct} X=Y+ct ”的定理,如果恒等式两边 X X X和 Y Y Y都是既非封闭形式也非固定数值的数学表达式,你应该问“ X − Y X - Y X−Y的值是多少?”并将答案设为“ct”而不是“ X − Y − c t X - Y -ct X−Y−ct”
-
- 对于形式为“如果X成立,那么Y ”的定理,构建问答对以询问当关系X成立时Y发生了什么,而不是询问Y成立的条件(因为如果定理不是“当且仅当”的形式,条件X可能不是唯一的)。
-
- 不要为定理的主要结果属于复杂性类的定理生成问答对。
-
- 如果定理陈述结果为“Y = |X|”,其中|X|表示集合X的基数,构建问题为“用…来表示X的基数是多少?”并将答案设为“Y”,而不是反过来,即不要说“Y的值是多少?”并将答案设为“X的基数”,因为在逻辑上不合理地将问题表述为关于数值量,而不是确定集合特性的特征。
以严格的以下JSON格式返回输出:
{
“question”: “从定理衍生出的明确表述的、唯一答案的问题。如果定理不好,返回空字符串”,
“answer”: “从定理衍生出的单一、唯一、准确的答案。如果定理不好,返回空字符串”,
“is_good_theorem”: "如果定理好则为true,否则为false
}
" " "
- 如果定理陈述结果为“Y = |X|”,其中|X|表示集合X的基数,构建问题为“用…来表示X的基数是多少?”并将答案设为“Y”,而不是反过来,即不要说“Y的值是多少?”并将答案设为“X的基数”,因为在逻辑上不合理地将问题表述为关于数值量,而不是确定集合特性的特征。
A. 2 评估模型的提示
我们使用了以下系统提示和用户提示,提供给GPT 40以评估LLMs对数学问题的回答是否正确。
system_prompt = r"““您是一位负责评估数学问题答案正确性的专家数学家
比较生成的答案与标准答案,并判断生成的答案是否在数学上正确
并等价于标准答案。
请非常严格和严谨地进行评估,即使答案有80%或90%正确也要标记为错误。确保生成的答案可以直接在标准LaTeX中呈现
而不需要自定义命令定义。精确并专注于数学上的正确性,而非格式或风格差异。
您的评估应该是公平的,并考虑到相同的数学内容可以用不同的方式表达。” " "
user_prompt = f”""问题:{问题} 标准答案:{
标准答案} 生成的答案:{最终答案} 仔细评估生成的答案是否在数学上正确
并等价于标准答案。您的回应应该仅包含一个JSON对象,包含以下字段:
{{
“is_correct”: boolean,
“explanation”: “一个简洁解释为什么答案正确或不正确的理由,以干净的LaTeX格式”
} }
其中is_correct为true表示答案在数学上正确且等价于标准答案,false表示不是。
" " "
A. 3 手动审查
对于我们在第4节中分析的数据集,我们依赖人工审查以确保样本的质量。正如第3.2节所述,对于Math.arXiv,我们去除了 5.2 % 5.2 \% 5.2%的不良样本,而对于CS.arXiv,我们丢弃了 7.5 % 7.5 \% 7.5%的样本。图8显示了每个类别中手动丢弃的项目百分比(Math.arXiv共有35个样本,CS.arXiv共有9个样本)。这些样本要么是定理,要么是问答对,它们没有唯一答案,但被LLMs在自动化管道的前几个阶段未能过滤掉。
A. 4 构建阶段中的类别分布
我们数据集中的问题根据其领域(如arXiv论文类别)分为人类标注的类别。图9展示了数据集构建各阶段中类别分布的变化。组合数学(math.CO)在后期阶段变得越来越占主导地位,

图8:每个类别在最终手动审查阶段中消除的样本。
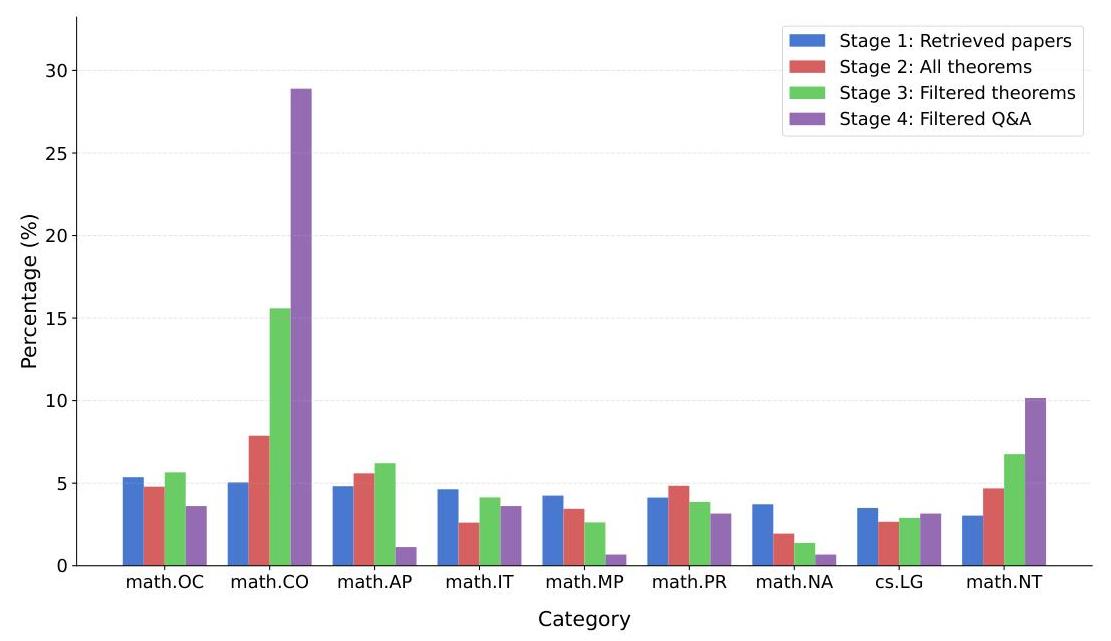
图9:Math.arXiv(05/2022 - 09/2022)数据集中不同构建阶段的类别分布。x轴显示主题类别(例如,math.CO、math.NT等),y轴代表每个类别占数据集的百分比。值得注意的是,组合数学(math.CO)在后期阶段变得更加占主导地位,特别是在最终的问答数据集中。
因为这些论文往往包含大量定理,其中许多非常适合问答格式。
A. 5 Mathematics Stack Exchange的管道
第3节中描述的管道专为arXiv论文设计。为了检索和处理来自Mathematics Stack Exchange的样本,我们需要调整一些步骤。我们首先查询相应的API以获取带有标签如[limits]、[definite-integrals]、[integration]的问题——这些预期会有明确的数值答案——以及可用的最高排名答案。我们提取HTML格式文本,并使用LLM将用户的帖子转换为陈述和证明格式,类似于从arXiv论文中提取的定理。然后我们应用手动过滤步骤以确保陈述有固定答案并且答案确实正确(为此,我们检查引用的来源以及其他用户发布的最高评价答案)。最后,我们将制定的定理输入LLM以生成问答对并过滤琐碎的样本。
A. 6 可选的LaTeX转换
为了提高数据集的人类可读性,我们纳入了一个LaTeX格式化步骤,要求LLM将每个定理转换为独立且有效的LaTeX代码(这需要例如扩展所有宏)。我们验证了此步骤不会对语言模型生成问答对或过滤低质量样本的能力产生负面影响。
B 额外结果
B. 1 微调
在图10中,我们使用OpenAI的微调服务对我们的数据集进行GPT-4o-mini的微调。我们在图11中展示了详细的训练和测试损失。为确保可靠性,我们重复评估五次并报告结果的均值和标准差。令人惊讶的是,我们没有观察到统计学意义上的改进。
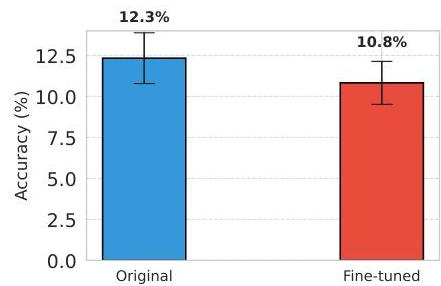
图10:原始与微调后的GPT-4o-mini在Math.arXiv上的准确率。
图11展示了OpenAI微调的训练和测试损失曲线。训练损失迅速下降并保持较低水平,表明模型很好地拟合了训练数据。另一方面,测试损失表现出波动行为,并随着时间推移相比开始时有所增加。这种模式可能解释了模型泛化失败的原因,进一步强化了微调并未带来性能提升的观点。
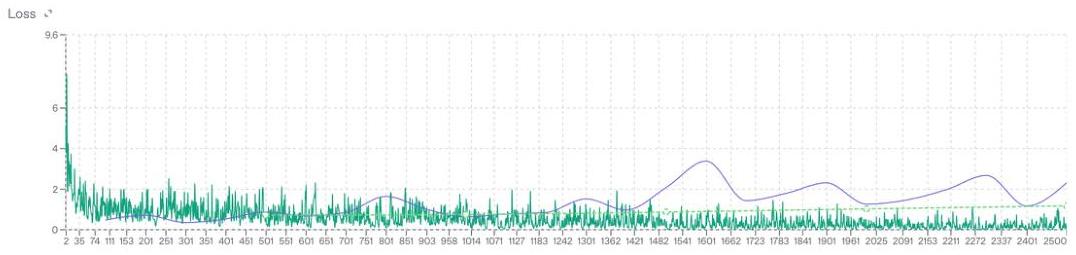
图11:来自OpenAI微调服务的训练(绿色)和测试(紫色)损失曲线。在我们的数据集上进行微调并没有显示出明显的改进。
B. 2 难度级别
我们通过使用较旧、较弱的模型并检查它们在样本上的表现来评估数据集中样本的难度级别。更具体地说,我们评估了四个不同家族的较旧模型的表现——Qwen3-235B、Claude 3.5 Haiku、GPT-3.5 Turbo和Llama 3.3-70B。
困难类别的样本是没有被上述任何模型正确回答的样本,而中等和简单类别的样本是被少于 50 % 50 \% 50%的LLMs(即1-2个中的4个)正确回答的样本,以及被超过 50 % 50 \% 50%的模型(即3-4个中的4个)正确回答的样本。
图12描绘了CS.arXiv数据收集中的样本在各类别中的分布,其中 69.4 % 69.4 \% 69.4%的样本被认为是困难的。这种分布表明我们的数据集确实反映了研究社区的适当难度水平。
此外,我们展示了部分最佳表现模型——o3、DeepSeekR1和Gemini-2.5-Pro——在CS.arXiv上的每类准确率。除o3外的三个LLMs(除o3外),随着难度级别的增加,准确率大幅下降,例如DeepSeek-R1在简单样本上的准确率为100%,而在困难样本上的准确率仅为
11.7
%
11.7 \%
11.7%。这是预期的模式,进一步证实了我们样本在这三个类别中的正确评估。
较高难度级别样本上o3的准确率相较于简单样本有所提高——75% vs
71.4
%
71.4 \%
71.4%——并不一定意味着异常行为,这可以通过两类样本数量差异来解释,其中我们有
18
%
18 \%
18%的样本被认为是中等难度,而仅有
12.6
%
12.6 \%
12.6%的样本被标记为简单。特别地,在困难类别中,我们注意到o3的相对较高的准确率,即
31.2
%
31.2 \%
31.2%,相比之下DeepSeek-R1和Gemini-2.5-Pro的准确率都不足
12
%
12 \%
12%。
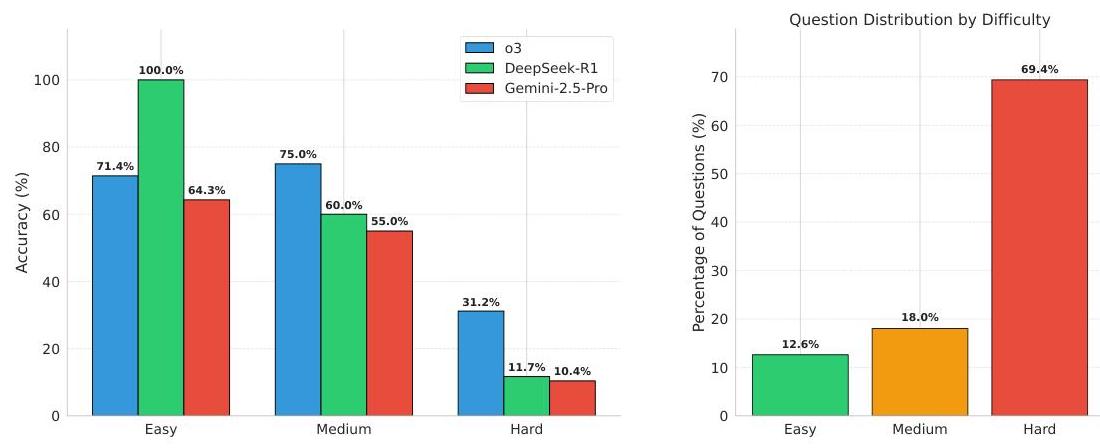
图12:CS.arXiv上最佳表现模型在不同难度级别上的准确率。
沿着同样的思路,图13展示了Math.StackExchange数据集的分布。我们注意到这个数据集的分布更为分散,中等难度的问题出现频率最高,与Math.arXiv和CS.arXiv的分布相反,后者的问题主要被分类为困难。这反映了Math.StackExchange的性质,它侧重于澄清本科和研究生水平的概念和计算,而非创新的研究级探究。
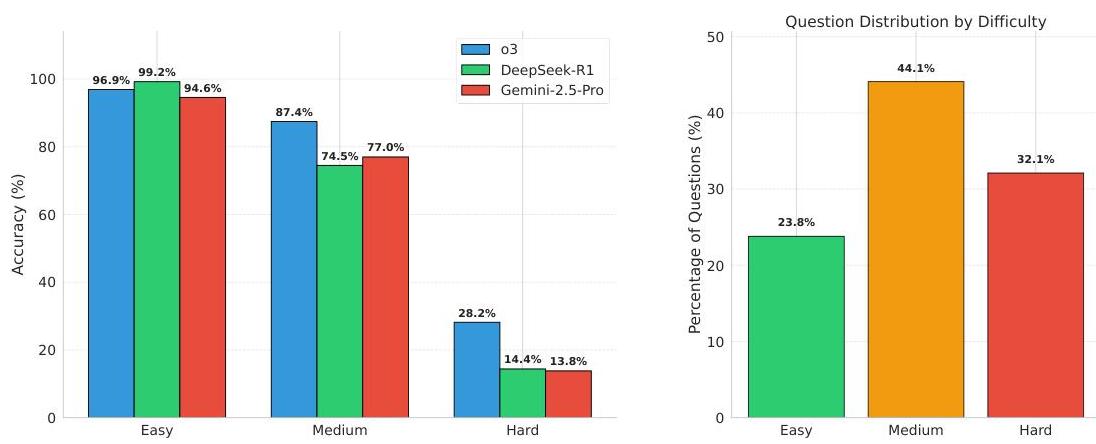
图13:math.stackExchange上最佳表现模型在不同难度级别上的准确率。
B. 3 各类别表现
我们评估了模型在每个子类别(针对CS.arXiv)和每个标签(针对Math.StackExchange)上的表现,以了解某些模型是否在特定类别的问题上表现特别出色。在图14中,我们展示了o3和Gemini-2.5-Pro的准确率。
一方面,我们注意到在CS.arXiv中,除了计算机科学中的逻辑(cs.LO)类别外,模型表现相同,o3在每个类别上都优于Gemini-2.5-Pro。另一方面,图14(a)中一个重要的特征是o3在应用类别如离散数学(cs.DM)和机器学习(cs.LG)上更擅长解决问题,而Gemini-2.5-Pro在理论主题如计算复杂性(cs.CC)和信息论(cs.IT)上获得最高准确率。这与这两个LLMs在Math.arXiv数据集上的行为一致。
对于图14(b)中的Math.StackExchange数据集,我们也观察到o3在每个类别上都优于Gemini-2.5-Pro。此外,这两个LLMs呈现出类似的趋势,即它们在每个子类别的准确率可以大致按相同的层次结构排序。两个模型在极限问题上表现最佳,表明这是一个相对简单的类别,它们能以高概率正确得出固定数值答案——超过
80
%
80 \%
80%——,而它们在更高级的主题如复分析上的表现则有所下降。
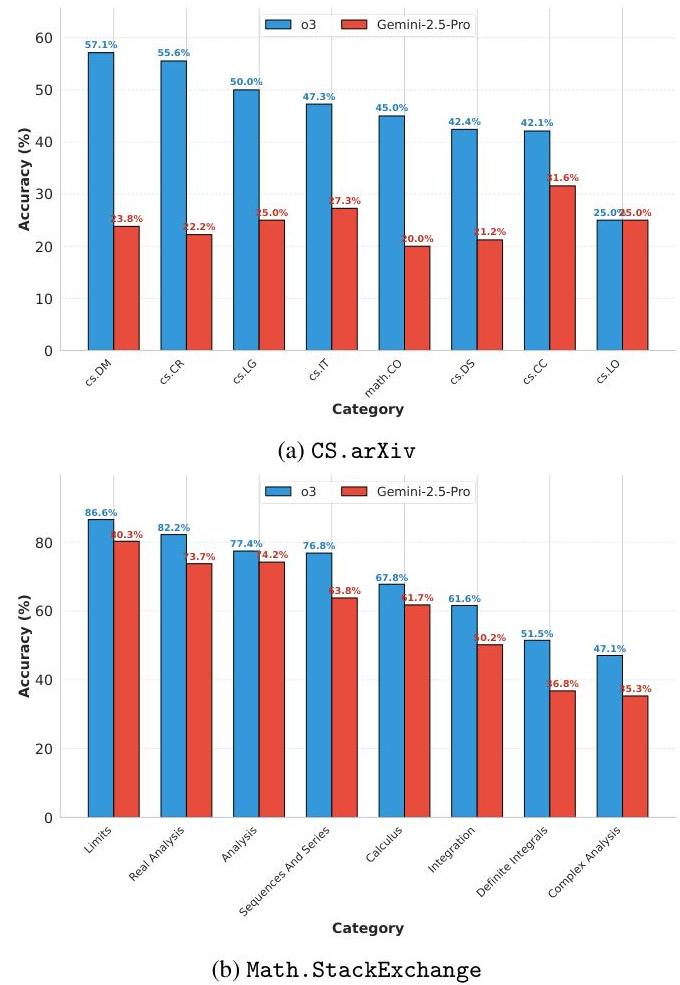
图14:在不同数学领域中的表现(a)CS.arXiv 和(b)Math.StackExchange。
B. 4 问题的类别分布
本小节提供了根据子领域划分的三个数据集中样本的统计数据,详见后续的三张表格。子领域是突出哪些数学领域最适合提取包含固定、唯一数值答案或封闭形式表达的定理及问答对的良好指标。
一个有趣的观察是组合数学(math.CO)在Math.arXiv和CS.arXiv数据集中都是最常见的领域之一。这表明组合数学问题不仅得到了很好的代表,而且更有可能拥有满足我们基准标准的固定答案解决方案,使自动评估过程易于验证。
| 类别 | arXiv标签 | 百分比(%) |
|---|---|---|
| 组合数学 | math.CO | 28.89 |
| 数论 | math.NT | 10.16 |
| 代数几何 | math.AG | 5.19 |
| 概率论 | math.PR | 3.16 |
| 几何拓扑 | math.GT | 4.51 |
| 群论 | math.GR | 3.16 |
| 信息论 | math.IT | 7.22 |
| 最优化与控制 | math.OC | 3.61 |
| 离散数学 | cs.DM | 4.51 |
| 偏微分方程分析 | math.AP | 1.13 |
| 交换代数 | math.AC | 1.35 |
| 机器学习 | cs.LG | 3.16 |
| 表示理论 | math.RT | 1.35 |
| 数学物理 | math.MP | 0.68 |
| 环与代数 | math.RA | 1.35 |
| 辛几何 | math.SG | 3.61 |
| 泛函分析 | math.FA | 2.93 |
| 经典分析与常微分方程 | math.CA | 2.48 |
| 微分几何 | math.DG | 1.58 |
| 复变量 | math.CV | 1.58 |
表4:Math.arXiv(05/2022 - 09/2022)数据集中最常代表的前20个arXiv类别的百分比分布。类别并非互斥;具有多个标签的论文会在每个相应类别下计数。组合数学和数论问题的主导地位与其他最近的数学基准(例如 [2, 14])一致,并可能反映出这些主题中构造性陈述的丰富性。
| 类别 | arXiv标签 | 百分比(%) |
|---|---|---|
| 信息论 | cs.IT | 49.55 |
| 组合数学 | math.CO | 36.04 |
| 数据结构与算法 | cs.DS | 29.73 |
| 离散数学 | cs.DM | 18.92 |
| 计算复杂性 | cs.CC | 17.12 |
| 机器学习 | cs.LG | 10.81 |
| 密码学与安全 | cs.CR | 8.11 |
| 计算机科学中的逻辑 | cs.LO | 7.21 |
| 计算机科学与博弈论 | cs.GT | 3.60 |
| 最优化与控制 | math.OC | 3.60 |
| 形式语言与自动机理论 | cs.FL | 2.70 |
| 逻辑 | math.LO | 2.70 |
| 数据库 | cs.DB | 1.80 |
| 代数几何 | math.AG | 1.80 |
| 神经与进化计算 | cs.NE | 1.80 |
| 交换代数 | math.AC | 1.80 |
| 分布式、并行与集群计算 | cs.DC | 1.80 |
| 系统与控制 | cs.SY | 0.90 |
| 多智能体系统 | cs.MA | 0.90 |
| 人工智能 | cs.AI | 0.90 |
| 信息检索 | cs.IR | 0.90 |
| 网络与互联网架构 | cs.NI | 0.90 |
| 数值分析 | cs.NA | 0.90 |
| 环与代数 | math.RA | 0.90 |
| 概率论 | math.PR | 0.90 |
表5:CS.arXiv数据集中arXiv类别的百分比分布。类别并非互斥;具有多个标签的论文会在每个相应类别下计数。
| 类别 | 百分比(%) |
|---|---|
| 积分 | 53.32 |
| 极限 | 43.91 |
| 微积分 | 33.76 |
| 定积分 | 25.09 |
| 实分析 | 21.77 |
| 序列与级数 | 12.73 |
| 复分析 | 6.27 |
| 分析 | 5.72 |
| 广义积分 | 5.35 |
| 解答验证 | 5.35 |
| 多元微积分 | 4.43 |
| 导数 | 4.43 |
| 极限不使用洛必达法则 | 4.06 |
| 封闭形式 | 3.32 |
| 三角函数 | 2.95 |
| 收敛与发散 | 2.77 |
| 概率 | 2.77 |
| 特殊函数 | 2.77 |
| 三角积分 | 2.58 |
| 轮廓积分 | 2.03 |
| 测度论 | 2.03 |
| 不定积分 | 2.03 |
| 复积分 | 1.85 |
| Gamma函数 | 1.85 |
| Epsilon Delta | 1.66 |
| 渐近分析 | 1.66 |
表6:Math.stackExchange数据集中最常代表的前26个标签的百分比分布。类别并非互斥;具有多个标签的问题会在每个相应类别下计数。
B. 5 上下文如何提高LLM在数学问题上的表现
图15展示了一些来自CS.arXiv数据集的例子,这些问题在提供相关上下文时可以正确解决,但在没有上下文时无法正确回答。
基于对样本的手动验证,我们观察到不提供上下文会对模型产生两个方向的负面影响:
- LLMs无法回答问题,因为它们不了解某些量的符号,而这些符号仅在论文中解释。在这种情况下,上下文对LLM至关重要,否则它要么试图猜测符号的含义,要么干脆不尝试回答并指出这些量未知。
-
- LLMs无法回答问题,因为在不提供上下文时,问题被认为较难。这种情况包括上下文提供用于构建当前定理或其证明的中间结果或证明示例。向语言模型提供上下文可以改善其正确证明问题的方法。
问题1:对于 r ≥ 5 r \geq 5 r≥5,请问 gcover ( B F ( r ) ) \operatorname{gcover}(\mathrm{BF}(r)) gcover(BF(r))用 r r r表示的值是什么?
- LLMs无法回答问题,因为在不提供上下文时,问题被认为较难。这种情况包括上下文提供用于构建当前定理或其证明的中间结果或证明示例。向语言模型提供上下文可以改善其正确证明问题的方法。
LLMs无法正确回答,因为如果没有事先定义, gcover ( B F ( r ) ) \operatorname{gcover}(B F(r)) gcover(BF(r))的符号是模糊的。
问题2:请问零速率误差指数 E ( 1 ) ( 0 ) E^{(1)}(0) E(1)(0)用 q ∈ P ( X ) q \in \mathcal{P}(\mathcal{X}) q∈P(X)的最大化和函数 d B ( x , x ′ , P ) d_{B}\left(x, x^{\prime}, P\right) dB(x,x′,P)表示的表达式是什么?
如果不提供上下文,LLMs不知道函数 d B ( x , x ′ , P ) d_{B}\left(x, x^{\prime}, P\right) dB(x,x′,P)或集合 P ( X ) \mathcal{P}(\mathcal{X}) P(X)。
问题3:设 n > 1 n>1 n>1为整数,且 A ⊆ Z 2 n \mathcal{A} \subseteq \mathbb{Z}_{2}^{n} A⊆Z2n为直径为一的最大反码。请问 A \mathcal{A} A中最多可能有多少个码字?
LLM知道反码代表什么,但这个问题太难了,无法正确回答。
问题4:考虑完全二部图 K m , n K_{m, n} Km,n,其参数满足 m < n m<n m<n、 n n n为偶数且 ( m + n ) ∣ m n (m+n) \mid m n (m+n)∣mn。请问 K m , n K_{m, n} Km,n的ATN是什么?
ATN(Alon-Tarsi Number)是语言模型常见的缩写,但问题难度太高,以至于它们无法正确回答。
图15:我们CS.arXiv数据集中的一些例子,这些问题在没有必要上下文的情况下无法被LLMs解决,但在提供上下文后可以解决。
参考论文:https://arxiv.org/pdf/2505.12575


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











